## Summary
Changes `future-rewritable-type-annotation` (`FA100`) message to be less
confusing. Uses phrasing from the rule documentation to be consistent.
For example,
```
from_typing_import.py:5:13: FA100 Add `from __future__ import annotations` to rewrite `typing.List` more succinctly
```
Closes#10573.
## Test Plan
`cargo nextest run`
## Summary
Should this consider the decorator only if the name is actually a
property or is the logic in this PR correct?
fixes: #11358
## Test Plan
Add test case.
## Summary
This PR fixes a bug where the auto-fix for `TCH005` would delete the
entire `if` statement.
The fix in this PR is to not consider it a violation if there are any
`elif`/`else` blocks. This also matches the behavior of the original
plugin.
fixes: #11368
## Test plan
Add test cases.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/10594.
Code actions to disable a diagnostic via `noqa` comment are now
available.
https://github.com/astral-sh/ruff/assets/19577865/6d3bcf11-a9d9-499b-8c7f-a10cd39cfbba
`DiagnosticFix` has been changed so that `noqa` code actions appear even
for diagnostics with no available quick fix. It can contain quick fix
edits, `noqa` comment edits, or both.
## Test Plan
The scenarios that need to be tested are as follows:
* A code action to disable a diagnostic should be available for every
diagnostic.
* Using this code action should append to the appropriate line with the
diagnostic, or modify an existing `noqa` comment.
* Adding a `noqa` comment manually should make a diagnostic disappear
* `Fix all auto-fixable problems` should not add `noqa` comments
* Removing a code from a `noqa` comment should make the diagnostic
re-appear
## Summary
`--add-noqa` now runs in two stages: first, the linter finds all
diagnostics that need noqa comments and generate edits on a per-line
basis. Second, these edits are applied, in order, to the document.
A public-facing function, `generate_noqa_edits`, has also been
introduced, which returns noqa edits generated on a per-diagnostic
basis. This will be used by `ruff server` for noqa comment quick-fixes.
## Test Plan
Unit tests have been updated.
## Summary
This PR adds updates the semantic model to detect attribute docstring.
Refer to [PEP 258](https://peps.python.org/pep-0258/#attribute-docstrings)
for the definition of an attribute docstring.
This PR doesn't add full support for it but only considers string
literals as attribute docstring for the following cases:
1. A string literal following an assignment statement in the **global
scope**.
2. A global class attribute
For an assignment statement, it's considered an attribute docstring only
if the target expression is a name expression (`x = 1`). So, chained
assignment, multiple assignment or unpacking, and starred expression,
which are all valid in the target position, aren't considered here.
In `__init__` method, an assignment to the `self` variable like `self.x = 1`
is also a candidate for an attribute docstring. **This PR does not
support this position.**
## Test Plan
I used the following source code along with a print statement to verify
that the attribute docstring detection is correct.
Refer to the PR description for the code snippet.
I'll add this in the follow-up PR
(https://github.com/astral-sh/ruff/pull/11302) which uses this method.
## Summary
Lots of TODOs and things to clean up here, but it demonstrates the
working lint rule.
## Test Plan
```
➜ cat main.py
from typing import override
from base import B
class C(B):
@override
def method(self): pass
➜ cat base.py
class B: pass
➜ cat typing.py
def override(func):
return func
```
(We provide our own `typing.py` since we don't have typeshed vendored or
type stub support yet.)
```
➜ ./target/debug/red_knot main.py
...
1 0.012086s TRACE red_knot Main Loop: Tick
[crates/red_knot/src/main.rs:157:21] diagnostics = [
"Method C.method is decorated with `typing.override` but does not override any base class method",
]
```
If we add `def method(self): pass` to class `B` in `base.py` and run
red_knot again, there is no lint error.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves#11263
Detect `pathlib.Path.open` calls which do not specify a file encoding.
## Test Plan
Test cases added to fixture.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
This PR vendors typeshed!
- The first commit vendors the stdlib directory from typeshed into a new crates/red_knot/vendored_typeshed directory.
- The second commit adjusts various linting config files to make sure that the vendored code is excluded from typo checks, formatting checks, etc.
