## Summary
Follow-up to #11902
This PR simplifies the `LinterResult` struct by avoiding the generic and
not store the `ParseError`.
This is possible because the callers already have access to the
`ParseError` via the `Parsed` output. This also means that we can
simplify the return type of `check_path` and avoid the generic `T` on
`LinterResult`.
## Test Plan
`cargo insta test`
## Summary
I look at the token stream a lot, not specifically in the playground but
in the terminal output and it's annoying to scroll a lot to find
specific location. Most of the information is also redundant.
The final format we end up with is: `<kind> <range> (flags = ...)` e.g.,
`String 0..4 (flags = BYTE_STRING)` where the flags part is only
populated if there are any flags set.
## Summary
This PR updates the parser to remove building the `CommentRanges` and
instead it'll be built by the linter and the formatter when it's
required.
For the linter, it'll be built and owned by the `Indexer` while for the
formatter it'll be built from the `Tokens` struct and passed as an
argument.
## Test Plan
`cargo insta test`
## Summary
This PR updates the entire parser stack in multiple ways:
### Make the lexer lazy
* https://github.com/astral-sh/ruff/pull/11244
* https://github.com/astral-sh/ruff/pull/11473
Previously, Ruff's lexer would act as an iterator. The parser would
collect all the tokens in a vector first and then process the tokens to
create the syntax tree.
The first task in this project is to update the entire parsing flow to
make the lexer lazy. This includes the `Lexer`, `TokenSource`, and
`Parser`. For context, the `TokenSource` is a wrapper around the `Lexer`
to filter out the trivia tokens[^1]. Now, the parser will ask the token
source to get the next token and only then the lexer will continue and
emit the token. This means that the lexer needs to be aware of the
"current" token. When the `next_token` is called, the current token will
be updated with the newly lexed token.
The main motivation to make the lexer lazy is to allow re-lexing a token
in a different context. This is going to be really useful to make the
parser error resilience. For example, currently the emitted tokens
remains the same even if the parser can recover from an unclosed
parenthesis. This is important because the lexer emits a
`NonLogicalNewline` in parenthesized context while a normal `Newline` in
non-parenthesized context. This different kinds of newline is also used
to emit the indentation tokens which is important for the parser as it's
used to determine the start and end of a block.
Additionally, this allows us to implement the following functionalities:
1. Checkpoint - rewind infrastructure: The idea here is to create a
checkpoint and continue lexing. At a later point, this checkpoint can be
used to rewind the lexer back to the provided checkpoint.
2. Remove the `SoftKeywordTransformer` and instead use lookahead or
speculative parsing to determine whether a soft keyword is a keyword or
an identifier
3. Remove the `Tok` enum. The `Tok` enum represents the tokens emitted
by the lexer but it contains owned data which makes it expensive to
clone. The new `TokenKind` enum just represents the type of token which
is very cheap.
This brings up a question as to how will the parser get the owned value
which was stored on `Tok`. This will be solved by introducing a new
`TokenValue` enum which only contains a subset of token kinds which has
the owned value. This is stored on the lexer and is requested by the
parser when it wants to process the data. For example:
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L1260-L1262)
[^1]: Trivia tokens are `NonLogicalNewline` and `Comment`
### Remove `SoftKeywordTransformer`
* https://github.com/astral-sh/ruff/pull/11441
* https://github.com/astral-sh/ruff/pull/11459
* https://github.com/astral-sh/ruff/pull/11442
* https://github.com/astral-sh/ruff/pull/11443
* https://github.com/astral-sh/ruff/pull/11474
For context,
https://github.com/RustPython/RustPython/pull/4519/files#diff-5de40045e78e794aa5ab0b8aacf531aa477daf826d31ca129467703855408220
added support for soft keywords in the parser which uses infinite
lookahead to classify a soft keyword as a keyword or an identifier. This
is a brilliant idea as it basically wraps the existing Lexer and works
on top of it which means that the logic for lexing and re-lexing a soft
keyword remains separate. The change here is to remove
`SoftKeywordTransformer` and let the parser determine this based on
context, lookahead and speculative parsing.
* **Context:** The transformer needs to know the position of the lexer
between it being at a statement position or a simple statement position.
