mirror of https://github.com/astral-sh/ruff
Index source code upfront to power (row, column) lookups (#1990)
## Summary The problem: given a (row, column) number (e.g., for a token in the AST), we need to be able to map it to a precise byte index in the source code. A while ago, we moved to `ropey` for this, since it was faster in practice (mostly, I think, because it's able to defer indexing). However, at some threshold of accesses, it becomes faster to index the string in advance, as we're doing here. ## Benchmark It looks like this is ~3.6% slower for the default rule set, but ~9.3% faster for `--select ALL`. **I suspect there's a strategy that would be strictly faster in both cases**, based on deferring even more computation (right now, we lazily compute these offsets, but we do it for the entire file at once, even if we only need some slice at the top), or caching the `ropey` lookups in some way. Before: 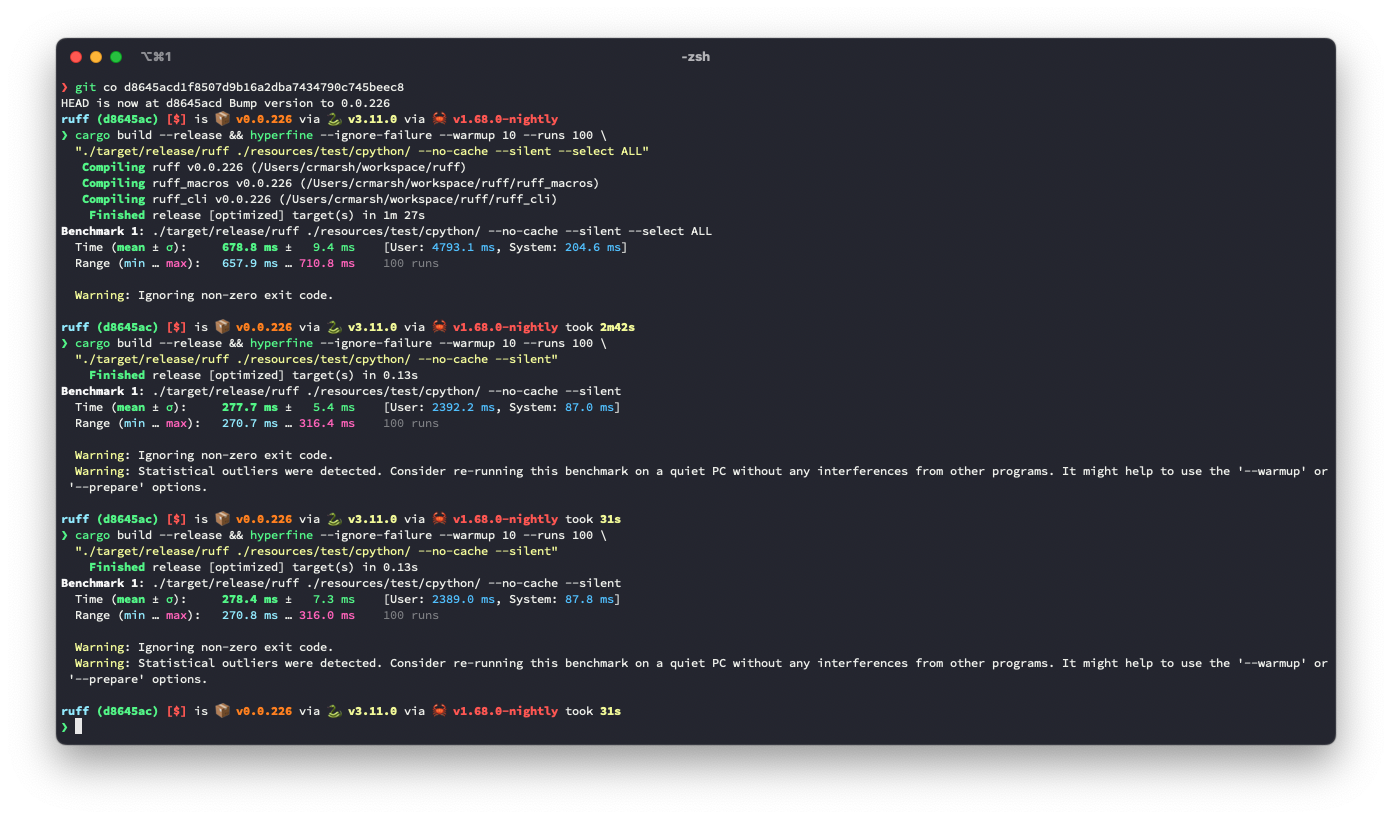 After: 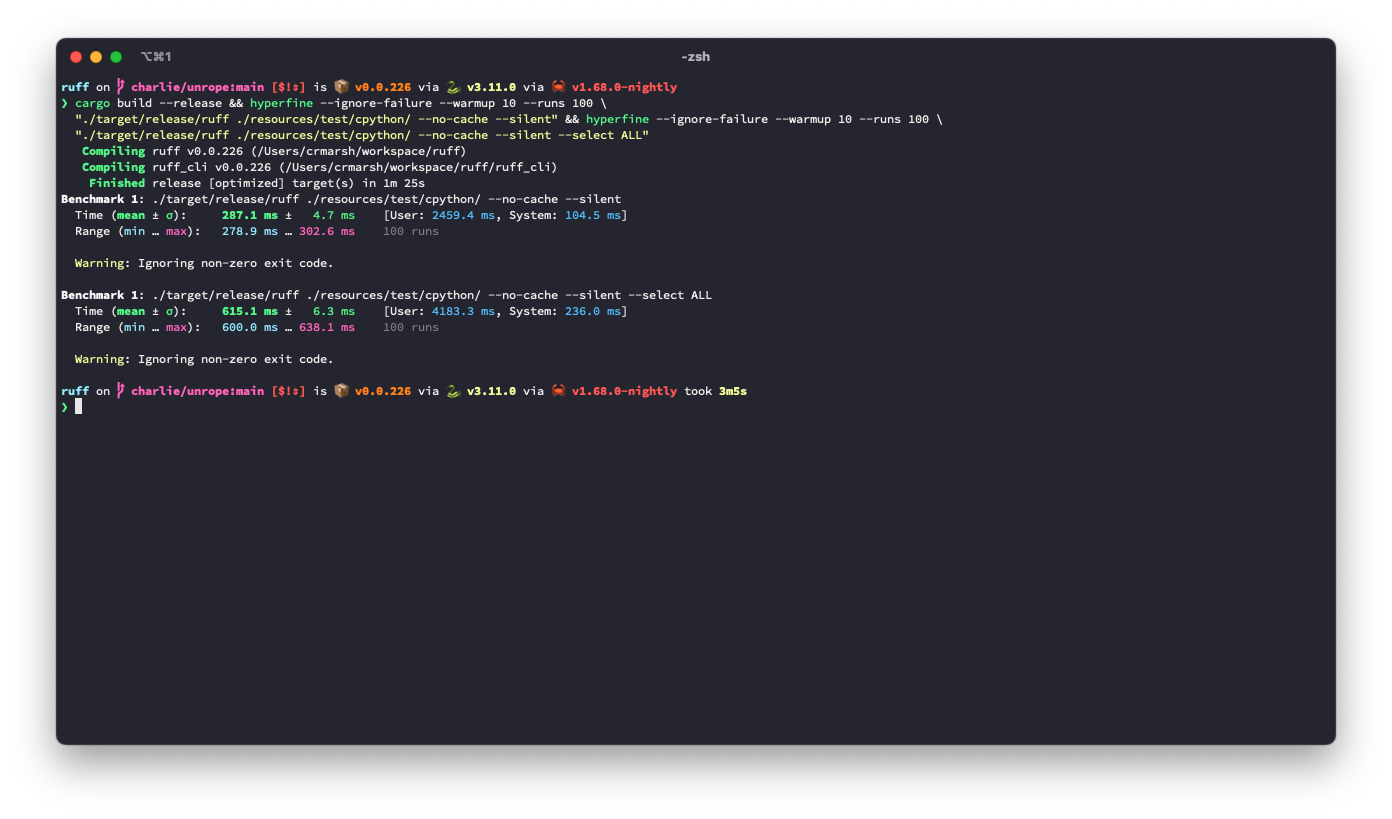 ## Alternatives I tried tweaking the `Vec::with_capacity` hints, and even trying `Vec::with_capacity(str_indices::lines_crlf::count_breaks(contents))` to do a quick scan of the number of lines, but that turned out to be slower.
