## Summary
This PR modifies our `Cargo.toml` files to use workspace dependencies
for _all_ dependencies, rather than the status quo of sporadically
trying to use workspace dependencies for those dependencies that are
used across multiple crates. I find the current situation more confusing
and harder to manage, since we have a mix of workspace and crate-local
dependencies, whereas this setup consistently uses the same approach for
all dependencies.
## Summary
I always found it odd that we had to pass this in, since it's really
higher-level context for the error. The awkwardness is further evidenced
by the fact that we pass in fake values everywhere (even outside of
tests). The source path isn't actually used to display the error; it's
only accessed elsewhere to _re-display_ the error in certain cases. This
PR modifies to instead pass the path directly in those cases.
## Summary
If a rule ends with a trailing placeholder (like "Use {target}"), that
gets interpreted as an HTML attribute adding, `target="target"` to the
node. This PR escapes such cases. In reality, they're rare, since we
almost always wrap placeholders in backticks, which avoids this problem
-- but in some cases, they are in fact correct to be un-backticked.
Closes https://github.com/astral-sh/ruff/issues/9288.
## Test Plan
<img width="673" alt="Screen Shot 2023-12-28 at 9 33 40 AM"
src="https://github.com/astral-sh/ruff/assets/1309177/14aaa168-c802-4258-b82d-217a85b42ebf">
Update to [Rust
1.74](https://blog.rust-lang.org/2023/11/16/Rust-1.74.0.html) and use
the new clippy lints table.
The update itself introduced a new clippy lint about superfluous hashes
in raw strings, which got removed.
I moved our lint config from `rustflags` to the newly stabilized
[workspace.lints](https://doc.rust-lang.org/stable/cargo/reference/workspaces.html#the-lints-table).
One consequence is that we have to `unsafe_code = "warn"` instead of
"forbid" because the latter now actually bans unsafe code:
```
error[E0453]: allow(unsafe_code) incompatible with previous forbid
--> crates/ruff_source_file/src/newlines.rs:62:17
|
62 | #[allow(unsafe_code)]
| ^^^^^^^^^^^ overruled by previous forbid
|
= note: `forbid` lint level was set on command line
```
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Add missing "is":
```diff
- The 🧪 emoji indicates that a rule in "preview".
+ The 🧪 emoji indicates that a rule is in "preview".
```
## Test Plan
N/A
## Summary
Explain the meaning of the icon for screen readers (and mouse over).
Hide "inactive" (low opacity) icons from screen readers.
Remove opacity: 1 styling, it's the default opacity.
Without this change a screen reader will just read "Hammer and spanner
test tube" for the last column in each row.
**Summary** Prepare for the black preview style becoming the black
stable style at the end of the year.
This adds a new test file to compare stable and preview on some relevant
preview options in black, and makes `format_dev` understand the black
preview flag. I've added poetry as a project that uses preview.
I've implemented one specific deviation (collapsing of stub
implementation in non-stub files) which showed up in poetry for testing.
This also improves poetry compatibility from 0.99891 to 0.99919.
Fixes#7440
New compatibility stats:
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75803 | 1799 | 1647 |
| django | 0.99983 | 2772 | 35 |
| home-assistant | 0.99953 | 10596 | 189 |
| poetry | 0.99919 | 317 | 12 |
| transformers | 0.99963 | 2657 | 332 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99978 | 3669 | 20 |
| warehouse | 0.99969 | 654 | 15 |
| zulip | 0.99970 | 1459 | 22 |
## Summary
This PR updates our documentation for the upcoming formatter release.
Broadly, the documentation is now structured as follows:
- Overview
- Tutorial
- Installing Ruff
- The Ruff Linter
- Overview
- `ruff check`
- Rule selection
- Error suppression
- Exit codes
- The Ruff Formatter
- Overview
- `ruff format`
- Philosophy
- Configuration
- Format suppression
- Exit codes
- Black compatibility
- Known deviations
- Configuring Ruff
- pyproject.toml
- File discovery
- Configuration discovery
- CLI
- Shell autocompletion
- Preview
- Rules
- Settings
- Integrations
- `pre-commit`
- VS Code
- LSP
- PyCharm
- GitHub Actions
- FAQ
- Contributing
The major changes include:
- Removing the "Usage" section from the docs, and instead folding that
information into "Integrations" and the new Linter and Formatter
sections.
- Breaking up "Configuration" into "Configuring Ruff" (for generic
configuration), and new Linter- and Formatter-specific sections.