This is because a `match` token starts a compound statement while a
`type` token starts a simple statement. **The parser already knows
this.**
* **Lookahead:** Now that the parser knows the context it can perform
lookahead of up to two tokens to classify the soft keyword. The logic
for this is mentioned in the PR implementing it for `type` and `match
soft keyword.
* **Speculative parsing:** This is where the checkpoint - rewind
infrastructure helps. For `match` soft keyword, there are certain cases
for which we can't classify based on lookahead. The idea here is to
create a checkpoint and keep parsing. Based on whether the parsing was
successful and what tokens are ahead we can classify the remaining
cases. Refer to #11443 for more details.
If the soft keyword is being parsed in an identifier context, it'll be
converted to an identifier and the emitted token will be updated as
well. Refer
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L487-L491).
The `case` soft keyword doesn't require any special handling because
it'll be a keyword only in the context of a match statement.
### Update the parser API
* https://github.com/astral-sh/ruff/pull/11494
* https://github.com/astral-sh/ruff/pull/11505
Now that the lexer is in sync with the parser, and the parser helps to
determine whether a soft keyword is a keyword or an identifier, the
lexer cannot be used on its own. The reason being that it's not
sensitive to the context (which is correct). This means that the parser
API needs to be updated to not allow any access to the lexer.
Previously, there were multiple ways to parse the source code:
1. Passing the source code itself
2. Or, passing the tokens
Now that the lexer and parser are working together, the API
corresponding to (2) cannot exists. The final API is mentioned in this
PR description: https://github.com/astral-sh/ruff/pull/11494.
### Refactor the downstream tools (linter and formatter)
* https://github.com/astral-sh/ruff/pull/11511
* https://github.com/astral-sh/ruff/pull/11515
* https://github.com/astral-sh/ruff/pull/11529
* https://github.com/astral-sh/ruff/pull/11562
* https://github.com/astral-sh/ruff/pull/11592
And, the final set of changes involves updating all references of the
lexer and `Tok` enum. This was done in two-parts:
1. Update all the references in a way that doesn't require any changes
from this PR i.e., it can be done independently
* https://github.com/astral-sh/ruff/pull/11402
* https://github.com/astral-sh/ruff/pull/11406
* https://github.com/astral-sh/ruff/pull/11418
* https://github.com/astral-sh/ruff/pull/11419
* https://github.com/astral-sh/ruff/pull/11420
* https://github.com/astral-sh/ruff/pull/11424
2. Update all the remaining references to use the changes made in this
PR
For (2), there were various strategies used:
1. Introduce a new `Tokens` struct which wraps the token vector and add
methods to query a certain subset of tokens. These includes:
1. `up_to_first_unknown` which replaces the `tokenize` function
2. `in_range` and `after` which replaces the `lex_starts_at` function
where the former returns the tokens within the given range while the
latter returns all the tokens after the given offset
2. Introduce a new `TokenFlags` which is a set of flags to query certain
information from a token. Currently, this information is only limited to
any string type token but can be expanded to include other information
in the future as needed. https://github.com/astral-sh/ruff/pull/11578
3. Move the `CommentRanges` to the parsed output because this
information is common to both the linter and the formatter. This removes
the need for `tokens_and_ranges` function.
## Test Plan
- [x] Update and verify the test snapshots
- [x] Make sure the entire test suite is passing
- [x] Make sure there are no changes in the ecosystem checks
- [x] Run the fuzzer on the parser
- [x] Run this change on dozens of open-source projects
### Running this change on dozens of open-source projects
Refer to the PR description to get the list of open source projects used
for testing.
Now, the following tests were done between `main` and this branch:
1. Compare the output of `--select=E999` (syntax errors)
2. Compare the output of default rule selection
3. Compare the output of `--select=ALL`
**Conclusion: all output were same**
## What's next?
The next step is to introduce re-lexing logic and update the parser to
feed the recovery information to the lexer so that it can emit the
correct token. This moves us one step closer to having error resilience
in the parser and provides Ruff the possibility to lint even if the
source code contains syntax errors.
## Summary
Alternative to #11237
This PR adds a new `Tokens` struct which is a newtype wrapper around a
vector of lexer output. This allows us to add a `kinds` method which
returns an iterator over the corresponding `TokenKind`. This iterator is
implemented as a separate `TokenKindIter` struct to allow using the type
and provide additional methods like `peek` directly on the iterator.
