## Summary
This PR fixes a bug introduced in
https://github.com/astral-sh/ruff/pull/12008 which didn't consider the
two character newline after the line continuation character.
For example, consider the following code highlighted with whitespaces:
```py
call(foo # comment \\r\n
\r\n
def bar():\r\n
....pass\r\n
```
The lexer is at `def` when it's running the re-lexing logic and trying
to move back to a newline character. It encounters `\n` and it's being
escaped (incorrect) but `\r` is being escaped, so it moves the lexer to
`\n` character. This creates an overlap in token ranges which causes the
panic.
```
Name 0..4
Lpar 4..5
Name 5..8
Comment 9..20
NonLogicalNewline 20..22 <-- overlap between
Newline 21..22 <-- these two tokens
NonLogicalNewline 22..23
Def 23..26
...
```
fixes: #12028
## Test Plan
Add a test case with line continuation and windows style newline
character.
## Summary
(I'm pretty sure I added this in the parser re-write but must've got
lost in the rebase?)
This PR raises a syntax error if the type parameter list is empty.
As per the grammar, there should be at least one type parameter:
```
type_params:
| invalid_type_params
| '[' type_param_seq ']'
type_param_seq: ','.type_param+ [',']
```
Verified via the builtin `ast` module as well:
```console
$ python3.13 -m ast parser/_.py
Traceback (most recent call last):
[..]
File "parser/_.py", line 1
def foo[]():
^
SyntaxError: Type parameter list cannot be empty
```
## Test Plan
Add inline test cases and update the snapshots.
## Summary
Right now, it's inconsistent... We sometimes match against the name, and
sometimes against the alias (`asname`). I could see a case for always
matching against the name, but matching against both seems fine too,
since the rule is really about the combination of the two?
Closes https://github.com/astral-sh/ruff/issues/12031.
## Summary
This PR fixes a bug where Ruff would raise `E203` for f-string debug
expression. This isn't valid because whitespaces are important for debug
expressions.
fixes: #12023
## Test Plan
Add test case and make sure there are no snapshot changes.
## Summary
This PR updates the parser test infrastructure to validate the token
ranges.
From the code documentation:
```
/// Verifies that:
/// * the ranges are strictly increasing when loop the tokens in insertion order
/// * all ranges are within the length of the source code
```
Follow-up from #12016 and #12017resolves: #11938
## Test Plan
Make sure that there are no failures.
## Summary
This PR updates the unterminated string error range to not include the
final newline character.
This is a follow-up to #12016 and required for #12019
This is not done for when the unterminated string goes till the end of
file (not a newline character). The unterminated f-string range is
correct.
### Why is this required for #12019 ?
Because otherwise the token ranges will overlap. For example:
```py
f"{"
f"{foo!r"
```
Here, the re-lexing logic recovers from an unterminated f-string and
thus emitting a `Newline` token for the one at the end of the first
line. But, currently the `Unknown` and the `Newline` token would overlap
because the `Unknown` token (unterminated string literal) range would
include the newline character.
## Test Plan
Update and validate the snapshot.
## Summary
This PR fixes the range highlighted for the line continuation error.
Previously, it would highlight an incorrect range:
```
1 | call(a, b, \\\
| ^^ Syntax Error: unexpected character after line continuation character
2 |
3 | def bar():
|
```
And now:
```
|
1 | call(a, b, \\\
| ^ Syntax Error: unexpected character after line continuation character
2 |
3 | def bar():
|
```
This is implemented by avoiding to update the token range for the
`Unknown` token which is emitted when there's a lexical error. Instead,
the `push_error` helper method will be responsible to update the range
to the error location.
This actually becomes a requirement which can be seen in follow-up PRs.
## Test Plan
Update and validate the snapshot.
## Summary
This PR fixes a bug where the re-lexing logic didn't consider the line
continuation character being present before the newline character. This
meant that the lexer was being moved back to the newline character which
is actually ignored via `\`.
Considering the following code:
```py
f'middle {'string':\
'format spec'}
```
The old token stream is:
```
...
Colon 18..19
FStringMiddle 19..29 (flags = F_STRING)
Newline 20..21
Indent 21..29
String 29..42
Rbrace 42..43
...
```
Notice how the ranges are overlapping between the `FStringMiddle` token
and the tokens emitted after moving the lexer backwards.
After this fix, the new token stream which is without moving the lexer
backwards in this scenario:
```
FStringStart 0..2 (flags = F_STRING)
FStringMiddle 2..9 (flags = F_STRING)
Lbrace 9..10
String 10..18
Colon 18..19
FStringMiddle 19..29 (flags = F_STRING)
FStringEnd 29..30 (flags = F_STRING)
Name 30..36
Name 37..41
Unknown 41..44
Newline 44..45
```
fixes: #12004
## Test Plan
Add test cases and update the snapshots.
## Summary
This PR updates `F811` rule to include assignment as possible shadowed
binding. This will fix issue: #11828 .
## Test Plan
Add a test file, F811_30.py, which includes a redefinition after an
assignment and a verified snapshot file.
## Summary
Addresses #11974 to add a `RUF` rule to replace `print` expressions in
`assert` statements with the inner message.
An autofix is available, but is considered unsafe as it changes
behaviour of the execution, notably:
- removal of the printout in `stdout`, and
- `AssertionError` instance containing a different message.
While the detection of the condition is a straightforward matter,
deciding how to resolve the print arguments into a string literal can be
a relatively subjective matter. The implementation of this PR chooses to
be as tolerant as possible, and will attempt to reformat any number of
`print` arguments containing single or concatenated strings or variables
into either a string literal, or a f-string if any variables or
placeholders are detected.
## Test Plan
`cargo test`.
## Examples
For ease of discussion, this is the diff for the tests:
```diff
# Standard Case
# Expects:
# - single StringLiteral
-assert True, print("This print is not intentional.")
+assert True, "This print is not intentional."
# Concatenated string literals
# Expects:
# - single StringLiteral
-assert True, print("This print" " is not intentional.")
+assert True, "This print is not intentional."
# Positional arguments, string literals
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", "is not intentional")
+assert True, "This print is not intentional"
# Concatenated string literals combined with Positional arguments
# Expects:
# - single stringliteral concatenated with " " only between `print` and `is`
-assert True, print("This " "print", "is not intentional.")
+assert True, "This print is not intentional."
# Positional arguments, string literals with a variable
# Expects:
# - single FString concatenated with " "
-assert True, print("This", print.__name__, "is not intentional.")
+assert True, f"This {print.__name__} is not intentional."
# Mixed brackets string literals
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", 'is not intentional', """and should be removed""")
+assert True, "This print is not intentional and should be removed"
# Mixed brackets with other brackets inside
# Expects:
# - single StringLiteral concatenated with " " and escaped brackets
-assert True, print("This print", 'is not "intentional"', """and "should" be 'removed'""")
+assert True, "This print is not \"intentional\" and \"should\" be 'removed'"
# Positional arguments, string literals with a separator
# Expects:
# - single StringLiteral concatenated with "|"
-assert True, print("This print", "is not intentional", sep="|")
+assert True, "This print|is not intentional"
# Positional arguments, string literals with None as separator
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", "is not intentional", sep=None)
+assert True, "This print is not intentional"
# Positional arguments, string literals with variable as separator, needs f-string
# Expects:
# - single FString concatenated with "{U00A0}"
-assert True, print("This print", "is not intentional", sep=U00A0)
+assert True, f"This print{U00A0}is not intentional"
# Unnecessary f-string
# Expects:
# - single StringLiteral
-assert True, print(f"This f-string is just a literal.")
+assert True, "This f-string is just a literal."
# Positional arguments, string literals and f-strings
# Expects:
# - single FString concatenated with " "
-assert True, print("This print", f"is not {'intentional':s}")
+assert True, f"This print is not {'intentional':s}"
# Positional arguments, string literals and f-strings with a separator
# Expects:
# - single FString concatenated with "|"
-assert True, print("This print", f"is not {'intentional':s}", sep="|")
+assert True, f"This print|is not {'intentional':s}"
# A single f-string
# Expects:
# - single FString
-assert True, print(f"This print is not {'intentional':s}")
+assert True, f"This print is not {'intentional':s}"
# A single f-string with a redundant separator
# Expects:
# - single FString
-assert True, print(f"This print is not {'intentional':s}", sep="|")
+assert True, f"This print is not {'intentional':s}"
# Complex f-string with variable as separator
# Expects:
# - single FString concatenated with "{U00A0}", all placeholders preserved
condition = "True is True"
maintainer = "John Doe"
-assert True, print("Unreachable due to", condition, f", ask {maintainer} for advice", sep=U00A0)
+assert True, f"Unreachable due to{U00A0}{condition}{U00A0}, ask {maintainer} for advice"
# Empty print
# Expects:
# - `msg` entirely removed from assertion
-assert True, print()
+assert True
# Empty print with separator
# Expects:
# - `msg` entirely removed from assertion
-assert True, print(sep=" ")
+assert True
# Custom print function that actually returns a string
# Expects:
@@ -100,4 +100,4 @@
# Use of `builtins.print`
# Expects:
# - single StringLiteral
-assert True, builtins.print("This print should be removed.")
+assert True, "This print should be removed."
```
## Known Issues
The current implementation resolves all arguments and separators of the
`print` expression into a single string, be it
`StringLiteralValue::single` or a `FStringValue::single`. This:
- potentially joins together strings well beyond the ideal character
limit for each line, and
- does not preserve multi-line strings in their original format, in
favour of a single line `"...\n...\n..."` format.
These are purely formatting issues only occurring in unusual scenarios.
Additionally, the autofix will tolerate `print` calls that were
previously invalid:
```python
assert True, print("this", "should not be allowed", sep=42)
```
This will be transformed into
```python
assert True, f"this{42}should not be allowed"
```
which some could argue is an alteration of behaviour.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Documentation mentions:
> PEP 563 enabled the use of a number of convenient type annotations,
such as `list[str]` instead of `List[str]`
but it meant [PEP 585](https://peps.python.org/pep-0585/) instead.
[PEP 563](https://peps.python.org/pep-0563/) is the one defining `from
__future__ import annotations`.
## Test Plan
No automated test required, just verify that
https://peps.python.org/pep-0585/ is the correct reference.
## Summary
I look at the token stream a lot, not specifically in the playground but
in the terminal output and it's annoying to scroll a lot to find
specific location. Most of the information is also redundant.
The final format we end up with is: `<kind> <range> (flags = ...)` e.g.,
`String 0..4 (flags = BYTE_STRING)` where the flags part is only
populated if there are any flags set.
## Summary
Fixes#11651.
Fixes#11851.
We were double-closing a notebook document from the index, once in
`textDocument/didClose` and then in the `notebookDocument/didClose`
handler. The second time this happens, taking a snapshot fails.
I've rewritten how we handle snapshots for closing notebooks / notebook
cells so that any failure is simply logged instead of propagating
upwards. This implementation works consistently even if we don't receive
`textDocument/didClose` notifications for each specific cell, since they
get closed (and the diagnostics get cleared) in the notebook document
removal process.
## Test Plan
1. Open an untitled, unsaved notebook with the `Create: New Jupyter
Notebook` command from the VS Code command palette (`Ctrl/Cmd + Shift +
P`)
2. Without saving the document, close it.
3. No error popup should appear.
4. Run the debug command (`Ruff: print debug information`) to confirm
that there are no open documents
## Summary
This PR does some housekeeping into moving certain structs into related
modules. Specifically,
1. Move `LexicalError` from `lexer.rs` to `error.rs` which also contains
the `ParseError`
2. Move `Token`, `TokenFlags` and `TokenValue` from `lexer.rs` to
`token.rs`
## Summary
This PR removes the duplication around `is_trivia` functions.
