This adds a new `backend: internal | uv` option to the LSP
`FormatOptions` allowing users to perform document and range formatting
operations though uv. The idea here is to prototype a solution for users
to transition to a `uv format` command without encountering version
mismatches (and consequently, formatting differences) between the LSP's
version of `ruff` and uv's version of `ruff`.
The primarily alternative to this would be to use uv to discover the
`ruff` version used to start the LSP in the first place. However, this
would increase the scope of a minimal `uv format` command beyond "run a
formatter", and raise larger questions about how uv should be used to
coordinate toolchain discovery. I think those are good things to
explore, but I'm hesitant to let them block a `uv format`
implementation. Another downside of using uv to discover `ruff`, is that
it needs to be implemented _outside_ the LSP; e.g., we'd need to change
the instructions on how to run the LSP and implement it in each editor
integration, like the VS Code plugin.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR is a collaboration with @AlexWaygood from our pairing session
last Friday.
The main goal here is removing `ruff_linter::message::OldDiagnostic` in
favor of
using `ruff_db::diagnostic::Diagnostic` directly. This involved a few
major steps:
- Transferring the fields
- Transferring the methods and trait implementations, where possible
- Converting some constructor methods to free functions
- Moving the `SecondaryCode` struct
- Updating the method names
I'm hoping that some of the methods, especially those in the
`expect_ruff_*`
family, won't be necessary long-term, but I avoided trying to replace
them
entirely for now to keep the already-large diff a bit smaller.
### Related refactors
Alex and I noticed a few refactoring opportunities while looking at the
code,
specifically the very similar implementations for
`create_parse_diagnostic`,
`create_unsupported_syntax_diagnostic`, and
`create_semantic_syntax_diagnostic`.
We combined these into a single generic function, which I then copied
into
`ruff_linter::message` with some small changes and a TODO to combine
them in the
future.
I also deleted the `DisplayParseErrorType` and `TruncateAtNewline` types
for
reporting parse errors. These were added in #4124, I believe to work
around the
error messages from LALRPOP. Removing these didn't affect any tests, so
I think
they were unnecessary now that we fully control the error messages from
the
parser.
On a more minor note, I factored out some calls to the
`OldDiagnostic::filename`
(now `Diagnostic::expect_ruff_filename`) function to avoid repeatedly
allocating
`String`s in some places.
### Snapshot changes
The `show_statistics_syntax_errors` integration test changed because the
`OldDiagnostic::name` method used `syntax-error` instead of
`invalid-syntax`
like in ty. I think this (`--statistics`) is one of the only places we
actually
use this name for syntax errors, so I hope this is okay. An alternative
is to
use `syntax-error` in ty too.
The other snapshot changes are from removing this code, as discussed on
[Discord](https://discord.com/channels/1039017663004942429/1228460843033821285/1388252408848847069):
34052a1185/crates/ruff_linter/src/message/mod.rs (L128-L135)
I think both of these are technically breaking changes, but they only
affect
syntax errors and are very narrow in scope, while also pretty
substantially
simplifying the refactor, so I hope they're okay to include in a patch
release.
## Test plan
Existing tests, with the adjustments mentioned above
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Currently, the log messages emitted by the server includes multiple
information which isn't really required most of the time.