This exposes the linter to access the stream of `TokenKind` instead of
`Tok`.
Edit: I've made the necessary downstream changes and plan to merge the
entire stack at once.
## Summary
This PR removes the `ImportMap` implementation and all its routing
through ruff.
The import map was added in https://github.com/astral-sh/ruff/pull/3243
but we then never ended up using it to do cross file analysis.
We are now working on adding multifile analysis to ruff, and revisit
import resolution as part of it.
```
hyperfine --warmup 10 --runs 20 --setup "./target/release/ruff clean" \
"./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I" \
"./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 37.6 ms ± 0.9 ms [User: 52.2 ms, System: 63.7 ms]
Range (min … max): 35.8 ms … 39.8 ms 20 runs
Benchmark 2: ./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 36.0 ms ± 0.7 ms [User: 50.3 ms, System: 58.4 ms]
Range (min … max): 34.5 ms … 37.6 ms 20 runs
Summary
./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I ran
1.04 ± 0.03 times faster than ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
```
I suspect that the performance improvement should even be more
significant for users that otherwise don't have any diagnostics.
```
hyperfine --warmup 10 --runs 20 --setup "cd ../ecosystem/airflow && ../../ruff/target/release/ruff clean" \
"./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I" \
"./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 53.7 ms ± 1.8 ms [User: 68.4 ms, System: 63.0 ms]
Range (min … max): 51.1 ms … 58.7 ms 20 runs
Benchmark 2: ./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 50.8 ms ± 1.4 ms [User: 50.7 ms, System: 60.9 ms]
Range (min … max): 48.5 ms … 55.3 ms 20 runs
Summary
./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I ran
1.06 ± 0.05 times faster than ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
```
## Test Plan
`cargo test`
## Summary
This PR updates the playground to display the AST even if it contains a
syntax error. This could be useful for development and also to give a
quick preview of what error recovery looks like.
Note that not all recovery is correct but this allows us to iterate
quickly on what can be improved.
## Test Plan
Build the playground locally and test it.
<img width="1688" alt="Screenshot 2024-04-25 at 21 02 22"
src="https://github.com/astral-sh/ruff/assets/67177269/2b94934c-4f2c-4a9a-9693-3d8460ed9d0b">
Fixes#8368
Fixes https://github.com/astral-sh/ruff/issues/9186
## Summary
Arbitrary TOML strings can be provided via the command-line to override
configuration options in `pyproject.toml` or `ruff.toml`. As an example:
to run over typeshed and respect typeshed's `pyproject.toml`, but
override a specific isort setting and enable an additional pep8-naming
setting:
```
cargo run -- check ../typeshed --no-cache --config ../typeshed/pyproject.toml --config "lint.isort.combine-as-imports=false" --config "lint.extend-select=['N801']"
```
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Zanie Blue <contact@zanie.dev>
## Summary
Adds an additional warning macro (we should consolidate these later)
that shows a warning once based on the content of the warning itself.
This is less efficient than `warn_user_once!` and `warn_user_by_id!`,
but this is so expensive that it doesn't matter at all.
Applies this macro to the various warnings for the v0.2.0 release, and
also includes the filename in said warnings, so the FastAPI case is now:
```text
warning: The top-level linter settings are deprecated in favour of their counterparts in the `lint` section. Please update the following options in /Users/crmarsh/workspace/fastapi/pyproject.toml:
- 'ignore' -> 'lint.ignore'
- 'select' -> 'lint.select'
- 'isort' -> 'lint.isort'
- 'pyupgrade' -> 'lint.pyupgrade'
- 'per-file-ignores' -> 'lint.per-file-ignores'
```
---------
Co-authored-by: Zanie <contact@zanie.dev>
## Summary
This PR modifies our `Cargo.toml` files to use workspace dependencies
for _all_ dependencies, rather than the status quo of sporadically
trying to use workspace dependencies for those dependencies that are
used across multiple crates. I find the current situation more confusing
and harder to manage, since we have a mix of workspace and crate-local
dependencies, whereas this setup consistently uses the same approach for
all dependencies.
