When a fork is created from a list of dependencies, we were previously
adding all other sibling dependencies to every fork created. But this
isn't actually quite right, since the fork created is always created by
some marker expression. And while it is definitively disjoint from any
directly conflicting dependency specification, it is also possibly
disjoint with other dependencies. For example, as reported in #4414:
```toml
dependencies = [
"anyio==4.4.0 ; python_version >= '3.12'",
"anyio==4.3.0 ; python_version < '3.12'",
"b1 ; python_version >= '3.12'",
"b2 ; python_version < '3.12'",
]
```
The first two `anyio` requirements are conflicting with non-overlapping
marker expressions, and so a fork is created. Prior to this commit,
*both* `b1` and `b2` would be added to each fork. But of course, `b2` is
impossible in the `anyio==4.4.0` fork because of disjoint marker
expressions.
So in this commit, we specifically filter out any sibling dependencies
that could find their way into a fork that have disjoint markers with
that fork. We are careful to do this both when a new fork is created
from an existing set of dependencies, and when adding new dependencies
to a fork.
Fixes#4414
To support diverging urls, we have to check urls when adding
dependencies (after forking). To prepare for this, i've moved adding
dependencies for the current version to
`SolveState::add_package_version_dependencies` and removed the
duplication when checking for self-dependencies.
This changed is joined with a change in pubgrub
(https://github.com/astral-sh/pubgrub/pull/27) that simplifies the same
code path.
This commit adds marker expressions to our `Fork` type, which are in
turn passed down into `PubGrubDependencies::from_requirements` to filter
our any dependencies with markers that are disjoint from the fork's
marker expression.
This is necessary to avoid visiting packages in the dependency graph
that can never actually be installed. This is because when a fork is
created in the resolver, it always happens when there are two sibling
dependency specifications on a package with the same name, but with
non-overlapping marker expressions. Each fork corresponds to each
such conflicting dependency specification, and each fork assumes the
the corresponding marker expression as a pre-condition for any future
dependencies considered by it. That is, since the fork represents an
installation path that can only be taken when the corresponding
dependency specification (and its marker expression) is actually used,
it also therefore follows that the marker expression is true. Therefore,
any dependency visited in that fork with a marker expression that cannot
possibly be true when the markers of the fork are true can and ought to
be completely ignored.
There are some key invariants that I had to re-learn by reading the
code. This hopefully makes those invariants easier to discover by future
me (and others).
In the time before universal resolving, we would always pass a
`MarkerEnvironment`, and this environment would capture any relevant
`Requires-Python` specifier (including if `-p/--python` was provided on
the CLI).
But in universal resolution, we very specifically do not use a
`MarkerEnvironment` because we want to produce a resolution that is
compatible across potentially multiple environments. This in turn meant
that we lost `Requires-Python` filtering.
This PR adds it back. We do this by converting our `PythonRequirement`
into a `MarkerTree` that encodes the version specifiers in a
`Requires-Python` specifier. We then ask whether that `MarkerTree` is
disjoint with a dependency specification's `MarkerTree`. If it is, then
we know it's impossible for that dependency specification to every be
true, and we can completely ignore it.
## Summary
Similar to how we abstracted the dependencies into
`ResolutionDependencyNames`, I think it makes sense to abstract the base
packages into a `ResolutionPackage`. This also avoids leaking details
about the various `PubGrubPackage` enum variants to `ResolutionGraph`.
## Summary
If a package lacks a source distribution, and we can't find a compatible
wheel for the current platform, we need to just _assume_ that the
package will have a valid wheel on all platforms on which it's
requested; if not, we raise an error at install time.
It's possible that we can be smarter about this over time. For example,
if the package was requested _only_ for macOS, we could verify that
there's at least one macOS-compatible wheel. See the linked issue for
more details.
Closes https://github.com/astral-sh/uv/issues/4139.
The basic idea here is to make it so forking can only ever result in a
resolution that, for a particular marker environment, will only install
at most one version of a package. We can guarantee this by ensuring we
only fork on conflicting dependency specifications only when their
corresponding markers are completely disjoint. If they aren't, then
resolution _must_ find a single version of the package in the
intersection of the two dependency specifications.
A test for this case has been added to packse here:
https://github.com/astral-sh/packse/pull/182. Previously, that test
would result in a resolution with two different unconditional versions
of the same package. With this change, resolution fails (as it should).
A commit-by-commit review should be helpful here, since the first commit
is a refactor to make the second commit a bit more digestible.
## Summary
I think we should be able to model PubGrub such that this isn't
necessary (at least for the case described in the issue), but for now,
let's just avoid attempting to build very old distributions in
prefetching.
Closes https://github.com/astral-sh/uv/issues/4136.
## Summary
This PR adds a lowering similar to that seen in
https://github.com/astral-sh/uv/pull/3100, but this time, for markers.
Like `PubGrubPackageInner::Extra`, we now have
`PubGrubPackageInner::Marker`. The dependencies of the `Marker` are
`PubGrubPackageInner::Package` with and without the marker.
As an example of why this is useful: assume we have `urllib3>=1.22.0` as
a direct dependency. Later, we see `urllib3 ; python_version > '3.7'` as
a transitive dependency. As-is, we might (for some reason) pick a very
old version of `urllib3` to satisfy `urllib3 ; python_version > '3.7'`,
then attempt to fetch its dependencies, which could even involve
building a very old version of `urllib3 ; python_version > '3.7'`. Once
we fetch the dependencies, we would see that `urllib3` at the same
version is _also_ a dependency (because we tack it on). In the new
scheme though, as soon as we "choose" the very old version of `urllib3 ;
python_version > '3.7'`, we'd then see that `urllib3` (the base package)
is also a dependency; so we see a conflict before we even fetch the
dependencies of the old variant.
With this, I can successfully resolve the case in #4099.
Closes https://github.com/astral-sh/uv/issues/4099.
## Summary
This PR modifies our `Requires-Python` handling to treat
`Requires-Python` as a lower bound. There's extensive discussion around
this in https://github.com/astral-sh/uv/issues/4022 and the references
linked therein. I think it's an experiment worth trying. Even in my own
small projects, I'm running into issues whereby I'm being "forced" to
add a `<4` upper bound to my `Requires-Python` due to these caps.
Separately, we should explore adding a mechanism that's distinct from
`Requires-Python` to enable users to declare a supported range for
locking.
Closes https://github.com/astral-sh/uv/issues/4022.
## Summary
Externally, development dependencies are currently structured as a flat
list of PEP 580-compatible requirements:
```toml
[tool.uv]
dev-dependencies = ["werkzeug"]
```
When locking, we lock all development dependencies; when syncing, users
can provide `--dev`.
Internally, though, we model them as dependency groups, similar to
Poetry, PDM, and [PEP 735](https://peps.python.org/pep-0735). This
enables us to change out the user-facing frontend without changing the
internal implementation, once we've decided how these should be exposed
to users.
A few important decisions encoded in the implementation (which we can
change later):
1. Groups are enabled globally, for all dependencies. This differs from
extras, which are enabled on a per-requirement basis. Note, however,
that we'll only discover groups for uv-enabled packages anyway.
2. Installing a group requires installing the base package. We rely on
this in PubGrub to ensure that we resolve to the same version (even
though we only expect groups to come from workspace dependencies anyway,
which are unique). But anyway, that's encoded in the resolver right now,
just as it is for extras.