- The LICENSE and README.md files are also vendored, but all other directories and files (stubs, scripts, tests, test_cases, etc.) are excluded. We should have no need for them (except possibly stubs/, discussed in more depth below).
- Similar to the way pyright has a commit.txt file in its vendored copy of typeshed, to indicate which typeshed commit the vendored code corresponds to, I've also added a crates/red_knot/vendored_typeshed/source_commit.txt file in the third commit of this PR.
One open question is: should we vendor the stdlib and stubs directories, or just the stdlib directory? The stubs/ directory contains stubs for 162 third-party packages outside the stdlib. Mypy and typeshed_client1 only vendor the stdlib directory; pyright and pyre vendor both the stdlib and stubs directories; pytype vendors the entire typeshed repo (scripts/, tests/ and all).
In this PR, I've chosen to copy mypy and typeshed_client. Unlike vendoring the stdlib, which is unavoidable if we want to do typechecking of the stdlib, it's not strictly necessary to vendor the stubs directory: each subdirectory in stubs is published to PyPI as a standalone stubs distribution that can be (uv)-pip-installed into a virtual environment. It might be useful for our users if we vendored those stubs anyway, but there are costs as well as benefits to doing so (apart from just the sheer amount of vendored code in the ruff repository), so I'd rather consider it separately.
Resolves https://github.com/astral-sh/ruff/issues/11313
## Summary
PLR0912(too-many-branches) did not count branches inside with: blocks.
With this fix, the branches inside with statements are also counted.
## Test Plan
Added a new test case.
## Summary
This PR removes the cyclic dev dependency some of the crates had with
the parser crate.
The cyclic dependencies are:
* `ruff_python_ast` has a **dev dependency** on `ruff_python_parser` and
`ruff_python_parser` directly depends on `ruff_python_ast`
* `ruff_python_trivia` has a **dev dependency** on `ruff_python_parser`
and `ruff_python_parser` has an indirect dependency on
`ruff_python_trivia` (`ruff_python_parser` - `ruff_python_ast` -
`ruff_python_trivia`)
Specifically, this PR does the following:
* Introduce two new crates
* `ruff_python_ast_integration_tests` and move the tests from the
`ruff_python_ast` crate which uses the parser in this crate
* `ruff_python_trivia_integration_tests` and move the tests from the
`ruff_python_trivia` crate which uses the parser in this crate
### Motivation
The main motivation for this PR is to help development. Before this PR,
`rust-analyzer` wouldn't provide any intellisense in the
`ruff_python_parser` crate regarding the symbols in `ruff_python_ast`
crate.
```
[ERROR][2024-05-03 13:47:06] .../vim/lsp/rpc.lua:770 "rpc" "/Users/dhruv/.cargo/bin/rust-analyzer" "stderr" "[ERROR project_model::workspace] cyclic deps: ruff_python_parser(Idx::<CrateData>(50)) -> ruff_python_ast(Idx::<CrateData>(37)), alternative path: ruff_python_ast(Idx::<CrateData>(37)) -> ruff_python_parser(Idx::<CrateData>(50))\n"
```
## Test Plan
Check the logs of `rust-analyzer` to not see any signs of cyclic
dependency.
## Summary
While I was here, I also updated the rule to use
`function_type::classify` rather than hard-coding `staticmethod` and
friends.
Per Carl:
> Enum instances are already referred to by the class, forming a cycle
that won't get collected until the class itself does. At which point the
`lru_cache` itself would be collected, too.
Closes https://github.com/astral-sh/ruff/issues/9912.
## Summary
Historically, we only ignored `flake8-blind-except` if you re-raised or
logged the exception as a _direct_ child statement; but it could be
nested somewhere. This was just a known limitation at the time of adding
the previous logic.
Closes https://github.com/astral-sh/ruff/issues/11289.
## Summary
A follow-up to https://github.com/astral-sh/ruff/pull/11222. `ruff
server` stalls during shutdown with Neovim because after it receives an
exit notification and closes the I/O thread, it attempts to log a
success message to `stderr`. Removing this log statement fixes this
issue.
## Test Plan
Track the instances of `ruff` in the OS task manager as you open and
close Neovim. A new instance should appear when Neovim starts and it
should disappear once Neovim is closed.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11258.