## Summary
I always found it odd that we had to pass this in, since it's really
higher-level context for the error. The awkwardness is further evidenced
by the fact that we pass in fake values everywhere (even outside of
tests). The source path isn't actually used to display the error; it's
only accessed elsewhere to _re-display_ the error in certain cases. This
PR modifies to instead pass the path directly in those cases.
## Summary
This PR adds some helper structs to the linter paths to enable passing
in the pre-computed tokens and parsed source code during benchmarking,
to remove lexing and parsing from the overall linter benchmark
measurement. We already remove parsing for the formatter, and we have
separate benchmarks for the lexer and the parser, so this should make it
much easier to measure linter performance changes.
Bumps [wasm-bindgen-test](https://github.com/rustwasm/wasm-bindgen) from
0.3.38 to 0.3.39.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/rustwasm/wasm-bindgen/commits">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[serde-wasm-bindgen](https://github.com/RReverser/serde-wasm-bindgen)
from 0.6.1 to 0.6.3.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="e65f027ed7"><code>e65f027</code></a>
chore: Release</li>
<li><a
href="0cf8879399"><code>0cf8879</code></a>
Fix find-replace typo in docs</li>
<li><a
href="ff83666343"><code>ff83666</code></a>
Fix doc annotation</li>
<li><a
href="014e415d41"><code>014e415</code></a>
chore: Release</li>
<li><a
href="34aab01dcb"><code>34aab01</code></a>
Use Wasm target for docs.rs</li>
<li><a
href="455d55645f"><code>455d556</code></a>
More consistent docs + hide internal fields</li>
<li><a
href="ce7669e1d1"><code>ce7669e</code></a>
Use field indices for struct deserialization</li>
<li><a
href="a7e4c5b5aa"><code>a7e4c5b</code></a>
Bump deps</li>
<li><a
href="b4b4965c63"><code>b4b4965</code></a>
Don't use --profiling for benchmarks</li>
<li><a
href="3dfe7271ba"><code>3dfe727</code></a>
Speed up integer decoding</li>
<li>Additional commits viewable in <a
href="https://github.com/RReverser/serde-wasm-bindgen/compare/v0.6.1...v0.6.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [js-sys](https://github.com/rustwasm/wasm-bindgen) from 0.3.64 to
0.3.65.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/rustwasm/wasm-bindgen/commits">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Update to [Rust
1.74](https://blog.rust-lang.org/2023/11/16/Rust-1.74.0.html) and use
the new clippy lints table.
The update itself introduced a new clippy lint about superfluous hashes
in raw strings, which got removed.
I moved our lint config from `rustflags` to the newly stabilized
[workspace.lints](https://doc.rust-lang.org/stable/cargo/reference/workspaces.html#the-lints-table).
One consequence is that we have to `unsafe_code = "warn"` instead of
"forbid" because the latter now actually bans unsafe code:
```
error[E0453]: allow(unsafe_code) incompatible with previous forbid
--> crates/ruff_source_file/src/newlines.rs:62:17
|
62 | #[allow(unsafe_code)]
| ^^^^^^^^^^^ overruled by previous forbid
|
= note: `forbid` lint level was set on command line
```
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR renames the `tab-size` configuration option to `indent-width` to
express that the formatter uses the option to determine the indentation
width AND as tab width.
I first preferred naming the option `tab-width` but then decided to go
with `indent-width` because:
* It aligns with the `indent-style` option
* It would allow us to write a lint rule that asserts that each
indentation uses `indent-width` spaces.
Closes#7643
## Test Plan
Added integration test
See the provided breaking changes note for details.
Removes support for the deprecated `--format`option in the `ruff check`
CLI, `format` inference as `output-format` in the configuration file,
and the `RUFF_FORMAT` environment variable.
The error message for use of `format` in the configuration file could be
better, but would require some awkward serde wrappers and it seems hard
to present the correct schema to the user still.
Closes https://github.com/astral-sh/ruff/issues/7572
Drops formatting specific rules from the default rule set as they
conflict with formatters in general (and in particular, conflict with
our formatter). Most of these rules are in preview, but the removal of
`line-too-long` and `mixed-spaces-and-tabs` is a change to the stable
rule set.