## Summary
This PR adds the `Requires-Python` range to the user's lockfile. This
will enable us to validate it when installing.
For now, we repeat the `Requires-Python` back to the user;
alternatively, though, we could detect the supported Python range
automatically.
See: https://github.com/astral-sh/uv/issues/4052
## Summary
Thankfully this is pretty rare since `pip sync` is usually run on `pip
compile` output, and `pip compile` never outputs markers.
Closes https://github.com/astral-sh/uv/issues/4044
## Summary
Instead of checking if the target and installed version are the same, we
model the data such that the target version is only present if it was
specified by the user. This also means that we correctly say "requested
version" even if the two happen to be the same.
## Summary
I believe this is no longer necessary. Part of the problem here is that
we can't _know_ the full set of available Python versions, especially
once we start resolving against a `Requires-Python` rather than a fixed
set of two versions.
## Summary
Once we use a _range_ rather than a precise version, it won't actually
make sense to return a version here. It's no longer required, so I'm
removing it.
## Summary
Running a resolution that required forking was failing due to breaking
an invariant in PubGrub. It looks like we were adding the same
incompatibility multiple times, or something like that. The issue
appears to be that when forking, we modify the current state, then clone
it as the "next state", then push to the "forked states" -- but that
means we're cloning the _modified_ state.
This PR changes the order of operations such that we clone, then modify.
It shouldn't introduce any additional clones though.
## Summary
This PR removes the static resolver map:
```rust
static RESOLVED_GIT_REFS: Lazy<Mutex<FxHashMap<RepositoryReference, GitSha>>> =
Lazy::new(Mutex::default);
```
With a `GitResolver` struct that we now pass around on the
`BuildContext`. There should be no behavior changes here; it's purely an
internal refactor with an eye towards making it cleaner for us to
"pre-populate" the list of resolved SHAs.
With the change, we remove the special casing of workspace dependencies
and resolve `tool.uv` for all git and directory distributions. This
gives us support for non-editable workspace dependencies and path
dependencies in other workspaces. It removes a lot of special casing
around workspaces. These changes are the groundwork for supporting
`tool.uv` with dynamic metadata.
The basis for this change is moving `Requirement` from
`distribution-types` to `pypi-types` and the lowering logic from
`uv-requirements` to `uv-distribution`. This changes should be split out
in separate PRs.
I've included an example workspace `albatross-root-workspace2` where
`bird-feeder` depends on `a` from another workspace `ab`. There's a
bunch of failing tests and regressed error messages that still need
fixing. It does fix the audited package count for the workspace tests.
We significantly regressed performance in some cases because we were
cloning the resolver state one more time than we needed to. That doesn't
sound like a lot, but in the case where there are no forks, it implies
we were cloning the state for every `get_dependencies` called when we
shouldn't have been cloning it at all.
Avoiding the clone results in somewhat tortured code. This can probably
be refactored by moving bits out to a helper routine, but that also
seemed non-trivial. So we let this suffice for now.
This addresses the lack of marker support in prior commits.
Specifically, we add them as a new field to `AnnotatedDist`, and from
there, they get added to a `Distribution` in a `Lock`.
This commit is a pretty invasive change that implements the merging
of resolutions created by each fork of the resolver.
The main idea here is that each `SolveState` is converted into a
`Resolution` (a new type) and stored on the heap after its fork
completes. When all forks complete, they are all merged into a single
`Resolution`. This `Resolution` is then used to build a `ResolutionGraph`.
Construction of `ResolutionGraph` mostly stays the same (despite the
gnarly diff due to an indent change) with one exception: the code to
extract dependency edges out of PubGrub's state has been moved to
`SolveState::into_resolution`. The idea here is that once a fork
completes, we extract what we need from the PubGrub state and then
throw it away. We store these edges in our own intermediate type which
is then converted into petgraph edges in the `ResolutionGraph`
constructor.
One interesting change we make here is that our edge
data is now a `Version` instead of a `Range<Version>`. I don't think
`Range<Version>` was actually being used anywhere, so this seems okay?
In any case, I think `Version` here is correct because a resolution
corresponds to specific dependencies of each package. Moreover, I didn't
see an easy way to make things work with `Range<Version>`. Notably,
since we no longer have the guarantee that there is only one version of
each package, we need to use `(PackageName, Version)` instead of just
`PackageName` for inverted lookups in `ResolutionGraph::from_state`.
Finally, the main resolver loop itself is changed a bit to track all
forked resolutions and then merge them at the end.
Note that we don't really have any dealings with markers in this commit.
We'll get to that in a subsequent commit.
This changes the constructor to just take an `InMemoryIndex`
directly instead of the constituent parts. No real reason other
than it seems a little simpler.
There are still some TODOs/FIXMEs here, but this makes represents a
chunk of the resolver refactoring to enable forking. We don't do any
merging of resolutions yet, so crucially, this code is broken when no
marker environment is provided. But when a marker environment is
provided, this should behave the same as a non-forking resolver. In
particular, `get_dependencies_forking` is just `get_dependencies`
whenever there's a marker environment.
## Summary
This PR adds extras to the lockfile, and enables users to selectively
sync extras in `uv sync` and `uv run`. The end result here was fairly
simple, though it required a few refactors to get here. The basic idea
is that `DistributionId` now includes `extra: Option<ExtraName>`, so we
effectively treat extras as separate packages. Generating the lockfile,
and generating the resolution from the lockfile, fall out of this
naturally with no special-casing or additional changes.
The main downside here is that it bloats the lockfile significantly.
Specifically:
- We include _all_ distribution URLs and hashes for _every_ extra
variant.
- We include all dependencies for the extra variant, even though that
are dependencies of the base package.
We could normalize this representation by changing each distribution
have an `optional-dependencies` hash map that keys on extras, but we
actually don't have the information we need to create that right now
(specifically, we can't differentiate between dependencies that
_require_ the extra and dependencies on the base package).
Closes#3700.
## Summary
There are a few behavior changes in here:
- We now enforce `--require-hashes` for editables, like pip. So if you
use `--require-hashes` with an editable requirement, we'll reject it. I
could change this if it seems off.
- We now treat source tree requirements, editable or not (e.g., both `-e
./black` and `./black`) as if `--refresh` is always enabled. This
doesn't mean that we _always_ rebuild them; but if you pass
`--reinstall`, then yes, we always rebuild them. I think this is an
improvement and is close to how editables work today.
Closes#3844.
Closes#2695.
When parsing requirements from any source, directly parse the url parts
(and reject unsupported urls) instead of parsing url parts at a later
stage. This removes a bunch of error branches and concludes the work
parsing url parts once and passing them around everywhere.
Many usages of the assembled `VerbatimUrl` remain, but these can be
removed incrementally.
Please review commit-by-commit.
Pubgrub stores incompatibilities as (package name, version range)
tuples, meaning it needs to clone the package name for each
incompatibility, and each non-borrowed operation on incompatibilities.
https://github.com/astral-sh/uv/pull/3673 made me realize that
`PubGrubPackage` has gotten large (expensive to copy), so like `Version`
and other structs, i've added an `Arc` wrapper around it.
It's a pity clippy forbids `.deref()`, it's less opaque than `&**` and
has IDE support (clicking on `.deref()` jumps to the right impl).