- Updating all example configurations to use `[tool.ruff.lint]` and
`[tool.ruff.format]`.
My suggestion is to pull and build the docs locally, and review by
reading them in the browser rather than trying to parse all the code
changes.
Closes https://github.com/astral-sh/ruff/issues/7235.
Closes https://github.com/astral-sh/ruff/issues/7647.
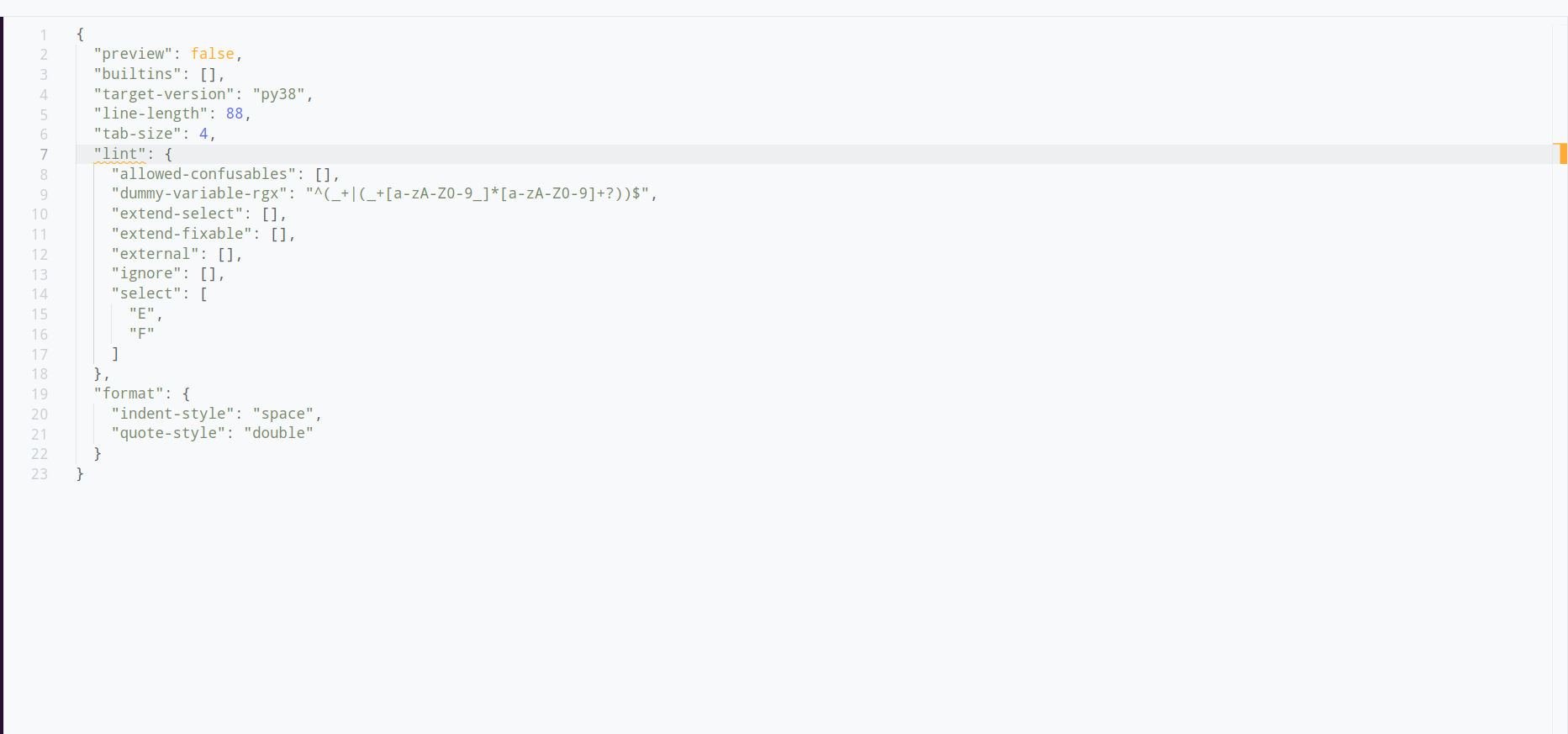
## Summary
This PR adds a new `lint` section to the configuration that groups all linter-specific settings. The existing top-level configurations continue to work without any warning because the `lint.*` settings are experimental.