## Example
The following no longer raises `E501`
```
echo "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx = 1" | ruff check -
```
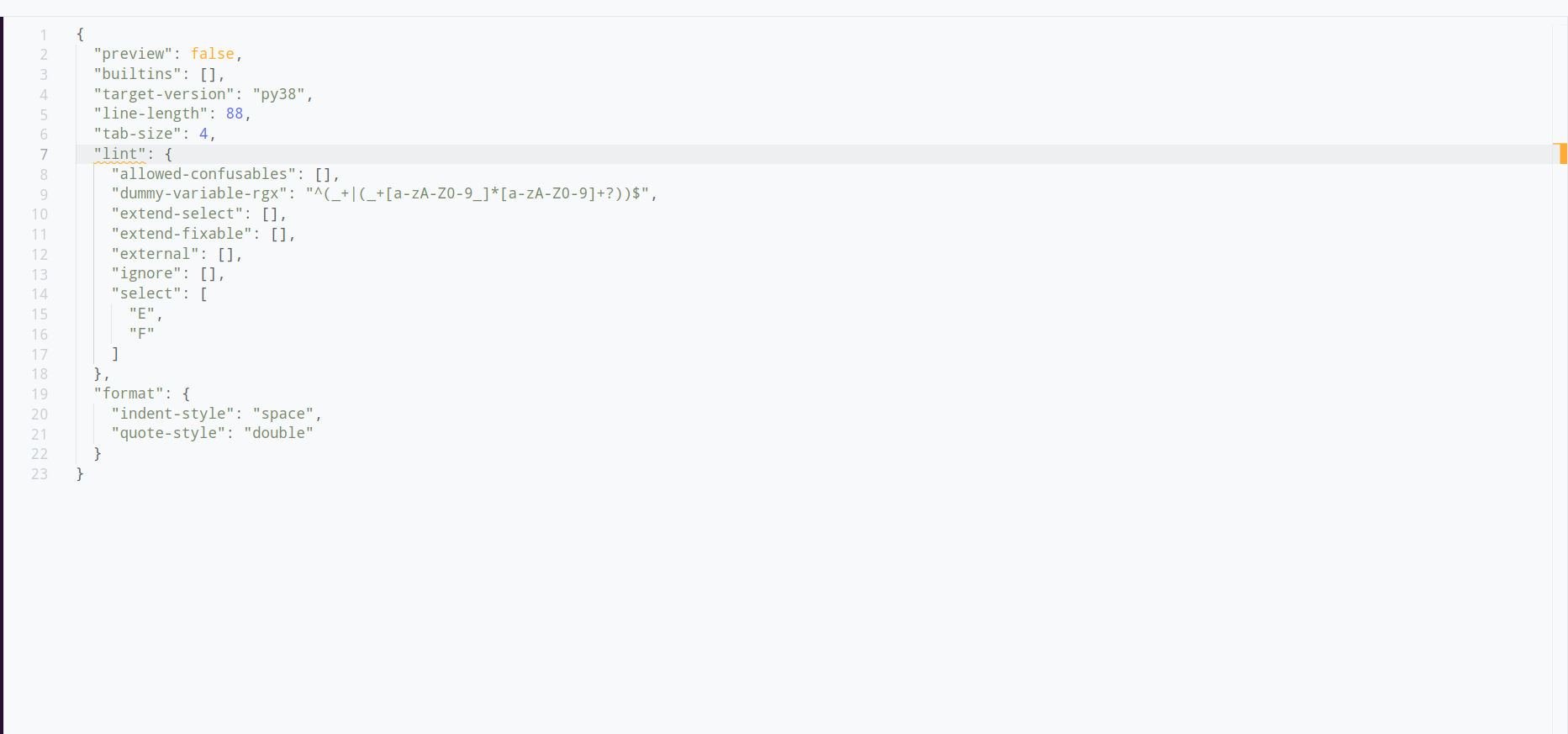
## Summary
This PR adds a new `lint` section to the configuration that groups all linter-specific settings. The existing top-level configurations continue to work without any warning because the `lint.*` settings are experimental.
The configuration merges the top level and `lint.*` settings where the settings in `lint` have higher precedence (override the top-level settings). The reasoning behind this is that the settings in `lint.` are more specific and more specific settings should override less specific settings.
I decided against showing the new `lint.*` options on our website because it would make the page extremely long (it's technically easy to do, just attribute `lint` with `[option_group`]). We may want to explore adding an `alias` field to the `option` attribute and show the alias on the website along with its regular name.