Here's the current format:
```
0.000755625s DEBUG main ruff_server::session::index::ruff_settings: Indexing settings for workspace: /Users/dhruv/playground/ruff
0.016334666s DEBUG ThreadId(10) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
0.019954541s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
0.020160416s TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
0.020209625s TRACE ruff:worker:0 request{id=1 method="textDocument/diagnostic"}: ruff_server::server::api: enter
0.020228166s DEBUG ruff:worker:0 request{id=1 method="textDocument/diagnostic"}: ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/test.py
0.020359833s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
```
This PR updates the following:
* Uses current timestamp (same as red-knot) for all log levels instead
of the uptime value
* Includes the target and thread names only at the trace level
What this means is that the message is reduced to only important
information at DEBUG level:
```
2025-02-26 11:35:02.198375000 DEBUG Indexing settings for workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:02.209933000 DEBUG Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
2025-02-26 11:35:02.217165000 INFO Registering workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:02.217631000 DEBUG Included path via `include`: /Users/dhruv/playground/ruff/lsp/test.py
2025-02-26 11:35:02.217684000 INFO Configuration file watcher successfully registered
```
while still showing the other information (thread names and target) at
trace level:
```
2025-02-26 11:35:27.819617000 DEBUG main ruff_server::session::index::ruff_settings: Indexing settings for workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:27.830500000 DEBUG ThreadId(11) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
2025-02-26 11:35:27.837212000 INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:27.837714000 TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
2025-02-26 11:35:27.838019000 INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
2025-02-26 11:35:27.838084000 TRACE ruff:worker:1 request{id=1 method="textDocument/diagnostic"}: ruff_server::server::api: enter
2025-02-26 11:35:27.838205000 DEBUG ruff:worker:1 request{id=1 method="textDocument/diagnostic"}: ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/test.py
```
## Summary
[Internal design
document](https://www.notion.so/astral-sh/In-editor-settings-19e48797e1ca807fa8c2c91b689d9070?pvs=4)
This PR expands `ruff.configuration` to allow inline configuration
directly in the editor. For example:
```json
{
"ruff.configuration": {
"line-length": 100,
"lint": {
"unfixable": ["F401"],
"flake8-tidy-imports": {
"banned-api": {
"typing.TypedDict": {
"msg": "Use `typing_extensions.TypedDict` instead"
}
}
}
},
"format": {
"quote-style": "single"
}
}
}
```
This means that now `ruff.configuration` accepts either a path to
configuration file or the raw config itself. It's _mostly_ similar to
`--config` with one difference that's highlighted in the following
section. So, it can be said that the format of `ruff.configuration` when
provided the config map is same as the one on the [playground] [^1].
## Limitations
<details><summary><b>Casing (<code>kebab-case</code> v/s/
<code>camelCase</code>)</b></summary>
<p>
The config keys needs to be in `kebab-case` instead of `camelCase` which
is being used for other settings in the editor.
This could be a bit confusing. For example, the `line-length` option can
be set directly via an editor setting or can be configured via
`ruff.configuration`:
```json
{
"ruff.configuration": {
"line-length": 100
},
"ruff.lineLength": 120
}
```
#### Possible solution
We could use feature flag with [conditional
compilation](https://doc.rust-lang.org/reference/conditional-compilation.html#the-cfg_attr-attribute)
to indicate that when used in `ruff_server`, we need the `Options`
fields to be renamed as `camelCase` while for other crates it needs to
be renamed as `kebab-case`. But, this might not work very easily because
it will require wrapping the `Options` struct and create two structs in
which we'll have to add `#[cfg_attr(...)]` because otherwise `serde`
will complain:
```
error: duplicate serde attribute `rename_all`
--> crates/ruff_workspace/src/options.rs:43:38
|
43 | #[cfg_attr(feature = "editor", serde(rename_all = "camelCase"))]
| ^^^^^^^^^^
```
</p>
</details>
<details><summary><b>Nesting (flat v/s nested keys)</b></summary>
<p>
This is the major difference between `--config` flag on the command-line
v/s `ruff.configuration` and it makes it such that `ruff.configuration`
has same value format as [playground] [^1].
The config keys needs to be split up into keys which can result in
nested structure instead of flat structure:
So, the following **won't work**:
```json
{
"ruff.configuration": {
"format.quote-style": "single",
"lint.flake8-tidy-imports.banned-api.\"typing.TypedDict\".msg": "Use `typing_extensions.TypedDict` instead"
}
}
```
But, instead it would need to be split up like the following:
```json
{
"ruff.configuration": {
"format": {
"quote-style": "single"
},
"lint": {
"flake8-tidy-imports": {
"banned-api": {
"typing.TypedDict": {
"msg": "Use `typing_extensions.TypedDict` instead"
}
}
}
}
}
}
```
#### Possible solution (1)
The way we could solve this and make it same as `--config` would be to
add a manual logic of converting the JSON map into an equivalent TOML
string which would be then parsed into `Options`.