There are two of them in the codebase:
1. In `pycodestyle`, it's for newline, indent, dedent, non-logical
newline and comment
2. In the parser, it's for non-logical newline and comment
The `TokenKind::is_trivia` method used (1) but that's not correct in
that context. So, this PR introduces a new `is_non_logical_token` helper
method for the `pycodestyle` crate and updates the
`TokenKind::is_trivia` implementation with (2).
This also means we can remove `Token::is_trivia` method and the
standalone `token_source::is_trivia` function and use the one on
`TokenKind`.
## Test Plan
`cargo insta test`
## Summary
Closes#11914.
This PR introduces a snapshot test that replays the LSP requests made
during a document formatting request, and confirms that the notebook
document is updated in the expected way.
## Summary
Fixes#11911.
`shellexpand` is now used on `logFile` to expand the file path, allowing
the usage of `~` and environment variables.
## Test Plan
1. Set `logFile` in either Neovim or Helix to a file path that needs
expansion, like `~/.config/helix/ruff_logs.txt`.
2. Ensure that `RUFF_TRACE` is set to `messages` or `verbose`
3. Open a Python file in Neovim/Helix
4. Confirm that a file at the path specified was created, with the
expected logs.
## Summary
This PR updates the logical line rules entry-point function to only run
the logic if any of the rules within that group is enabled.
Although this shouldn't really give any performance improvements, it's
better not to do additional work if we can. This is also consistent with
how other rules are run.
## Test Plan
`cargo insta test`
## Summary
This PR avoids moving back the lexer for a triple-quoted f-string during
the re-lexing phase.
The reason this is a problem is that for a triple-quoted f-string the
newlines are part of the f-string itself, specifically they'll be part
of the `FStringMiddle` token. So, if we moved the lexer back, there
would be a `Newline` token whose range would be in between an
`FStringMiddle` token. This creates a panic in downstream usage.
fixes: #11937
## Test Plan
Add test cases and validate the snapshots.
## Summary
This PR avoids the `depth` counter when detecting indentation from
non-logical lines because it seems to never be used. It might have been
a leftover when the logic was added originally in #11608.
## Test Plan
`cargo insta test`
## Summary
This PR updates the linter to show all the parse errors as diagnostics
instead of just the first one.
Note that this doesn't affect the parse error displayed as error log
message. This will be removed in a follow-up PR.
### Breaking?
I don't think this is a breaking change even though this might give more
diagnostics. The main reason is that this shouldn't affect any users
because it'll only give additional diagnostics in the case of multiple
syntax errors.
## Test Plan
Add an integration test case which would raise more than one parse
error.
## Summary
This PR updates the re-lexing logic to avoid consuming the trailing
whitespace and move the lexer explicitly to the last newline character
encountered while moving backwards.
Consider the following code snippet as taken from the test case
highlighted with whitespace (`.`) and newline (`\n`) characters:
```py
# There are trailing whitespace before the newline character but those whitespaces are
# part of the comment token
f"""hello {x # comment....\n
# ^
y = 1\n
```
The parser is at `y` when it's trying to recover from an unclosed `{`,
so it calls into the re-lexing logic which tries to move the lexer back
to the end of the previous line. But, as it consumed all whitespaces it
moved the lexer to the location marked by `^` in the above code snippet.
But, those whitespaces are part of the comment token. This means that
the range for the two tokens were overlapping which introduced the
panic.
Note that this is only a bug when there's a comment with a trailing
whitespace otherwise it's fine to move the lexer to the whitespace
character. This is because the lexer would just skip the whitespace
otherwise. Nevertheless, this PR updates the logic to move it explicitly
to the newline character in all cases.
fixes: #11929
## Test Plan
Add test cases and update the snapshot. Make sure that it doesn't panic
on the code snippet in the linked issue.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
related to https://github.com/astral-sh/ruff/issues/5306
The check right now only checks in the first 1024 bytes, and that's
really not enough when there's a docstring at the beginning of a file.
A more proper fix might be needed, which might be more complex (and I
don't have the `rust` skills to implement that). But this temporary
"fix" might enable more users to use this.
Context: We want to use this rule in
https://github.com/scikit-learn/scikit-learn/ and we got blocked because
of this hardcoded rule (which TBH took us quite a while to figure out
why it was failing since it's not documented).
## Test Plan
This is already kinda tested, modified the test for the new byte number.
<!-- How was it tested? -->
## Summary
This PR removes most of the syntax errors from the test cases. This
would create noise when https://github.com/astral-sh/ruff/pull/11901 is
complete. These syntax errors are also just noise for the test itself.
## Test Plan
Update the snapshots and verify that they're still the same.
## Summary
This PR is a follow-up on #11845 to add the re-lexing logic for normal
list parsing.
A normal list parsing is basically parsing elements without any
separator in between i.e., there can only be trivia tokens in between
the two elements. Currently, this is only being used for parsing
**assignment statement** and **f-string elements**. Assignment
statements cannot be in a parenthesized context, but f-string can have
curly braces so this PR is specifically for them.
I don't think this is an ideal recovery but the problem is that both
lexer and parser could add an error for f-strings. If the lexer adds an
error it'll emit an `Unknown` token instead while the parser adds the
error directly. I think we'd need to move all f-string errors to be
emitted by the parser instead. This way the parser can correctly inform
the lexer that it's out of an f-string and then the lexer can pop the
current f-string context out of the stack.
## Test Plan
Add test cases, update the snapshots, and run the fuzzer.
## Summary
Fixes https://github.com/astral-sh/ruff-vscode/issues/496.
Cells are no longer removed from the notebook index when a notebook gets
updated, but rather when `textDocument/didClose` is called for them.
This solves an issue where their premature removal from the notebook
cell index would cause their URL to be un-queryable in the
`textDocument/didClose` handler.
## Test Plan
Create and then delete a notebook cell in VS Code. No error should
appear.
## Summary
This PR implements the re-lexing logic in the parser.
This logic is only applied when recovering from an error during list
parsing. The logic is as follows:
1. During list parsing, if an unexpected token is encountered and it
detects that an outer context can understand it and thus recover from
it, it invokes the re-lexing logic in the lexer
2. This logic first checks if the lexer is in a parenthesized context
and returns if it's not. Thus, the logic is a no-op if the lexer isn't
in a parenthesized context
3. It then reduces the nesting level by 1. It shouldn't reset it to 0
because otherwise the recovery from nested list parsing will be
incorrect
4. Then, it tries to find last newline character going backwards from
the current position of the lexer. This avoids any whitespaces but if it
encounters any character other than newline or whitespace, it aborts.
5. Now, if there's a newline character, then it needs to be re-lexed in
a logical context which means that the lexer needs to emit it as a
`Newline` token instead of `NonLogicalNewline`.
6. If the re-lexing gives a different token than the current one, the
token source needs to update it's token collection to remove all the
tokens which comes after the new current position.
It turns out that the list parsing isn't that happy with the results so
it requires some re-arranging such that the following two errors are
raised correctly:
1. Expected comma
2. Recovery context error
For (1), the following scenarios needs to be considered:
* Missing comma between two elements
* Half parsed element because the grammar doesn't allow it (for example,
named expressions)
For (2), the following scenarios needs to be considered:
1. If the parser is at a comma which means that there's a missing
element otherwise the comma would've been consumed by the first `eat`
call above. And, the parser doesn't take the re-lexing route on a comma
token.
2. If it's the first element and the current token is not a comma which
means that it's an invalid element.
resolves: #11640
## Test Plan
- [x] Update existing test snapshots and validate them
- [x] Add additional test cases specific to the re-lexing logic and
validate the snapshots
- [x] Run the fuzzer on 3000+ valid inputs
- [x] Run the fuzzer on invalid inputs
- [x] Run the parser on various open source projects
- [x] Make sure the ecosystem changes are none
## Summary
This PR updates the server capabilities to include the commands that
Ruff supports. This is similar to how there's a list of possible code
actions supported by the server.
I noticed this when I was trying to find whether Helix supported
workspace commands or not based on Jane's comment
(https://github.com/astral-sh/ruff/pull/11831#discussion_r1634984921)
and I found the `:lsp-workspace-command` in the editor but it didn't
show up anything in the picker.
So, I looked at the implementation in Helix
(9c479e6d2d/helix-term/src/commands/typed.rs (L1372-L1384))
which made me realize that Ruff doesn't provide this in its
capabilities. Currently, this does require `ruff` to be first in the
list of language servers in the user config but that should be resolved
by https://github.com/helix-editor/helix/pull/10176. So, the following
config should work:
```toml
[[language]]
name = "python"
# Ruff should come first until https://github.com/helix-editor/helix/pull/10176 is released
language-servers = ["ruff", "pyright"]
```
## Test Plan
1. Neovim's server capabilities output should include the supported
commands:
```
executeCommandProvider = {
commands = { "ruff.applyFormat", "ruff.applyAutofix", "ruff.applyOrganizeImports", "ruff.printDebugInformation" },
workDoneProgress = false
},
```
2. Helix should now display the commands to pick from when
`:lsp-workspace-command` is invoked:
<img width="832" alt="Screenshot 2024-06-13 at 08 47 14"
src="https://github.com/astral-sh/ruff/assets/67177269/09048ecd-c974-4e09-ab56-9482ff3d780b">
## Summary
This PR adds a new enum to determine the kind of terminator token i.e.,
is it actually terminates the list or is it used for error recovery.
This is important because the parser should take the error recovery
route in case the terminator token is used for better error recovery.
This will then try to re-lex the token if it's the case.
I haven't updated any reference to use this new enum as otherwise it'll
update the snapshots. I plan to do that in a follow-up PR so that it's
easier to reason about.
## Test plan
`cargo insta test`
## Summary
This PR separates the terminator token for f-string elements depending
on the context. A list of f-string element can occur either in a regular
f-string or a format spec of an f-string. The terminator token is
different depending on that context.
## Test Plan
`cargo insta test` and verify the updated snapshots.
## Summary
This PR re-uses the `ruff_python_trivia::is_python_whitespace` in the
lexer instead of defining its own. This was mainly to avoid circular
dependency which was resolved in #11261.
## Summary
Add Constraint nodes to flow graph, and narrow types based on that (only
`is None` and `is not None` narrowing supported for now, to prototype
the structure.)
Also add simplification of zero- and one-element unions and
intersections, and flattening of intersections.
There's a lot more normalization logic needed for unions and
intersections (as is obvious from the inferred type in the added
`narrow_none` test), but this will be non-trivial and I'd rather do it
in a separate PR.
Here's a flowchart diagram for the code in the added `narrow_none` test:

The top branch is for the `if` expression in the initial assignment to
`x`; that `Constraint` node would only affect the type of `flag`, which
we don't care about in this test.
The second branch is for the `if` statement, with `Constraint` node
affecting the type of `x`.
## Test Plan
Added tests.
## Summary
Fixes#11744.
We now show a distinct popup message when we fail to get a document
snapshot during command execution. This message more clearly
communicates the issue to the user, instead of a generic "ruff
encountered an error" message.
## Test Plan
Try running `Fix all auto-fixable problems` on an incompatible file (for
example: `settings.json`). You should see the following popup message:
<img width="456" alt="Screenshot 2024-06-11 at 11 47 16 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/3a28e3d7-3896-4dd0-b117-f87300dd3b68">
## Summary
Closes#11715.
Introduces a new command, `ruff.printDebugInformation`. This will print
useful information about the status of the server to `stderr`.
Right now, the information shown by this command includes:
* The path to the server executable
* The version of the executable
* The text encoding being used
* The number of open documents and workspaces
* A list of registered configuration files
* The capabilities of the client
## Test Plan
First, checkout and use [the corresponding `ruff-vscode`
PR](https://github.com/astral-sh/ruff-vscode/pull/495).
Running the `Print debug information` command in VS Code should show
something like the following in the Output channel:
<img width="991" alt="Screenshot 2024-06-11 at 11 41 46 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/ab93c009-bb7b-4291-b057-d44fdc6f9f86">
## Summary
Fixes#10968.
Fixes#11545.