The configuration merges the top level and `lint.*` settings where the settings in `lint` have higher precedence (override the top-level settings). The reasoning behind this is that the settings in `lint.` are more specific and more specific settings should override less specific settings.
I decided against showing the new `lint.*` options on our website because it would make the page extremely long (it's technically easy to do, just attribute `lint` with `[option_group`]). We may want to explore adding an `alias` field to the `option` attribute and show the alias on the website along with its regular name.
## Test Plan
* I added new integration tests
* I verified that the generated `options.md` is identical
* Verified the default settings in the playground
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
The note about rules being in preview was not being displayed for legacy
nursery rules.
Adds a link to the new preview documentation as well.
## Test Plan
<!-- How was it tested? -->
Built locally and checked a nursery rule e.g.
http://127.0.0.1:8000/ruff/rules/no-indented-block-comment/
I got confused and refactored a bit, now the naming should be more
consistent. This is the basis for the range formatting work.
Chages:
* `format_module` -> `format_module_source` (format a string)
* `format_node` -> `format_module_ast` (format a program parsed into an
AST)
* Added `parse_ok_tokens` that takes `Token` instead of `Result<Token>`
* Call the source code `source` consistently
* Added a `tokens_and_ranges` helper
* `python_ast` -> `module` (because that's the type)
## Summary
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR moves the `ResolverSettings` and `Settings` struct to `ruff_workspace`. `LinterSettings` remains in `ruff_linter` because it gets passed to lint rules, the `Checker` etc.
## Test Plan
`cargo test`
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR extracts the linter-specific settings into a new `LinterSettings` struct and adds it as a `linter` field to the `Settings` struct. This is in preparation for moving `Settings` from `ruff_linter` to `ruff_workspace`
## Test Plan
`cargo test`
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR extracts a `ResolverSettings` struct that holds all the resolver-relevant fields (uninteresting for the `Formatter` or `Linter`). This will allow us to move the `ResolverSettings` out of `ruff_linter` further up in the stack.
## Test Plan
`cargo test`
(I'll to more extensive testing at the top of this stack)
Closes#5497
Needs MkDocs 1.5 to be released.
- [x] https://github.com/mkdocs/mkdocs/milestone/15
## Summary
Uses MkDocs' `not_in_nav` config to hide spam about files in
`docs/rules/` not being in nav.
## Summary
We're planning to move the documentation from
[https://beta.ruff.rs/docs](https://beta.ruff.rs/docs) to
[https://docs.astral.sh/ruff](https://docs.astral.sh/ruff), for a few
reasons:
1. We want to remove the `beta` from the domain, as Ruff is no longer
considered beta software.
2. We want to migrate to a structure that could accommodate multiple
future tools living under one domain.
The docs are actually already live at
[https://docs.astral.sh/ruff](https://docs.astral.sh/ruff), but later
today, I'll add a permanent redirect from the previous to the new
domain. **All existing links will continue to work, now and in
perpetuity.**
This PR contains the code changes necessary for the updated
documentation. As part of this effort, I moved the playground and
documentation from my personal Cloudflare account to our team Cloudflare
account (hence the new `--project-name` references). After merging, I'll
also update the secrets on this repo.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Extends work in #7046 (some relevant discussion there)
Changes:
- All nursery rules are now referred to as preview rules
- Documentation for the nursery is updated to describe preview
- Adds a "PREVIEW" selector for preview rules
- This is primarily to allow `--preview --ignore PREVIEW --extend-select
FOO001,BAR200`
- Using `--preview` enables preview rules that match selectors
Notable decisions:
- Preview rules are not selectable by their rule code without enabling
preview
- Retains the "NURSERY" selector for backwards compatibility
- Nursery rules are selectable by their rule code for backwards
compatiblity
Additional work:
- Selection of preview rules without the "--preview" flag should display
a warning
- Use of deprecated nursery selection behavior should display a warning
- Nursery selection should be removed after some time
## Test Plan
<!-- How was it tested? -->
Manual confirmation (i.e. we don't have an preview rules yet just
nursery rules so I added a preview rule for manual testing)
New unit tests
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR moves `ruff/jupyter` into its own `ruff_notebook` crate. Beyond
the move itself, there were a few challenges:
1. `ruff_notebook` relies on the source map abstraction. I've moved the
source map into `ruff_diagnostics`, since it doesn't have any
dependencies on its own and is used alongside diagnostics.