This PR fixes the settings resolver to match the expected behavior when
file-based configuration is not available.
## Test Plan
In a workspace with no file-based configuration, set a setting in your
editor and confirm that this setting is used instead of the default.
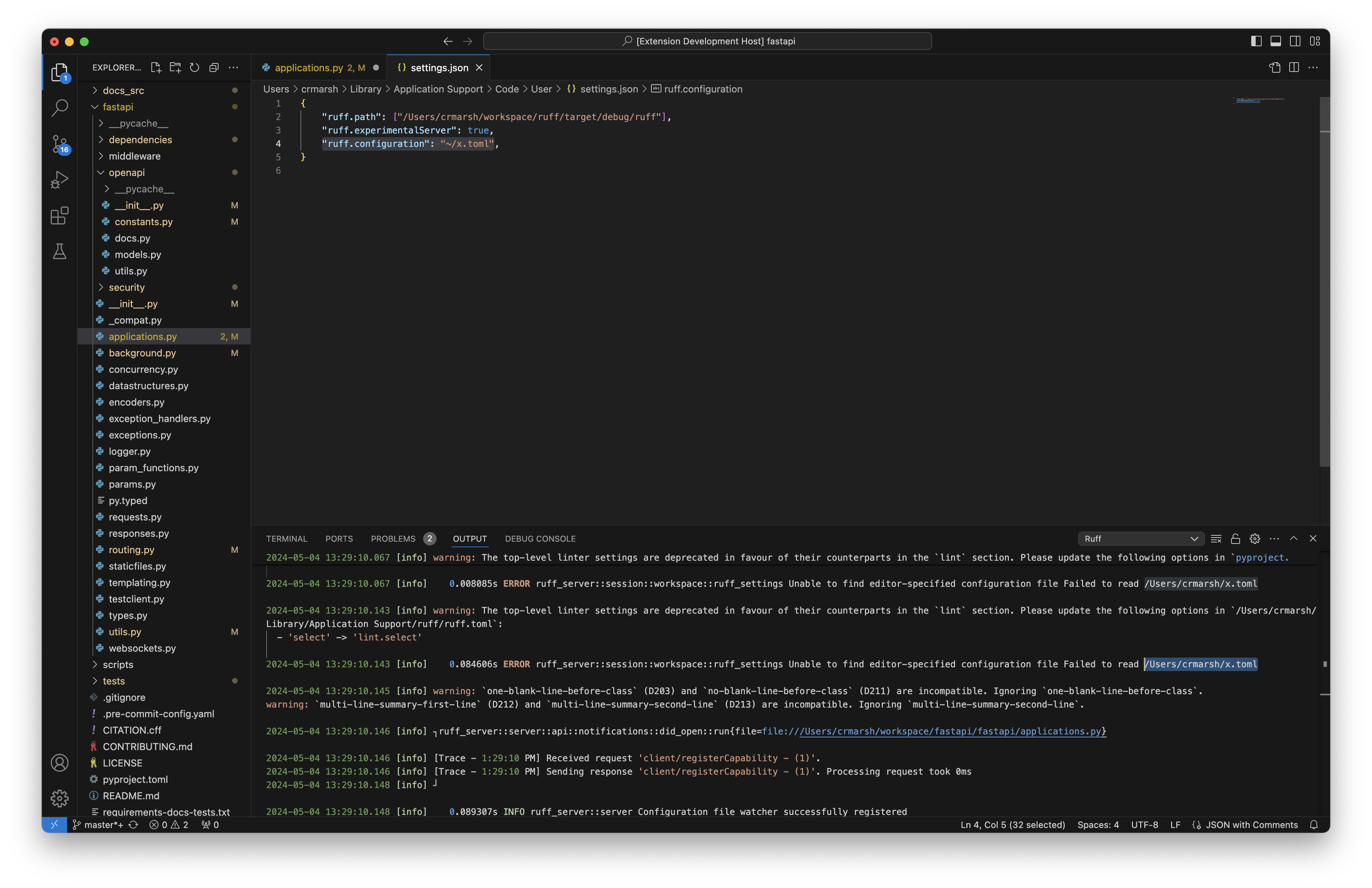
## Summary
Users can now include tildes and environment variables in the provided
path, just like with `--config`.