So, the following JSON map:
```json
{ "lint.flake8-tidy-imports": { "banned-api": {"\"typing.TypedDict\".msg": "Use typing_extensions.TypedDict instead"}}}
```
would need to be converted into the following TOML string:
```toml
lint.flake8-tidy-imports = { banned-api = { "typing.TypedDict".msg = "Use typing_extensions.TypedDict instead" } }
```
by recursively convering `"key": value` into `key = value` which is to
remove the quotes from key and replacing `:` with `=`.
#### Possible solution (2)
Another would be to just accept `Map<String, String>` strictly and
convert it into `key = value` and then parse it as a TOML string. This
would also match `--config` but quotes might become a nuisance because
JSON only allows double quotes and so it'll require escaping any inner
quotes or use single quotes.
</p>
</details>
## Test Plan
### VS Code
**Requires https://github.com/astral-sh/ruff-vscode/pull/702**
**`settings.json`**:
```json
{
"ruff.lint.extendSelect": ["TID"],
"ruff.configuration": {
"line-length": 50,
"format": {
"quote-style": "single"
},
"lint": {
"unfixable": ["F401"],
"flake8-tidy-imports": {
"banned-api": {
"typing.TypedDict": {
"msg": "Use `typing_extensions.TypedDict` instead"
}
}
}
}
}
}
```
Following video showcases me doing the following:
1. Check diagnostics that it includes `TID`
2. Run `Ruff: Fix all auto-fixable problems` to test `unfixable`
3. Run `Format: Document` to test `line-length` and `quote-style`
https://github.com/user-attachments/assets/0a38176f-3fb0-4960-a213-73b2ea5b1180
### Neovim
**`init.lua`**:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
lint = {
extendSelect = { 'TID' },
},
configuration = {
['line-length'] = 50,
format = {
['quote-style'] = 'single',
},
lint = {
unfixable = { 'F401' },
['flake8-tidy-imports'] = {
['banned-api'] = {
['typing.TypedDict'] = {
msg = 'Use typing_extensions.TypedDict instead',
},
},
},
},
},
},
},
}
```
Same steps as in the VS Code test:
https://github.com/user-attachments/assets/cfe49a9b-9a89-43d7-94f2-7f565d6e3c9d
## Documentation Preview
https://github.com/user-attachments/assets/e0062f58-6ec8-4e01-889d-fac76fd8b3c7
[playground]: https://play.ruff.rs
[^1]: This has one advantage that the value can be copy-pasted directly
into the playground
## Summary
This PR updates the language server to avoid indexing the workspace for
single-file mode.
**What's a single-file mode?**
When a user opens the file directly in an editor, and not the folder
that represents the workspace, the editor usually can't determine the
workspace root. This means that during initializing the server, the
`workspaceFolders` field will be empty / nil.
Now, in this case, the server defaults to using the current working
directory which is a reasonable default assuming that the directory
would point to the one where this open file is present. This would allow
the server to index the directory itself for any config file, if
present.
It turns out that in VS Code the current working directory in the above
scenario is the system root directory `/` and so the server will try to
index the entire root directory which would take a lot of time. This is
the issue as described in
https://github.com/astral-sh/ruff-vscode/issues/627. To reproduce, refer
https://github.com/astral-sh/ruff-vscode/issues/627#issuecomment-2401440767.
This PR updates the indexer to avoid traversing the workspace to read
any config file that might be present. The first commit
(8dd2a31eef)
refactors the initialization and introduces two structs `Workspaces` and
`Workspace`. The latter struct includes a field to determine whether
it's the default workspace. The second commit
(61fc39bdb6)
utilizes this field to avoid traversing.
Closes: #11366
## Editor behavior
This is to document the behavior as seen in different editors. The test
scenario used has the following directory tree structure:
```
.
├── nested
│ ├── nested.py
│ └── pyproject.toml
└── test.py
```
where, the contents of the files are:
**test.py**
```py
import os
```
**nested/nested.py**
```py
import os
import math
```
**nested/pyproject.toml**
```toml
[tool.ruff.lint]
select = ["I"]
```
Steps:
1. Open `test.py` directly in the editor
2. Validate that it raises the `F401` violation
3. Open `nested/nested.py` in the same editor instance
4. This file would raise only `I001` if the `nested/pyproject.toml` was
indexed
### VS Code
When (1) is done from above, the current working directory is `/` which
means the server will try to index the entire system to build up the
settings index. This will include the `nested/pyproject.toml` file as
well. This leads to bad user experience because the user would need to
wait for minutes for the server to finish indexing.
