mirror of
https://github.com/astral-sh/ruff
synced 2026-01-21 21:40:51 -05:00
Index source code upfront to power (row, column) lookups (#1990)
## Summary The problem: given a (row, column) number (e.g., for a token in the AST), we need to be able to map it to a precise byte index in the source code. A while ago, we moved to `ropey` for this, since it was faster in practice (mostly, I think, because it's able to defer indexing). However, at some threshold of accesses, it becomes faster to index the string in advance, as we're doing here. ## Benchmark It looks like this is ~3.6% slower for the default rule set, but ~9.3% faster for `--select ALL`. **I suspect there's a strategy that would be strictly faster in both cases**, based on deferring even more computation (right now, we lazily compute these offsets, but we do it for the entire file at once, even if we only need some slice at the top), or caching the `ropey` lookups in some way. Before: 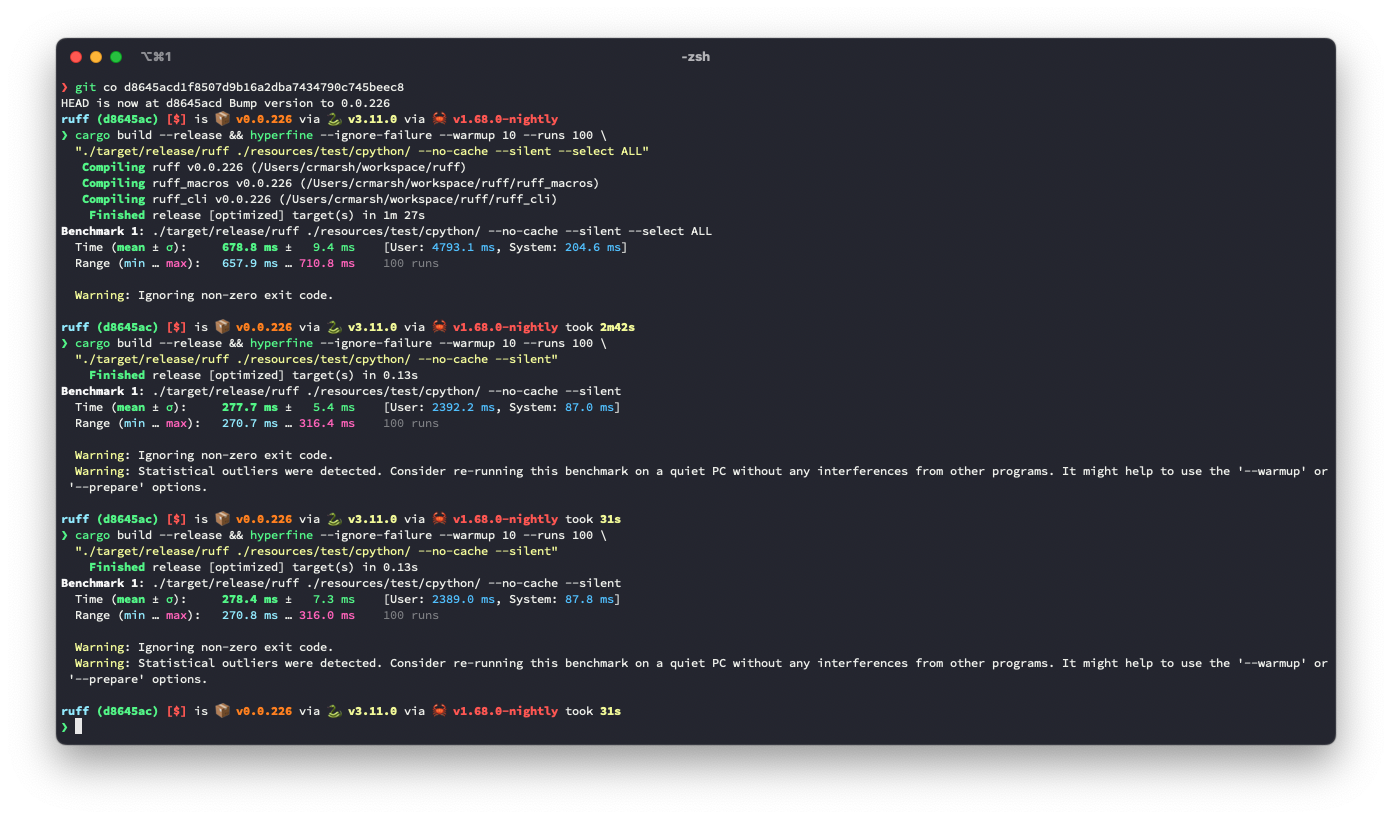 After: 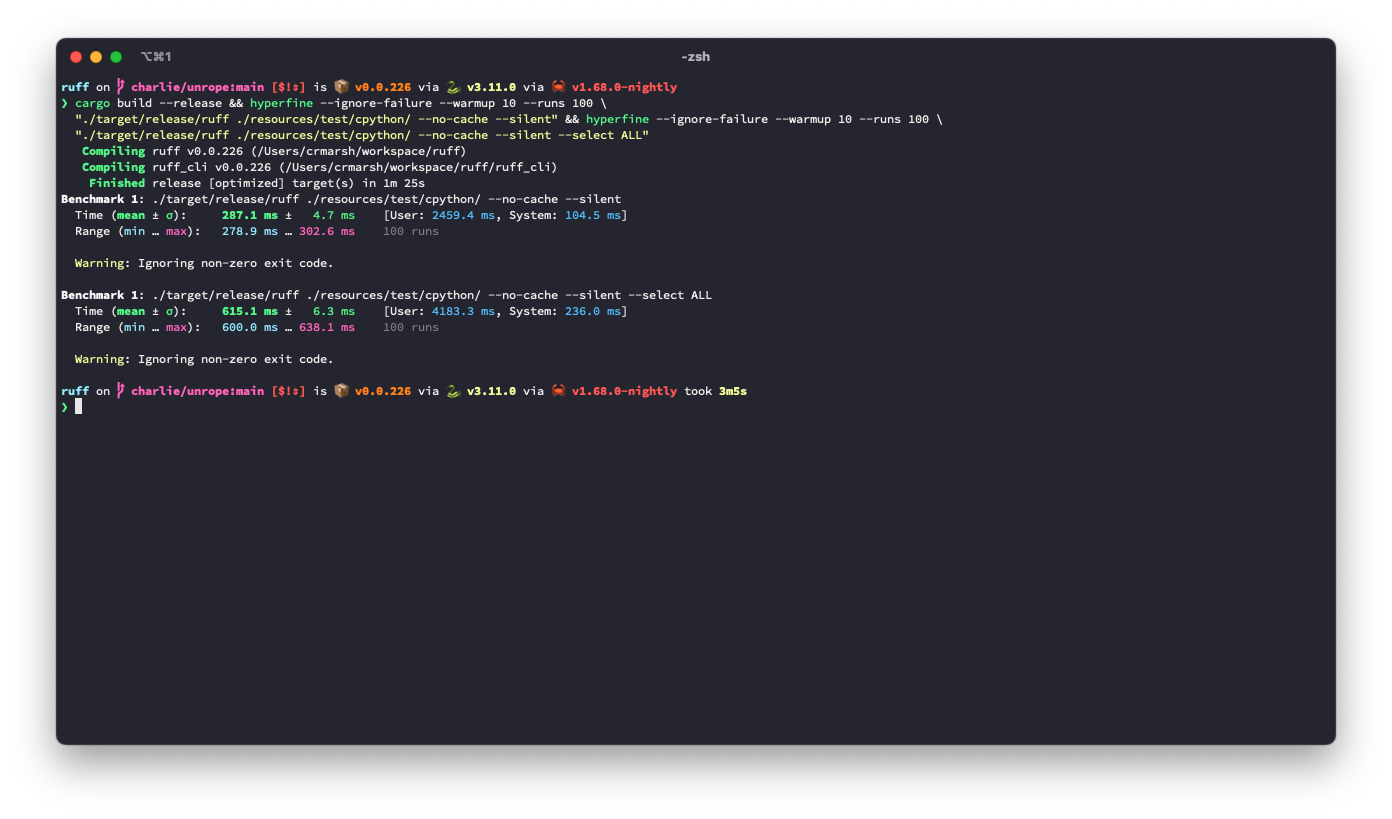 ## Alternatives I tried tweaking the `Vec::with_capacity` hints, and even trying `Vec::with_capacity(str_indices::lines_crlf::count_breaks(contents))` to do a quick scan of the number of lines, but that turned out to be slower.