{kind=link}
{kind=link}
This commit is contained in:
parent
08fc9b8095
commit
4dcf284a04
|
|
@ -1 +0,0 @@
|
|||
from long_module_name import member_one, member_two, member_three, member_four, member_five
|
||||
|
|
@ -366,7 +366,7 @@ pub fn collect_arg_names<'a>(arguments: &'a Arguments) -> FxHashSet<&'a str> {
|
|||
|
||||
/// Returns `true` if a statement or expression includes at least one comment.
|
||||
pub fn has_comments_in(range: Range, locator: &Locator) -> bool {
|
||||
lexer::make_tokenizer(&locator.slice_source_code_range(&range))
|
||||
lexer::make_tokenizer(locator.slice_source_code_range(&range))
|
||||
.any(|result| result.map_or(false, |(_, tok, _)| matches!(tok, Tok::Comment(..))))
|
||||
}
|
||||
|
||||
|
|
@ -486,7 +486,7 @@ pub fn identifier_range(stmt: &Stmt, locator: &Locator) -> Range {
|
|||
| StmtKind::AsyncFunctionDef { .. }
|
||||
) {
|
||||
let contents = locator.slice_source_code_range(&Range::from_located(stmt));
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(&contents, stmt.location).flatten() {
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(contents, stmt.location).flatten() {
|
||||
if matches!(tok, Tok::Name { .. }) {
|
||||
return Range::new(start, end);
|
||||
}
|
||||
|
|
@ -515,7 +515,7 @@ pub fn binding_range(binding: &Binding, locator: &Locator) -> Range {
|
|||
// Return the ranges of `Name` tokens within a specified node.
|
||||
pub fn find_names<T>(located: &Located<T>, locator: &Locator) -> Vec<Range> {
|
||||
let contents = locator.slice_source_code_range(&Range::from_located(located));
|
||||
lexer::make_tokenizer_located(&contents, located.location)
|
||||
lexer::make_tokenizer_located(contents, located.location)
|
||||
.flatten()
|
||||
.filter(|(_, tok, _)| matches!(tok, Tok::Name { .. }))
|
||||
.map(|(start, _, end)| Range {
|
||||
|
|
@ -535,7 +535,7 @@ pub fn excepthandler_name_range(handler: &Excepthandler, locator: &Locator) -> O
|
|||
let type_end_location = type_.end_location.unwrap();
|
||||
let contents =
|
||||
locator.slice_source_code_range(&Range::new(type_end_location, body[0].location));
|
||||
let range = lexer::make_tokenizer_located(&contents, type_end_location)
|
||||
let range = lexer::make_tokenizer_located(contents, type_end_location)
|
||||
.flatten()
|
||||
.tuple_windows()
|
||||
.find(|(tok, next_tok)| {
|
||||
|
|
@ -562,7 +562,7 @@ pub fn except_range(handler: &Excepthandler, locator: &Locator) -> Range {
|
|||
location: handler.location,
|
||||
end_location: end,
|
||||
});
|
||||
let range = lexer::make_tokenizer_located(&contents, handler.location)
|
||||
let range = lexer::make_tokenizer_located(contents, handler.location)
|
||||
.flatten()
|
||||
.find(|(_, kind, _)| matches!(kind, Tok::Except { .. }))
|
||||
.map(|(location, _, end_location)| Range {
|
||||
|
|
@ -576,7 +576,7 @@ pub fn except_range(handler: &Excepthandler, locator: &Locator) -> Range {
|
|||
/// Find f-strings that don't contain any formatted values in a `JoinedStr`.
|
||||
pub fn find_useless_f_strings(expr: &Expr, locator: &Locator) -> Vec<(Range, Range)> {
|
||||
let contents = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
lexer::make_tokenizer_located(&contents, expr.location)
|
||||
lexer::make_tokenizer_located(contents, expr.location)
|
||||
.flatten()
|
||||
.filter_map(|(location, tok, end_location)| match tok {
|
||||
Tok::String {
|
||||
|
|
@ -630,7 +630,7 @@ pub fn else_range(stmt: &Stmt, locator: &Locator) -> Option<Range> {
|
|||
.expect("Expected orelse to be non-empty")
|
||||
.location,
|
||||
});
|
||||
let range = lexer::make_tokenizer_located(&contents, body_end)
|
||||
let range = lexer::make_tokenizer_located(contents, body_end)
|
||||
.flatten()
|
||||
.find(|(_, kind, _)| matches!(kind, Tok::Else))
|
||||
.map(|(location, _, end_location)| Range {
|
||||
|
|
@ -646,7 +646,7 @@ pub fn else_range(stmt: &Stmt, locator: &Locator) -> Option<Range> {
|
|||
/// Return the `Range` of the first `Tok::Colon` token in a `Range`.
|
||||
pub fn first_colon_range(range: Range, locator: &Locator) -> Option<Range> {
|
||||
let contents = locator.slice_source_code_range(&range);
|
||||
let range = lexer::make_tokenizer_located(&contents, range.location)
|
||||
let range = lexer::make_tokenizer_located(contents, range.location)
|
||||
.flatten()
|
||||
.find(|(_, kind, _)| matches!(kind, Tok::Colon))
|
||||
.map(|(location, _, end_location)| Range {
|
||||
|
|
@ -676,7 +676,7 @@ pub fn elif_else_range(stmt: &Stmt, locator: &Locator) -> Option<Range> {
|
|||
_ => return None,
|
||||
};
|
||||
let contents = locator.slice_source_code_range(&Range::new(start, end));
|
||||
let range = lexer::make_tokenizer_located(&contents, start)
|
||||
let range = lexer::make_tokenizer_located(contents, start)
|
||||
.flatten()
|
||||
.find(|(_, kind, _)| matches!(kind, Tok::Elif | Tok::Else))
|
||||
.map(|(location, _, end_location)| Range {
|
||||
|
|
|
|||
|
|
@ -1,4 +1,3 @@
|
|||
use std::borrow::Cow;
|
||||
use std::str::Lines;
|
||||
|
||||
use rustpython_ast::{Located, Location};
|
||||
|
|
@ -7,7 +6,7 @@ use crate::ast::types::Range;
|
|||
use crate::source_code::Locator;
|
||||
|
||||
/// Extract the leading indentation from a line.