Closes#11277.
## Test Plan
Set the configuration path to `"ruff.configuration": "~/x.toml"`;
verified that the server attempted to read from `/Users/crmarsh/x.toml`.
## Summary
Change `hardcoded-tmp-directory-extend` example to follow the schema:
1e91a09918/ruff.schema.json (L896-L901)
<!-- What's the purpose of the change? What does it do, and why? -->
## Summary
In #9218 `Rule::NeverUnion` was partially removed from a
`checker.any_enabled` call. This makes the change consistent.
## Test Plan
`cargo test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11207.
The server would hang after handling a shutdown request on
`IoThreads::join()` because a global sender (`MESSENGER`, used to send
`window/showMessage` notifications) would remain allocated even after
the event loop finished, which kept the writer I/O thread channel open.
To fix this, I've made a few structural changes to `ruff server`. I've
wrapped the send/receive channels and thread join handle behind a new
struct, `Connection`, which facilitates message sending and receiving,
and also runs `IoThreads::join()` after the event loop finishes. To
control the number of sender channels, the `Connection` wraps the sender
channel in an `Arc` and only allows the creation of a wrapper type,
`ClientSender`, which hold a weak reference to this `Arc` instead of
direct channel access. The wrapper type implements the channel methods
directly to prevent access to the inner channel (which would allow the
channel to be cloned). ClientSender's function is analogous to
[`WeakSender` in
`tokio`](https://docs.rs/tokio/latest/tokio/sync/mpsc/struct.WeakSender.html).
Additionally, the receiver channel cannot be accessed directly - the
`Connection` only exposes an iterator over it.
These changes will guarantee that all channels are closed before the I/O
threads are joined.
## Test Plan
Repeatedly open and close an editor utilizing `ruff server` while
observing the task monitor. The net total amount of open `ruff`
instances should be zero once all editor windows have closed.
The following logs should also appear after the server is shut down:
<img width="835" alt="Screenshot 2024-04-30 at 3 56 22 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/404b74f5-ef08-4bb4-9fa2-72e72b946695">
This can be tested on VS Code by changing the settings and then checking
`Output`.
* Add `decorators: Vec<Type>` to `FunctionType` struct
* Thread decorators through two `add_function` definitions
* Populate decorators at the callsite in `infer_symbol_type`
* Small test
Resolves#10390 and starts to address #10391
# Changes to behavior
* In `__init__.py` we now offer some fixes for unused imports.
* If the import binding is first-party this PR suggests a fix to turn it
into a redundant alias.
* If the import binding is not first-party, this PR suggests a fix to
remove it from the `__init__.py`.
* The fix-titles are specific to these new suggested fixes.
* `checker.settings.ignore_init_module_imports` setting is
deprecated/ignored. There is probably a documentation change to make
that complete which I haven't done.
---
<details><summary>Old description of implementation changes</summary>
# Changes to the implementation
* In the body of the loop over import statements that contain unused
bindings, the bindings are partitioned into `to_reexport` and
`to_remove` (according to how we want to resolve the fact they're
unused) with the following predicate:
```rust
in_init && is_first_party(checker, &import.qualified_name().to_string())
// true means make it a reexport
```
* Instead of generating a single fix per import statement, we now
generate up to two fixes per import statement:
```rust
(fix_by_removing_imports(checker, node_id, &to_remove, in_init).ok(),
fix_by_reexporting(checker, node_id, &to_reexport, dunder_all).ok())
```
* The `to_remove` fixes are unsafe when `in_init`.
* The `to_explicit` fixes are safe. Currently, until a future PR, we
make them redundant aliases (e.g. `import a` would become `import a as
a`).
## Other changes
* `checker.settings.ignore_init_module_imports` is deprecated/ignored.
Instead, all fixes are gated on `checker.settings.preview.is_enabled()`.
* Got rid of the pattern match on the import-binding bound by the inner
loop because it seemed less readable than referencing fields on the
binding.