## Test Plan
* I added new integration tests
* I verified that the generated `options.md` is identical
* Verified the default settings in the playground
I got confused and refactored a bit, now the naming should be more
consistent. This is the basis for the range formatting work.
Chages:
* `format_module` -> `format_module_source` (format a string)
* `format_node` -> `format_module_ast` (format a program parsed into an
AST)
* Added `parse_ok_tokens` that takes `Token` instead of `Result<Token>`
* Call the source code `source` consistently
* Added a `tokens_and_ranges` helper
* `python_ast` -> `module` (because that's the type)
## Summary
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR moves the `ResolverSettings` and `Settings` struct to `ruff_workspace`. `LinterSettings` remains in `ruff_linter` because it gets passed to lint rules, the `Checker` etc.
## Test Plan
`cargo test`
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR extracts the linter-specific settings into a new `LinterSettings` struct and adds it as a `linter` field to the `Settings` struct. This is in preparation for moving `Settings` from `ruff_linter` to `ruff_workspace`
## Test Plan
`cargo test`
## Summary
The tokenizer was split into a forward and a backwards tokenizer. The
backwards tokenizer uses the same names as the forwards ones (e.g.
`next_token`). The backwards tokenizer gets the comment ranges that we
already built to skip comments.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Per discussion at https://github.com/astral-sh/ruff/discussions/6998
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Adds a `--preview` and `--no-preview` option to the CLI for `ruff check`
and corresponding settings. The CLI options are hidden for now.
Available in the settings as `preview = true` or `preview = false`.
Does not include environment variable configuration, although we may add
it in the future.
## Test Plan
<!-- How was it tested? -->
`cargo build`
Future work will build on this setting, such as toggling the mode during
a test.
## Summary
I think it makes sense for `PythonVersion::default()` to return our
minimum-supported non-EOL version.
## Test Plan
`cargo test`
---------
Co-authored-by: Zanie <contact@zanie.dev>
## Summary
Enable using the new `Mode::Jupyter` for the tokenizer/parser to parse
Jupyter line magic tokens.
The individual call to the lexer i.e., `lex_starts_at` done by various
rules should consider the context of the source code (is this content
from a Jupyter Notebook?). Thus, a new field `source_type` (of type
`PySourceType`) is added to `Checker` which is being passed around as an
argument to the relevant functions. This is then used to determine the
`Mode` for the lexer.
## Test Plan
Add new test cases to make sure that the magic statement is considered
while generating the diagnostic and autofix:
* For `I001`, if there's a magic statement in between two import blocks,
they should be sorted independently
fixes: #6090
**Summary** This adds the information whether we're in a .py python
source file or in a .pyi stub file to enable people working on #5822 and
related issues.
I'm not completely happy with `Default` for something that depends on
the input.
**Test Plan** None, this is currently unused, i'm leaving this to first
implementation of stub file specific formatting.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Right now, if we have two fixes that have an overlapping edit, but not
an _identical_ set of edits, they'll conflict, causing us to do another
linter traversal. Here, I've enabled the fixer to support partially
overlapping edits, which (as an example) let's us greatly reduce the
number of iterations required in the test suite.
The most common case here is that in which a bunch of edits need to
import some symbol, and then use that symbol, but in different ways. In
that case, all edits will have a common fix (to import the symbol), but
deviate in some way. With this change, we can do all of those edits in
one pass.
Note that the simplest way to enable this was to store sorted edits on
`Fix`. We don't allow modifying the edits on `Fix` once it's
constructed, so this is an easy change, and allows us to avoid a bunch
of clones and traversals later on.
Closes#5800.
## Summary
This PR adds a `logger-objects` setting that allows users to mark
specific symbols a `logging.Logger` objects. Currently, if a `logger` is
imported, we only flagged it as a `logging.Logger` if it comes exactly
from the `logging` module or is `flask.current_app.logger`.
This PR allows users to mark specific loggers, like
`logging_setup.logger`, to ensure that they're covered by the
`flake8-logging-format` rules and others.
For example, if you have a module `logging_setup.py` with the following
contents:
```python
import logging
logger = logging.getLogger(__name__)
```
Adding `"logging_setup.logger"` to `logger-objects` will ensure that
`logging_setup.logger` is treated as a `logging.Logger` object when
imported from other modules (e.g., `from logging_setup import logger`).