## Benchmarks
It looks like this matters most for complex resolutions which, i assume
because they carry larger `PubGrubPackageInner::Package` and
`PubGrubPackageInner::Extra` types.
```bash
hyperfine --warmup 5 "./uv-main pip compile -q ./scripts/requirements/jupyter.in" "./uv-branch pip compile -q ./scripts/requirements/jupyter.in"
hyperfine --warmup 5 "./uv-main pip compile -q ./scripts/requirements/airflow.in" "./uv-branch pip compile -q ./scripts/requirements/airflow.in"
hyperfine --warmup 5 "./uv-main pip compile -q ./scripts/requirements/boto3.in" "./uv-branch pip compile -q ./scripts/requirements/boto3.in"
```
```
Benchmark 1: ./uv-main pip compile -q ./scripts/requirements/jupyter.in
Time (mean ± σ): 18.2 ms ± 1.6 ms [User: 14.4 ms, System: 26.0 ms]
Range (min … max): 15.8 ms … 22.5 ms 181 runs
Benchmark 2: ./uv-branch pip compile -q ./scripts/requirements/jupyter.in
Time (mean ± σ): 17.8 ms ± 1.4 ms [User: 14.4 ms, System: 25.3 ms]
Range (min … max): 15.4 ms … 23.1 ms 159 runs
Summary
./uv-branch pip compile -q ./scripts/requirements/jupyter.in ran
1.02 ± 0.12 times faster than ./uv-main pip compile -q ./scripts/requirements/jupyter.in
```
```
Benchmark 1: ./uv-main pip compile -q ./scripts/requirements/airflow.in
Time (mean ± σ): 153.7 ms ± 3.5 ms [User: 165.2 ms, System: 157.6 ms]
Range (min … max): 150.4 ms … 163.0 ms 19 runs
Benchmark 2: ./uv-branch pip compile -q ./scripts/requirements/airflow.in
Time (mean ± σ): 123.9 ms ± 4.6 ms [User: 152.4 ms, System: 133.8 ms]
Range (min … max): 118.4 ms … 138.1 ms 24 runs
Summary
./uv-branch pip compile -q ./scripts/requirements/airflow.in ran
1.24 ± 0.05 times faster than ./uv-main pip compile -q ./scripts/requirements/airflow.in
```
```
Benchmark 1: ./uv-main pip compile -q ./scripts/requirements/boto3.in
Time (mean ± σ): 327.0 ms ± 3.8 ms [User: 344.5 ms, System: 71.6 ms]
Range (min … max): 322.7 ms … 334.6 ms 10 runs
Benchmark 2: ./uv-branch pip compile -q ./scripts/requirements/boto3.in
Time (mean ± σ): 311.2 ms ± 3.1 ms [User: 339.3 ms, System: 63.1 ms]
Range (min … max): 307.8 ms … 317.0 ms 10 runs
Summary
./uv-branch pip compile -q ./scripts/requirements/boto3.in ran
1.05 ± 0.02 times faster than ./uv-main pip compile -q ./scripts/requirements/boto3.in
```
<!--
Thank you for contributing to uv! To help us out with reviewing, please
consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
This is split out from workspaces support, which needs editables in the
bluejay commands. It consists mainly of refactorings:
* Move the `editable` module one level up.
* Introduce a `BuiltEditableMetadata` type for `(LocalEditable,
Metadata23, Requirements)`.
* Add editables to `InstalledPackagesProvider` so we can use
`EmptyInstalledPackages` for them.
## Summary
Uncertain about this, but we don't actually need the full
`SourceDistFilename`, only the name and version -- and we often have
that information already (as in the lockfile routines). So by flattening
the fields onto `RegistrySourceDist`, we can avoid re-parsing for
information we already have.
## Summary
This PR introduces parallelism to the resolver. Specifically, we can
perform PubGrub resolution on a separate thread, while keeping all I/O
on the tokio thread. We already have the infrastructure set up for this
with the channel and `OnceMap`, which makes this change relatively
simple. The big change needed to make this possible is removing the
lifetimes on some of the types that need to be shared between the
resolver and pubgrub thread.
A related PR, https://github.com/astral-sh/uv/pull/1163, found that
adding `yield_now` calls improved throughput. With optimal scheduling we
might be able to get away with everything on the same thread here.
However, in the ideal pipeline with perfect prefetching, the resolution
and prefetching can run completely in parallel without depending on one
another. While this would be very difficult to achieve, even with our
current prefetching pattern we see a consistent performance improvement
from parallelism.
This does also require reverting a few of the changes from
https://github.com/astral-sh/uv/pull/3413, but not all of them. The
sharing is isolated to the resolver task.
## Test Plan
On smaller tasks performance is mixed with ~2% improvements/regressions
on both sides. However, on medium-large resolution tasks we see the
benefits of parallelism, with improvements anywhere from 10-50%.
```
./scripts/requirements/jupyter.in
Benchmark 1: ./target/profiling/baseline (resolve-warm)
Time (mean ± σ): 29.2 ms ± 1.8 ms [User: 20.3 ms, System: 29.8 ms]
Range (min … max): 26.4 ms … 36.0 ms 91 runs
Benchmark 2: ./target/profiling/parallel (resolve-warm)
Time (mean ± σ): 25.5 ms ± 1.0 ms [User: 19.5 ms, System: 25.5 ms]
Range (min … max): 23.6 ms … 27.8 ms 99 runs
Summary
./target/profiling/parallel (resolve-warm) ran
1.15 ± 0.08 times faster than ./target/profiling/baseline (resolve-warm)
```
```
./scripts/requirements/boto3.in
Benchmark 1: ./target/profiling/baseline (resolve-warm)
Time (mean ± σ): 487.1 ms ± 6.2 ms [User: 464.6 ms, System: 61.6 ms]
Range (min … max): 480.0 ms … 497.3 ms 10 runs
Benchmark 2: ./target/profiling/parallel (resolve-warm)
Time (mean ± σ): 430.8 ms ± 9.3 ms [User: 529.0 ms, System: 77.2 ms]
Range (min … max): 417.1 ms … 442.5 ms 10 runs
Summary
./target/profiling/parallel (resolve-warm) ran
1.13 ± 0.03 times faster than ./target/profiling/baseline (resolve-warm)
```
```
./scripts/requirements/airflow.in
Benchmark 1: ./target/profiling/baseline (resolve-warm)
Time (mean ± σ): 478.1 ms ± 18.8 ms [User: 482.6 ms, System: 205.0 ms]
Range (min … max): 454.7 ms … 508.9 ms 10 runs
Benchmark 2: ./target/profiling/parallel (resolve-warm)
Time (mean ± σ): 308.7 ms ± 11.7 ms [User: 428.5 ms, System: 209.5 ms]
Range (min … max): 287.8 ms … 323.1 ms 10 runs
Summary
./target/profiling/parallel (resolve-warm) ran
1.55 ± 0.08 times faster than ./target/profiling/baseline (resolve-warm)
```
Our current flow of data from "simple registry package" to "final
resolved distribution" goes through a number of types:
* `SimpleMetadata` is the API response from a registry that includes all
published versions for a package. Each version has an assortment of
metadata
associated with it.
* `VersionFiles` is the aforementioned metadata. It is split in two: a
group of files for source distributions and a group of files for wheels.