* [x] `// FIXME: rename "imports" to "bindings"` if reviewer agrees (see
code)
* [x] `// FIXME: rename "node_id" to "import_statement"` if reviewer
agrees (see code)
<details>
<summary><h2>Scope cut until a future PR</h2></summary>
* (Not implemented) The `to_explicit` fixes will be added to `__all__`
unless it doesn't exist. When `__all__` doesn't exist they're resolved
by converting to redundant aliases (e.g. `import a` would become `import
a as a`).
---
</details>
# Test plan
* [x] `crates/ruff_linter/resources/test/fixtures/pyflakes/F401_24`
contains an `__init__.py` with*out* `__all__` that exercises the
features in this PR, but it doesn't pass.
* [x]
`crates/ruff_linter/resources/test/fixtures/pyflakes/F401_25_dunder_all`
contains an `__init__.py` *with* `__all__` that exercises the features
in this PR, but it doesn't pass.
* [x] Write unit tests for the new edit functions in
`fix::edits::make_redundant_alias`.
</details>
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR removes the `ImportMap` implementation and all its routing
through ruff.
The import map was added in https://github.com/astral-sh/ruff/pull/3243
but we then never ended up using it to do cross file analysis.
We are now working on adding multifile analysis to ruff, and revisit
import resolution as part of it.
```
hyperfine --warmup 10 --runs 20 --setup "./target/release/ruff clean" \
"./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I" \
"./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 37.6 ms ± 0.9 ms [User: 52.2 ms, System: 63.7 ms]
Range (min … max): 35.8 ms … 39.8 ms 20 runs
Benchmark 2: ./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 36.0 ms ± 0.7 ms [User: 50.3 ms, System: 58.4 ms]
Range (min … max): 34.5 ms … 37.6 ms 20 runs
Summary
./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I ran
1.04 ± 0.03 times faster than ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
```
I suspect that the performance improvement should even be more
significant for users that otherwise don't have any diagnostics.
```
hyperfine --warmup 10 --runs 20 --setup "cd ../ecosystem/airflow && ../../ruff/target/release/ruff clean" \
"./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I" \
"./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 53.7 ms ± 1.8 ms [User: 68.4 ms, System: 63.0 ms]
Range (min … max): 51.1 ms … 58.7 ms 20 runs
Benchmark 2: ./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 50.8 ms ± 1.4 ms [User: 50.7 ms, System: 60.9 ms]
Range (min … max): 48.5 ms … 55.3 ms 20 runs
Summary
./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I ran
1.06 ± 0.05 times faster than ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
```
## Test Plan
`cargo test`
## Summary
Fixes#11185Fixes#11214
Document path and package information is now forwarded to the Ruff
linter, which allows `per-file-ignores` to correctly match against the
file name. This also fixes an issue where the import sorting rule didn't
distinguish between third-party and first-party packages since we didn't
pass in the package root.
## Test Plan
`per-file-ignores` should ignore files as expected. One quick way to
check is by adding this to your `pyproject.toml`:
```toml
[tool.ruff.lint.per-file-ignores]
"__init__.py" = ["ALL"]
```
Then, confirm that no diagnostics appear when you add code to an
`__init__.py` file (besides syntax errors).
The import sorting fix can be verified by failing to reproduce the
original issue - an `I001` diagnostic should not appear in
`other_module.py`.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11158.
A settings file in the ruff user configuration directory will be used as
a configuration fallback, if it exists.
## Test Plan
Create a `pyproject.toml` or `ruff.toml` configuration file in the ruff
user configuration directory.
* On Linux, that will be `$XDG_CONFIG_HOME/ruff/` or `$HOME/.config`
* On macOS, that will be `$HOME/Library/Application Support`
* On Windows, that will be `{FOLDERID_LocalAppData}`
Then, open a file inside of a workspace with no configuration. The
settings in the user configuration file should be used.
## Summary
I think the check included here does make sense, but I don't see why we
would allow it if a value is provided for the attribute -- since, in
that case, isn't it _not_ abstract?
Closes: https://github.com/astral-sh/ruff/issues/11208.