{kind=link}
{kind=link}
This commit is contained in:
@@ -1,65 +1,256 @@
|
||||
//! Struct used to efficiently slice source code at (row, column) Locations.
|
||||
|
||||
use std::borrow::Cow;
|
||||
|
||||
use once_cell::unsync::OnceCell;
|
||||
use ropey::Rope;
|
||||
use rustpython_ast::Location;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
|
||||
pub struct Locator<'a> {
|
||||
contents: &'a str,
|
||||
rope: OnceCell<Rope>,
|
||||
index: OnceCell<Index>,
|
||||
}
|
||||
|
||||
pub enum Index {
|
||||
Ascii(Vec<usize>),
|
||||
Utf8(Vec<Vec<usize>>),
|
||||
}
|
||||
|
||||
/// Compute the starting byte index of each line in ASCII source code.
|
||||
fn index_ascii(contents: &str) -> Vec<usize> {
|
||||
let mut index = Vec::with_capacity(48);
|
||||
index.push(0);
|
||||
let bytes = contents.as_bytes();
|
||||
for (i, byte) in bytes.iter().enumerate() {
|
||||
if *byte == b'\n' {
|
||||
index.push(i + 1);
|
||||
}
|
||||
}
|
||||
index
|
||||
}
|
||||
|
||||
/// Compute the starting byte index of each character in UTF-8 source code.
|
||||
fn index_utf8(contents: &str) -> Vec<Vec<usize>> {
|
||||
let mut index = Vec::with_capacity(48);
|
||||
let mut current_row = Vec::with_capacity(48);
|
||||
let mut current_byte_offset = 0;
|
||||
let mut previous_char = '\0';
|
||||
for char in contents.chars() {
|
||||
current_row.push(current_byte_offset);
|
||||
if char == '\n' {
|
||||
if previous_char == '\r' {
|
||||
current_row.pop();
|
||||
}
|
||||
index.push(current_row);
|
||||
current_row = Vec::with_capacity(48);
|
||||
}
|
||||
current_byte_offset += char.len_utf8();
|
||||
previous_char = char;
|
||||
}
|
||||
index.push(current_row);
|
||||
index
|
||||
}
|
||||
|
||||
/// Compute the starting byte index of each line in source code.
|
||||
pub fn index(contents: &str) -> Index {
|
||||
if contents.is_ascii() {
|
||||
Index::Ascii(index_ascii(contents))
|
||||
} else {
|
||||
Index::Utf8(index_utf8(contents))
|
||||
}
|
||||
}
|
||||
|
||||
/// Truncate a [`Location`] to a byte offset in ASCII source code.
|
||||
fn truncate_ascii(location: Location, index: &[usize], contents: &str) -> usize {
|
||||
if location.row() - 1 == index.len() && location.column() == 0
|
||||
|| (!index.is_empty()
|
||||
&& location.row() - 1 == index.len() - 1
|
||||
&& index[location.row() - 1] + location.column() >= contents.len())
|
||||
{
|
||||
contents.len()
|
||||
} else {
|
||||
index[location.row() - 1] + location.column()
|
||||
}
|
||||
}
|
||||
|
||||
/// Truncate a [`Location`] to a byte offset in UTF-8 source code.
|
||||
fn truncate_utf8(location: Location, index: &[Vec<usize>], contents: &str) -> usize {
|
||||
if (location.row() - 1 == index.len() && location.column() == 0)
|
||||
|| (location.row() - 1 == index.len() - 1
|
||||
&& location.column() == index[location.row() - 1].len())
|
||||
{
|
||||
contents.len()
|
||||
} else {
|
||||
index[location.row() - 1][location.column()]
|
||||
}
|
||||
}
|
||||
|
||||
/// Truncate a [`Location`] to a byte offset in source code.