* `PrioritizedDist` collects a subset of the files from `VersionFiles`
to form a selection of the "best" sdist and the "best" wheel for the
current environment.
* `CompatibleDist` is created from a borrowed `PrioritizedDist` that,
perhaps among other things, encapsulates the decision of whether to pick
an sdist or a wheel. (This decision depends both on compatibility and
the action being performed. e.g., When doing installation, a
`CompatibleDist` will sometimes select an sdist over a wheel.)
* `ResolvedDistRef` is like a `ResolvedDist`, but borrows a `Dist`.
* `ResolvedDist` is the almost-final-form of a distribution in a
resolution and is created from a `ResolvedDistRef`.
* `AnnotatedResolvedDist` is a new data type that is the actual final
form of a distribution that a universal lock file cares about. It
bundles a `ResolvedDist` with some metadata needed to generate a lock
file.
One of the requirements of a universal lock file is that we include all
wheels (and maybe all source distributions? but at least one if it's
present) associated with a distribution. But the above flow of data (in
the step from `VersionFiles` to `PrioritizedDist`) drops all wheels
except for the best one.
To remedy this, in this PR, we rejigger `PrioritizedDist`,
`CompatibleDist` and `ResolvedDistRef` so that all wheel data is
preserved. And when a `ResolvedDistRef` is finally turned into a
`ResolvedDist`, we copy all of the wheel data. And finally, we adjust
the `Lock` constructor to read this new data and include it in the lock
file. To make this work, we also modify `RegistryBuiltDist` so that it
can contain one or more wheels instead of just one.
One shortcoming here (called out in the code as a FIXME) is that if a
source distribution is selected as the "best" thing to use (perhaps
there are no compatible wheels), then the wheels won't end up in the
lock file. I plan to fix this in a follow-up PR.
We also aren't totally consistent on source distribution naming.
Sometimes we use `sdist`. Sometimes `source`. Sometimes `source_dist`.
I think it'd be nice to just use `sdist` everywhere, but I do prefer
the type names to be `SourceDist`. And sometimes you want function
names to match the type names (i.e., `from_source_dist`), which in turn
leads to an appearance of inconsistency. I'm open to ideas.
Closes#3351
## Summary
In `ResolutionGraph::from_state`, we have mechanisms to grab the hashes
and metadata for all distributions -- but we then throw that information
away. This PR preserves it on a new `AnnotatedDist` (yikes, open to
suggestions) that wraps `ResolvedDist` and includes (1) the hashes
(computed or from the registry) and (2) the `Metadata23`, which lets us
extract the version.
Closes https://github.com/astral-sh/uv/issues/3356.
Closes https://github.com/astral-sh/uv/issues/3357.
## Summary
It's confusing that we use `constraints` here because constraints mean
something else for us (e.g., `--constraint constraints.txt`). These are
really the dependencies of a given `PubGrubPackage` -- the type is even
called `PubGrubDependencies`.
## Summary
I think this is overall good change because it explicitly encodes (in
the type system) something that was previously implicit. I'm not a huge
fan of the names here, open to input.
It covers some of https://github.com/astral-sh/uv/issues/3506 but I
don't think it _closes_ it.
<!--
Thank you for contributing to uv! To help us out with reviewing, please
consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Just fix typos.
While `alpha-numeric` is not really a misspelling:
- it is missing from mainstream curated dictionaries, all of them
suggest `alphanumeric`;
- it is less used than `alphanumeric` (more than ⨉10 less) according to
the Google [Ngram
Viewer](https://books.google.com/ngrams/graph?content=alpha-numeric%2Calphanumeric&year_start=1900&year_end=2019&corpus=en-2019);
- it is [missing from
SCOWL](http://app.aspell.net/lookup?dict=en_US-large;words=alpha-numeric).
## Test Plan
CI jobs.
## Summary
This PR consolidates the concurrency limits used throughout `uv` and
exposes two limits, `UV_CONCURRENT_DOWNLOADS` and
`UV_CONCURRENT_BUILDS`, as environment variables.
Currently, `uv` has a number of concurrent streams that it buffers using
relatively arbitrary limits for backpressure. However, many of these
limits are conflated. We run a relatively small number of tasks overall
and should start most things as soon as possible. What we really want to
limit are three separate operations:
- File I/O. This is managed by tokio's blocking pool and we should not
really have to worry about it.
- Network I/O.
- Python build processes.
Because the current limits span a broad range of tasks, it's possible
that a limit meant for network I/O is occupied by tasks performing
builds, reading from the file system, or even waiting on a `OnceMap`. We
also don't limit build processes that end up being required to perform a
download. While this may not pose a performance problem because our
limits are relatively high, it does mean that the limits do not do what
we want, making it tricky to expose them to users
(https://github.com/astral-sh/uv/issues/1205,
https://github.com/astral-sh/uv/issues/3311).
After this change, the limits on network I/O and build processes are
centralized and managed by semaphores. All other tasks are unbuffered
(note that these tasks are still bounded, so backpressure should not be
a problem).
This still keeps the resolver state on the stack, but it organizes it
into a more structured representation. This is a precursor to
implementing resolver forking, where we will ultimately put this state
on the heap. The idea is that this will let us maintain multiple
independent resolver states that will all produce their own resolution
(and potentially other forked states).
Closes#3354
This commit touches a lot of code, but the conceptual change here is
pretty simple: make it so we can run the resolver without providing a
`MarkerEnvironment`. This also indicates that the resolver should run in
universal mode. That is, the effect of a missing marker environment is
that all marker expressions that reference the marker environment are
evaluated to `true`. That is, they are ignored. (The only markers we
evaluate in that context are extras, which are the only markers that
aren't dependent on the environment.)
One interesting change here is that a `Resolver` no longer needs an
`Interpreter`. Previously, it had only been using it to construct a
`PythonRequirement`, by filling in the installed version from the
`Interpreter` state. But we now construct a `PythonRequirement`
explicitly since its `target` Python version should no longer be tied to
the `MarkerEnvironment`. (Currently, the marker environment is mutated
such that its `python_full_version` is derived from multiple sources,
including the CLI, which I found a touch confusing.)
The change in behavior can now be observed through the
`--unstable-uv-lock-file` flag. First, without it:
```
$ cat requirements.in
anyio>=4.3.0 ; sys_platform == "linux"
anyio<4 ; sys_platform == "darwin"
$ cargo run -qp uv -- pip compile -p3.10 requirements.in
anyio==4.3.0
exceptiongroup==1.2.1
# via anyio
idna==3.7
# via anyio
sniffio==1.3.1
# via anyio
typing-extensions==4.11.0
# via anyio
```
And now with it:
```
$ cargo run -qp uv -- pip compile -p3.10 requirements.in --unstable-uv-lock-file
x No solution found when resolving dependencies:
`-> Because you require anyio>=4.3.0 and anyio<4, we can conclude that the requirements are unsatisfiable.
```
This is expected at this point because the marker expressions are being
explicitly ignored, *and* there is no forking done yet to account for
the conflict.
Pubgrub got a new feature where all unavailability is a custom, instead
of the reasonless `UnavailableDependencies` and our custom `String` type
previously (https://github.com/pubgrub-rs/pubgrub/pull/208). This PR
introduces a `UnavailableReason` that tracks either an entire version
being unusable, or a specific version. The error messages now also track
this difference properly.