This PR avoids that by not traversing the workspace directory in
single-file mode. But, in VS Code, this means that per (4), the file
wouldn't raise `I001` but only raise two `F401` violations because the
`nested/pyproject.toml` was never resolved.
One solution here would be to fix this in the extension itself where we
would detect this scenario and pass in the workspace directory that is
the one containing this open file in (1) above.
### Neovim
**tl;dr** it works as expected because the client considers the presence
of certain files (depending on the server) as the root of the workspace.
For Ruff, they are `pyproject.toml`, `ruff.toml`, and `.ruff.toml`. This
means that the client notifies us as the user moves between single-file
mode and workspace mode.
https://github.com/astral-sh/ruff/pull/13770#issuecomment-2416608055
### Helix
Same as Neovim, additional context in
https://github.com/astral-sh/ruff/pull/13770#issuecomment-2417362097
### Sublime Text
**tl;dr** It works similar to VS Code except that the current working
directory of the current process is different and thus the config file
is never read. So, the behavior remains unchanged with this PR.
https://github.com/astral-sh/ruff/pull/13770#issuecomment-2417362097
### Zed
Zed seems to be starting a separate language server instance for each
file when the editor is running in a single-file mode even though all
files have been opened in a single editor instance.
(Separated the logs into sections separated by a single blank line
indicating 3 different server instances that the editor started for 3
files.)
```
0.000053375s INFO main ruff_server::server: No workspace settings found for file:///Users/dhruv/projects/ruff-temp, using default settings
0.009448792s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/projects/ruff-temp
0.009906334s DEBUG ruff:main ruff_server::resolve: Included path via `include`: /Users/dhruv/projects/ruff-temp/test.py
0.011775917s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
0.000060583s INFO main ruff_server::server: No workspace settings found for file:///Users/dhruv/projects/ruff-temp/nested, using default settings
0.010387125s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/projects/ruff-temp/nested
0.011061875s DEBUG ruff:main ruff_server::resolve: Included path via `include`: /Users/dhruv/projects/ruff-temp/nested/nested.py
0.011545208s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
0.000059125s INFO main ruff_server::server: No workspace settings found for file:///Users/dhruv/projects/ruff-temp/nested, using default settings
0.010857583s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/projects/ruff-temp/nested
0.011428958s DEBUG ruff:main ruff_server::resolve: Included path via `include`: /Users/dhruv/projects/ruff-temp/nested/other.py
0.011893792s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
```
## Test Plan
When using the `ruff` server from this PR, we see that the server starts
quickly as seen in the logs. Next, when I switch to the release binary,
it starts indexing the root directory.
For more details, refer to the "Editor Behavior" section above.
## Summary
This PR updates the server to build the settings index in parallel using
similar logic as `python_files_in_path`.
This should help with https://github.com/astral-sh/ruff/issues/11366 but
ideally we would want to build it lazily.
## Test Plan
`cargo insta test`
## Summary
Fixes#10968.
Fixes#11545.
The server's tracing system has been rewritten from the ground up. The
server now has trace level and log level settings which restrict the
tracing events and spans that get logged.
* A `logLevel` setting has been added, which lets a user set the log
level. By default, it is set to `"info"`.
* A `logFile` setting has also been added, which lets the user supply an
optional file to send tracing output (it does not have to exist as a
file yet). By default, if this is unset, tracing output will be sent to
`stderr`.
* A `$/setTrace` handler has also been added, and we also set the trace
level from the initialization options. For editors without direct
support for tracing, the environment variable `RUFF_TRACE` can override
the trace level.
* Small changes have been made to how we display tracing output. We no
longer use `tracing-tree`, and instead use
`tracing_subscriber::fmt::Layer` to format output. Thread names are now
included in traces, and I've made some adjustment to thread worker names
to be more useful.
## Test Plan
In VS Code, with `ruff.trace.server` set to its default value, no logs
from Ruff should appear.