|
||||
fn truncate(location: Location, index: &Index, contents: &str) -> usize {
|
||||
match index {
|
||||
Index::Ascii(index) => truncate_ascii(location, index, contents),
|
||||
Index::Utf8(index) => truncate_utf8(location, index, contents),
|
||||
}
|
||||
}
|
||||
|
||||
impl<'a> Locator<'a> {
|
||||
pub fn new(contents: &'a str) -> Self {
|
||||
Locator {
|
||||
contents,
|
||||
rope: OnceCell::default(),
|
||||
index: OnceCell::new(),
|
||||
}
|
||||
}
|
||||
|
||||
fn get_or_init_rope(&self) -> &Rope {
|
||||
self.rope.get_or_init(|| Rope::from_str(self.contents))
|
||||
fn get_or_init_index(&self) -> &Index {
|
||||
self.index.get_or_init(|| index(self.contents))
|
||||
}
|
||||
|
||||
pub fn slice_source_code_at(&self, location: Location) -> Cow<'_, str> {
|
||||
let rope = self.get_or_init_rope();
|
||||
let offset = rope.line_to_char(location.row() - 1) + location.column();
|
||||
Cow::from(rope.slice(offset..))
|
||||
pub fn slice_source_code_until(&self, location: Location) -> &'a str {
|
||||
let index = self.get_or_init_index();
|
||||
let offset = truncate(location, index, self.contents);
|
||||
&self.contents[..offset]
|
||||
}
|
||||
|
||||
pub fn slice_source_code_until(&self, location: Location) -> Cow<'_, str> {
|
||||
let rope = self.get_or_init_rope();
|
||||
let offset = rope.line_to_char(location.row() - 1) + location.column();
|
||||
Cow::from(rope.slice(..offset))
|
||||
pub fn slice_source_code_at(&self, location: Location) -> &'a str {
|
||||
let index = self.get_or_init_index();
|
||||
let offset = truncate(location, index, self.contents);
|
||||
&self.contents[offset..]
|
||||
}
|
||||
|
||||
pub fn slice_source_code_range(&self, range: &Range) -> Cow<'_, str> {
|
||||
let rope = self.get_or_init_rope();
|
||||
let start = rope.line_to_char(range.location.row() - 1) + range.location.column();
|
||||
let end = rope.line_to_char(range.end_location.row() - 1) + range.end_location.column();
|
||||
Cow::from(rope.slice(start..end))
|
||||
pub fn slice_source_code_range(&self, range: &Range) -> &'a str {
|
||||
let index = self.get_or_init_index();
|
||||
let start = truncate(range.location, index, self.contents);
|
||||
let end = truncate(range.end_location, index, self.contents);
|
||||
&self.contents[start..end]
|
||||
}
|
||||
|
||||
pub fn partition_source_code_at(
|
||||
&self,
|
||||
outer: &Range,
|
||||
inner: &Range,
|
||||
) -> (Cow<'_, str>, Cow<'_, str>, Cow<'_, str>) {
|
||||
let rope = self.get_or_init_rope();
|
||||
let outer_start = rope.line_to_char(outer.location.row() - 1) + outer.location.column();
|
||||
let outer_end =
|
||||
rope.line_to_char(outer.end_location.row() - 1) + outer.end_location.column();
|
||||
let inner_start = rope.line_to_char(inner.location.row() - 1) + inner.location.column();
|
||||
let inner_end =
|
||||
rope.line_to_char(inner.end_location.row() - 1) + inner.end_location.column();
|
||||
) -> (&'a str, &'a str, &'a str) {
|
||||
let index = self.get_or_init_index();
|
||||
let outer_start = truncate(outer.location, index, self.contents);
|
||||
let outer_end = truncate(outer.end_location, index, self.contents);
|
||||
let inner_start = truncate(inner.location, index, self.contents);
|
||||
let inner_end = truncate(inner.end_location, index, self.contents);
|
||||
(
|
||||
Cow::from(rope.slice(outer_start..inner_start)),
|
||||
Cow::from(rope.slice(inner_start..inner_end)),
|
||||
Cow::from(rope.slice(inner_end..outer_end)),
|
||||
&self.contents[outer_start..inner_start],
|
||||
&self.contents[inner_start..inner_end],
|
||||
&self.contents[inner_end..outer_end],
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use rustpython_ast::Location;
|
||||
|
||||
use crate::source_code::locator::{index_ascii, index_utf8, truncate_ascii, truncate_utf8};
|
||||
|
||||
#[test]
|
||||
fn ascii_index() {
|
||||
let contents = "";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0]);
|
||||
|
||||
let contents = "x = 1";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0]);
|
||||
|
||||
let contents = "x = 1\n";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0, 6]);
|
||||
|
||||
let contents = "x = 1\r\n";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0, 7]);
|
||||
|
||||
let contents = "x = 1\ny = 2\nz = x + y\n";
|
||||
let index = index_ascii(contents);
|
||||
assert_eq!(index, [0, 6, 12, 22]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn ascii_truncate() {
|
||||
let contents = "x = 1\ny = 2";
|
||||
let index = index_ascii(contents);
|
||||
|
||||
// First row.