Closes https://github.com/astral-sh/ruff/issues/5694.
## Summary
Previously, `StmtIf` was defined recursively as
```rust
pub struct StmtIf {
pub range: TextRange,
pub test: Box<Expr>,
pub body: Vec<Stmt>,
pub orelse: Vec<Stmt>,
}
```
Every `elif` was represented as an `orelse` with a single `StmtIf`. This
means that this representation couldn't differentiate between
```python
if cond1:
x = 1
else:
if cond2:
x = 2
```
and
```python
if cond1:
x = 1
elif cond2:
x = 2
```
It also makes many checks harder than they need to be because we have to
recurse just to iterate over an entire if-elif-else and because we're
lacking nodes and ranges on the `elif` and `else` branches.
We change the representation to a flat
```rust
pub struct StmtIf {
pub range: TextRange,
pub test: Box<Expr>,
pub body: Vec<Stmt>,
pub elif_else_clauses: Vec<ElifElseClause>,
}
pub struct ElifElseClause {
pub range: TextRange,
pub test: Option<Expr>,
pub body: Vec<Stmt>,
}
```
where `test: Some(_)` represents an `elif` and `test: None` an else.
This representation is different tradeoff, e.g. we need to allocate the
`Vec<ElifElseClause>`, the `elif`s are now different than the `if`s
(which matters in rules where want to check both `if`s and `elif`s) and
the type system doesn't guarantee that the `test: None` else is actually
last. We're also now a bit more inconsistent since all other `else`,
those from `for`, `while` and `try`, still don't have nodes. With the
new representation some things became easier, e.g. finding the `elif`
token (we can use the start of the `ElifElseClause`) and formatting
comments for if-elif-else (no more dangling comments splitting, we only
have to insert the dangling comment after the colon manually and set
`leading_alternate_branch_comments`, everything else is taken of by
having nodes for each branch and the usual placement.rs fixups).
## Merge Plan
This PR requires coordination between the parser repo and the main ruff
repo. I've split the ruff part, into two stacked PRs which have to be
merged together (only the second one fixes all tests), the first for the
formatter to be reviewed by @michareiser and the second for the linter
to be reviewed by @charliermarsh.
* MH: Review and merge
https://github.com/astral-sh/RustPython-Parser/pull/20
* MH: Review and merge or move later in stack
https://github.com/astral-sh/RustPython-Parser/pull/21
* MH: Review and approve
https://github.com/astral-sh/RustPython-Parser/pull/22
* MH: Review and approve formatter PR
https://github.com/astral-sh/ruff/pull/5459
* CM: Review and approve linter PR
https://github.com/astral-sh/ruff/pull/5460
* Merge linter PR in formatter PR, fix ecosystem checks (ecosystem
checks can't run on the formatter PR and won't run on the linter PR, so
we need to merge them first)
* Merge https://github.com/astral-sh/RustPython-Parser/pull/22
* Create tag in the parser, update linter+formatter PR
* Merge linter+formatter PR https://github.com/astral-sh/ruff/pull/5459
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
I initially wanted this category to be more general and decoupled from
the plugin, but I got some feedback that the titling felt inconsistent
with others.
## Summary
Add support for applying auto-fixes in Jupyter Notebook.
### Solution
Cell offsets are the boundaries for each cell in the concatenated source
code. They are represented using `TextSize`. It includes the start and
end offset as well, thus creating a range for each cell. These offsets
are updated using the `SourceMap` markers.
### SourceMap
`SourceMap` contains markers constructed from each edits which tracks
the original source code position to the transformed positions. The
following drawing might make it clear:

The center column where the dotted lines are present are the markers
included in the `SourceMap`. The `Notebook` looks at these markers and
updates the cell offsets after each linter loop. If you notice closely,
the destination takes into account all of the markers before it.
The index is constructed only when required as it's only used to render
the diagnostics. So, a `OnceCell` is used for this purpose. The cell
offsets, cell content and the index will be updated after each iteration
of linting in the mentioned order. The order is important here as the
content is updated as per the new offsets and index is updated as per
the new content.