## Summary
This PR changes the `DebugStatistics` and `ReleaseStatistics` structs so
that they implement a common `StatisticsRecorder` trait, and makes the
`KeyValueCache` struct generic over a type parameter bound to that
trait. The advantage of this approach is that it's much harder for the
`DebugStatistics` and `ReleaseStatistics` structs to accidentally grow
out of sync in the methods that they implement, which was the cause of
the release-build failure recently fixed in #11177.
## Test Plan
`cargo test -p red_knot` and `cargo build --release` both continue to
pass for me locally
* Adds `Symbol.flag` bitfield. Populates it from (the three renamed)
`add_or_update_symbol*` methods.
* Currently there are these flags supported:
* `IS_DEFINED` is set in a scope where a variable is defined.
* `IS_USED` is set in a scope where a variable is referenced. (To have
both this and `IS_DEFINED` would require two separate appearances of a
variable in the same scope-- one def and one use.)
* `MARKED_GLOBAL` and `MARKED_NONLOCAL` are **not yet implemented**.
(*TODO: While traversing, if you find these declarations, add these
flags to the variable.*)
* Adds `Symbol.kind` field (commented) and the data structure which will
populate it: `Kind` which is an enum of freevar, cellvar,
implicit_global, and implicit_local. **Not yet populated**. (*TODO: a
second pass over the scope (or the ast?) will observe the
`MARKED_GLOBAL` and `MARKED_NONLOCAL` flags to populate this field. When
that's added, we'll uncomment the field.*)
* Adds a few tests that the `IS_DEFINED` and `IS_USED` fields are
correctly set and/or merged:
* Unit test that subsequent calls to `add_or_update_symbol` will merge
the flag arguments.
* Unit test that in the statement `x = foo`, the variable `foo` is
considered used but not defined.
* Unit test that in the statement `from bar import foo`, the variable
`foo` is considered defined but not used.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR adds a basic README for the `ruff_python_parser` crate and
updates the CONTRIBUTING docs with the fuzzer and benchmark section.
Additionally, it also updates some inline documentation within the
parser crate and splits the `parse_program` function into
`parse_single_expression` and `parse_module` which will be called by
matching against the `Mode`.
This PR doesn't go into too much internal detail around the parser logic
due to the following reasons:
1. Where should the docs go? Should it be as a module docs in `lib.rs`
or in README?
2. The parser is still evolving and could include a lot of refactors
with the future work (feedback loop and improved error recovery and
resilience)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
`cargo build --release` currently fails to compile on `main`:
<details>
```
error[E0599]: no method named `hit` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:22:29
|
22 | self.statistics.hit();
| ^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `hit` not found for this struct
error[E0599]: no method named `miss` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:25:29
|
25 | self.statistics.miss();
| ^^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `miss` not found for this struct
error[E0599]: no method named `hit` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:36:33
|
36 | self.statistics.hit();
| ^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `hit` not found for this struct
error[E0599]: no method named `miss` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:41:33
|
41 | self.statistics.miss();
| ^^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `miss` not found for this struct
```
</details>
This is because in a release build, `CacheStatistics` is a type alias
for `ReleaseStatistics`, and `ReleaseStatistics` doesn't have `hit()` or
`miss()` methods. (In a debug build, `CacheStatistics` is a type alias
for `DebugStatistics`, which _does_ have those methods.)
Possibly we could make this less likely to happen in the future by
making both structs implement a common trait instead of using type
aliases that vary depending on whether it's a debug build or not? For
now, though, this PR just brings the two structs in sync w.r.t. the
methods they expose.
## Test Plan
`cargo build --release` now once again compiles for me locally
## Summary
This PR adds an override to the fixer to ensure that we apply any
`redefined-while-unused` fixes prior to `unused-import`.
Closes https://github.com/astral-sh/ruff/issues/10905.
## Summary
Implement duplicate code detection as part of `RUF100`, mirroring the
behavior of `flake8-noqa` (`NQA005`) mentioned in #850. The idea to
merge the rule into `RUF100` was suggested by @MichaReiser
https://github.com/astral-sh/ruff/pull/10325#issuecomment-2025535444.
## Test Plan
Test cases were added to the fixture.
This syntax wasn't "deprecated" in Python 3; it was removed.