The server's tracing system has been rewritten from the ground up. The
server now has trace level and log level settings which restrict the
tracing events and spans that get logged.
* A `logLevel` setting has been added, which lets a user set the log
level. By default, it is set to `"info"`.
* A `logFile` setting has also been added, which lets the user supply an
optional file to send tracing output (it does not have to exist as a
file yet). By default, if this is unset, tracing output will be sent to
`stderr`.
* A `$/setTrace` handler has also been added, and we also set the trace
level from the initialization options. For editors without direct
support for tracing, the environment variable `RUFF_TRACE` can override
the trace level.
* Small changes have been made to how we display tracing output. We no
longer use `tracing-tree`, and instead use
`tracing_subscriber::fmt::Layer` to format output. Thread names are now
included in traces, and I've made some adjustment to thread worker names
to be more useful.
## Test Plan
In VS Code, with `ruff.trace.server` set to its default value, no logs
from Ruff should appear.
After changing `ruff.trace.server` to either `messages` or `verbose`,
you should see log messages at `info` level or higher appear in Ruff's
output:
<img width="1005" alt="Screenshot 2024-06-10 at 10 35 04 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/6050d107-9815-4bd2-96d0-e86f096a57f5">
In Helix, by default, no logs from Ruff should appear.
To set the trace level in Helix, you'll need to modify your language
configuration as follows:
```toml
[language-server.ruff]
command = "/Users/jane/astral/ruff/target/debug/ruff"
args = ["server", "--preview"]
environment = { "RUFF_TRACE" = "messages" }
```
After doing this, logs of `info` level or higher should be visible in
Helix:
<img width="1216" alt="Screenshot 2024-06-10 at 10 39 26 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/8ff88692-d3f7-4fd1-941e-86fb338fcdcc">
You can use `:log-open` to quickly open the Helix log file.
In Neovim, by default, no logs from Ruff should appear.
To set the trace level in Neovim, you'll need to modify your
configuration as follows:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" }
}
```
You should see logs appear in `:LspLog` that look like the following:
<img width="1490" alt="Screenshot 2024-06-11 at 11 24 01 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/576cd5fa-03cf-477a-b879-b29a9a1200ff">
You can adjust `logLevel` and `logFile` in `settings`:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" },
settings = {
logLevel = "debug",
logFile = "your/log/file/path/log.txt"
}
}
```
The `logLevel` and `logFile` can also be set in Helix like so:
```toml
[language-server.ruff.config.settings]
logLevel = "debug"
logFile = "your/log/file/path/log.txt"
```
Even if this log file does not exist, it should now be created and
written to after running the server:
<img width="1148" alt="Screenshot 2024-06-10 at 10 43 44 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/ab533cf7-d5ac-4178-97f1-e56da17450dd">
## Summary
This PR updates the parser to remove building the `CommentRanges` and
instead it'll be built by the linter and the formatter when it's
required.
For the linter, it'll be built and owned by the `Indexer` while for the
formatter it'll be built from the `Tokens` struct and passed as an
argument.
## Test Plan
`cargo insta test`
## Summary
The fix for E203 now produces the same result as ruff format in cases
where a slice ends on a colon and the closing square bracket is on the
following line.
Refers to https://github.com/astral-sh/ruff/issues/10973
## Test Plan
The minimal reproduction case in the ticket was added as test case
producing no error. Additional cases with multiple spaces or a tab
before the colon where added to make sure that the rule still finds
these.
## Summary
As-is, we're using the URL path for all files, leading us to use paths
like:
```
/c%3A/Users/crmar/workspace/fastapi/tests/main.py
```
This doesn't match against per-file ignores and other patterns in Ruff
configuration.
This PR modifies the LSP to use the real file path if available, and the
virtual file path if not.
Closes https://github.com/astral-sh/ruff/issues/11751.
## Test Plan
Ran the LSP on Windows. In the FastAPI repo, added:
```toml
[tool.ruff.lint.per-file-ignores]
"tests/**/*.py" = ["F401"]
```
And verified that an unused import was ignored in `tests` after this
change, but not before.
## Summary
This PR removes the `result-like` dependency and instead implement the
required functionality. The motivation being that `noqa.is_enabled()` is
easier to read than `noqa.into()`.
For context, I was just trying to understand the syntax error workflow
and I saw these flags which were being converted via `into`. I always
find `into` confusing because you never know what's it being converted
into unless you know the type. Later realized that it's just a boolean
flag. After removing the usages from these two flags, it turns out that
the dependency is only being used in one rule so I thought to remove
that as well.
## Test Plan
`cargo insta test`
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements the [consider dict
items](https://pylint.pycqa.org/en/latest/user_guide/messages/convention/consider-using-dict-items.html)
rule from Pylint. Enabling this rule flags:
```python
ORCHESTRA = {
"violin": "strings",
"oboe": "woodwind",
"tuba": "brass",
"gong": "percussion",
}
for instrument in ORCHESTRA:
print(f"{instrument}: {ORCHESTRA[instrument]}")
for instrument in ORCHESTRA.keys():
print(f"{instrument}: {ORCHESTRA[instrument]}")
for instrument in (inline_dict := {"foo": "bar"}):
print(f"{instrument}: {inline_dict[instrument]}")
```
For not using `items()` to extract the value out of the dict. We ignore
the case of an assignment, as you can't modify the underlying
representation with the value in the list of tuples returned.
## Test Plan
<!-- How was it tested? -->
`cargo test`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Definitions are used in symbol table and in flow graph, and aren't
inherently owned by one or the other; move them into their own
submodule.
## Test Plan
Existing tests.
## Summary
Add support for inferring int literal types from basic arithmetic on int
literals. Just to begin showing examples of resolving more complex
expression types, and because this will be useful in testing walrus
expressions.
## Test Plan
Added test.
## Summary
After looking at this a bit, I think it does make sense to have
`Unbound` as part of the `Definition` enum; if we are modeling `Unbound`
as a type (which currently we are), then every symbol implicitly starts
each scope with a "definition" as unbound, and the cleanest way to model
that is as a real `Definition`. We should be able to handle a definition
of "unbound" anywhere we handle definitions.
But the name `None` wasn't clear enough; changing the name to `Unbound`
and adding a doc comment.
Also change `[first].into_iter()` to `std::iter::once(first)`, from
post-land code review on a prior PR.
## Test Plan
Existing tests.
## Summary
This PR is a follow-up to #11740 to restrict access to the `Parsed`
output by replacing the `parsed` API function with a more specific one.
Currently, that is `comment_ranges` but the linked PR exposes a `tokens`
method.
The main motivation is so that there's no way to get an incorrect
information from the checker. And, it also encapsulates the source of
the comment ranges and the tokens itself. This way it would become
easier to just update the checker if the source for these information
changes in the future.
## Test Plan
`cargo insta test`
## Summary
This PR fixes a bug where the checker would require the tokens for an
invalid offset w.r.t. the source code.
Taking the source code from the linked issue as an example:
```py
relese_version :"0.0is 64"
```
Now, this isn't really a valid type annotation but that's what this PR
is fixing. Regardless of whether it's valid or not, Ruff shouldn't
panic.
The checker would visit the parsed type annotation (`0.0is 64`) and try
to detect any violations. Certain rule logic requests the tokens for the
same but it would fail because the lexer would only have the `String`
token considering original source code. This worked before because the
lexer was invoked again for each rule logic.
The solution is to store the parsed type annotation on the checker if
it's in a typing context and use the tokens from that instead if it's
available. This is enforced by creating a new API on the checker to get
the tokens.
But, this means that there are two ways to get the tokens via the
checker API. I want to restrict this in a follow-up PR (#11741) to only
expose `tokens` and `comment_ranges` as methods and restrict access to
the parsed source code.
fixes: #11736
## Test Plan
- [x] Add a test case for `F632` rule and update the snapshot
- [x] Check all affected rules
- [x] No ecosystem changes
## Summary
This PR updates the return type of `parse_type_annotation` from `Expr`
to `Parsed<ModExpression>`. This is to allow accessing the tokens for
the parsed sub-expression in the follow-up PR.
## Test Plan
`cargo insta test`
## Summary
Fixes https://github.com/astral-sh/ruff-vscode/issues/482.
I've made adjustments to `format` and `format_range` that handle parsing
errors before they become server errors. We'll still log this as a
problem, but there will no longer be a visible popup.
## Test Plan
Instead of seeing a visible error when formatting a document with syntax
issues, you should see this warning in the LSP logs:
<img width="991" alt="Screenshot 2024-06-04 at 3 38 23 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/9d68947d-6462-4ca6-ab5a-65e573c91db6">
Similarly, if you try to format a range with syntax issues, you should
see this warning in the LSP logs instead of a visible error popup:
<img width="1010" alt="Screenshot 2024-06-04 at 3 39 10 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/99fff098-798d-406a-976e-81ead0da0352">
---------
Co-authored-by: Zanie Blue <contact@zanie.dev>
## Summary
This PR fixes a bug where the lexer didn't consider the BOM into the
start offset.
fixes: #11731
## Test Plan
Add multiple test cases which involves BOM character in the source for
the lexer and verify the snapshot.
## Summary
This PR updates the lexer checkpoint to store the cursor offset instead
of cloning the cursor itself. This reduces the size of `LexerCheckpoint`
from 136 to 112 bytes and also removes the need for lifetime.
## Test Plan
`cargo insta test`
## Summary
Ensures that we respect per-file ignores and exemptions for these rules.
Specifically, we allow:
```python
# ruff: noqa: PGH004
```
...to ignore `PGH004`.
## Summary
Should resolve https://github.com/astral-sh/ruff/issues/11454.
This is my first PR to `ruff`, so I may have missed something.
If I understood the suggestion in the issue correctly, rule `PGH004`
should be set to `Preview` again.
## Test Plan
Created two fixtures derived from the issue.
## Summary
Switch name resolution in `infer_expression_type` from resolving the
public type of a symbol, to resolving the reachable definitions of that
symbol from the reference point, using the flow graph.
This surfaced a bug in the flow graph implementation and a bug in symbol
table building, both of which are also fixed here.
The bug in flow graph implementation was that when we pushed and popped
scopes, we didn't maintain a stack of "current flow nodes" in all
stacked scopes, to be restored when we returned to that scope. Now we
do.
The bug in symbol table building that we didn't visit the parts of
functions and class definitions in the correct scopes. E.g. decorators
should be visited in the outer scope, arguments should be visited inside
the type-params scope (if any) but not inside the function body scope,
and only the body itself should actually be visited inside the body
scope. Fixing this requires that we no longer use `walk_stmt` here,
instead we have to visit each individual component.
## Test Plan
Added test.
## Summary
Rename `infer_symbol_type` to `infer_symbol_public_type`, and allow it
to work on symbols with more than one definition. For now, use the most
cautious/sound inference, which is the union of all definitions. We can
prune this union more in future by eliminating definitions if we can
show that they can't be visible (this requires both that the symbol is
definitely later reassigned, and that there is no intervening
call/import that might be able to see the over-written definition).
## Test Plan
Added a test showing inference of union from multiple definitions.
## Summary
This PR fixes a bug where the `Generator` wouldn't add a newline before
a type alias statement. This is because it wasn't using the `statement`
macro which takes care of the newline.
Without this fix, a code like:
```py
type X = int
type Y = str
```
The generator would produce:
```py
type X = inttype Y = str
```
## Test Plan
Add a test case.
## Summary
This PR removes the following dependencies from the `ruff_python_parser`
crate:
* `anyhow` (moved to dev dependencies)
* `is-macro`
* `itertools`
The main motivation is that they aren't used much.
Additionally, it updates the return type of `parse_type_annotation` to
use a more specific `ParseError` instead of the generic `anyhow::Error`.
## Test Plan
`cargo insta test`
## Summary
This PR updates the logic for parsing type annotation to accept a
`ExprStringLiteral` node instead of the string value and the range.