The pubgrub commit is our main rebased onto the merged
https://github.com/pubgrub-rs/pubgrub/pull/208, i'll push
`konsti/main-rebase-generic-reason` to `main` after checking for rebase
problems.
## Summary
All of the resolver code is run on the main thread, so a lot of the
`Send` bounds and uses of `DashMap` and `Arc` are unnecessary. We could
also switch to using single-threaded versions of `Mutex` and `Notify` in
some places, but there isn't really a crate that provides those I would
be comfortable with using.
The `Arc` in `OnceMap` can't easily be removed because of the uv-auth
code which uses the
[reqwest-middleware](https://docs.rs/reqwest-middleware/latest/reqwest_middleware/trait.Middleware.html)
crate, that seems to adds unnecessary `Send` bounds because of
`async-trait`. We could duplicate the code and create a `OnceMapLocal`
variant, but I don't feel that's worth it.
## Introduction
PEP 621 is limited. Specifically, it lacks
* Relative path support
* Editable support
* Workspace support
* Index pinning or any sort of index specification
The semantics of urls are a custom extension, PEP 440 does not specify
how to use git references or subdirectories, instead pip has a custom
stringly format. We need to somehow support these while still stying
compatible with PEP 621.
## `tool.uv.source`
Drawing inspiration from cargo, poetry and rye, we add `tool.uv.sources`
or (for now stub only) `tool.uv.workspace`:
```toml
[project]
name = "albatross"
version = "0.1.0"
dependencies = [
"tqdm >=4.66.2,<5",
"torch ==2.2.2",
"transformers[torch] >=4.39.3,<5",
"importlib_metadata >=7.1.0,<8; python_version < '3.10'",
"mollymawk ==0.1.0"
]
[tool.uv.sources]
tqdm = { git = "https://github.com/tqdm/tqdm", rev = "cc372d09dcd5a5eabdc6ed4cf365bdb0be004d44" }
importlib_metadata = { url = "https://github.com/python/importlib_metadata/archive/refs/tags/v7.1.0.zip" }
torch = { index = "torch-cu118" }
mollymawk = { workspace = true }
[tool.uv.workspace]
include = [
"packages/mollymawk"
]
[tool.uv.indexes]
torch-cu118 = "https://download.pytorch.org/whl/cu118"
```
See `docs/specifying_dependencies.md` for a detailed explanation of the
format. The basic gist is that `project.dependencies` is what ends up on
pypi, while `tool.uv.sources` are your non-published additions. We do
support the full range or PEP 508, we just hide it in the docs and
prefer the exploded table for easier readability and less confusing with
actual url parts.
This format should eventually be able to subsume requirements.txt's
current use cases. While we will continue to support the legacy `uv pip`
interface, this is a piece of the uv's own top level interface. Together
with `uv run` and a lockfile format, you should only need to write
`pyproject.toml` and do `uv run`, which generates/uses/updates your
lockfile behind the scenes, no more pip-style requirements involved. It
also lays the groundwork for implementing index pinning.
## Changes
This PR implements:
* Reading and lowering `project.dependencies`,
`project.optional-dependencies` and `tool.uv.sources` into a new
requirements format, including:
* Git dependencies
* Url dependencies
* Path dependencies, including relative and editable
* `pip install` integration
* Error reporting for invalid `tool.uv.sources`
* Json schema integration (works in pycharm, see below)
* Draft user-level docs (see `docs/specifying_dependencies.md`)
It does not implement:
* No `pip compile` testing, deprioritizing towards our own lockfile
* Index pinning (stub definitions only)
* Development dependencies
* Workspace support (stub definitions only)
* Overrides in pyproject.toml
* Patching/replacing dependencies
One technically breaking change is that we now require user provided
pyproject.toml to be valid wrt to PEP 621. Included files still fall
back to PEP 517. That means `pip install -r requirements.txt` requires
it to be valid while `pip install -r requirements.txt` with `-e .` as
content falls back to PEP 517 as before.
## Implementation
The `pep508` requirement is replaced by a new `UvRequirement` (name up
for bikeshedding, not particularly attached to the uv prefix). The still
existing `pep508_rs::Requirement` type is a url format copied from pip's
requirements.txt and doesn't appropriately capture all features we
want/need to support. The bulk of the diff is changing the requirement
type throughout the codebase.
We still use `VerbatimUrl` in many places, where we would expect a
parsed/decomposed url type, specifically:
* Reading core metadata except top level pyproject.toml files, we fail a
step later instead if the url isn't supported.
* Allowed `Urls`.
* `PackageId` with a custom `CanonicalUrl` comparison, instead of
canonicalizing urls eagerly.
* `PubGrubPackage`: We eventually convert the `VerbatimUrl` back to a
`Dist` (`Dist::from_url`), instead of remembering the url.
* Source dist types: We use verbatim url even though we know and require
that these are supported urls we can and have parsed.
I tried to make improve the situation be replacing `VerbatimUrl`, but
these changes would require massive invasive changes (see e.g.
https://github.com/astral-sh/uv/pull/3253). A main problem is the ref
`VersionOrUrl` and applying overrides, which assume the same
requirement/url type everywhere. In its current form, this PR increases
this tech debt.
I've tried to split off PRs and commits, but the main refactoring is
still a single monolith commit to make it compile and the tests pass.