## Limitations
### 1
Styling rules such as the ones in `pycodestyle` will not be applicable
everywhere in Jupyter notebook, especially at the cell boundaries. Let's
take an example where a rule suggests to have 2 blank lines before a
function and the cells contains the following code:
```python
import something
# ---
def first():
pass
def second():
pass
```
(Again, the comment is only to visualize cell boundaries.)
In the concatenated source code, the 2 blank lines will be added but it
shouldn't actually be added when we look in terms of Jupyter notebook.
It's as if the function `first` is at the start of a file.
`nbqa` solves this by recording newlines before and after running
`autopep8`, then running the tool and restoring the newlines at the end
(refer https://github.com/nbQA-dev/nbQA/pull/807).
## Test Plan
Three commands were run in order with common flags (`--select=ALL
--no-cache --isolated`) to isolate which stage the problem is occurring:
1. Only diagnostics
2. Fix with diff (`--fix --diff`)
3. Fix (`--fix`)
### https://github.com/facebookresearch/segment-anything
```
-------------------------------------------------------------------------------
Jupyter Notebooks 3 0 0 0 0
|- Markdown 3 98 0 94 4
|- Python 3 513 468 4 41
(Total) 611 468 98 45
-------------------------------------------------------------------------------
```
```console
$ cargo run --all-features --bin ruff -- check --no-cache --isolated --select=ALL /path/to/segment-anything/**/*.ipynb --fix
...
Found 180 errors (89 fixed, 91 remaining).
```
### https://github.com/openai/openai-cookbook
```
-------------------------------------------------------------------------------
Jupyter Notebooks 65 0 0 0 0
|- Markdown 64 3475 12 2507 956
|- Python 65 9700 7362 1101 1237
(Total) 13175 7374 3608 2193
===============================================================================
```
```console
$ cargo run --all-features --bin ruff -- check --no-cache --isolated --select=ALL /path/to/openai-cookbook/**/*.ipynb --fix
error: Failed to parse /path/to/openai-cookbook/examples/vector_databases/Using_vector_databases_for_embeddings_search.ipynb:cell 4:29:18: unexpected token '-'
...
Found 4227 errors (2165 fixed, 2062 remaining).
```
### https://github.com/tensorflow/docs
```
-------------------------------------------------------------------------------
Jupyter Notebooks 150 0 0 0 0
|- Markdown 1 55 0 46 9
|- Python 1 402 289 60 53
(Total) 457 289 106 62
-------------------------------------------------------------------------------
```
```console
$ cargo run --all-features --bin ruff -- check --no-cache --isolated --select=ALL /path/to/tensorflow-docs/**/*.ipynb --fix
error: Failed to parse /path/to/tensorflow-docs/site/en/guide/extension_type.ipynb:cell 80:1:1: unexpected token Indent
error: Failed to parse /path/to/tensorflow-docs/site/en/r1/tutorials/eager/custom_layers.ipynb:cell 20:1:1: unexpected token Indent
error: Failed to parse /path/to/tensorflow-docs/site/en/guide/data.ipynb:cell 175:5:14: unindent does not match any outer indentation level
error: Failed to parse /path/to/tensorflow-docs/site/en/r1/tutorials/representation/unicode.ipynb:cell 30:1:1: unexpected token Indent
...
Found 12726 errors (5140 fixed, 7586 remaining).
```
### https://github.com/tensorflow/models
```
-------------------------------------------------------------------------------
Jupyter Notebooks 46 0 0 0 0
|- Markdown 1 11 0 6 5
|- Python 1 328 249 19 60
(Total) 339 249 25 65
-------------------------------------------------------------------------------
```
```console
$ cargo run --all-features --bin ruff -- check --no-cache --isolated --select=ALL /path/to/tensorflow-models/**/*.ipynb --fix
...
Found 4856 errors (2690 fixed, 2166 remaining).
```
resolves: #1218fixes: #4556
## Summary
Add copyright notice detection to enforce the presence of copyright
headers in Python files.
Configurable settings include: the relevant regular expression, the
author name, and the minimum file size, similar to
[flake8-copyright](https://github.com/savoirfairelinux/flake8-copyright).
Closes https://github.com/charliermarsh/ruff/issues/3579
---------
Signed-off-by: ryan <ryang@waabi.ai>
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>