|
||||
pub fn indentation<'a, T>(locator: &'a Locator, located: &'a Located<T>) -> Option<Cow<'a, str>> {
|
||||
pub fn indentation<'a, T>(locator: &'a Locator, located: &'a Located<T>) -> Option<&'a str> {
|
||||
let range = Range::from_located(located);
|
||||
let indentation = locator.slice_source_code_range(&Range::new(
|
||||
Location::new(range.location.row(), 0),
|
||||
|
|
|
|||
|
|
@ -80,7 +80,7 @@ fn is_lone_child(child: &Stmt, parent: &Stmt, deleted: &[&Stmt]) -> Result<bool>
|
|||
/// of a multi-statement line.
|
||||
fn trailing_semicolon(stmt: &Stmt, locator: &Locator) -> Option<Location> {
|
||||
let contents = locator.slice_source_code_at(stmt.end_location.unwrap());
|
||||
for (row, line) in LinesWithTrailingNewline::from(&contents).enumerate() {
|
||||
for (row, line) in LinesWithTrailingNewline::from(contents).enumerate() {
|
||||
let trimmed = line.trim();
|
||||
if trimmed.starts_with(';') {
|
||||
let column = line
|
||||
|
|
@ -103,7 +103,7 @@ fn trailing_semicolon(stmt: &Stmt, locator: &Locator) -> Option<Location> {
|
|||
fn next_stmt_break(semicolon: Location, locator: &Locator) -> Location {
|
||||
let start_location = Location::new(semicolon.row(), semicolon.column() + 1);
|
||||
let contents = locator.slice_source_code_at(start_location);
|
||||
for (row, line) in LinesWithTrailingNewline::from(&contents).enumerate() {
|
||||
for (row, line) in LinesWithTrailingNewline::from(contents).enumerate() {
|
||||
let trimmed = line.trim();
|
||||
// Skip past any continuations.
|
||||
if trimmed.starts_with('\\') {
|
||||
|
|
@ -202,7 +202,7 @@ pub fn remove_unused_imports<'a>(
|
|||
indexer: &Indexer,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(stmt));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
|
||||
let Some(Statement::Simple(body)) = tree.body.first_mut() else {
|
||||
bail!("Expected Statement::Simple");
|
||||
|
|
|
|||
|
|
@ -54,7 +54,7 @@ fn apply_fixes<'a>(
|
|||
|
||||
// Add all contents from `last_pos` to `fix.location`.
|
||||
let slice = locator.slice_source_code_range(&Range::new(last_pos, fix.location));
|
||||
output.append(&slice);
|
||||
output.append(slice);
|
||||
|
||||
// Add the patch itself.
|
||||
output.append(&fix.content);
|
||||
|
|
@ -67,7 +67,7 @@ fn apply_fixes<'a>(
|
|||
|
||||
// Add the remaining content.
|
||||
let slice = locator.slice_source_code_at(last_pos);
|
||||
output.append(&slice);
|
||||
output.append(slice);
|
||||
|
||||
(Cow::from(output.finish()), num_fixed)
|
||||
}
|
||||
|
|
|
|||
|
|
@ -273,7 +273,7 @@ impl<'a> Checker<'a> {
|
|||
Location::new(*noqa_lineno, 0),
|
||||
Location::new(noqa_lineno + 1, 0),
|
||||
));
|
||||
match noqa::extract_noqa_directive(&line) {
|
||||
match noqa::extract_noqa_directive(line) {
|
||||
Directive::None => false,
|
||||
Directive::All(..) => true,
|
||||
Directive::Codes(.., codes) => noqa::includes(code, &codes),
|
||||
|
|
@ -4610,12 +4610,13 @@ impl<'a> Checker<'a> {
|
|||
Location::new(expr.location.row(), 0),
|
||||
Location::new(expr.location.row(), expr.location.column()),
|
||||
));
|
||||
let body = pydocstyle::helpers::raw_contents(&contents);
|
||||
|
||||
let body = pydocstyle::helpers::raw_contents(contents);
|
||||
let docstring = Docstring {
|
||||
kind: definition.kind,
|
||||
expr,
|
||||
contents: &contents,
|
||||
indentation: &indentation,
|
||||
contents,
|
||||
indentation,
|
||||
body,
|
||||
};
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,3 @@
|
|||
use std::borrow::Cow;
|
||||
|
||||
use rustpython_ast::{Expr, Stmt};
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
|
|
@ -23,9 +21,9 @@ pub struct Definition<'a> {
|
|||
pub struct Docstring<'a> {
|
||||
pub kind: DefinitionKind<'a>,
|
||||
pub expr: &'a Expr,
|
||||
pub contents: &'a Cow<'a, str>,
|
||||
pub contents: &'a str,
|
||||
pub body: &'a str,
|
||||
pub indentation: &'a Cow<'a, str>,
|
||||
pub indentation: &'a str,
|
||||
}
|
||||
|
||||
pub enum Documentable {
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@ pub fn commented_out_code(
|
|||
let line = locator.slice_source_code_range(&Range::new(location, end_location));
|
||||
|
||||
// Verify that the comment is on its own line, and that it contains code.
|
||||
if is_standalone_comment(&line) && comment_contains_code(&line, &settings.task_tags[..]) {
|
||||
if is_standalone_comment(line) && comment_contains_code(line, &settings.task_tags[..]) {
|
||||
let mut diagnostic = Diagnostic::new(violations::CommentedOutCode, Range::new(start, end));
|
||||
if matches!(autofix, flags::Autofix::Enabled)
|
||||
&& settings.rules.should_fix(&Rule::CommentedOutCode)
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ pub fn add_return_none_annotation(locator: &Locator, stmt: &Stmt) -> Result<Fix>
|
|||
let mut seen_lpar = false;
|
||||
let mut seen_rpar = false;
|
||||
let mut count: usize = 0;
|
||||
for (start, tok, ..) in lexer::make_tokenizer_located(&contents, range.location).flatten() {
|
||||
for (start, tok, ..) in lexer::make_tokenizer_located(contents, range.location).flatten() {
|
||||
if seen_lpar && seen_rpar {
|
||||
if matches!(tok, Tok::Colon) {
|
||||
return Ok(Fix::insertion(" -> None".to_string(), start));
|
||||
|
|
|
|||
|
|
@ -34,7 +34,7 @@ pub fn fix_unnecessary_generator_list(
|
|||
) -> Result<Fix> {
|
||||
// Expr(Call(GeneratorExp)))) -> Expr(ListComp)))
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -75,7 +75,7 @@ pub fn fix_unnecessary_generator_set(
|
|||
) -> Result<Fix> {
|
||||
// Expr(Call(GeneratorExp)))) -> Expr(SetComp)))
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -116,7 +116,7 @@ pub fn fix_unnecessary_generator_dict(
|
|||
expr: &rustpython_ast::Expr,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -175,7 +175,7 @@ pub fn fix_unnecessary_list_comprehension_set(
|
|||
// Expr(Call(ListComp)))) ->
|
||||
// Expr(SetComp)))
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -214,7 +214,7 @@ pub fn fix_unnecessary_list_comprehension_dict(
|
|||
expr: &rustpython_ast::Expr,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -305,7 +305,7 @@ fn drop_trailing_comma<'a>(