After changing `ruff.trace.server` to either `messages` or `verbose`,
you should see log messages at `info` level or higher appear in Ruff's
output:
<img width="1005" alt="Screenshot 2024-06-10 at 10 35 04 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/6050d107-9815-4bd2-96d0-e86f096a57f5">
In Helix, by default, no logs from Ruff should appear.
To set the trace level in Helix, you'll need to modify your language
configuration as follows:
```toml
[language-server.ruff]
command = "/Users/jane/astral/ruff/target/debug/ruff"
args = ["server", "--preview"]
environment = { "RUFF_TRACE" = "messages" }
```
After doing this, logs of `info` level or higher should be visible in
Helix:
<img width="1216" alt="Screenshot 2024-06-10 at 10 39 26 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/8ff88692-d3f7-4fd1-941e-86fb338fcdcc">
You can use `:log-open` to quickly open the Helix log file.
In Neovim, by default, no logs from Ruff should appear.
To set the trace level in Neovim, you'll need to modify your
configuration as follows:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" }
}
```
You should see logs appear in `:LspLog` that look like the following:
<img width="1490" alt="Screenshot 2024-06-11 at 11 24 01 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/576cd5fa-03cf-477a-b879-b29a9a1200ff">
You can adjust `logLevel` and `logFile` in `settings`:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" },
settings = {
logLevel = "debug",
logFile = "your/log/file/path/log.txt"
}
}
```
The `logLevel` and `logFile` can also be set in Helix like so:
```toml
[language-server.ruff.config.settings]
logLevel = "debug"
logFile = "your/log/file/path/log.txt"
```
Even if this log file does not exist, it should now be created and
written to after running the server:
<img width="1148" alt="Screenshot 2024-06-10 at 10 43 44 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/ab533cf7-d5ac-4178-97f1-e56da17450dd">
## Summary
Closes https://github.com/astral-sh/ruff/issues/10858.
`ruff server` now supports `*.ipynb` (aka Jupyter Notebook) files.
Extensive internal changes have been made to facilitate this, which I've
done some work to contextualize with documentation and an pre-review
that highlights notable sections of the code.
`*.ipynb` cells should behave similarly to `*.py` documents, with one
major exception. The format command `ruff.applyFormat` will only apply
to the currently selected notebook cell - if you want to format an
entire notebook document, use `Format Notebook` from the VS Code context
menu.
## Test Plan
The VS Code extension does not yet have Jupyter Notebook support
enabled, so you'll first need to enable it manually. To do this,
checkout the `pre-release` branch and modify `src/common/server.ts` as
follows:
Before:

After:

I recommend testing this PR with large, complicated notebook files. I
used notebook files from [this popular
repository](https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks)
in my preliminary testing.
The main thing to test is ensuring that notebook cells behave the same
as Python documents, besides the aforementioned issue with
`ruff.applyFormat`. You should also test adding and deleting cells (in
particular, deleting all the code cells and ensure that doesn't break
anything), changing the kind of a cell (i.e. from markup -> code or vice
versa), and creating a new notebook file from scratch. Finally, you
should also test that source actions work as expected (and across the
entire notebook).
Note: `ruff.applyAutofix` and `ruff.applyOrganizeImports` are currently
broken for notebook files, and I suspect it has something to do with
https://github.com/astral-sh/ruff/issues/11248. Once this is fixed, I
will update the test plan accordingly.