The main motivation of this change is to simplify the implementation of
`parse_type_annotation` function with:
* Use the `opener_len` and `closer_len` from the string flags to get the
raw contents range instead of extracting it via
* `str::leading_quote(expression).unwrap().text_len()`
* `str::trailing_quote(expression).unwrap().text_len()`
* Avoid comparing the string content if we already know that it's
implicitly concatenated
## Test Plan
`cargo insta test`
## Summary
This PR re-orders the lexer methods in the following order:
1. `next_token`
2. `lex_token`
3. `eat_indentation`
4. `handle_indentation`
5. `skip_whitespace`
6. `consume_ascii_character`
7. `try_single_char_prefix`
8. `try_double_char_prefix`
9. `lex_identifier`
10. `lex_fstring_start`
11. `lex_fstring_middle_or_end`
12. `lex_string`
13. `lex_number`
14. `lex_number_radix`
15. `lex_decimal_number`
16. `radix_run`
17. `lex_comment`
18. `lex_ipython_escape_command`
19. `consume_end`
Following was considered for the ordering:
* 1 is the main entry point which delegates to 2
* 3, 4, 5 are all related to whitespace which is done first
* 6 is the entrypoint for an ascii character which delegates to 9, 12,
13, 17, 18, 19
* Others are grouped around similar kind of methods
## Summary
This PR updates the entire parser stack in multiple ways:
### Make the lexer lazy
* https://github.com/astral-sh/ruff/pull/11244
* https://github.com/astral-sh/ruff/pull/11473
Previously, Ruff's lexer would act as an iterator. The parser would
collect all the tokens in a vector first and then process the tokens to
create the syntax tree.
The first task in this project is to update the entire parsing flow to
make the lexer lazy. This includes the `Lexer`, `TokenSource`, and
`Parser`. For context, the `TokenSource` is a wrapper around the `Lexer`
to filter out the trivia tokens[^1]. Now, the parser will ask the token
source to get the next token and only then the lexer will continue and
emit the token. This means that the lexer needs to be aware of the
"current" token. When the `next_token` is called, the current token will
be updated with the newly lexed token.
The main motivation to make the lexer lazy is to allow re-lexing a token
in a different context. This is going to be really useful to make the
parser error resilience. For example, currently the emitted tokens
remains the same even if the parser can recover from an unclosed
parenthesis. This is important because the lexer emits a
`NonLogicalNewline` in parenthesized context while a normal `Newline` in
non-parenthesized context. This different kinds of newline is also used
to emit the indentation tokens which is important for the parser as it's
used to determine the start and end of a block.
Additionally, this allows us to implement the following functionalities:
1. Checkpoint - rewind infrastructure: The idea here is to create a
checkpoint and continue lexing. At a later point, this checkpoint can be
used to rewind the lexer back to the provided checkpoint.
2. Remove the `SoftKeywordTransformer` and instead use lookahead or
speculative parsing to determine whether a soft keyword is a keyword or
an identifier
3. Remove the `Tok` enum. The `Tok` enum represents the tokens emitted
by the lexer but it contains owned data which makes it expensive to
clone. The new `TokenKind` enum just represents the type of token which
is very cheap.
This brings up a question as to how will the parser get the owned value
which was stored on `Tok`. This will be solved by introducing a new
`TokenValue` enum which only contains a subset of token kinds which has
the owned value. This is stored on the lexer and is requested by the
parser when it wants to process the data. For example:
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L1260-L1262)
[^1]: Trivia tokens are `NonLogicalNewline` and `Comment`
### Remove `SoftKeywordTransformer`
* https://github.com/astral-sh/ruff/pull/11441
* https://github.com/astral-sh/ruff/pull/11459
* https://github.com/astral-sh/ruff/pull/11442
* https://github.com/astral-sh/ruff/pull/11443
* https://github.com/astral-sh/ruff/pull/11474
For context,
https://github.com/RustPython/RustPython/pull/4519/files#diff-5de40045e78e794aa5ab0b8aacf531aa477daf826d31ca129467703855408220
added support for soft keywords in the parser which uses infinite
lookahead to classify a soft keyword as a keyword or an identifier. This
is a brilliant idea as it basically wraps the existing Lexer and works
on top of it which means that the logic for lexing and re-lexing a soft
keyword remains separate. The change here is to remove
`SoftKeywordTransformer` and let the parser determine this based on
context, lookahead and speculative parsing.
* **Context:** The transformer needs to know the position of the lexer
between it being at a statement position or a simple statement position.
This is because a `match` token starts a compound statement while a
`type` token starts a simple statement. **The parser already knows
this.**
* **Lookahead:** Now that the parser knows the context it can perform
lookahead of up to two tokens to classify the soft keyword. The logic
for this is mentioned in the PR implementing it for `type` and `match
soft keyword.
* **Speculative parsing:** This is where the checkpoint - rewind
infrastructure helps. For `match` soft keyword, there are certain cases
for which we can't classify based on lookahead. The idea here is to
create a checkpoint and keep parsing. Based on whether the parsing was
successful and what tokens are ahead we can classify the remaining
cases. Refer to #11443 for more details.
If the soft keyword is being parsed in an identifier context, it'll be
converted to an identifier and the emitted token will be updated as
well. Refer
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L487-L491).
The `case` soft keyword doesn't require any special handling because
it'll be a keyword only in the context of a match statement.
### Update the parser API
* https://github.com/astral-sh/ruff/pull/11494
* https://github.com/astral-sh/ruff/pull/11505
Now that the lexer is in sync with the parser, and the parser helps to
determine whether a soft keyword is a keyword or an identifier, the
lexer cannot be used on its own. The reason being that it's not
sensitive to the context (which is correct). This means that the parser
API needs to be updated to not allow any access to the lexer.
Previously, there were multiple ways to parse the source code:
1. Passing the source code itself
2. Or, passing the tokens
Now that the lexer and parser are working together, the API
corresponding to (2) cannot exists. The final API is mentioned in this
PR description: https://github.com/astral-sh/ruff/pull/11494.
### Refactor the downstream tools (linter and formatter)
* https://github.com/astral-sh/ruff/pull/11511
* https://github.com/astral-sh/ruff/pull/11515
* https://github.com/astral-sh/ruff/pull/11529
* https://github.com/astral-sh/ruff/pull/11562
* https://github.com/astral-sh/ruff/pull/11592
And, the final set of changes involves updating all references of the
lexer and `Tok` enum. This was done in two-parts:
1. Update all the references in a way that doesn't require any changes
from this PR i.e., it can be done independently
* https://github.com/astral-sh/ruff/pull/11402
* https://github.com/astral-sh/ruff/pull/11406
* https://github.com/astral-sh/ruff/pull/11418
* https://github.com/astral-sh/ruff/pull/11419
* https://github.com/astral-sh/ruff/pull/11420
* https://github.com/astral-sh/ruff/pull/11424
2. Update all the remaining references to use the changes made in this
PR
For (2), there were various strategies used:
1. Introduce a new `Tokens` struct which wraps the token vector and add
methods to query a certain subset of tokens. These includes:
1. `up_to_first_unknown` which replaces the `tokenize` function
2. `in_range` and `after` which replaces the `lex_starts_at` function
where the former returns the tokens within the given range while the
latter returns all the tokens after the given offset
2. Introduce a new `TokenFlags` which is a set of flags to query certain
information from a token. Currently, this information is only limited to
any string type token but can be expanded to include other information
in the future as needed. https://github.com/astral-sh/ruff/pull/11578
3. Move the `CommentRanges` to the parsed output because this
information is common to both the linter and the formatter. This removes
the need for `tokens_and_ranges` function.
## Test Plan
- [x] Update and verify the test snapshots
- [x] Make sure the entire test suite is passing
- [x] Make sure there are no changes in the ecosystem checks
- [x] Run the fuzzer on the parser
- [x] Run this change on dozens of open-source projects
### Running this change on dozens of open-source projects
Refer to the PR description to get the list of open source projects used
for testing.
Now, the following tests were done between `main` and this branch:
1. Compare the output of `--select=E999` (syntax errors)
2. Compare the output of default rule selection
3. Compare the output of `--select=ALL`
**Conclusion: all output were same**
## What's next?
The next step is to introduce re-lexing logic and update the parser to
feed the recovery information to the lexer so that it can emit the
correct token. This moves us one step closer to having error resilience
in the parser and provides Ruff the possibility to lint even if the
source code contains syntax errors.
## Summary
Implement support for RDJson output for `ruff check`, as requested in
#8655.
## Test Plan
Tested using a snapshot test. Same approach as for e.g. the JSON output
formatter.
## Additional info
I tried to keep the implementation close to the JSON implementation.
I had to deviate a bit to make the `suggestions` key work: If there are
no suggestions, then setting `suggestions` to `null` is invalid
according to the JSONSchema. Therefore, I opted for a slightly more
complex implementation, that skips the `suggestions` key entirely if
there are no fixes available for the given diagnostic. Maybe it would
have been easier to set `"suggestions": []`, but I ended up doing it
this way.
I didn't consider notebooks, as I _think_ that RDJson doesn't work with
notebooks. This should be confirmed, and if so, there should be some
form of warning or error emitted when trying to output diagnostics for a
notebook.
I also didn't consider `ruff format`, as this comment:
https://github.com/astral-sh/ruff/issues/8655#issuecomment-1811446160
suggests that that wouldn't be compatible.
I'm new to Rust, any feedback is appreciated. 🙂 I
implemented this in order to have a productive rainy saturday afternoon,
I'm not knowledgeable about RDJson beyond the sources linked in the
issue.
## Summary
This PR implements the rule B901, which is part of the opinionated rules
of `flake8-bugbear`.
This rule seems to be desired in `ruff` as per
https://github.com/astral-sh/ruff/issues/3758 and
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976.
## Test Plan
As this PR was made closely following the
[CONTRIBUTING.md](8a25531a71/CONTRIBUTING.md),
it tests using the snapshot approach, that is described there.
## Sources
The implementation is inspired by [the original implementation in the
`flake8-bugbear`
repository](d1aec4cbef/bugbear.py (L1092)).
The error message and [test
file](d1aec4cbef/tests/b901.py)
where also copied from there.
The documentation I came up with on my own and needs improvement. Maybe
the example given in
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976
could be used, but maybe they are too complex, I'm not sure.
## Open Questions
- [ ] Documentation. (See above.)
- [x] Can I access the parent in a visitor?
The [original
implementation](d1aec4cbef/bugbear.py (L1100))
references the `yield` statement's parent to check if it is an
expression statement. I didn't find a way to do this in `ruff` and used
the `is_expresssion_statement` field on the visitor instead. What are
your thoughts on this? Is it possible and / or desired to access the
parent node here?
- [x] Is `Option::is_some(...)` -> `...unwrap()` the right thing to do?
Referring to [this piece of
code](9d5a280f71/crates/ruff_linter/src/rules/flake8_bugbear/rules/return_x_in_generator.rs?plain=1#L91-L96).
From my understanding, the `.unwrap()` is safe, because it is checked
that `return_` is not `None`. However, I feel like I missed a more
elegant solution that does both in one.
## Other
I don't know a lot about this rule, I just implemented it because I
found it in a
https://github.com/astral-sh/ruff/labels/good%20first%20issue.
I'm new to Rust, so any constructive critisism is appreciated.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Introduces the skeleton of the flow graph. So far it doesn't actually
handle any non-linear control flow :) But it does show how we can go
from an expression that references a symbol, backward through the flow
graph, to find reachable definitions of that symbol.
Adding non-linear control flow will mean adding flow nodes with multiple
predecessors, which will introduce more complexity into
`ReachableDefinitionsIterator.next()`. But one step at a time.
## Test Plan
Added a (very basic) test.
## Summary
Give red-knot the ability to infer int literal types. This is quick and
easy, mostly because these types are a convenient way to observe
control-flow handling with simple assignments.
## Test Plan
Added test.