|
||||
let loc = truncate_ascii(Location::new(1, 0), &index, contents);
|
||||
assert_eq!(loc, 0);
|
||||
|
||||
// Second row.
|
||||
let loc = truncate_ascii(Location::new(2, 0), &index, contents);
|
||||
assert_eq!(loc, 6);
|
||||
|
||||
// One-past-the-end.
|
||||
let loc = truncate_ascii(Location::new(3, 0), &index, contents);
|
||||
assert_eq!(loc, 11);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn utf8_index() {
|
||||
let contents = "";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 1);
|
||||
assert_eq!(index[0], Vec::<usize>::new());
|
||||
|
||||
let contents = "x = 1";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 1);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4]);
|
||||
|
||||
let contents = "x = 1\n";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 2);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4, 5]);
|
||||
assert_eq!(index[1], Vec::<usize>::new());
|
||||
|
||||
let contents = "x = 1\r\n";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 2);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4, 5]);
|
||||
assert_eq!(index[1], Vec::<usize>::new());
|
||||
|
||||
let contents = "x = 1\ny = 2\nz = x + y\n";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 4);
|
||||
assert_eq!(index[0], [0, 1, 2, 3, 4, 5]);
|
||||
assert_eq!(index[1], [6, 7, 8, 9, 10, 11]);
|
||||
assert_eq!(index[2], [12, 13, 14, 15, 16, 17, 18, 19, 20, 21]);
|
||||
assert_eq!(index[3], Vec::<usize>::new());
|
||||
|
||||
let contents = "# \u{4e9c}\nclass Foo:\n \"\"\".\"\"\"";
|
||||
let index = index_utf8(contents);
|
||||
assert_eq!(index.len(), 3);
|
||||
assert_eq!(index[0], [0, 1, 2, 5]);
|
||||
assert_eq!(index[1], [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]);
|
||||
assert_eq!(index[2], [17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn utf8_truncate() {
|
||||
let contents = "x = '☃'\ny = 2";
|
||||
let index = index_utf8(contents);
|
||||
|
||||
// First row.
|
||||
let loc = truncate_utf8(Location::new(1, 0), &index, contents);
|
||||
assert_eq!(loc, 0);
|
||||
|
||||
let loc = truncate_utf8(Location::new(1, 5), &index, contents);
|
||||
assert_eq!(loc, 5);
|
||||
assert_eq!(&contents[loc..], "☃'\ny = 2");
|
||||
|
||||
let loc = truncate_utf8(Location::new(1, 6), &index, contents);
|
||||
assert_eq!(loc, 8);
|
||||
assert_eq!(&contents[loc..], "'\ny = 2");
|
||||
|
||||
// Second row.
|
||||
let loc = truncate_utf8(Location::new(2, 0), &index, contents);
|
||||
assert_eq!(loc, 10);
|
||||
|
||||
// One-past-the-end.
|
||||
let loc = truncate_utf8(Location::new(3, 0), &index, contents);
|
||||
assert_eq!(loc, 15);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -170,7 +170,7 @@ fn detect_quote(contents: &str, locator: &Locator) -> Option<Quote> {
|
||||
for (start, tok, end) in lexer::make_tokenizer(contents).flatten() {
|
||||
if let Tok::String { .. } = tok {
|
||||
let content = locator.slice_source_code_range(&Range::new(start, end));
|
||||
if let Some(pattern) = leading_quote(&content) {
|
||||
if let Some(pattern) = leading_quote(content) {
|
||||
if pattern.contains('\'') {
|
||||
return Some(Quote::Single);
|
||||
} else if pattern.contains('"') {
|
||||
|
||||
Reference in New Issue
Block a user