---------
Co-authored-by: nolan <nolan.king90@gmail.com>
## Summary
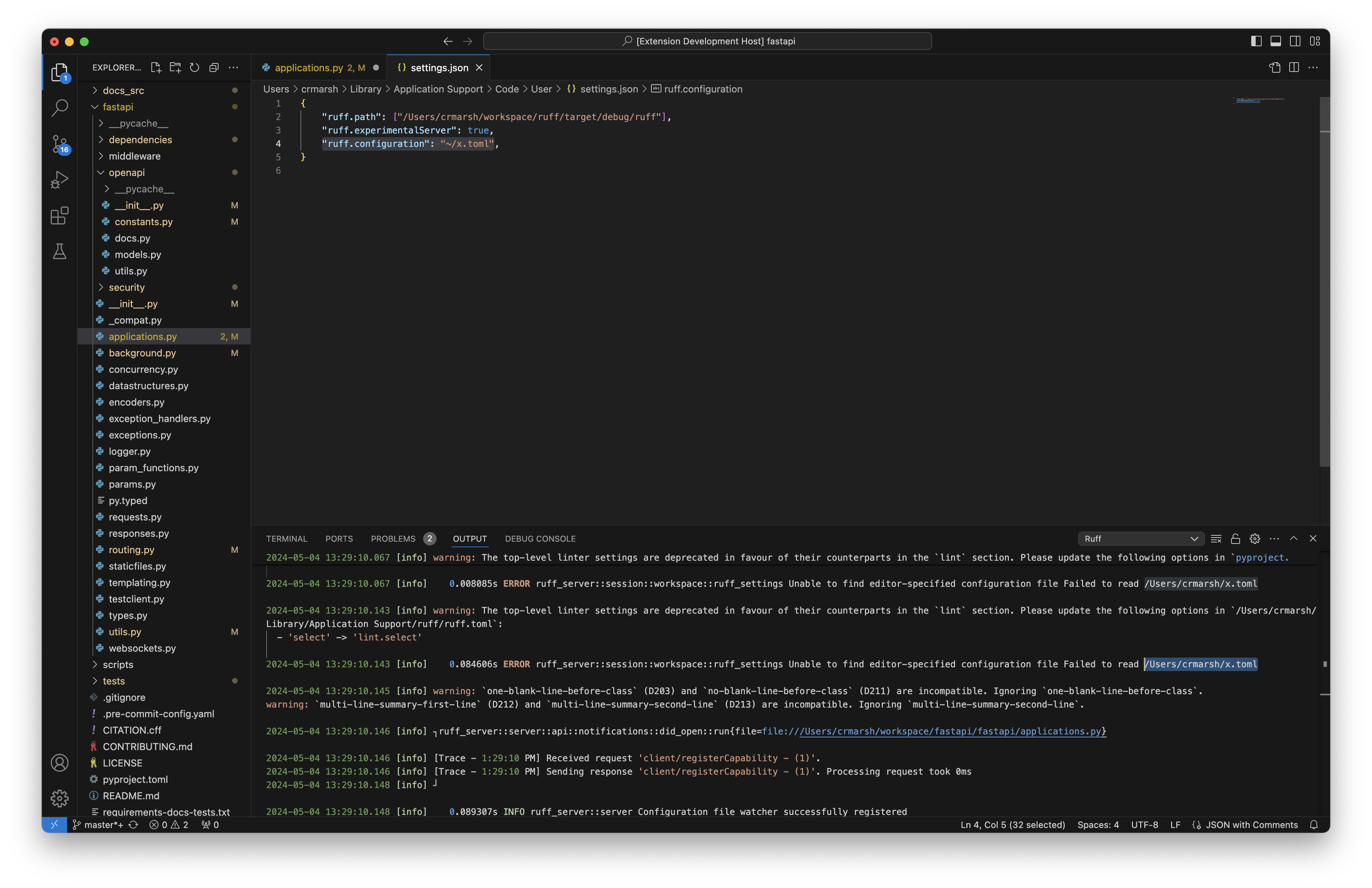
Users can now include tildes and environment variables in the provided
path, just like with `--config`.
Closes#11277.
## Test Plan
Set the configuration path to `"ruff.configuration": "~/x.toml"`;
verified that the server attempted to read from `/Users/crmarsh/x.toml`.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Add support for hover menu to ruff_server, as requested in
[10595](https://github.com/astral-sh/ruff/issues/10595).
Majority of new code is in hover.rs.
I reused the regex from ruff-lsp's implementation. Also reused the
format_rule_text function from ruff/src/commands/rule.rs
Added capability registration in server.rs, and added the handler to
api.rs.
## Test Plan
Tested in NVIM v0.10.0-dev-2582+g2a8cef6bd, configured with lspconfig
using the default options (other than cmd pointing to my test build,
with options "server" and "--preview"). OS: Ubuntu 24.04, kernel
6.8.0-22.