## Demo
Adding
d1ae3b85d5/pyproject.json
as json schema (v7) to pycharm for `pyproject.toml`, you can try the IDE
support already:
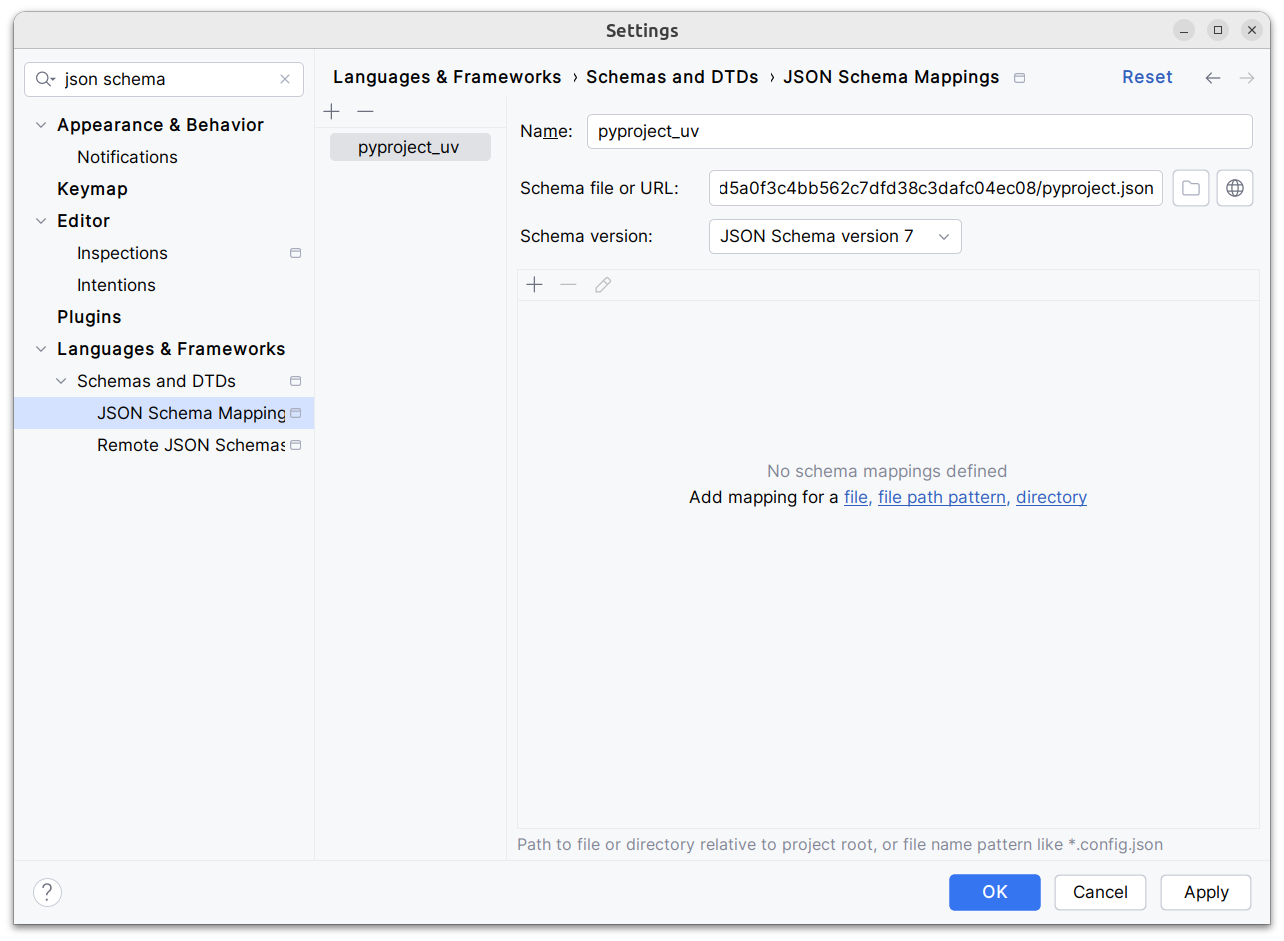
[dove.webm](https://github.com/astral-sh/uv/assets/6826232/c293c272-c80b-459d-8c95-8c46a8d198a1)
The only thing a `OnceMap` really needs to be able to do with the value
is to clone it. All extant uses benefited from having this done for them
by automatically wrapping values in an `Arc`. But this isn't necessarily
true for all things. For example, a value might have an `Arc` internally
to making cloning cheap in other contexts, and it doesn't make sense to
re-wrap it in an `Arc` just to use it with a `OnceMap`. Or
alternatively, cloning might just be cheap enough on its own that an
`Arc` isn't worth it.
## Summary
This PR avoids: (1) using the lookahead resolver when `--no-deps` is
specified (we'll never use those requirements), and (2) including any
transitive requirements when searching for allowed URLs, etc., when
`--no-deps` is specified.
Closes https://github.com/astral-sh/uv/issues/3183.
## Summary
We weren't setting a priority for editables, so they were being visited
last.
I think there's still a problem whereby we're not aggressive enough in
visiting recursive extras (and, in fact, that's making it really hard to
write a test -- I wrote a test, but the most-reduced case still fails,
and I'd need to add a layer of indirection to make it
fail-on-main-but-pass-on-this-branch), but that problem likely already
existed on main prior to #3087, so I just want to get this quick fix out
now.
Closes https://github.com/astral-sh/uv/issues/3127.
## Test Plan
- `git clone https://github.com/cda-tum/mqt-core.git`
- `cargo run venv`
- `cargo run pip install 'scikit-build-core[pyproject]>=0.8.1'
'setuptools_scm>=7' 'pybind11>=2.12' --resolution=lowest-direct`
- `cargo run pip install --no-build-isolation
'-ve.[test,qiskit,evaluation,coverage]' --resolution=lowest-direct`
Given requirements like:
```
black==23.1.0
black[colorama]
```
The resolver will (on `main`) add a dependency on Black, and then try to
use the most recent version of Black to satisfy `black[colorama]`. For
sake of example, assume `black==24.0.0` is the most recent version. Once
the selects this most recent version, it'll fetch the metadata, then
return the dependencies for `black==24.0.0` with the `colorama` extra
enabled. Finally, it will tack on `black==24.0.0` (a dependency on the
base package). The resolver will then detect a conflict between
`black==23.1.0` and `black==24.0.0`, and throw out
`black[colorama]==24.0.0`, trying to next most-recent version.
This is both wasteful and can cause problems, since we're fetching
metadata for versions that will _never_ satisfy the resolver. In the
`apache-airflow[all]` case, I also ran into an issue whereby we were
attempting to build very old versions of `apache-airflow` due to
`apache-airflow[pandas]`, which in turn led to resolution failures.
The solution proposed here is that we create a new proxy package with
exactly two dependencies: one on `black` and one of `black[colorama]`.
Both of these packages must be at the same version as the proxy package,
so the resolver knows much _earlier_ that (in the above example) the
extra variant _must_ match `23.1.0`.
## Summary
This PR enables `--require-hashes` with unnamed requirements. The key
change is that `PackageId` becomes `VersionId` (since it refers to a
package at a specific version), and the new `PackageId` consists of
_either_ a package name _or_ a URL. The hashes are keyed by `PackageId`,
so we can generate the `RequiredHashes` before we have names for all
packages, and enforce them throughout.
Closes#2979.
## Summary
This PR enables hash generation for URL requirements when the user
provides `--generate-hashes` to `pip compile`. While we include the
hashes from the registry already, today, we omit hashes for URLs.
To power hash generation, we introduce a `HashPolicy` abstraction:
```rust
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum HashPolicy<'a> {
/// No hash policy is specified.
None,
/// Hashes should be generated (specifically, a SHA-256 hash), but not validated.
Generate,
/// Hashes should be validated against a pre-defined list of hashes. If necessary, hashes should
/// be generated so as to ensure that the archive is valid.
Validate(&'a [HashDigest]),
}
```
All of the methods on the distribution database now accept this policy,
instead of accepting `&'a [HashDigest]`.
Closes#2378.
## Summary
This PR modifies the distribution database to return both the
`Metadata23` and the computed hashes when clients request metadata.
No behavior changes, but this will be necessary to power
`--generate-hashes`.
## Summary
This PR adds support for hash-checking mode in `pip install` and `pip
sync`. It's a large change, both in terms of the size of the diff and
the modifications in behavior, but it's also one that's hard to merge in
pieces (at least, with any test coverage) since it needs to work
end-to-end to be useful and testable.
Here are some of the most important highlights:
- We store hashes in the cache. Where we previously stored pointers to
unzipped wheels in the `archives` directory, we now store pointers with
a set of known hashes. So every pointer to an unzipped wheel also
includes its known hashes.
- By default, we don't compute any hashes. If the user runs with
`--require-hashes`, and the cache doesn't contain those hashes, we
invalidate the cache, redownload the wheel, and compute the hashes as we
go. For users that don't run with `--require-hashes`, there will be no
change in performance. For users that _do_, the only change will be if
they don't run with `--generate-hashes` -- then they may see some
repeated work between resolution and installation, if they use `pip
compile` then `pip sync`.