## Summary
In the [roadmap for `ruff
server`](https://github.com/astral-sh/ruff/discussions/10581) support
for vim and kate is listed. Therefore I added setup guides for them
based on the neovim guide. As I don't use pyright I wasn't able to
translate the corresponding part from the neovim guide.
## Test Plan
Doesn't apply.
* Potentially resolves#11619 (nondeterministic hashmap order across
different architectures) in F401 by replacing a hashmap with
nondeterministic traversal order with an ordered mapping.
I'm not sure how to test this with our CI/CD. I don't have an s390x
machine at home. Should I try it in Qemu?
## Summary
In an `__init__.py` file, it's not uncommon to lack a logical indent
(since it may just contain imports). In such cases, we were always
falling back to four-space indent. This PR adds detection for indents
within import groups.
Closes https://github.com/astral-sh/ruff/issues/11606.
## Summary
This PR aims to close#10095 by adding an option
`init-allow-undef-export` to the `pyflakes` settings. This option is
currently set to `true` such that behavior is kept identical.
But setting this option to `false` will lead to `F822` warnings to be
shown in all files, **including** `__init__.py` files.
As I've mentioned on #10095, I think `init-allow-undef-export=false`
would be the more user-friendly default option, as it creates fewer
surprises. @charliermarsh what do you think about making that the
default?
With this option in place, it's a single line fix for people that rely
on the old behavior.
And thinking longer term, for future major releases, one could probably
consider deprecating the option and eventually having people just `noqa`
these warnings if they are not wanted.
## Test Plan
I've added a `test_init_f822_enabled` test which repeats the test that
is done in the `init` test but this time with
`init-allow-undef-export=false` and the snap file correctly shows that
ruff will then trigger the otherwise suppressed F822 warning.
closes#10095
## Summary
Removed stray space in sample code snippet that is against ruff's own
default formatting rules.
This documentation appears on
https://docs.astral.sh/ruff/rules/unused-import/
## Test Plan
This is a trivially obvious change, verifiable with `ruff format
--check`
## Summary
Closes https://github.com/astral-sh/ruff/issues/11587.
## Test Plan
- Added a lint error to `test_server.py` in `vscode-ruff`.
- Validated that, prior to this change, diagnostics appeared in the
file.
- Validated that, with this change, no diagnostics were shown.
- Validated that, with this change, no diagnostics were fixed on-save.
## Summary
- Implements `Y066` from `flake8-pyi` as `PYI066`
- Fixes `PYI006` not being raised for `elif` clauses. This would have
conflicted with PYI006's implementation, so decided to do it in the same
PR.
## Test Plan
`cargo test` / `cargo insta review`
* Add a module type, `ModuleTypeId`
* Add an attribute lookup method `get_member` for `Type`
* Only implemented for `ModuleTypeId` and `ClassTypeId`
* [x] Should this be a trait?
*Answer: no*
* [x] Uses `unwrap`, but we should remove that. Maybe add a new variant
to `QueryError`?
*Answer: Return `Option<Type>` as is done elsewhere*
* Add `infer_definition_type` case for `Import`
* Add `infer_expr_type` case for `Attribute`
* Add a test to exercise these
* [x] remove all NOTE/FIXME/TODO after discussing with reviewers
## Summary
This PR ensures that if a variable is bound via `global`, and then the
`global` is read, the originating variable is also marked as read. It's
not perfect, in that it won't detect _rebindings_, like:
```python
from app import redis_connection
def func():
global redis_connection
redis_connection = 1
redis_connection()
```
So, above, `redis_connection` is still marked as unused.
But it does avoid flagging `redis_connection` as unused in:
```python
from app import redis_connection
def func():
global redis_connection
redis_connection()
```
Closes https://github.com/astral-sh/ruff/issues/11518.
## Summary
Follow up to https://github.com/astral-sh/ruff/pull/11521
Removes the extra added complexity for catch all match cases. This
matches the implementation of plain `else` statements.
## Test Plan
Added new test cases.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR fixes the bug to avoid flattening the global-only settings for
the new server.
This was added in https://github.com/astral-sh/ruff/pull/11497, possibly
to correctly de-serialize an empty value (`{}`). But, this lead to a bug
where the configuration under the `settings` key was not being read for
global-only variant.
By using #[serde(default)], we ensure that the settings field in the
`GlobalOnly` variant is optional and that an empty JSON object `{}` is
correctly deserialized into `GlobalOnly` with a default `ClientSettings`
instance.
fixes: #11507
## Test Plan
Update the snapshot and existing test case. Also, verify the following
settings in Neovim:
1. Nothing
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
}
```
2. Empty dictionary
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = vim.empty_dict(),
}
```
3. Empty `settings`
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = {
settings = vim.empty_dict(),
},
}
```
4. With some configuration:
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = {
settings = {
configuration = '/tmp/ruff-repro/pyproject.toml',
},
},
}
```
## Summary
This PR brings back the functionality to remove empty strings when
converting to an f-string in `UP032`.
For context, https://github.com/astral-sh/ruff/pull/8712 added this
functionality to remove _trailing_ empty strings but it got removed in
https://github.com/astral-sh/ruff/pull/8697 possibly unexpectedly so.
There's one difference which is that this PR will remove _any_ empty
strings and not just trailing ones. For example,
```diff
--- /Users/dhruv/playground/ruff/src/UP032.py
+++ /Users/dhruv/playground/ruff/src/UP032.py
@@ -1,7 +1,5 @@
(
- "{a}"
- ""
- "{b}"
- ""
-).format(a=1, b=1)
+ f"{1}"
+ f"{1}"
+)
```
## Test Plan
Run `cargo insta test` and update the snapshots.
## Summary
This PR updates the sequence sorting (`RUF022` and `RUF023`) to avoid
using the owned data from the string token. Instead, we will directly
use the reference to the data on the AST. This does introduce a lot of
lifetimes but that's required.
The main motivation for this is to allow removing the `lex_starts_at`
usage easily.
### Alternatives
1. Extract the raw string content (stripping the prefix and quotes)
using the `Locator` and use that for comparison
2. Build up an
[`IndexVec`](3e30962077/crates/ruff_index/src/vec.rs)
and use the newtype index in place of the string value itself. This also
does require lifetimes so we might as well just use the method in this
PR.
## Test Plan
`cargo insta test` and no ecosystem changes
## Summary
Fixes#11506.
`RuffSettingsIndex::new` now searches for configuration files in parent
directories.
## Test Plan
I confirmed that the original test case described in the issue worked as
expected.
## Summary
Concurrent GitLab runners clone projects into separate directories, e.g.
`{builds_dir}/$RUNNER_TOKEN_KEY/$CONCURRENT_ID/$NAMESPACE/$PROJECT_NAME`.
Since the fingerprint uses the full path to the file, the fingerprints
calculated by Ruff are different depending on which concurrent runner it
executes on, so often an MR will appear to remove all existing issues
and add them with new fingerprints.
I've adjusted the fingerprint function to use the project relative path,
which fixes this. Unfortunately this will have a breaking change for any
current users of this output - the fingerprints will change and appear
in GitLab as all linting messages having been fixed and then created.
## Test Plan
`cargo nextest run`
Running `ruff check --output-format gitlab` in a git repo, moving the
repo and running again, verifying no diffs between the outputs
## Summary
Fixes#11534.
`DocumentQuery::source_type` now returns `PySourceType::Stub` when the
document is a `.pyi` file.
## Test Plan
I confirmed that stub-specific rule violations appeared with a build
from this PR (they were not visible from a `main` build).
<img width="1066" alt="Screenshot 2024-05-24 at 2 15 38 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/cd519b7e-21e4-41c8-bc30-43eb6d4d438e">
Hi!
I left out some of the functions in the migration rule which became
removed in NumPy 2.0:
- `np.alltrue`
- `np.anytrue`
- `np.cumproduct`
- `np.product`
Addressing: https://github.com/numpy/numpy/issues/26493
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Current doc says `sys.version[0]` will select the first digit of a major
version number (correct) then as an example says
> e.g., `"3.10"` would evaluate to `"1"`
(would actually evaluate to `"3"`). Changed the example version to a
two-digit number to make the problem more clear.
## Test Plan
<!-- How was it tested? -->
ran the following:
- `cargo run -p ruff -- check
crates/ruff_linter/resources/test/fixtures/flake8_2020/YTT301.py
--no-cache`
- `cargo insta review`
- `cargo test`
which all passed.
## Summary
Rule `logging-warn` (`G010`) prescribes a change from `warn` to
`warning` and has a corresponding autofix, but the autofix is mistakenly
titled ```"Convert to `warn`"``` instead of ```"Convert to `warning`"```
(the latter is what the autofix actually does). Seems to be a plain
typo.
## Summary
Fixes#11516
`ruff server` was sending both regular source actions and notebook
source actions back when passed an empty action filter. This PR makes a
few small changes so that notebook source actions are not sent when
regular source actions are sent, which means that an empty filter will
only return regular source actions.
## Test Plan
I confirmed that duplicate code actions no longer appeared in Neovim,
using a configuration similar to the one from the original issue.
<img width="509" alt="Screenshot 2024-05-23 at 11 48 48 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/9a5d6907-dd41-48bd-b015-8a344c5e0b3f">
## Summary
It turns out that `singledispatch` does end up evaluating all arguments,
even though only the first is used to dispatch.
Closes https://github.com/astral-sh/ruff/issues/11520.
## Summary
Addresses #8451 by implementing rule 116 to add an unsafe fix when sleep
is used with a >24 hour interval to instead consider sleeping forever.
This rule is added as async instead as I my understanding was that these
trio rules would be moved to async anyway.
There are a couple of TODOs, which address further extending the rule by
adding support for lookups and evaluations, and also supporting `anyio`.
## Summary
This PR updates the `FA102` rule logic to use the `Importer` which is
available on the `Checker`.
The main motivation is that this would make updating the `Importer` to
use the `Tokens` struct which will be required to remove the
`lex_starts_at` usage in `Insertion::start_of_block` method.
## Test Plan
`cargo insta test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11236.
This PR fixes several issues, most of which relate to non-VS Code
editors (Helix and Neovim).
1. Global-only initialization options are now correctly deserialized
from Neovim and Helix
2. Empty diagnostics are now published correctly for Neovim and Helix.
3. A workspace folder is created at the current working directory if the
initialization parameters send an empty list of workspace folders.
4. The server now gracefully handles opening files outside of any known
workspace, and will use global fallback settings taken from client
editor settings and a user settings TOML, if it exists.
## Test Plan
I've tested to confirm that each issue has been fixed.
* Global-only initialization options are now correctly deserialized from
Neovim and Helix + the server gracefully handles opening files outside
of any known workspace
https://github.com/astral-sh/ruff/assets/19577865/4f33477f-20c8-4e50-8214-6608b1a1ea6b
* Empty diagnostics are now published correctly for Neovim and Helix
https://github.com/astral-sh/ruff/assets/19577865/c93f56a0-f75d-466f-9f40-d77f99cf0637
* A workspace folder is created at the current working directory if the
initialization parameters send an empty list of workspace folders.
https://github.com/astral-sh/ruff/assets/19577865/b4b2e818-4b0d-40ce-961d-5831478cc726
## Summary
Similar to #11414, this PR extends `UP037` to flag quoted annotations
that are located in positions that won't be evaluated at runtime.
For example, the quotes on `Tuple` are unnecessary in:
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from typing import Tuple
def foo():
x: "Tuple[int, int]" = (0, 0)
foo()
```
## Summary
Recent changes made in the [Jupyter Notebook feature
PR](https://github.com/astral-sh/ruff/pull/11206) caused automatic
configuration reloading to stop working. This was because we would check
for paths to reload using the changed path, when we should have been
using the parent path of the changed path (to get the directory it was
changed in).
Additionally, this PR fixes an issue where `ruff.toml` and `.ruff.toml`
files were not being automatically reloaded.