2. `ruff_notebook` has a couple tests for end-to-end linting and
autofixing. I had to leave these tests in `ruff` itself.
3. We had code in `ruff/jupyter` that relied on Python lexing, in order
to provide a more targeted error message in the event that a user saves
a `.py` file with a `.ipynb` extension. I removed this in order to avoid
a dependency on the parser, it felt like it wasn't worth retaining just
for that dependency.
## Test Plan
`cargo test`
The docs were out of date, and the new version incorporates some
feedback.
I tried to keep the language concise and the information ordered by how
early you need it, so people can get the relevant information quickly
before jumping into the code.
I did some minor format_dev changes for consistency in the docs.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
**Summary** Some files seems notoriously slow in the formatter (secons in debug mode). This time was however almost exclusively spent in the diff algorithm to collect the similarity index, so i replaced that. I kept `similar` for printing actual diff to avoid rewriting that too, with the disadvantage that we now have to diff libraries in format_dev.
I used this PR to remove the spinner from tracing-indicatif and changed `flamegraph --perfdata perf.data` to `flamegraph --perfdata perf.data --no-inline` as the former wouldn't finish for me on release builds with debug info.
## Summary
Enable using the new `Mode::Jupyter` for the tokenizer/parser to parse
Jupyter line magic tokens.
The individual call to the lexer i.e., `lex_starts_at` done by various
rules should consider the context of the source code (is this content
from a Jupyter Notebook?). Thus, a new field `source_type` (of type
`PySourceType`) is added to `Checker` which is being passed around as an
argument to the relevant functions. This is then used to determine the
`Mode` for the lexer.
## Test Plan
Add new test cases to make sure that the magic statement is considered
while generating the diagnostic and autofix:
* For `I001`, if there's a magic statement in between two import blocks,
they should be sorted independently
fixes: #6090
**Summary** This adds the information whether we're in a .py python
source file or in a .pyi stub file to enable people working on #5822 and
related issues.
I'm not completely happy with `Default` for something that depends on
the input.
**Test Plan** None, this is currently unused, i'm leaving this to first
implementation of stub file specific formatting.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
**Summary** Prompted by
https://github.com/astral-sh/ruff/pull/6257#issuecomment-1661308410, it
tried to make the ecosystem script output on failure better
understandable. All log messages are now written to a file, which is
printed on error. Running locally progress is still shown.
Looking through the log output i saw that we currently log syntax errors
in input, which is confusing because they aren't actual errors, but we
don't check that these files don't change due to parser regressions or
improvements. I added `--files-with-errors` to catch that.
**Test Plan** CI
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Before:
<img width="1031" alt="Screen Shot 2023-08-02 at 15 57 10"
src="https://github.com/astral-sh/ruff/assets/17039389/171a21d5-01a5-4aa5-8079-4e7f8a59ade8">
After:
<img width="1031" alt="Screen Shot 2023-08-02 at 15 58 03"
src="https://github.com/astral-sh/ruff/assets/17039389/afd1b9b7-89e0-4e38-a4a6-e3255b62f021">
## Test Plan
<!-- How was it tested? -->
Manual inspection
**Summary** This includes two changes:
* Allow setting `-v` in `ruff_dev`, using the `ruff_cli` implementation
* `debug!` which ruff configuration strategy was used
This is a byproduct of debugging #6187.
**Test Plan** n/a
**Summary** Add a formatter progress testing script to CI. This script
will 1) print the black compability on each run 2) catch regressions wrt
to formatter stability, emitting invalid syntax and other kinds of bugs
(e.g. #5917) before they land on main 3) have an additional layer of
real world tests when implementing new nodes or other new formatter
code.
This is currently a bash script, i'm not sure if we want to keep it that
way, or switch to e.g. the regular ecosystem scripts. The output
separation of `format_dev` could also use some polishing. We should also
consider pinning commits so we don't get spurious regression when they
change their code.
**Test Plan** The script extends CI.
**Summary** Previously, `RUF014` would be part of ruff.schema.json
depending on whether or not the `unreachable-code` feature was active.
This caused problems for contributors who got unrelated RUF014 changes
when updating the schema without the feature active.
An alternative would be to always add `RUF014`.
**Test plan** `cargo dev generate-all` and `cargo run --bin ruff_dev
--features unreachable-code -- generate-all` now have the same effect.