---------
Co-authored-by: Jane Lewis <me@jane.engineering>
## Summary
Configuration is no longer the property of a workspace but rather of
individual documents. Just like the Ruff CLI, each document is
configured based on the 'nearest' project configuration. See [the Ruff
documentation](https://docs.astral.sh/ruff/configuration/#config-file-discovery)
for more details.
To reduce the amount of times we resolve configuration for a file, we
have an index for each workspace that stores a reference-counted pointer
to a configuration for a given folder. If another file in the same
folder is opened, the configuration is simply re-used rather than us
re-resolving it.
## Guide for reviewing
The first commit is just the restructuring work, which adds some noise
to the diff. If you want to quickly understand what's actually changed,
I recommend looking at the two commits that come after it.
f7c073d441 makes configuration a property
of `DocumentController`/`DocumentRef`, moving it out of `Workspace`, and
it also sets up the `ConfigurationIndex`, though it doesn't implement
its key function, `get_or_insert`. In the commit after it,
fc35618f17, we implement `get_or_insert`.
## Test Plan
The best way to test this would be to ensure that the behavior matches
the Ruff CLI. Open a project with multiple configuration files (or add
them yourself), and then introduce problems in certain files that won't
show due to their configuration. Add those same problems to a section of
the project where those rules are run. Confirm that the lint rules are
run as expected with `ruff check`. Then, open your editor and confirm
that the diagnostics shown match the CLI output.
As an example - I have a workspace with two separate folders, `pandas`
and `scipy`. I created a `pyproject.toml` file in `pandas/pandas/io` and
a `ruff.toml` file in `pandas/pandas/api`. I changed the `select` and
`preview` settings in the sub-folder configuration files and confirmed
that these were reflected in the diagnostics. I also confirmed that this
did not change the diagnostics for the `scipy` folder whatsoever.
## Summary
I used `cargo-shear` (see
[tweet](https://twitter.com/boshen_c/status/1770106165923586395)) to
remove some unused dependencies that `cargo udeps` wasn't reporting.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
`cargo test`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR introduces the `ruff_server` crate and a new `ruff server`
command. `ruff_server` is a re-implementation of
[`ruff-lsp`](https://github.com/astral-sh/ruff-lsp), written entirely in
Rust. It brings significant performance improvements, much tighter
integration with Ruff, a foundation for supporting entirely new language
server features, and more!
This PR is an early version of `ruff_lsp` that we're calling the
**pre-release** version. Anyone is more than welcome to use it and
submit bug reports for any issues they encounter - we'll have some
documentation on how to set it up with a few common editors, and we'll
also provide a pre-release VSCode extension for those interested.
This pre-release version supports:
- **Diagnostics for `.py` files**
- **Quick fixes**
- **Full-file formatting**
- **Range formatting**
- **Multiple workspace folders**
- **Automatic linter/formatter configuration** - taken from any
`pyproject.toml` files in the workspace.
Many thanks to @MichaReiser for his [proof-of-concept
work](https://github.com/astral-sh/ruff/pull/7262), which was important
groundwork for making this PR possible.
## Architectural Decisions
I've made an executive choice to go with `lsp-server` as a base
framework for the LSP, in favor of `tower-lsp`. There were several
reasons for this:
1. I would like to avoid `async` in our implementation. LSPs are mostly
computationally bound rather than I/O bound, and `async` adds a lot of
complexity to the API, while also making harder to reason about
execution order. This leads into the second reason, which is...
2. Any handlers that mutate state should be blocking and run in the
event loop, and the state should be lock-free. This is the approach that
`rust-analyzer` uses (also with the `lsp-server`/`lsp-types` crates as a
framework), and it gives us assurances about data mutation and execution
order. `tower-lsp` doesn't support this, which has caused some
[issues](https://github.com/ebkalderon/tower-lsp/issues/284) around data
races and out-of-order handler execution.
3. In general, I think it makes sense to have tight control over
scheduling and the specifics of our implementation, in exchange for a
slightly higher up-front cost of writing it ourselves. We'll be able to
fine-tune it to our needs and support future LSP features without
depending on an upstream maintainer.
## Test Plan
The pre-release of `ruff_server` will have snapshot tests for common
document editing scenarios. An expanded test suite is on the roadmap for
future version of `ruff_server`.