|
|||
pub fn fix_unnecessary_literal_set(locator: &Locator, expr: &rustpython_ast::Expr) -> Result<Fix> {
|
||||
// Expr(Call(List|Tuple)))) -> Expr(Set)))
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let mut call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -348,7 +348,7 @@ pub fn fix_unnecessary_literal_set(locator: &Locator, expr: &rustpython_ast::Exp
|
|||
pub fn fix_unnecessary_literal_dict(locator: &Locator, expr: &rustpython_ast::Expr) -> Result<Fix> {
|
||||
// Expr(Call(List|Tuple)))) -> Expr(Dict)))
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -416,7 +416,7 @@ pub fn fix_unnecessary_collection_call(
|
|||
) -> Result<Fix> {
|
||||
// Expr(Call("list" | "tuple" | "dict")))) -> Expr(List|Tuple|Dict)
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let Expression::Name(name) = &call.func.as_ref() else {
|
||||
|
|
@ -524,7 +524,7 @@ pub fn fix_unnecessary_literal_within_tuple_call(
|
|||
expr: &rustpython_ast::Expr,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -578,7 +578,7 @@ pub fn fix_unnecessary_literal_within_list_call(
|
|||
expr: &rustpython_ast::Expr,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -632,7 +632,7 @@ pub fn fix_unnecessary_literal_within_list_call(
|
|||
pub fn fix_unnecessary_list_call(locator: &Locator, expr: &rustpython_ast::Expr) -> Result<Fix> {
|
||||
// Expr(Call(List|Tuple)))) -> Expr(List|Tuple)))
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let call = match_call(body)?;
|
||||
let arg = match_arg(call)?;
|
||||
|
|
@ -657,7 +657,7 @@ pub fn fix_unnecessary_call_around_sorted(
|
|||
expr: &rustpython_ast::Expr,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
let outer_call = match_call(body)?;
|
||||
let inner_call = match &outer_call.args[..] {
|
||||
|
|
@ -739,7 +739,7 @@ pub fn fix_unnecessary_comprehension(
|
|||
expr: &rustpython_ast::Expr,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(expr));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
|
||||
match &body.value {
|
||||
|
|
|
|||
|
|
@ -109,7 +109,7 @@ fn implicit_return(checker: &mut Checker, last_stmt: &Stmt) {
|
|||
if checker.patch(&Rule::ImplicitReturn) {
|
||||
if let Some(indent) = indentation(checker.locator, last_stmt) {
|
||||
let mut content = String::new();
|
||||
content.push_str(&indent);
|
||||
content.push_str(indent);
|
||||
content.push_str("return None");
|
||||
content.push('\n');
|
||||
diagnostic.amend(Fix::insertion(
|
||||
|
|
|
|||
|
|
@ -1,5 +1,3 @@
|
|||
use std::borrow::Cow;
|
||||
|
||||
use anyhow::{bail, Result};
|
||||
use libcst_native::{
|
||||
BooleanOp, BooleanOperation, Codegen, CodegenState, CompoundStatement, Expression, If,
|
||||
|
|
@ -52,9 +50,9 @@ pub(crate) fn fix_nested_if_statements(
|
|||
// If this is an `elif`, we have to remove the `elif` keyword for now. (We'll
|
||||
// restore the `el` later on.)
|
||||
let module_text = if is_elif {
|
||||
Cow::Owned(contents.replacen("elif", "if", 1))
|
||||
contents.replacen("elif", "if", 1)
|
||||
} else {
|
||||
contents
|
||||
contents.to_string()
|
||||
};
|
||||
|
||||
// If the block is indented, "embed" it in a function definition, to preserve
|
||||
|
|
@ -63,10 +61,7 @@ pub(crate) fn fix_nested_if_statements(
|
|||
let module_text = if outer_indent.is_empty() {
|
||||
module_text
|
||||
} else {
|
||||
Cow::Owned(format!(
|
||||
"def f():{}{module_text}",
|
||||
stylist.line_ending().as_str()
|
||||
))
|
||||
format!("def f():{}{module_text}", stylist.line_ending().as_str())
|
||||
};
|
||||
|
||||
// Parse the CST.
|
||||
|
|
@ -82,7 +77,7 @@ pub(crate) fn fix_nested_if_statements(
|
|||
let Suite::IndentedBlock(indented_block) = &mut embedding.body else {
|
||||
bail!("Expected indented block")
|
||||
};
|
||||
indented_block.indent = Some(&outer_indent);
|
||||
indented_block.indent = Some(outer_indent);
|
||||
|
||||
&mut *indented_block.body
|
||||
};
|
||||
|
|
|
|||
|
|
@ -1,5 +1,3 @@
|
|||
use std::borrow::Cow;
|
||||
|
||||
use anyhow::{bail, Result};
|
||||
use libcst_native::{Codegen, CodegenState, CompoundStatement, Statement, Suite, With};
|
||||
use rustpython_ast::Location;
|
||||
|
|
@ -30,9 +28,9 @@ pub(crate) fn fix_multiple_with_statements(
|
|||
// indentation while retaining valid source code. (We'll strip the prefix later
|
||||
// on.)
|
||||
let module_text = if outer_indent.is_empty() {
|
||||
contents
|
||||
contents.to_string()
|
||||
} else {
|
||||
Cow::Owned(format!("def f():\n{contents}"))
|
||||
format!("def f():\n{contents}")
|
||||
};
|
||||
|
||||
// Parse the CST.
|
||||
|
|
@ -48,7 +46,7 @@ pub(crate) fn fix_multiple_with_statements(
|
|||
let Suite::IndentedBlock(indented_block) = &mut embedding.body else {
|
||||
bail!("Expected indented block")
|
||||
};
|
||||
indented_block.indent = Some(&outer_indent);
|
||||
indented_block.indent = Some(outer_indent);
|
||||
|
||||
&mut *indented_block.body
|
||||
};
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ pub struct Comment<'a> {
|
|||
/// Collect all comments in an import block.
|
||||
pub fn collect_comments<'a>(range: &Range, locator: &'a Locator) -> Vec<Comment<'a>> {
|
||||
let contents = locator.slice_source_code_range(range);
|
||||
lexer::make_tokenizer_located(&contents, range.location)
|
||||
lexer::make_tokenizer_located(contents, range.location)
|
||||
.flatten()
|
||||
.filter_map(|(start, tok, end)| {
|
||||
if let Tok::Comment(value) = tok {
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ pub fn trailing_comma(stmt: &Stmt, locator: &Locator) -> TrailingComma {
|
|||
let contents = locator.slice_source_code_range(&Range::from_located(stmt));
|
||||
let mut count: usize = 0;
|
||||
let mut trailing_comma = TrailingComma::Absent;
|
||||
for (_, tok, _) in lexer::make_tokenizer(&contents).flatten() {
|
||||
for (_, tok, _) in lexer::make_tokenizer(contents).flatten() {
|
||||
if matches!(tok, Tok::Lpar) {
|
||||
count += 1;
|
||||
}
|
||||
|
|
@ -110,7 +110,7 @@ pub fn find_splice_location(body: &[Stmt], locator: &Locator) -> Location {
|
|||
|
||||
// Find the first token that isn't a comment or whitespace.