Finally, this PR improves configuration reloading by actively publishing
diagnostics for notebook documents (which won't be affected by the
workspace refresh since they don't use pull diagnostics). It will also
publish diagnostics for text documents if pull diagnostics aren't
supported.
## Test Plan
To test this, open an existing configuration file in a codebase, and
make modifications that will affect one or more open Python / Jupyter
Notebook files. You should observe that the diagnostics for both kinds
of files update automatically when the file changes are saved.
Here's a test video showing what a successful test should look like:
https://github.com/astral-sh/ruff/assets/19577865/7172b598-d6de-4965-b33c-6cb8b911ef6c
## Summary
Previously, `ruff.applyFormat`, seen in VS Code as the command `Ruff:
Format Document`, would only format the currently active notebook cell
inside a notebook document. This PR makes `ruff.applyFormat` format the
entire notebook document at once, operating on each code cell in order.
## Test Plan
1. Open a notebook document that has multiple unformatted code cells.
2. Run `Ruff: Format Document` through the Command Palette
(`Ctrl/Cmd+Shift+P` by default)
3. Observe that all code cells in the notebook have been formatted.
## Summary
This PR moves the `has_comments` function from `Indexer` to
`CommentRanges`. The main motivation is that the `CommentRanges` will
now be built by the parser which is shared between the linter and the
formatter. Thus, the `CommentRanges` will be removed from the `Indexer`.
## Test Plan
`cargo test`
## Summary
Matching Pylint, we now omit the `try` body itself from branch counting.
Each `except` counts as a branch, as does the `else` and the `finally`.
Closes https://github.com/astral-sh/ruff/issues/11205.
## Summary
Closes https://github.com/astral-sh/ruff/issues/10858.
`ruff server` now supports `*.ipynb` (aka Jupyter Notebook) files.
Extensive internal changes have been made to facilitate this, which I've
done some work to contextualize with documentation and an pre-review
that highlights notable sections of the code.
`*.ipynb` cells should behave similarly to `*.py` documents, with one
major exception. The format command `ruff.applyFormat` will only apply
to the currently selected notebook cell - if you want to format an
entire notebook document, use `Format Notebook` from the VS Code context
menu.
## Test Plan
The VS Code extension does not yet have Jupyter Notebook support
enabled, so you'll first need to enable it manually. To do this,
checkout the `pre-release` branch and modify `src/common/server.ts` as
follows:
Before:

After:

I recommend testing this PR with large, complicated notebook files. I
used notebook files from [this popular
repository](https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks)
in my preliminary testing.
The main thing to test is ensuring that notebook cells behave the same
as Python documents, besides the aforementioned issue with
`ruff.applyFormat`. You should also test adding and deleting cells (in
particular, deleting all the code cells and ensure that doesn't break
anything), changing the kind of a cell (i.e. from markup -> code or vice
versa), and creating a new notebook file from scratch. Finally, you
should also test that source actions work as expected (and across the
entire notebook).
Note: `ruff.applyAutofix` and `ruff.applyOrganizeImports` are currently
broken for notebook files, and I suspect it has something to do with
https://github.com/astral-sh/ruff/issues/11248. Once this is fixed, I
will update the test plan accordingly.
---------
Co-authored-by: nolan <nolan.king90@gmail.com>
The wording 'negative comparison' is a rather vague description of the
'is not' operation and does not describe what the 'not in' operation
does (potentially copied from 'is not'). This was replaced with more
precise language to describe the operators taken from the official
python docs[1].
Both rules didn't have a strong reasoning besides 'it's bad, use the
other'. The origin of these rules seems to be PEP8[2] which prefers 'is
not' over 'not ... is' for readability. This is now reflected in the
description.
[1]:
https://docs.python.org/3/reference/expressions.html#membership-test-operations
[2]: https://peps.python.org/pep-0008/#programming-recommendations
## Summary
If an annotation won't be evaluated at runtime, we don't need to flag
`from __future__ import annotations` as required. This applies both to
quoted annotations and annotations outside of runtime-evaluated
positions, like:
```python
def main() -> None:
a_list: list[str] | None = []
a_list.append("hello")
```
Closes https://github.com/astral-sh/ruff/issues/11397.
## Summary
* Update documentation for F401 following recent PRs
* #11168
* #11314
* Deprecate `ignore_init_module_imports`
* Add a deprecation pragma to the option and a "warn user once" message
when the option is used.
* Restore the old behavior for stable (non-preview) mode:
* When `ignore_init_module_imports` is set to `true` (default) there are
no `__init_.py` fixes (but we get nice fix titles!).
* When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
* When preview mode is enabled, it overrides
`ignore_init_module_imports`.
* Fixed a bug in fix titles where `import foo as bar` would recommend
reexporting `bar as bar`. It now says to reexport `foo as foo`. (In this
case we don't issue a fix, fwiw; it was just a fix title bug.)
## Test plan
Added new fixture tests that reuse the existing fixtures for
`__init__.py` files. Each of the three situations listed above has
fixture tests. The F401 "stable" tests cover:
> * When `ignore_init_module_imports` is set to `true` (default) there
are no `__init_.py` fixes (but we get nice fix titles!).
The F401 "deprecated option" tests cover:
> * When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
These complement existing "preview" tests that show the new behavior
which recommends fixes in `__init__.py` according to whether the import
is 1st party and other circumstances (for more on that behavior see:
#11314).
## Summary
This is a follow-up PR to #11445 update the `E27` rules to consider soft
keywords as well.
## Test Plan
Add test cases consisting of soft keywords and update the snapshot.
## Summary
We weren't treating the escaped newline as a valid condition to trigger
the safer fix (add an extra backslash before each invalid escape
sequence).
Closes https://github.com/astral-sh/ruff/issues/11461.
## Summary
This PR updates the `TokenKind::is_keyword` check to include soft
keywords. To account for this change, it adds a new
`is_non_soft_keyword` method.
The usage in logical line rules were updated to use the
`is_non_soft_keyword` method but it'll be updated to use `is_keyword` in
a follow-up PR (#11446).
While, the parser usages were kept as is. And because of that, the
snapshots for two test cases were updated in a better direction.
## Test Plan
`cargo insta test`
## Summary
We already have handling for "references that get quoted within our
quoted references", but we were assuming a specific ordering in the way
edits were generated.
Closes https://github.com/astral-sh/ruff/issues/11449.
This is useful for extracting the defaults in order to construct
equivalent configs by external scripts. This is my first non-hello-world
rust code, comments and suggested tests appreciated.
## Summary
We already have `ruff linter --output-format json`, this provides `ruff
config x --output-format json` as well. I plan to use this to construct
an equivalent config snippet to include in some managed repos, so when
we update their version of ruff and it adds new lints, they get a PR
that includes the commented-out new lints.
Note that the no-args form of `ruff config` ignores output-format
currently, but probably should obey it (although array-of-strings
doesn't seem that useful, looking for input on format).
## Test Plan
I could use a hand coming up with a typical way to write automated tests
for this.
```sh-session
(.venv) [timhatch:ruff ]$ ./target/debug/ruff config lint.select
A list of rule codes or prefixes to enable. Prefixes can specify exact
rules (like `F841`), entire categories (like `F`), or anything in
between.
When breaking ties between enabled and disabled rules (via `select` and
`ignore`, respectively), more specific prefixes override less
specific prefixes.
Default value: ["E4", "E7", "E9", "F"]
Type: list[RuleSelector]
Example usage:
``toml
# On top of the defaults (`E4`, E7`, `E9`, and `F`), enable flake8-bugbear (`B`) and flake8-quotes (`Q`).
select = ["E4", "E7", "E9", "F", "B", "Q"]
``
(.venv) [timhatch:ruff ]$ ./target/debug/ruff config lint.select --output-format json
{
"Field": {
"doc": "A list of rule codes or prefixes to enable. Prefixes can specify exact\nrules (like `F841`), entire categories (like `F`), or anything in\nbetween.\n\nWhen breaking ties between enabled and disabled rules (via `select` and\n`ignore`, respectively), more specific prefixes override less\nspecific prefixes.",
"default": "[\"E4\", \"E7\", \"E9\", \"F\"]",
"value_type": "list[RuleSelector]",
"scope": null,
"example": "# On top of the defaults (`E4`, E7`, `E9`, and `F`), enable flake8-bugbear (`B`) and flake8-quotes (`Q`).\nselect = [\"E4\", \"E7\", \"E9\", \"F\", \"B\", \"Q\"]",
"deprecated": null
}
}
```
## Summary
As discussed in issue #11408, PLR0912 has a broader definition of
"branches" than I expected. This updates the documentation to include
this definition.
I also updated the example to include several different types of
branches, while still maintaining dictionary lookup as an alternative
solution. (Crafting a realistic example was quite a challenge 😅).
Closes https://github.com/astral-sh/ruff/issues/11408.
## Summary
This moves the string-prefix enumerations in `ruff_python_ast` to a
separate submodule. I think this helps clarify that these prefixes are
purely abstract: they only depend on each other, and do not depend on
any of the other code in `nodes.rs` in any way. Moreover, while various
AST nodes _use_ them, they're not really nodes themselves, so they feel
slightly out of place in `nodes.rs`.
I considered moving all of them to `str.rs`, but it felt like enough
code that it could be a separate submodule.
## Test Plan
`cargo test`
Followup on #11168 and resolve#10391
# User facing changes
* F401 now recommends a fix to add unused import bindings to to
`__all__` if a single `__all__` list or tuple is found in `__init__.py`.
* If there are no `__all__` found in the file, fall back to recommending
redundant-aliases.
* If there are multiple `__all__` or only one but of the wrong type (non
list or tuple) then diagnostics are generated without fixes.
* `fix_title` is updated to reflect what the fix/recommendation is.
Subtlety: For a renamed import such as `import foo as bees`, we can
generate a fix to add `bees` to `__all__` but cannot generate a fix to
produce a redundant import (because that would break uses of the binding
`bees`).
# Implementation changes
* Add `name` field to `ImportBinding` to contain the name of the
_binding_ we want to add to `__all__` (important for the `import foo as
bees` case). It previously only contained the `AnyImport` which can give
us information about the import but not the binding.
* Add `binding` field to `UnusedImport` to contain the same. (Naming
note: the field `name` field already existed on `UnusedImport` and
contains the qualified name of the imported symbol/module)
* Change `fix_by_reexporting` to branch on the size of `dunder_all:
Vec<&Expr>`
* For length 0 call the edit-producing function `make_redundant_alias`.
* For length 1 call edit-producing function `add_to_dunder_all`.
* Otherwise, produce no fix.
* Implement the edit-producing function `add_to_dunder_all` and add unit
tests.
* Implement several fixture tests: empty `__all__ = []`, nonempty
`__all__ = ["foo"]`, mis-typed `__all__ = None`, plus-eq `__all__ +=
["foo"]`
* `UnusedImportContext::Init` variant now has two fields: whether the
fix is in `__init__.py` and how many `__all__` were found.
# Other changes
* Remove a spurious pattern match and instead use field lookups b/c the
addition of a field would have required changing the unrelated pattern.
* Tweak input type of `make_redundant_alias`
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR follows up from #11420 to move `UP034` to use `TokenKind`
instead of `Tok`.
The main reason to have a separate PR is so that the reviewing is easy.
This required a lot more updates because the rule used an index (`i`) to
keep track of the current position in the token vector. Now, as it's
just an iterator, we just use `next` to move the iterator forward and
extract the relevant information.
This is part of https://github.com/astral-sh/ruff/issues/11401
## Test Plan
`cargo test`
## Summary
This PR moves the following rules to use `TokenKind` instead of `Tok`:
* `PLE2510`, `PLE2512`, `PLE2513`, `PLE2514`, `PLE2515`
* `E701`, `E702`, `E703`
* `ISC001`, `ISC002`
* `COM812`, `COM818`, `COM819`
* `W391`
I've paused here because the next set of rules
(`pyupgrade::rules::extraneous_parentheses`) indexes into the token
slice but we only have an iterator implementation. So, I want to isolate
that change to make sure the logic is still the same when I move to
using the iterator approach.