## Summary
For formatter instabilities, the message we get look something like
this:
```text
Unstable formatting /home/konsti/ruff/target/checkouts/deepmodeling:dpdispatcher/dpdispatcher/slurm.py
@@ -47,9 +47,9 @@
- script_header_dict["slurm_partition_line"] = (
- NOT_YET_IMPLEMENTED_ExprJoinedStr
- )
+ script_header_dict[
+ "slurm_partition_line"
+ ] = NOT_YET_IMPLEMENTED_ExprJoinedStr
Unstable formatting /home/konsti/ruff/target/checkouts/deepmodeling:dpdispatcher/dpdispatcher/pbs.py
@@ -26,9 +26,9 @@
- pbs_script_header_dict["select_node_line"] += (
- NOT_YET_IMPLEMENTED_ExprJoinedStr
- )
+ pbs_script_header_dict[
+ "select_node_line"
+ ] += NOT_YET_IMPLEMENTED_ExprJoinedStr
```
For ruff crashes. you don't even get that but just the file that crashed
it. To extract the actual bug, you'd need to manually remove parts of
the file, rerun to see if the bug still occurs (and revert if it
doesn't) until you have a minimal example.
With this script, you run
```shell
cargo run --bin ruff_shrinking -- target/checkouts/deepmodeling:dpdispatcher/dpdispatcher/slurm.py target/minirepo/code.py "Unstable formatting" "target/debug/ruff_dev format-dev --stability-check target/minirepo"
```
and get
```python
class Slurm():
def gen_script_header(self, job):
if resources.queue_name != "":
script_header_dict["slurm_partition_line"] = f"#SBATCH --partition {resources.queue_name}"
```
which is an nice minimal example.
I've been using this script and it would be easier for me if this were
part of main. The main disadvantage to merging is that it adds
additional dependencies.
## Test Plan
I've been using this for a number of minimization. This is an internal
helper script you only run manually. I could add a test that minimizes a
rule violation if required.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Comparing repos with black requires that we use the settings as black,
notably line length and magic trailing comma behaviour. Excludes and
preserving quotes (vs. a preference for either quote style) is not yet
implemented because they weren't needed for the test projects.
In the other two commits i fixed the output when the progress bar is
hidden (this way is recommonded in the indicatif docs), added a
`scratch.pyi` file to gitignore because black formats stub files
differently and also updated the ecosystem readme with the projects json
without forks.
## Test Plan
I added a `line-length` vs `line_length` test. Otherwise only my
personal usage atm, a PR to integrate the script into the CI to check
some projects will follow.
## Summary
Document all `ruff_dev` subcommands and document the `format_dev` flags
in the formatter readme.
CC @zanieb please flag everything that isn't clear or missing
## Test Plan
n/a
## Summary
The similarity index, the fraction of unchanged lines, is easier to
understand than the jaccard index, the fraction between intersection and
union.
## Test Plan
I ran this on django and git a 0.945 index, meaning 5.5% of lines are
currently reformatted when compared to black
## Summary
This PR reworks the `upstream_categories` mechanism that is only used
for documentation purposes to make it easier to generate docs using
`all_rules()`. The new implementation also relies on "tribal knowledge"
about rule codes, so it's not the best implementation, but gets us
forward.
Another option would be to change the rule-defining proc macros to allow
configuring an optional `RuleCategory`, but that seems more heavy-handed
and possibly unnecessary in the long run...
Draft since this builds on #5439.
cc @charliermarsh :)
## Summary
This changes the docs to show a nursery icon (🌅) for rules in the
nursery.
It currently doesn't do that for the rules that are in sub-categories
(Pylint, Pycodestyle) because there is no `all_rules()` for the
`RuleCodePrefix` that's returned by `UpstreamCategory` iteration (and as
mentioned on Discord, I think `UpstreamCategory` maybe shouldn't be a
thing). (That would be enabled by #5591.)
## Test Plan
Generated docs to see new icons (with the caveat above).
## Summary
This extends the `ruff_dev` formatter script util. Instead of only doing
stability checks, you can now choose different compatible options on the
CLI and get statistics.
* It adds an option the formats all files that ruff would check to allow
looking at an entire black-formatted repository with `git diff`
* It computes the [Jaccard
index](https://en.wikipedia.org/wiki/Jaccard_index) as a measure of
deviation between input and output, which is useful as single number
metric for assessing our current deviations from black.
* It adds progress bars to both the single projects as well as the
multi-project mode.