|
||||
let contents = locator.slice_source_code_at(splice);
|
||||
for (.., tok, end) in lexer::make_tokenizer(&contents).flatten() {
|
||||
for (.., tok, end) in lexer::make_tokenizer(contents).flatten() {
|
||||
if matches!(tok, Tok::Comment(..) | Tok::Newline) {
|
||||
splice = end;
|
||||
} else {
|
||||
|
|
|
|||
|
|
@ -701,7 +701,6 @@ mod tests {
|
|||
#[test_case(Path::new("insert_empty_lines.py"))]
|
||||
#[test_case(Path::new("insert_empty_lines.pyi"))]
|
||||
#[test_case(Path::new("leading_prefix.py"))]
|
||||
#[test_case(Path::new("line_ending_cr.py"))]
|
||||
#[test_case(Path::new("line_ending_crlf.py"))]
|
||||
#[test_case(Path::new("line_ending_lf.py"))]
|
||||
#[test_case(Path::new("magic_trailing_comma.py"))]
|
||||
|
|
|
|||
|
|
@ -38,7 +38,7 @@ pub fn organize_imports(
|
|||
package: Option<&Path>,
|
||||
) -> Option<Diagnostic> {
|
||||
let indentation = locator.slice_source_code_range(&extract_indentation_range(&block.imports));
|
||||
let indentation = leading_space(&indentation);
|
||||
let indentation = leading_space(indentation);
|
||||
|
||||
let range = extract_range(&block.imports);
|
||||
|
||||
|
|
@ -96,7 +96,7 @@ pub fn organize_imports(
|
|||
Location::new(range.location.row(), 0),
|
||||
Location::new(range.end_location.row() + 1 + num_trailing_lines, 0),
|
||||
);
|
||||
let actual = dedent(&locator.slice_source_code_range(&range));
|
||||
let actual = dedent(locator.slice_source_code_range(&range));
|
||||
if actual == dedent(&expected) {
|
||||
None
|
||||
} else {
|
||||
|
|
|
|||
|
|
@ -1,22 +0,0 @@
|
|||
---
|
||||
source: src/rules/isort/mod.rs
|
||||
expression: diagnostics
|
||||
---
|
||||
- kind:
|
||||
UnsortedImports: ~
|
||||
location:
|
||||
row: 1
|
||||
column: 0
|
||||
end_location:
|
||||
row: 2
|
||||
column: 0
|
||||
fix:
|
||||
content: "from long_module_name import (\r member_five,\r member_four,\r member_one,\r member_three,\r member_two,\r)\r"
|
||||
location:
|
||||
row: 1
|
||||
column: 0
|
||||
end_location:
|
||||
row: 2
|
||||
column: 0
|
||||
parent: ~
|
||||
|
||||
|
|
@ -480,7 +480,7 @@ pub fn do_not_assign_lambda(checker: &mut Checker, target: &Expr, value: &Expr,
|
|||
Location::new(stmt.location.row(), 0),
|
||||
Location::new(stmt.location.row() + 1, 0),
|
||||
));
|
||||
let indentation = &leading_space(&first_line);
|
||||
let indentation = &leading_space(first_line);
|
||||
let mut indented = String::new();
|
||||
for (idx, line) in function(id, args, body, checker.stylist)
|
||||
.lines()
|
||||
|
|
@ -603,7 +603,7 @@ pub fn invalid_escape_sequence(
|
|||
let text = locator.slice_source_code_range(&Range::new(start, end));
|
||||
|
||||
// Determine whether the string is single- or triple-quoted.
|
||||
let quote = extract_quote(&text);
|
||||
let quote = extract_quote(text);
|
||||
let quote_pos = text.find(quote).unwrap();
|
||||
let prefix = text[..quote_pos].to_lowercase();
|
||||
let body = &text[(quote_pos + quote.len())..(text.len() - quote.len())];
|
||||
|
|
|
|||
|
|
@ -74,7 +74,7 @@ pub fn blank_before_after_function(checker: &mut Checker, docstring: &Docstring)
|
|||
.count();
|
||||
|
||||
// Avoid D202 violations for blank lines followed by inner functions or classes.
|
||||
if blank_lines_after == 1 && INNER_FUNCTION_OR_CLASS_REGEX.is_match(&after) {
|
||||
if blank_lines_after == 1 && INNER_FUNCTION_OR_CLASS_REGEX.is_match(after) {
|
||||
return;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ pub fn remove_unused_format_arguments_from_dict(
|
|||
locator: &Locator,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(stmt));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
|
||||
let new_dict = {
|
||||
|
|
@ -63,7 +63,7 @@ pub fn remove_unused_keyword_arguments_from_format_call(
|
|||
locator: &Locator,
|
||||
) -> Result<Fix> {
|
||||
let module_text = locator.slice_source_code_range(&location);
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut body = match_expr(&mut tree)?;
|
||||
|
||||
let new_call = {
|
||||
|
|
@ -112,7 +112,7 @@ pub fn remove_exception_handler_assignment(
|
|||
// End of the token just before the `as` to the semicolon.
|
||||
let mut prev = None;
|
||||
for (start, tok, end) in
|
||||
lexer::make_tokenizer_located(&contents, excepthandler.location).flatten()
|
||||
lexer::make_tokenizer_located(contents, excepthandler.location).flatten()
|
||||
{
|
||||
if matches!(tok, Tok::As) {
|
||||
fix_start = prev;
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ pub fn invalid_literal_comparison(
|
|||
comparators: &[Expr],
|
||||
location: Range,
|
||||
) {
|
||||
let located = Lazy::new(|| locate_cmpops(&checker.locator.slice_source_code_range(&location)));
|
||||
let located = Lazy::new(|| locate_cmpops(checker.locator.slice_source_code_range(&location)));
|
||||
let mut left = left;
|
||||
for (index, (op, right)) in izip!(ops, comparators).enumerate() {
|
||||
if matches!(op, Cmpop::Is | Cmpop::IsNot)
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ where
|
|||
F: Fn(Tok) -> bool,
|
||||
{
|
||||
let contents = locator.slice_source_code_range(&Range::from_located(stmt));
|
||||
for ((_, tok, _), (start, ..)) in lexer::make_tokenizer_located(&contents, stmt.location)
|
||||
for ((_, tok, _), (start, ..)) in lexer::make_tokenizer_located(contents, stmt.location)
|
||||
.flatten()
|
||||
.tuple_windows()
|
||||
{
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ pub fn remove_class_def_base(
|
|||
let mut fix_start = None;
|
||||
let mut fix_end = None;
|
||||
let mut count: usize = 0;
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(&contents, stmt_at).flatten() {
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(contents, stmt_at).flatten() {
|
||||
if matches!(tok, Tok::Lpar) {
|
||||
if count == 0 {
|
||||
fix_start = Some(start);
|
||||
|
|
@ -57,7 +57,7 @@ pub fn remove_class_def_base(
|
|||
let mut fix_start: Option<Location> = None;
|
||||
let mut fix_end: Option<Location> = None;
|
||||
let mut seen_comma = false;
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(&contents, stmt_at).flatten() {
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(contents, stmt_at).flatten() {
|
||||
if seen_comma {
|
||||
if matches!(tok, Tok::NonLogicalNewline) {
|
||||
// Also delete any non-logical newlines after the comma.
|
||||
|
|
@ -87,7 +87,7 @@ pub fn remove_class_def_base(
|
|||
// isn't a comma.