This is part of #11401
## Test Plan
`cargo test`
## Summary
Alternative to #11237
This PR adds a new `Tokens` struct which is a newtype wrapper around a
vector of lexer output. This allows us to add a `kinds` method which
returns an iterator over the corresponding `TokenKind`. This iterator is
implemented as a separate `TokenKindIter` struct to allow using the type
and provide additional methods like `peek` directly on the iterator.
This exposes the linter to access the stream of `TokenKind` instead of
`Tok`.
Edit: I've made the necessary downstream changes and plan to merge the
entire stack at once.
## Summary
This PR updates the linter benchmark to use the `tokenize` function
instead of the lexer.
The linter expects the token list to be up to and including the first
error which is what the `ruff_python_parser::tokenize` function returns.
This was not a problem before because the benchmarks only uses valid
Python code.
## Summary
This PR adds a newtype wrapper around `Vec<FStringElement>` that derefs
to a `&Vec<FStringElement>`.
Both f-string and format specifier are made up of `Vec<FStringElement>`.
By creating a newtype wrapper around it, we can share the methods for
both parent types.
## Summary
This PR adds support to iterate over each part of a string-like
expression.
This similar to the one in the formatter:
128414cd95/crates/ruff_python_formatter/src/string/any.rs (L121-L125)
Although I don't think it's a 1-1 replacement in the formatter because
the one implemented in the formatter has another information for certain
variants (as can be seen for `FString`).
The main motivation for this is to avoid duplication for rules which
work only on the parts of the string and doesn't require any information
from the parent node. Here, the parent node being the expression node
which could be an implicitly concatenated string.
This PR also updates certain rule implementation to make use of this and
avoids logic duplication.
## Summary
This PR renames `AnyStringKind` to `AnyStringFlags` and `AnyStringFlags`
to `AnyStringFlagsInner`.
The main motivation is to have consistent usage of "kind" and "flags".
For each string kind, it's "flags" like `StringLiteralFlags`,
`BytesLiteralFlags`, and `FStringFlags` but it was `AnyStringKind` for
the "any" variant.
## Summary
Changes `future-rewritable-type-annotation` (`FA100`) message to be less
confusing. Uses phrasing from the rule documentation to be consistent.
For example,
```
from_typing_import.py:5:13: FA100 Add `from __future__ import annotations` to rewrite `typing.List` more succinctly
```
Closes#10573.
## Test Plan
`cargo nextest run`
## Summary
Should this consider the decorator only if the name is actually a
property or is the logic in this PR correct?
fixes: #11358
## Test Plan
Add test case.
## Summary
This PR fixes a bug where the auto-fix for `TCH005` would delete the
entire `if` statement.
The fix in this PR is to not consider it a violation if there are any
`elif`/`else` blocks. This also matches the behavior of the original
plugin.
fixes: #11368
## Test plan
Add test cases.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/10594.
Code actions to disable a diagnostic via `noqa` comment are now
available.
https://github.com/astral-sh/ruff/assets/19577865/6d3bcf11-a9d9-499b-8c7f-a10cd39cfbba
`DiagnosticFix` has been changed so that `noqa` code actions appear even
for diagnostics with no available quick fix. It can contain quick fix
edits, `noqa` comment edits, or both.
## Test Plan
The scenarios that need to be tested are as follows:
* A code action to disable a diagnostic should be available for every
diagnostic.
* Using this code action should append to the appropriate line with the
diagnostic, or modify an existing `noqa` comment.
* Adding a `noqa` comment manually should make a diagnostic disappear
* `Fix all auto-fixable problems` should not add `noqa` comments
* Removing a code from a `noqa` comment should make the diagnostic
re-appear
## Summary
`--add-noqa` now runs in two stages: first, the linter finds all
diagnostics that need noqa comments and generate edits on a per-line
basis. Second, these edits are applied, in order, to the document.
A public-facing function, `generate_noqa_edits`, has also been
introduced, which returns noqa edits generated on a per-diagnostic
basis. This will be used by `ruff server` for noqa comment quick-fixes.
## Test Plan
Unit tests have been updated.
## Summary
This PR adds updates the semantic model to detect attribute docstring.
Refer to [PEP 258](https://peps.python.org/pep-0258/#attribute-docstrings)
for the definition of an attribute docstring.
This PR doesn't add full support for it but only considers string
literals as attribute docstring for the following cases:
1. A string literal following an assignment statement in the **global
scope**.
2. A global class attribute
For an assignment statement, it's considered an attribute docstring only
if the target expression is a name expression (`x = 1`). So, chained
assignment, multiple assignment or unpacking, and starred expression,
which are all valid in the target position, aren't considered here.
In `__init__` method, an assignment to the `self` variable like `self.x = 1`
is also a candidate for an attribute docstring. **This PR does not
support this position.**
## Test Plan
I used the following source code along with a print statement to verify
that the attribute docstring detection is correct.
Refer to the PR description for the code snippet.
I'll add this in the follow-up PR
(https://github.com/astral-sh/ruff/pull/11302) which uses this method.
## Summary
Lots of TODOs and things to clean up here, but it demonstrates the
working lint rule.
## Test Plan
```
➜ cat main.py
from typing import override
from base import B
class C(B):
@override
def method(self): pass
➜ cat base.py
class B: pass
➜ cat typing.py
def override(func):
return func
```
(We provide our own `typing.py` since we don't have typeshed vendored or
type stub support yet.)
```
➜ ./target/debug/red_knot main.py
...
1 0.012086s TRACE red_knot Main Loop: Tick
[crates/red_knot/src/main.rs:157:21] diagnostics = [
"Method C.method is decorated with `typing.override` but does not override any base class method",
]
```
If we add `def method(self): pass` to class `B` in `base.py` and run
red_knot again, there is no lint error.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves#11263
Detect `pathlib.Path.open` calls which do not specify a file encoding.
## Test Plan
Test cases added to fixture.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
This PR vendors typeshed!
- The first commit vendors the stdlib directory from typeshed into a new crates/red_knot/vendored_typeshed directory.
- The second commit adjusts various linting config files to make sure that the vendored code is excluded from typo checks, formatting checks, etc.
- The LICENSE and README.md files are also vendored, but all other directories and files (stubs, scripts, tests, test_cases, etc.) are excluded. We should have no need for them (except possibly stubs/, discussed in more depth below).
- Similar to the way pyright has a commit.txt file in its vendored copy of typeshed, to indicate which typeshed commit the vendored code corresponds to, I've also added a crates/red_knot/vendored_typeshed/source_commit.txt file in the third commit of this PR.
One open question is: should we vendor the stdlib and stubs directories, or just the stdlib directory? The stubs/ directory contains stubs for 162 third-party packages outside the stdlib. Mypy and typeshed_client1 only vendor the stdlib directory; pyright and pyre vendor both the stdlib and stubs directories; pytype vendors the entire typeshed repo (scripts/, tests/ and all).
In this PR, I've chosen to copy mypy and typeshed_client. Unlike vendoring the stdlib, which is unavoidable if we want to do typechecking of the stdlib, it's not strictly necessary to vendor the stubs directory: each subdirectory in stubs is published to PyPI as a standalone stubs distribution that can be (uv)-pip-installed into a virtual environment. It might be useful for our users if we vendored those stubs anyway, but there are costs as well as benefits to doing so (apart from just the sheer amount of vendored code in the ruff repository), so I'd rather consider it separately.
Resolves https://github.com/astral-sh/ruff/issues/11313
## Summary
PLR0912(too-many-branches) did not count branches inside with: blocks.
With this fix, the branches inside with statements are also counted.
## Test Plan
Added a new test case.
## Summary
This PR removes the cyclic dev dependency some of the crates had with
the parser crate.
The cyclic dependencies are:
* `ruff_python_ast` has a **dev dependency** on `ruff_python_parser` and
`ruff_python_parser` directly depends on `ruff_python_ast`
* `ruff_python_trivia` has a **dev dependency** on `ruff_python_parser`
and `ruff_python_parser` has an indirect dependency on
`ruff_python_trivia` (`ruff_python_parser` - `ruff_python_ast` -
`ruff_python_trivia`)
Specifically, this PR does the following:
* Introduce two new crates
* `ruff_python_ast_integration_tests` and move the tests from the
`ruff_python_ast` crate which uses the parser in this crate
* `ruff_python_trivia_integration_tests` and move the tests from the
`ruff_python_trivia` crate which uses the parser in this crate
### Motivation
The main motivation for this PR is to help development. Before this PR,
`rust-analyzer` wouldn't provide any intellisense in the
`ruff_python_parser` crate regarding the symbols in `ruff_python_ast`
crate.
```
[ERROR][2024-05-03 13:47:06] .../vim/lsp/rpc.lua:770 "rpc" "/Users/dhruv/.cargo/bin/rust-analyzer" "stderr" "[ERROR project_model::workspace] cyclic deps: ruff_python_parser(Idx::<CrateData>(50)) -> ruff_python_ast(Idx::<CrateData>(37)), alternative path: ruff_python_ast(Idx::<CrateData>(37)) -> ruff_python_parser(Idx::<CrateData>(50))\n"
```
## Test Plan
Check the logs of `rust-analyzer` to not see any signs of cyclic
dependency.
## Summary
While I was here, I also updated the rule to use
`function_type::classify` rather than hard-coding `staticmethod` and
friends.
Per Carl:
> Enum instances are already referred to by the class, forming a cycle
that won't get collected until the class itself does. At which point the
`lru_cache` itself would be collected, too.
Closes https://github.com/astral-sh/ruff/issues/9912.
## Summary
Historically, we only ignored `flake8-blind-except` if you re-raised or
logged the exception as a _direct_ child statement; but it could be
nested somewhere. This was just a known limitation at the time of adding
the previous logic.
Closes https://github.com/astral-sh/ruff/issues/11289.
## Summary
A follow-up to https://github.com/astral-sh/ruff/pull/11222. `ruff
server` stalls during shutdown with Neovim because after it receives an
exit notification and closes the I/O thread, it attempts to log a
success message to `stderr`. Removing this log statement fixes this
issue.
## Test Plan
Track the instances of `ruff` in the OS task manager as you open and
close Neovim. A new instance should appear when Neovim starts and it
should disappear once Neovim is closed.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11258.
This PR fixes the settings resolver to match the expected behavior when
file-based configuration is not available.
## Test Plan
In a workspace with no file-based configuration, set a setting in your
editor and confirm that this setting is used instead of the default.
## Summary
Users can now include tildes and environment variables in the provided
path, just like with `--config`.
Closes#11277.
## Test Plan
Set the configuration path to `"ruff.configuration": "~/x.toml"`;
verified that the server attempted to read from `/Users/crmarsh/x.toml`.