* It adds an option to write the multi-project output to a file
Sample usage:
```
$ cargo run --bin ruff_dev -- format-dev --stability-check crates/ruff/resources/test/cpython
$ cargo run --bin ruff_dev -- format-dev --stability-check /home/konsti/projects/django
Syntax error in /home/konsti/projects/django/tests/test_runner_apps/tagged/tests_syntax_error.py: source contains syntax errors (parser error): BaseError { error: UnrecognizedToken(Name { name: "syntax_error" }, None), offset: 131, source_path: "<filename>" }
Found 0 stability errors in 2755 files (jaccard index 0.911) in 9.75s
$ cargo run --bin ruff_dev -- format-dev --write /home/konsti/projects/django
```
Options:
```
Several utils related to the formatter which can be run on one or more repositories. The selected set of files in a repository is the same as for `ruff check`.
* Check formatter stability: Format a repository twice and ensure that it looks that the first and second formatting look the same. * Format: Format the files in a repository to be able to check them with `git diff` * Statistics: The subcommand the Jaccard index between the (assumed to be black formatted) input and the ruff formatted output
Usage: ruff_dev format-dev [OPTIONS] [FILES]...
Arguments:
[FILES]...
Like `ruff check`'s files. See `--multi-project` if you want to format an ecosystem checkout
Options:
--stability-check
Check stability
We want to ensure that once formatted content stays the same when formatted again, which is known as formatter stability or formatter idempotency, and that the formatter prints syntactically valid code. As our test cases cover only a limited amount of code, this allows checking entire repositories.
--write
Format the files. Without this flag, the python files are not modified
--format <FORMAT>
Control the verbosity of the output
[default: default]
Possible values:
- minimal: Filenames only
- default: Filenames and reduced diff
- full: Full diff and invalid code
-x, --exit-first-error
Print only the first error and exit, `-x` is same as pytest
--multi-project
Checks each project inside a directory, useful e.g. if you want to check all of the ecosystem checkouts
--error-file <ERROR_FILE>
Write all errors to this file in addition to stdout. Only used in multi-project mode
```
## Test Plan
I ran this on django (2755 files, jaccard index 0.911) and discovered a
magic trailing comma problem and that we really needed to implement
import formatting. I ran the script on cpython to identify
https://github.com/astral-sh/ruff/pull/5558.
## Summary
This makes the output of `check-formatter-stability` more concise by
removing extraneous newlines. It also adds a `--error-file` option to
that script that allows creating a file with just the errors (without
the status messages) to share with others.
## Test Plan
I ran it over CPython and looked at the output. I then added the
`--error-file` option and looked at the contents of the file
## Summary
As discussed on ~IRC~ Discord, this will make it easier for e.g. the
docs generation stuff to get all rules for a linter (using
`all_rules()`) instead of just non-nursery ones, and it also makes it
more Explicit Is Better Than Implicit to iterate over linter rules.
Grepping for `Item = Rule` reveals some remaining implicit
`IntoIterator`s that I didn't feel were necessarily in scope for this
(and honestly, iterating over a `RuleSet` makes sense).
Support for `let…else` formatting was just merged to nightly
(rust-lang/rust#113225). Rerun `cargo fmt` with Rust nightly 2023-07-02
to pick this up. Followup to #939.
Signed-off-by: Anders Kaseorg <andersk@mit.edu>
<!--
Thank you for contributing to Ruff! To help us out with reviewing, please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR uses rayon to parallelize the stability check by scheduling each project as its own task.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
I ran the ecosystem check. It now makes use of all cores (except at the end, there are some large projects).
## Performance
The check now completes in minutes where it took about 30 minutes before.
<!-- How was it tested? -->
ruff_dev repeat recently broke (i think with the cargo update?):
> thread 'main' panicked at 'Command repeat: Short option names must be
unique for each argument, but '-n' is in use by both 'no_cache' and
'repeat''
This fixes this by removing the short argument.
## Summary
Experimental release for Jupyter Notebook integration.
Currently, this requires a user to explicitly opt-in using the
[include](https://beta.ruff.rs/docs/settings/#include) configuration:
```toml
[tool.ruff]
include = ["*.py", "*.pyi", "**/pyproject.toml", "*.ipynb"]
```
Or, a user can pass in the file directly:
```sh
ruff check path/to/notebook.ipynb
```
For known limitations, please refer #5188
## Test Plan
Following command should work without the `--all-features` flag:
```sh
cargo dev round-trip /path/to/notebook.ipynb
```
Following command should work with the above config file along with
`select = ["ALL"]`:
```sh
cargo run --bin ruff -- check --no-cache --config=../test-repos/openai-cookbook/pyproject.toml --fix ../test-repos/openai-cookbook/
```
Passing the Jupyter notebook directly:
```sh
cargo run --bin ruff -- check --no-cache --isolated --select=ALL --fix ../test-repos/openai-cookbook/examples/Classification_using_embeddings.ipynb
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing, please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR adds a new `PyFormatOptions` struct that stores the python formatter options.