I started looking at this rule because I was curious how Ruff could even
detect this without a Python 2 parser. Then I realized that
"print >> f, x" is actually valid Python 3 syntax: it creates a tuple
containing a right-shifted version of the print function.
## Summary
Based on discussion in #10850.
As it stands today `RUF100` will attempt to replace code redirects with
their target codes even though this is not the "goal" of `RUF100`. This
behavior is confusing and inconsistent, since code redirects which don't
otherwise violate `RUF100` will not be updated. The behavior is also
undocumented. Additionally, users who want to use `RUF100` but do not
want to update redirects have no way to opt out.
This PR explicitly detects redirects with a new rule `RUF101` and
patches `RUF100` to keep original codes in fixes and reporting.
## Test Plan
Added fixture.
## Summary
Closes#10985.
The server now supports a custom TOML configuration file as a client
setting. The setting must be an absolute path to a file. If the file is
called `pyproject.toml`, the server will attempt to parse it as a
pyproject file - otherwise, it will attempt to parse it as a `ruff.toml`
file, even if the file has a name besides `ruff.toml`.
If an option is set in both the custom TOML configuration file and in
the client settings directly, the latter will be used.
## Test Plan
1. Create a `ruff.toml` file outside of the workspace you are testing.
Set an option that is different from the one in the configuration for
your test workspace.
2. Set the path to the configuration in NeoVim:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
configuration = "absolute/path/to/your/configuration"
}
}
}
```
3. Confirm that the option in the configuration file is used, regardless
of what the option is set to in the workspace configuration.
4. Add the same option, with a different value, to the NeoVim
configuration directly. For example:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
configuration = "absolute/path/to/your/configuration",
lint = {
select = []
}
}
}
}
```
5. Confirm that the option set in client settings is used, regardless of
the value in either the custom configuration file or in the workspace
configuration.
## Summary
This PR fixes the bug where the formatter would format an f-string and
could potentially change the AST.
For a triple-quoted f-string, the element can't be formatted into
multiline if it has a format specifier because otherwise the newline
would be treated as part of the format specifier.
Given the following f-string:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f} ddddddddddddddd eeeeeeee"""
```
The formatter sees that the f-string is already multiline so it assumes
that it can contain line breaks i.e., broken into multiple lines. But,
in this specific case we can't format it as:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f
} ddddddddddddddd eeeeeeee"""
```
Because the format specifier string would become ".3f\n", which is not
the original string (`.3f`).
If the original source code already contained a newline, they'll be
preserved. For example:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f
} ddddddddddddddd eeeeeeee"""
```
The above will be formatted as:
```py
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {variable:.3f
} ddddddddddddddd eeeeeeee"""
```
Note that the newline after `.3f` is part of the format specifier which
needs to be preserved.
The Python version is irrelevant in this case.
fixes: #10040
## Test Plan
Add some test cases to verify this behavior.
## Summary
This is intended to address
https://github.com/astral-sh/ruff-vscode/issues/425, and is a follow-up
to https://github.com/astral-sh/ruff/pull/11062.
A new client setting is now supported by the server,
`prioritizeFileConfiguration`. This is a boolean setting (default:
`false`) that, if set to `true`, will instruct the configuration
resolver to prioritize file configuration (aka discovered TOML files)
over configuration passed in by the editor.
A corresponding extension PR has been opened, which makes this setting
available for VS Code:
https://github.com/astral-sh/ruff-vscode/pull/457.
## Test Plan
To test this with VS Code, you'll need to check out [the VS Code
PR](https://github.com/astral-sh/ruff-vscode/pull/457) that adds this
setting.
The test process is similar to
https://github.com/astral-sh/ruff/pull/11062, but in scenarios where the
editor configuration would take priority over file configuration, file
configuration should take priority.
## Summary
Resolves#11102
The error stems from these lines
f5c7a62aa6/crates/ruff_linter/src/noqa.rs (L697-L702)
I don't really understand the purpose of incrementing the last index,
but it makes the resulting range invalid for indexing into `contents`.
For now I just detect if the index is too high in `blanket_noqa` and
adjust it if necessary.
## Test Plan
Created fixture from issue example.