|
||||
let mut fix_start: Option<Location> = None;
|
||||
let mut fix_end: Option<Location> = None;
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(&contents, stmt_at).flatten() {
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(contents, stmt_at).flatten() {
|
||||
if start == expr_at {
|
||||
fix_end = Some(end);
|
||||
break;
|
||||
|
|
@ -109,7 +109,7 @@ pub fn remove_super_arguments(locator: &Locator, expr: &Expr) -> Option<Fix> {
|
|||
let range = Range::from_located(expr);
|
||||
let contents = locator.slice_source_code_range(&range);
|
||||
|
||||
let mut tree = libcst_native::parse_module(&contents, None).ok()?;
|
||||
let mut tree = libcst_native::parse_module(contents, None).ok()?;
|
||||
|
||||
let Statement::Simple(body) = tree.body.first_mut()? else {
|
||||
return None;
|
||||
|
|
|
|||
|
|
@ -33,7 +33,7 @@ impl<'a> FormatSummaryValues<'a> {
|
|||
let arg = checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::from_located(arg));
|
||||
if contains_invalids(&arg) {
|
||||
if contains_invalids(arg) {
|
||||
return None;
|
||||
}
|
||||
extracted_args.push(arg.to_string());
|
||||
|
|
@ -44,7 +44,7 @@ impl<'a> FormatSummaryValues<'a> {
|
|||
let kwarg = checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::from_located(value));
|
||||
if contains_invalids(&kwarg) {
|
||||
if contains_invalids(kwarg) {
|
||||
return None;
|
||||
}
|
||||
extracted_kwargs.insert(key, kwarg.to_string());
|
||||
|
|
@ -119,7 +119,7 @@ fn try_convert_to_f_string(checker: &Checker, expr: &Expr) -> Option<String> {
|
|||
.slice_source_code_range(&Range::from_located(value));
|
||||
|
||||
// Tokenize: we need to avoid trying to fix implicit string concatenations.
|
||||
if lexer::make_tokenizer(&contents)
|
||||
if lexer::make_tokenizer(contents)
|
||||
.flatten()
|
||||
.filter(|(_, tok, _)| matches!(tok, Tok::String { .. }))
|
||||
.count()
|
||||
|
|
@ -133,7 +133,7 @@ fn try_convert_to_f_string(checker: &Checker, expr: &Expr) -> Option<String> {
|
|||
let contents = if contents.starts_with('U') || contents.starts_with('u') {
|
||||
&contents[1..]
|
||||
} else {
|
||||
&contents
|
||||
contents
|
||||
};
|
||||
if contents.is_empty() {
|
||||
return None;
|
||||
|
|
|
|||
|
|
@ -102,7 +102,7 @@ pub(crate) fn format_literals(checker: &mut Checker, summary: &FormatSummary, ex
|
|||
// Currently, the only issue we know of is in LibCST:
|
||||
// https://github.com/Instagram/LibCST/issues/846
|
||||
if let Ok(contents) = generate_call(
|
||||
&checker
|
||||
checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::from_located(expr)),
|
||||
&summary.indexes,
|
||||
|
|
|
|||
|
|
@ -84,7 +84,7 @@ pub fn native_literals(
|
|||
let arg_code = checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::from_located(arg));
|
||||
if lexer::make_tokenizer(&arg_code)
|
||||
if lexer::make_tokenizer(arg_code)
|
||||
.flatten()
|
||||
.filter(|(_, tok, _)| matches!(tok, Tok::String { .. }))
|
||||
.count()
|
||||
|
|
|
|||
|
|
@ -186,7 +186,7 @@ fn clean_params_dictionary(checker: &mut Checker, right: &Expr) -> Option<String
|
|||
.slice_source_code_range(&Range::from_located(value));
|
||||
contents.push_str(key_string);
|
||||
contents.push('=');
|
||||
contents.push_str(&value_string);
|
||||
contents.push_str(value_string);
|
||||
arguments.push(contents);
|
||||
} else {
|
||||
// If there are any non-string keys, abort.
|
||||
|
|
@ -205,7 +205,7 @@ fn clean_params_dictionary(checker: &mut Checker, right: &Expr) -> Option<String
|
|||
|
||||
for item in &arguments {
|
||||
contents.push('\n');
|
||||
contents.push_str(&indent);
|
||||
contents.push_str(indent);
|
||||
contents.push_str(item);
|
||||
contents.push(',');
|
||||
}
|
||||
|
|
@ -217,7 +217,7 @@ fn clean_params_dictionary(checker: &mut Checker, right: &Expr) -> Option<String
|
|||
if let Some(ident) = indent.strip_prefix(default_indent) {
|
||||
contents.push_str(ident);
|
||||
} else {
|
||||
contents.push_str(&indent);
|
||||
contents.push_str(indent);
|
||||
}
|
||||
} else {
|
||||
contents.push_str(&arguments.join(", "));
|
||||
|
|
@ -304,7 +304,7 @@ pub(crate) fn printf_string_formatting(
|
|||
let mut strings: Vec<(Location, Location)> = vec![];
|
||||
let mut extension = None;
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(
|
||||
&checker
|
||||
checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::from_located(expr)),
|
||||
expr.location,
|
||||
|
|
@ -333,7 +333,7 @@ pub(crate) fn printf_string_formatting(
|
|||
let string = checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::new(*start, *end));
|
||||
let (Some(leader), Some(trailer)) = (leading_quote(&string), trailing_quote(&string)) else {
|
||||
let (Some(leader), Some(trailer)) = (leading_quote(string), trailing_quote(string)) else {
|
||||
return;
|
||||
};
|
||||
let string = &string[leader.len()..string.len() - trailer.len()];
|
||||
|
|
@ -371,14 +371,14 @@ pub(crate) fn printf_string_formatting(
|
|||
match prev {
|
||||
None => {
|
||||
contents.push_str(
|
||||
&checker
|
||||
checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::new(expr.location, *start)),
|
||||
);
|
||||
}
|
||||
Some(prev) => {
|
||||
contents.push_str(
|
||||
&checker
|
||||
checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::new(prev, *start)),
|
||||
);
|
||||
|
|
@ -391,7 +391,7 @@ pub(crate) fn printf_string_formatting(
|
|||
|
||||
if let Some((.., end)) = extension {
|
||||
contents.push_str(
|
||||
&checker
|
||||
checker
|
||||
.locator
|
||||
.slice_source_code_range(&Range::new(prev.unwrap(), end)),
|
||||
);
|
||||
|
|
|
|||
|
|
@ -112,7 +112,7 @@ fn create_remove_param_fix(locator: &Locator, expr: &Expr, mode_param: &Expr) ->
|
|||
let mut fix_end: Option<Location> = None;
|
||||
let mut is_first_arg: bool = false;
|
||||
let mut delete_first_arg: bool = false;
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(&content, expr.location).flatten() {
|
||||
for (start, tok, end) in lexer::make_tokenizer_located(content, expr.location).flatten() {
|
||||
if start == mode_param.location {
|
||||
if is_first_arg {
|
||||
delete_first_arg = true;
|
||||
|
|
|
|||
|
|
@ -56,7 +56,7 @@ fn generate_fix(locator: &Locator, stdout: &Keyword, stderr: &Keyword) -> Option
|
|||
};
|
||||
let mut contents = String::from("capture_output=True");
|
||||
if let Some(middle) = extract_middle(
|
||||
&locator.slice_source_code_range(&Range::new(first.end_location.unwrap(), last.location)),
|
||||
locator.slice_source_code_range(&Range::new(first.end_location.unwrap(), last.location)),
|
||||
) {
|
||||
if middle.multi_line {
|
||||
let Some(indent) = indentation(locator, first) else {
|
||||
|
|
@ -64,7 +64,7 @@ fn generate_fix(locator: &Locator, stdout: &Keyword, stderr: &Keyword) -> Option
|
|||
};
|
||||
contents.push(',');
|
||||
contents.push('\n');
|
||||
contents.push_str(&indent);
|
||||
contents.push_str(indent);
|
||||
} else {
|
||||
contents.push(',');
|
||||
contents.push(' ');
|
||||
|
|
|
|||
|
|
@ -117,7 +117,7 @@ fn format_import(
|
|||
stylist: &Stylist,
|
||||
) -> Result<String> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(stmt));
|
||||
let mut tree = match_module(&module_text)?;
|
||||
let mut tree = match_module(module_text)?;
|
||||
let mut import = match_import(&mut tree)?;
|
||||
|
||||
let Import { names, .. } = import.clone();
|
||||
|
|
@ -147,7 +147,7 @@ fn format_import_from(
|
|||
stylist: &Stylist,
|
||||
) -> Result<String> {
|
||||
let module_text = locator.slice_source_code_range(&Range::from_located(stmt));
|
||||
let mut tree = match_module(&module_text).unwrap();
|
||||
let mut tree = match_module(module_text).unwrap();
|
||||
let mut import = match_import_from(&mut tree)?;
|
||||
|
||||
let ImportFrom {
|
||||
|
|
@ -228,7 +228,7 @@ pub fn rewrite_mock_import(checker: &mut Checker, stmt: &Stmt) {
|
|||
// Generate the fix, if needed, which is shared between all `mock` imports.