- Many of the distribution types now include a `hashes` field, like
`CachedDist` and `LocalWheel`.
- Our behavior is similar to pip, in that we enforce hashes when pulling
any remote distributions, and when pulling from our own cache. Like pip,
though, we _don't_ enforce hashes if a distribution is _already_
installed.
- Hash validity is enforced in a few different places:
1. During resolution, we enforce hash validity based on the hashes
reported by the registry. If we need to access a source distribution,
though, we then enforce hash validity at that point too, prior to
running any untrusted code. (This is enforced in the distribution
database.)
2. In the install plan, we _only_ add cached distributions that have
matching hashes. If a cached distribution is missing any hashes, or the
hashes don't match, we don't return them from the install plan.
3. In the downloader, we _only_ return distributions with matching
hashes.
4. The final combination of "things we install" are: (1) the wheels from
the cache, and (2) the downloaded wheels. So this ensures that we never
install any mismatching distributions.
- Like pip, if `--require-hashes` is provided, we require that _all_
distributions are pinned with either `==` or a direct URL. We also
require that _all_ distributions have hashes.
There are a few notable TODOs:
- We don't support hash-checking mode for unnamed requirements. These
should be _somewhat_ rare, though? Since `pip compile` never outputs
unnamed requirements. I can fix this, it's just some additional work.
- We don't automatically enable `--require-hashes` with a hash exists in
the requirements file. We require `--require-hashes`.
Closes#474.
## Test Plan
I'd like to add some tests for registries that report incorrect hashes,
but otherwise: `cargo test`
## Summary
This lets us remove circular dependencies (in the future, e.g., #2945)
that arise from `FlatIndex` needing a bunch of resolver-specific
abstractions (like incompatibilities, required hashes, etc.) that aren't
necessary to _fetch_ the flat index entries.
## Summary
If we build a source distribution from the registry, and the version
doesn't match that of the filename, we should error, just as we do for
mismatched package names. However, we should also backtrack here, which
we didn't previously.
Closes https://github.com/astral-sh/uv/issues/2953.
## Test Plan
Verified that `cargo run pip install docutils --verbose --no-cache
--reinstall` installs `docutils==0.21` instead of the invalid
`docutils==0.21.post1`.
In the logs, I see:
```
WARN Unable to extract metadata for docutils: Package metadata version `0.21` does not match given version `0.21.post1`
```
Needed to prevent circular dependencies in my toolchain work (#2931). I
think this is probably a reasonable change as we move towards persistent
configuration too?
Unfortunately `BuildIsolation` needs to be in `uv-types` to avoid
circular dependencies still. We might be able to resolve that in the
future.
With pubgrub being fast for complex ranges, we can now compute the next
n candidates without taking a performance hit. This speeds up cold cache
`urllib3<1.25.4` `boto3` from maybe 40s - 50s to ~2s. See docstrings for
details on the heuristics.
**Before**

**After**

---
We need two parts of the prefetching, first looking for compatible
version and then falling back to flat next versions. After we selected a
boto3 version, there is only one compatible botocore version remaining,
so when won't find other compatible candidates for prefetching. We see
this as a pattern where we only prefetch boto3 (stack bars), but not
botocore (sequential requests between the stacked bars).

The risk is that we're completely wrong with the guess and cause a lot
of useless network requests. I think this is acceptable since this
mechanism only triggers when we're already on the bad path and we should
simply have fetched all versions after some seconds (assuming a fast
index like pypi).
---
It would be even better if the pubgrub state was copy-on-write so we
could simulate more progress than we actually have; currently we're
guessing what the next version is which could be completely wrong, but i
think this is still a valuable heuristic.
Fixes#170.
## Summary
Is this, perhaps, not totally necessary? It doesn't show up in any
fixtures beyond those that I added recently.
Closes https://github.com/astral-sh/uv/issues/2846.
## Summary
This partially revives https://github.com/astral-sh/uv/pull/2135 (with
some modifications) to enable users to opt-in to looking for packages
across multiple indexes.
The behavior is such that, in version selection, we take _any_
compatible version from a "higher-priority" index over the compatible
versions of a "lower-priority" index, even if that means we might accept
an "older" version.
Closes https://github.com/astral-sh/uv/issues/2775.
## Summary
Rather than storing the `redirects` on the resolver, this PR just
re-uses the "convert this URL to precise" logic when we convert to a
`Resolution` after-the-fact. I think this is a lot simpler: it removes
state from the resolver, and simplifies a lot of the hooks around
distribution fetching (e.g., `get_or_build_wheel_metadata` no longer
returns `(Metadata23, Option<Url>)`).
## Summary
This fixes a potential bug that revealed itself in
https://github.com/astral-sh/uv/pull/2761. We don't run into this now
because we always use "allowed URLs", stores the "last" compatible URL
in the map. But the use of the "raw" URL (rather than the "canonical"
URL) means that other writers have to follow that same assumption and
iterate over dependencies in-order.
## Summary
We can access cache from `BuildContext`. This mirrors
`SourceDistCachedBuilder`, which doesn't accept `Cache` as an argument
and always accesses it through `BuildContext`.
Previously, we did not consider installed distributions as candidates
while performing resolution. Here, we update the resolver to use
installed distributions that satisfy requirements instead of pulling new
distributions from the registry.
The implementation details are as follows:
- We now provide `SitePackages` to the `CandidateSelector`
- If an installed distribution satisfies the requirement, we prefer it
over remote distributions
- We do not want to allow installed distributions in some cases, i.e.,
upgrade and reinstall
- We address this by introducing an `Exclusions` type which tracks
installed packages to ignore during selection
- There's a new `ResolvedDist` wrapper with `Installed(InstalledDist)`
and `Installable(Dist)` variants
- This lets us pass already installed distributions throughout the
resolver
The user-facing behavior is thoroughly covered in the tests, but
briefly:
- Installing a package that depends on an already-installed package
prefers the local version over the index
- Installing a package with a name that matches an already-installed URL
package does not reinstall from the index
- Reinstalling (--reinstall) a package by name _will_ pull from the
index even if an already-installed URL package is present
- To reinstall the URL package, you must specify the URL in the request
Closes https://github.com/astral-sh/uv/issues/1661
Addresses:
- https://github.com/astral-sh/uv/issues/1476
- https://github.com/astral-sh/uv/issues/1856
- https://github.com/astral-sh/uv/issues/2093
- https://github.com/astral-sh/uv/issues/2282
- https://github.com/astral-sh/uv/issues/2383
- https://github.com/astral-sh/uv/issues/2560
## Test plan
- [x] Reproduction at `charlesnicholson/uv-pep420-bug` passes
- [x] Unit test for editable package
([#1476](https://github.com/astral-sh/uv/issues/1476))
- [x] Unit test for previously installed package with empty registry
- [x] Unit test for local non-editable package
- [x] Unit test for new version available locally but not in registry
([#2093](https://github.com/astral-sh/uv/issues/2093))
- ~[ ] Unit test for wheel not available in registry but already
installed locally
([#2282](https://github.com/astral-sh/uv/issues/2282))~ (seems
complicated and not worthwhile)
- [x] Unit test for install from URL dependency then with matching
version ([#2383](https://github.com/astral-sh/uv/issues/2383))
- [x] Unit test for install of new package that depends on installed
package does not change version
([#2560](https://github.com/astral-sh/uv/issues/2560))
- [x] Unit test that `pip compile` does _not_ consider installed
packages
## Summary
This looks like a big change but it really isn't. Rather, I just split
`get_or_build_wheel` into separate `get_wheel` and `build_wheel` methods
internally, which made `get_or_build_wheel_metadata` capable of _not_
relying on `Tags`, which in turn makes it easier for us to use the
`DistributionDatabase` in various places without having it coupled to an
interpreter or environment (something we already did for
`SourceDistributionBuilder`).