The new options aren't used yet, with the exception of magical trailing commas and the options passed to the printer.
I'll follow up with more PRs that use the new options (e.g. `QuoteStyle`).
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
`cargo test` I'll follow up with a new PR that adds support for overriding the options in our fixture tests.
## Summary
This contains three changes:
* repos in `check_ecosystem.py` are stored as `org:name` instead of
`org/name` to create a flat directory layout
* `check_ecosystem.py` performs a maximum of 50 parallel jobs at the
same time to avoid consuming to much RAM
* `check-formatter-stability` gets a new option `--multi-project` so
it's possible to do `cargo run --bin ruff_dev --
check-formatter-stability --multi-project target/checkouts`
With these three changes it becomes easy to check the formatter
stability over a larger number of repositories. This is part of the
integration of integrating formatter regressions checks into the
ecosystem checks.
## Test Plan
```shell
python scripts/check_ecosystem.py --checkouts target/checkouts --projects github_search.jsonl -v $(which true) $(which true)
cargo run --bin ruff_dev -- check-formatter-stability --multi-project target/checkouts
```
## Summary
We want to ensure that once formatted content stays the same when
formatted again, which is known as formatter stability or formatter
idempotency, and that the formatter prints syntactically valid code. As
our test cases cover only a limited amount of code, this allows checking
entire repositories.
This adds a new subcommand to `ruff_dev` which can be invoked as `cargo
run --bin ruff_dev -- check-formatter-stability <repo>`. While initially
only intended to check stability, it has also found cases where the
formatter printed invalid syntax or panicked.
## Test Plan
Running this on cpython is already identifying bugs
(https://github.com/astral-sh/ruff/pull/5089)
## Summary
This adds a new subcommand that can be used as
```shell
cargo build --bin ruff_dev --profile=release-debug
perf record -g -F 999 target/release-debug/ruff_dev repeat --repeat 30 --exit-zero --no-cache path/to/cpython > /dev/null
flamegraph --perfdata perf.data
```
## Test Plan
This is a ruff internal script. I successfully used it to profile
cpython with the instructions above
This tackles three problems:
* pre-commit was slow because it ran cargo commands
* Improve the clarity on what you need to run to get your PR pass on CI
(and make those fast)
* You had to compile and run `cargo dev generate-all` separately, which
was slow
The first change is to remove all cargo commands except running ruff
itself from pre-commit. With `cargo run --bin ruff` already compiled it
takes about 7s on my machine. It would make sense to also use the ruff
pre-commit action here even if we're then lagging a release behind for
checking ruff on ruff.
The contributing guide is now clear about what you need to run:
```shell
cargo clippy --workspace --all-targets --all-features -- -D warnings # Linting...
RUFF_UPDATE_SCHEMA=1 cargo test # Testing and updating ruff.schema.json
pre-commit run --all-files # rust and python formatting, markdown and python linting, etc.
```
Example timings from my machine:
`cargo clippy --workspace --all-targets --all-features -- -D warnings`:
23s
`RUFF_UPDATE_SCHEMA=1 cargo test`: 2min (recompiling), 1min (no code
changes, this is mainly doc tests)
`pre-commit run --all-files`: 7s
The exact numbers don't matter so much as the approximate experience (6s
is easier to just wait than 1min, esp if you need to fix and rerun). The
biggest remaining block seems to be doc tests, i'm surprised i didn't
find any solution to speeding them up (nextest simply doesn't run them
at all). Also note that the formatter has it's own tests which are much
faster since they avoid linking ruff (`cargo test
ruff_python_formatter`).
The third change is to enable `cargo test` to update the schema. Similar
to `INSTA_UPDATE=always`, i've added `RUFF_UPDATE_SCHEMA=1` (name open
to bikeshedding), so `RUFF_UPDATE_SCHEMA=1 cargo test` updates the
schema, while `cargo test` still fails as expected if the repo isn't
up-to-date.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>