|
||||
let content = if checker.patch(&Rule::RewriteMockImport) {
|
||||
if let Some(indent) = indentation(checker.locator, stmt) {
|
||||
match format_import(stmt, &indent, checker.locator, checker.stylist) {
|
||||
match format_import(stmt, indent, checker.locator, checker.stylist) {
|
||||
Ok(content) => Some(content),
|
||||
Err(e) => {
|
||||
error!("Failed to rewrite `mock` import: {e}");
|
||||
|
|
@ -277,7 +277,7 @@ pub fn rewrite_mock_import(checker: &mut Checker, stmt: &Stmt) {
|
|||
);
|
||||
if checker.patch(&Rule::RewriteMockImport) {
|
||||
if let Some(indent) = indentation(checker.locator, stmt) {
|
||||
match format_import_from(stmt, &indent, checker.locator, checker.stylist) {
|
||||
match format_import_from(stmt, indent, checker.locator, checker.stylist) {
|
||||
Ok(content) => {
|
||||
diagnostic.amend(Fix::replacement(
|
||||
content,
|
||||
|
|
|
|||
|
|
@ -1,65 +1,256 @@
|
|||
//! Struct used to efficiently slice source code at (row, column) Locations.
|
||||
|
||||
use std::borrow::Cow;
|
||||
|
||||
use once_cell::unsync::OnceCell;
|
||||
use ropey::Rope;
|
||||
use rustpython_ast::Location;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
|
||||
pub struct Locator<'a> {
|
||||
contents: &'a str,
|
||||
rope: OnceCell<Rope>,
|
||||
index: OnceCell<Index>,
|
||||
}
|
||||
|
||||
pub enum Index {
|
||||
Ascii(Vec<usize>),
|
||||
Utf8(Vec<Vec<usize>>),
|
||||
}
|
||||
|
||||
/// Compute the starting byte index of each line in ASCII source code.
|
||||
fn index_ascii(contents: &str) -> Vec<usize> {
|
||||
let mut index = Vec::with_capacity(48);
|
||||
index.push(0);
|
||||
let bytes = contents.as_bytes();
|
||||
for (i, byte) in bytes.iter().enumerate() {
|
||||
if *byte == b'\n' {
|
||||
index.push(i + 1);
|
||||
}
|
||||
}
|
||||
index
|
||||
}
|
||||
|
||||
/// Compute the starting byte index of each character in UTF-8 source code.
|
||||
fn index_utf8(contents: &str) -> Vec<Vec<usize>> {
|
||||
let mut index = Vec::with_capacity(48);
|
||||
let mut current_row = Vec::with_capacity(48);
|
||||
let mut current_byte_offset = 0;
|
||||
let mut previous_char = '\0';
|
||||
for char in contents.chars() {
|
||||
current_row.push(current_byte_offset);
|
||||
if char == '\n' {
|
||||
if previous_char == '\r' {
|
||||
current_row.pop();
|
||||
}
|
||||
index.push(current_row);
|
||||
current_row = Vec::with_capacity(48);
|
||||
}
|
||||
current_byte_offset += char.len_utf8();
|
||||
previous_char = char;
|
||||
}
|
||||
index.push(current_row);
|
||||
index
|
||||
}
|
||||
|
||||
/// Compute the starting byte index of each line in source code.
|
||||
pub fn index(contents: &str) -> Index {
|
||||
if contents.is_ascii() {
|
||||
Index::Ascii(index_ascii(contents))
|
||||
} else {
|
||||
Index::Utf8(index_utf8(contents))
|
||||
}
|
||||
}
|
||||
|
||||
/// Truncate a [`Location`] to a byte offset in ASCII source code.
|
||||
fn truncate_ascii(location: Location, index: &[usize], contents: &str) -> usize {
|
||||
if location.row() - 1 == index.len() && location.column() == 0
|
||||
|| (!index.is_empty()
|
||||
&& location.row() - 1 == index.len() - 1
|
||||
&& index[location.row() - 1] + location.column() >= contents.len())
|
||||
{
|
||||
contents.len()
|
||||
} else {
|
||||
index[location.row() - 1] + location.column()
|
||||
}
|
||||
}
|
||||
|
||||
/// Truncate a [`Location`] to a byte offset in UTF-8 source code.
|
||||
fn truncate_utf8(location: Location, index: &[Vec<usize>], contents: &str) -> usize {
|
||||
if (location.row() - 1 == index.len() && location.column() == 0)
|
||||
|| (location.row() - 1 == index.len() - 1
|
||||
&& location.column() == index[location.row() - 1].len())
|
||||
{
|
||||
contents.len()
|
||||
} else {
|
||||
index[location.row() - 1][location.column()]
|
||||
}
|
||||
}
|
||||
|
||||
/// Truncate a [`Location`] to a byte offset in source code.
|
||||
fn truncate(location: Location, index: &Index, contents: &str) -> usize {
|
||||
match index {
|
||||
Index::Ascii(index) => truncate_ascii(location, index, contents),
|
||||
Index::Utf8(index) => truncate_utf8(location, index, contents),
|
||||
}
|
||||
}
|
||||
|
||||
impl<'a> Locator<'a> {
|
||||
pub fn new(contents: &'a str) -> Self {
|
||||
Locator {
|
||||
contents,
|
||||
rope: OnceCell::default(),
|
||||
index: OnceCell::new(),
|
||||
}
|
||||
}
|
||||
|
||||
fn get_or_init_rope(&self) -> &Rope {
|
||||
self.rope.get_or_init(|| Rope::from_str(self.contents))
|
||||
fn get_or_init_index(&self) -> &Index {
|
||||
self.index.get_or_init(|| index(self.contents))
|
||||
}
|
||||
|
||||
pub fn slice_source_code_at(&self, location: Location) -> Cow<'_, str> {
|
||||
let rope = self.get_or_init_rope();
|
||||
let offset = rope.line_to_char(location.row() - 1) + location.column();
|
||||
Cow::from(rope.slice(offset..))