This is driving me a little crazy and is becoming a larger problem in
#2596 where I need to move more types (like `Upgrade` and `Reinstall`)
into this crate. Anything that's shared across our core resolver,
install, and build crates needs to be defined in this crate to avoid
cyclic dependencies. We've outgrown it being a single file with some
shared traits.
There are no behavioral changes here.
## Summary
When a user runs with `--output-file` and `--generate-hashes`, we should
_only_ update the hashes if the pinned version itself changes.
Closes https://github.com/astral-sh/uv/issues/1530.
## Summary
This PR adds limited support for PEP 440-compatible local version
testing. Our behavior is _not_ comprehensively in-line with the spec.
However, it does fix by _far_ the biggest practical limitation, and
resolves all the issues that've been raised on uv related to local
versions without introducing much complexity into the resolver, so it
feels like a good tradeoff for me.
I'll summarize the change here, but for more context, see [Andrew's
write-up](https://github.com/astral-sh/uv/issues/1855#issuecomment-1967024866)
in the linked issue.
Local version identifiers are really tricky because of asymmetry.
`==1.2.3` should allow `1.2.3+foo`, but `==1.2.3+foo` should not allow
`1.2.3`. It's very hard to map them to PubGrub, because PubGrub doesn't
think of things in terms of individual specifiers (unlike the PEP 440
spec) -- it only thinks in terms of ranges.
Right now, resolving PyTorch and friends fails, because...
- The user provides requirements like `torch==2.0.0+cu118` and
`torchvision==0.15.1+cu118`.
- We then match those exact versions.
- We then look at the requirements of `torchvision==0.15.1+cu118`, which
includes `torch==2.0.0`.
- Under PEP 440, this is fine, because `torch @ 2.0.0+cu118` should be
compatible with `torch==2.0.0`.
- In our model, though, it's not, because these are different versions.
If we change our comparison logic in various places to allow this, we
risk breaking some fundamental assumptions of PubGrub around version
continuity.
- Thus, we fail to resolve, because we can't accept both `torch @ 2.0.0`
and `torch @ 2.0.0+cu118`.
As compared to the solutions we explored in
https://github.com/astral-sh/uv/issues/1855#issuecomment-1967024866, at
a high level, this approach differs in that we lie about the
_dependencies_ of packages that rely on our local-version-using package,
rather than lying about the versions that exist, or the version we're
returning, etc.
In short:
- When users specify local versions upfront, we keep track of them. So,
above, we'd take note of `torch` and `torchvision`.
- When we convert the dependencies of a package to PubGrub ranges, we
check if the requirement matches `torch` or `torchvision`. If it's
an`==`, we check if it matches (in the above example) for
`torch==2.0.0`. If so, we _change_ the requirement to
`torch==2.0.0+cu118`. (If it's `==` some other version, we return an
incompatibility.)
In other words, we selectively override the declared dependencies by
making them _more specific_ if a compatible local version was specified
upfront.
The net effect here is that the motivating PyTorch resolutions all work.
And, in general, transitive local versions work as expected.
The thing that still _doesn't_ work is: imagine if there were _only_
local versions of `torch` available. Like, `torch @ 2.0.0` didn't exist,
but `torch @ 2.0.0+cpu` did, and `torch @ 2.0.0+gpu` did, and so on.
`pip install torch==2.0.0` would arbitrarily choose one one `2.0.0+cpu`
or `2.0.0+gpu`, and that's correct as per PEP 440 (local version
segments should be completely ignored on `torch==2.0.0`). However, uv
would fail to identify a compatible version. I'd _probably_ prefer to
fix this, although candidly I think our behavior is _ok_ in practice,
and it's never been reported as an issue.
Closes https://github.com/astral-sh/uv/issues/1855.
Closes https://github.com/astral-sh/uv/issues/2080.
Closes https://github.com/astral-sh/uv/issues/2328.
## Summary
Per [PEP 508](https://peps.python.org/pep-0508/), `python_version` is
just major and minor:

Right now, we're using the provided version directly, so if it's, e.g.,
`-p 3.11.8`, we'll inject the wrong marker. This was causing `pandas` to
omit `numpy` when `-p 3.11.8` was provided, since its markers look like:
```
Requires-Dist: numpy<2,>=1.22.4; python_version < "3.11"
Requires-Dist: numpy<2,>=1.23.2; python_version == "3.11"
Requires-Dist: numpy<2,>=1.26.0; python_version >= "3.12"
```
Closes https://github.com/astral-sh/uv/issues/2392.
## Summary
This is a more robust fix for
https://github.com/astral-sh/uv/issues/2300.
The basic issue is:
- When we resolve, we attempt to pre-fetch the distribution metadata for
candidate packages.
- It's possible that the resolution completes _without_ those pre-fetch
responses. (In the linked issue, this was mainly because we were running
with `--no-deps`, but the pre-fetch was causing us to attempt to build a
package to get its dependencies. The resolution would then finish before
the build completed.)
- In that case, the `Index` will be marked as "waiting" for that
response -- but it'll never come through.
- If there's a subsequent call to the `Index`, to see if we should fetch
or are waiting for that response, we'll end up waiting for it forever,
since it _looks_ like it's in-flight (but isn't). (In the linked issue,
we had to build the source distribution for the install phase of `pip
install`, but `setuptools` was in this bad state from the _resolve_
phase.)
This PR modifies the resolver to ensure that we flush the stream of
requests before returning. Specifically, we now `join` rather than
`select` between the resolution and request-handling futures.
This _could_ be wasteful, since we don't _need_ those requests, but it
at least ensures that every `.wait` is followed by ` .done`. In
practice, I expect this not to have any significant effect on
performance, since we end up using the pre-fetched distributions almost
every time.
## Test Plan
I ran through the test plan from
https://github.com/astral-sh/uv/pull/2373, but ran the build 10 times
and ensured it never crashed. (I reverted
https://github.com/astral-sh/uv/pull/2373, since that _also_ fixes the
issue in the proximate case, by never fetching `setuptools` during the
resolve phase.)
I also added logging to verify that requests are being handled _after_
the resolution completes, as expected.
I also introduced an arbitrary error in `fetch` to ensure that the error
was immediately propagated.
## Summary
When running under `--no-deps`, we don't need to pre-fetch, because
pre-fetching fetches the _distribution_ metadata. But with `--no-deps`,
we only need the package metadata for the top-level requirements. We
never need distribution metadata.
Incidentally, this will fix https://github.com/astral-sh/uv/issues/2300.
## Test Plan
- `cargo test`
- `./target/debug/uv pip install --verbose --no-cache-dir --no-deps
--reinstall ddtrace==2.6.2 debugpy==1.8.1 ecdsa==0.18.0
editorconfig==0.12.4 --verbose` in a Python 3.10 Docker contain
repeatedly.