|
||||
pub fn slice_source_code_until(&self, location: Location) -> &'a str {
|
||||
let index = self.get_or_init_index();
|
||||
let offset = truncate(location, index, self.contents);
|
||||
&self.contents[..offset]
|
||||
}
|
||||
|
||||
pub fn slice_source_code_until(&self, location: Location) -> Cow<'_, str> {
|
||||
let rope = self.get_or_init_rope();
|
||||
let offset = rope.line_to_char(location.row() - 1) + location.column();
|
||||
Cow::from(rope.slice(..offset))
|
||||
pub fn slice_source_code_at(&self, location: Location) -> &'a str {
|
||||
let index = self.get_or_init_index();
|
||||
let offset = truncate(location, index, self.contents);
|
||||
&self.contents[offset..]
|
||||
}
|
||||
|
||||
pub fn slice_source_code_range(&self, range: &Range) -> Cow<'_, str> {
|
||||
let rope = self.get_or_init_rope();
|
||||
let start = rope.line_to_char(range.location.row() - 1) + range.location.column();
|
||||
let end = rope.line_to_char(range.end_location.row() - 1) + range.end_location.column();
|
||||
Cow::from(rope.slice(start..end))
|
||||
pub fn slice_source_code_range(&self, range: &Range) -> &'a str {
|
||||
let index = self.get_or_init_index();
|
||||
let start = truncate(range.location, index, self.contents);
|
||||
let end = truncate(range.end_location, index, self.contents);
|
||||
&self.contents[start..end]
|
||||
}
|
||||
|
||||
pub fn partition_source_code_at(
|
||||
&self,
|
||||
outer: &Range,
|
||||
inner: &Range,
|
||||
) -> (Cow<'_, str>, Cow<'_, str>, Cow<'_, str>) {
|
||||
let rope = self.get_or_init_rope();
|
||||
let outer_start = rope.line_to_char(outer.location.row() - 1) + outer.location.column();
|
||||
let outer_end =
|
||||
rope.line_to_char(outer.end_location.row() - 1) + outer.end_location.column();
|
||||
let inner_start = rope.line_to_char(inner.location.row() - 1) + inner.location.column();
|
||||
let inner_end =
|
||||
rope.line_to_char(inner.end_location.row() - 1) + inner.end_location.column();
|
||||
) -> (&'a str, &'a str, &'a str) {
|
||||
let index = self.get_or_init_index();
|
||||
let outer_start = truncate(outer.location, index, self.contents);
|
||||
let outer_end = truncate(outer.end_location, index, self.contents);
|
||||
let inner_start = truncate(inner.location, index, self.contents);
|
||||
let inner_end = truncate(inner.end_location, index, self.contents);
|
||||
(
|
||||
Cow::from(rope.slice(outer_start..inner_start)),
|
||||
Cow::from(rope.slice(inner_start..inner_end)),
|
||||
Cow::from(rope.slice(inner_end..outer_end)),
|
||||
&self.contents[outer_start..inner_start],
|
||||
&self.contents[inner_start..inner_end],
|
||||
&self.contents[inner_end..outer_end],
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use rustpython_ast::Location;
|
||||
|
||||
use crate::source_code::locator::{index_ascii, index_utf8, truncate_ascii, truncate_utf8};
|
||||
|
||||
#[test]
|
||||
fn ascii_index() {
|
||||
let contents = "";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0]);
|
||||
|
||||
let contents = "x = 1";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0]);
|
||||
|
||||
let contents = "x = 1\n";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0, 6]);
|
||||
|
||||
let contents = "x = 1\r\n";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0, 7]);
|
||||
|
||||
let contents = "x = 1\ny = 2\nz = x + y\n";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0, 6, 12, 22]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn ascii_truncate() {
|
||||
let contents = "x = 1\ny = 2";
|
||||
let index = index_ascii(contents);
|
||||
|
||||
// First row.
|
||||
let loc = truncate_ascii(Location::new(1, 0), &index, contents);
|
||||
assert_eq!(loc, 0);
|
||||
|
||||
// Second row.
|
||||
let loc = truncate_ascii(Location::new(2, 0), &index, contents);
|
||||
assert_eq!(loc, 6);
|
||||
|
||||
// One-past-the-end.
|
||||
let loc = truncate_ascii(Location::new(3, 0), &index, contents);
|
||||
assert_eq!(loc, 11);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn utf8_index() {
|
||||
let contents = "";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 1);
|
||||
assert_eq!(index[0], Vec::<usize>::new());
|
||||
|
||||
let contents = "x = 1";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 1);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4]);
|
||||
|
||||
let contents = "x = 1\n";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 2);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4, 5]);
|
||||
assert_eq!(index[1], Vec::<usize>::new());
|
||||
|
||||
let contents = "x = 1\r\n";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 2);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4, 5]);
|
||||
assert_eq!(index[1], Vec::<usize>::new());
|
||||
|
||||
let contents = "x = 1\ny = 2\nz = x + y\n";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 4);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4, 5]);
|
||||
assert_eq!(index[1], [6, 7, 8, 9, 10, 11]);
|
||||
assert_eq!(index[2], [12, 13, 14, 15, 16, 17, 18, 19, 20, 21]);
|
||||
assert_eq!(index[3], Vec::<usize>::new());
|
||||
|
||||
let contents = "# \u{4e9c}\nclass Foo:\n \"\"\".\"\"\"";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 3);
|
||||
assert_eq!(index[0], [0, 1, 2, 5]);
|
||||
assert_eq!(index[1], [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]);
|
||||
assert_eq!(index[2], [17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn utf8_truncate() {
|
||||
let contents = "x = '☃'\ny = 2";
|
||||
let index = index_utf8(contents);
|
||||
|
||||
// First row.
|
||||
let loc = truncate_utf8(Location::new(1, 0), &index, contents);
|
||||
assert_eq!(loc, 0);
|
||||
|
||||
let loc = truncate_utf8(Location::new(1, 5), &index, contents);
|
||||
assert_eq!(loc, 5);
|
||||
assert_eq!(&contents[loc..], "☃'\ny = 2");
|
||||
|
||||
let loc = truncate_utf8(Location::new(1, 6), &index, contents);
|
||||
assert_eq!(loc, 8);
|
||||
assert_eq!(&contents[loc..], "'\ny = 2");
|
||||
|
||||
// Second row.
|
||||
let loc = truncate_utf8(Location::new(2, 0), &index, contents);
|
||||
assert_eq!(loc, 10);
|
||||
|
||||
// One-past-the-end.
|
||||
let loc = truncate_utf8(Location::new(3, 0), &index, contents);
|
||||
assert_eq!(loc, 15);
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -170,7 +170,7 @@ fn detect_quote(contents: &str, locator: &Locator) -> Option<Quote> {
|
|||
for (start, tok, end) in lexer::make_tokenizer(contents).flatten() {
|
||||
if let Tok::String { .. } = tok {
|
||||
let content = locator.slice_source_code_range(&Range::new(start, end));
|
||||
if let Some(pattern) = leading_quote(&content) {
|
||||
if let Some(pattern) = leading_quote(content) {
|
||||
if pattern.contains('\'') {
|
||||
return Some(Quote::Single);
|
||||
} else if pattern.contains('"') {
|
||||
|
|
|
|||
Loading…
Reference in New Issue