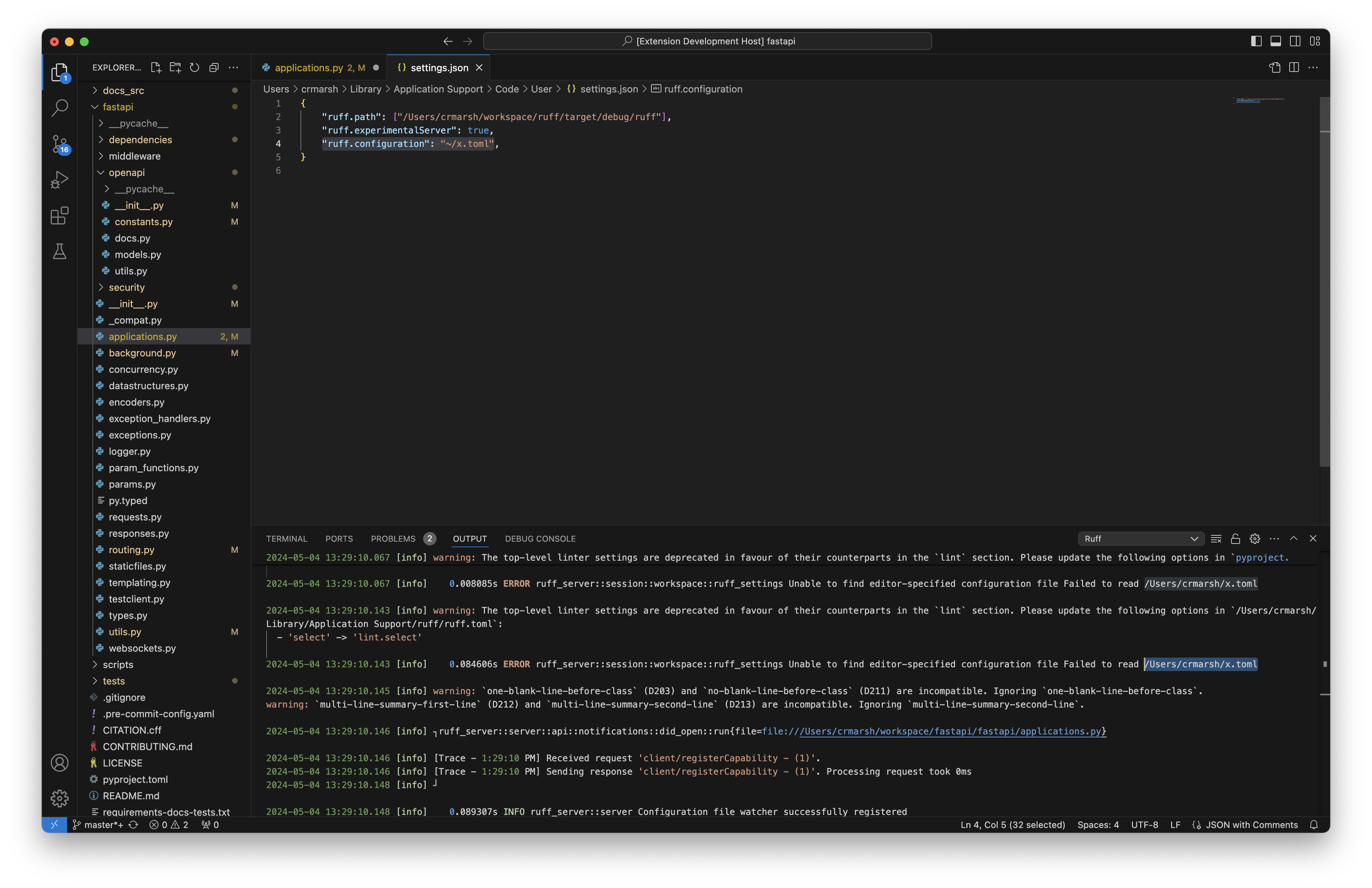
## Summary
Change `hardcoded-tmp-directory-extend` example to follow the schema:
1e91a09918/ruff.schema.json (L896-L901)
<!-- What's the purpose of the change? What does it do, and why? -->
## Summary
In #9218 `Rule::NeverUnion` was partially removed from a
`checker.any_enabled` call. This makes the change consistent.
## Test Plan
`cargo test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11207.
The server would hang after handling a shutdown request on
`IoThreads::join()` because a global sender (`MESSENGER`, used to send
`window/showMessage` notifications) would remain allocated even after
the event loop finished, which kept the writer I/O thread channel open.
To fix this, I've made a few structural changes to `ruff server`. I've
wrapped the send/receive channels and thread join handle behind a new
struct, `Connection`, which facilitates message sending and receiving,
and also runs `IoThreads::join()` after the event loop finishes. To
control the number of sender channels, the `Connection` wraps the sender
channel in an `Arc` and only allows the creation of a wrapper type,
`ClientSender`, which hold a weak reference to this `Arc` instead of
direct channel access. The wrapper type implements the channel methods
directly to prevent access to the inner channel (which would allow the
channel to be cloned). ClientSender's function is analogous to
[`WeakSender` in
`tokio`](https://docs.rs/tokio/latest/tokio/sync/mpsc/struct.WeakSender.html).
Additionally, the receiver channel cannot be accessed directly - the
`Connection` only exposes an iterator over it.
These changes will guarantee that all channels are closed before the I/O
threads are joined.
## Test Plan
Repeatedly open and close an editor utilizing `ruff server` while
observing the task monitor. The net total amount of open `ruff`
instances should be zero once all editor windows have closed.
The following logs should also appear after the server is shut down:
<img width="835" alt="Screenshot 2024-04-30 at 3 56 22 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/404b74f5-ef08-4bb4-9fa2-72e72b946695">
This can be tested on VS Code by changing the settings and then checking
`Output`.
* Add `decorators: Vec<Type>` to `FunctionType` struct
* Thread decorators through two `add_function` definitions
* Populate decorators at the callsite in `infer_symbol_type`
* Small test
Resolves#10390 and starts to address #10391
# Changes to behavior
* In `__init__.py` we now offer some fixes for unused imports.
* If the import binding is first-party this PR suggests a fix to turn it
into a redundant alias.
* If the import binding is not first-party, this PR suggests a fix to
remove it from the `__init__.py`.
* The fix-titles are specific to these new suggested fixes.
* `checker.settings.ignore_init_module_imports` setting is
deprecated/ignored. There is probably a documentation change to make
that complete which I haven't done.
---
<details><summary>Old description of implementation changes</summary>
# Changes to the implementation
* In the body of the loop over import statements that contain unused
bindings, the bindings are partitioned into `to_reexport` and
`to_remove` (according to how we want to resolve the fact they're
unused) with the following predicate:
```rust
in_init && is_first_party(checker, &import.qualified_name().to_string())
// true means make it a reexport
```
* Instead of generating a single fix per import statement, we now
generate up to two fixes per import statement:
```rust
(fix_by_removing_imports(checker, node_id, &to_remove, in_init).ok(),
fix_by_reexporting(checker, node_id, &to_reexport, dunder_all).ok())
```
* The `to_remove` fixes are unsafe when `in_init`.
* The `to_explicit` fixes are safe. Currently, until a future PR, we
make them redundant aliases (e.g. `import a` would become `import a as
a`).
## Other changes
* `checker.settings.ignore_init_module_imports` is deprecated/ignored.
Instead, all fixes are gated on `checker.settings.preview.is_enabled()`.
* Got rid of the pattern match on the import-binding bound by the inner
loop because it seemed less readable than referencing fields on the
binding.
* [x] `// FIXME: rename "imports" to "bindings"` if reviewer agrees (see
code)
* [x] `// FIXME: rename "node_id" to "import_statement"` if reviewer
agrees (see code)
<details>
<summary><h2>Scope cut until a future PR</h2></summary>
* (Not implemented) The `to_explicit` fixes will be added to `__all__`
unless it doesn't exist. When `__all__` doesn't exist they're resolved
by converting to redundant aliases (e.g. `import a` would become `import
a as a`).
---
</details>
# Test plan
* [x] `crates/ruff_linter/resources/test/fixtures/pyflakes/F401_24`
contains an `__init__.py` with*out* `__all__` that exercises the
features in this PR, but it doesn't pass.
* [x]
`crates/ruff_linter/resources/test/fixtures/pyflakes/F401_25_dunder_all`
contains an `__init__.py` *with* `__all__` that exercises the features
in this PR, but it doesn't pass.
* [x] Write unit tests for the new edit functions in
`fix::edits::make_redundant_alias`.
</details>
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR removes the `ImportMap` implementation and all its routing
through ruff.
The import map was added in https://github.com/astral-sh/ruff/pull/3243
but we then never ended up using it to do cross file analysis.
We are now working on adding multifile analysis to ruff, and revisit
import resolution as part of it.
```
hyperfine --warmup 10 --runs 20 --setup "./target/release/ruff clean" \
"./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I" \
"./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 37.6 ms ± 0.9 ms [User: 52.2 ms, System: 63.7 ms]
Range (min … max): 35.8 ms … 39.8 ms 20 runs
Benchmark 2: ./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 36.0 ms ± 0.7 ms [User: 50.3 ms, System: 58.4 ms]
Range (min … max): 34.5 ms … 37.6 ms 20 runs
Summary
./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I ran
1.04 ± 0.03 times faster than ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
```
I suspect that the performance improvement should even be more
significant for users that otherwise don't have any diagnostics.
```
hyperfine --warmup 10 --runs 20 --setup "cd ../ecosystem/airflow && ../../ruff/target/release/ruff clean" \
"./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I" \
"./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 53.7 ms ± 1.8 ms [User: 68.4 ms, System: 63.0 ms]
Range (min … max): 51.1 ms … 58.7 ms 20 runs
Benchmark 2: ./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 50.8 ms ± 1.4 ms [User: 50.7 ms, System: 60.9 ms]
Range (min … max): 48.5 ms … 55.3 ms 20 runs
Summary
./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I ran
1.06 ± 0.05 times faster than ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
```
## Test Plan
`cargo test`
## Summary
Fixes#11185Fixes#11214
Document path and package information is now forwarded to the Ruff
linter, which allows `per-file-ignores` to correctly match against the
file name. This also fixes an issue where the import sorting rule didn't
distinguish between third-party and first-party packages since we didn't
pass in the package root.
## Test Plan
`per-file-ignores` should ignore files as expected. One quick way to
check is by adding this to your `pyproject.toml`:
```toml
[tool.ruff.lint.per-file-ignores]
"__init__.py" = ["ALL"]
```
Then, confirm that no diagnostics appear when you add code to an
`__init__.py` file (besides syntax errors).
The import sorting fix can be verified by failing to reproduce the
original issue - an `I001` diagnostic should not appear in
`other_module.py`.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11158.
A settings file in the ruff user configuration directory will be used as
a configuration fallback, if it exists.
## Test Plan
Create a `pyproject.toml` or `ruff.toml` configuration file in the ruff
user configuration directory.
* On Linux, that will be `$XDG_CONFIG_HOME/ruff/` or `$HOME/.config`
* On macOS, that will be `$HOME/Library/Application Support`
* On Windows, that will be `{FOLDERID_LocalAppData}`
Then, open a file inside of a workspace with no configuration. The
settings in the user configuration file should be used.
## Summary
I think the check included here does make sense, but I don't see why we
would allow it if a value is provided for the attribute -- since, in
that case, isn't it _not_ abstract?
Closes: https://github.com/astral-sh/ruff/issues/11208.
## Summary
This PR changes the `DebugStatistics` and `ReleaseStatistics` structs so
that they implement a common `StatisticsRecorder` trait, and makes the
`KeyValueCache` struct generic over a type parameter bound to that
trait. The advantage of this approach is that it's much harder for the
`DebugStatistics` and `ReleaseStatistics` structs to accidentally grow
out of sync in the methods that they implement, which was the cause of
the release-build failure recently fixed in #11177.
## Test Plan
`cargo test -p red_knot` and `cargo build --release` both continue to
pass for me locally
* Adds `Symbol.flag` bitfield. Populates it from (the three renamed)
`add_or_update_symbol*` methods.
* Currently there are these flags supported:
* `IS_DEFINED` is set in a scope where a variable is defined.
* `IS_USED` is set in a scope where a variable is referenced. (To have
both this and `IS_DEFINED` would require two separate appearances of a
variable in the same scope-- one def and one use.)
* `MARKED_GLOBAL` and `MARKED_NONLOCAL` are **not yet implemented**.
(*TODO: While traversing, if you find these declarations, add these
flags to the variable.*)
* Adds `Symbol.kind` field (commented) and the data structure which will
populate it: `Kind` which is an enum of freevar, cellvar,
implicit_global, and implicit_local. **Not yet populated**. (*TODO: a
second pass over the scope (or the ast?) will observe the
`MARKED_GLOBAL` and `MARKED_NONLOCAL` flags to populate this field. When
that's added, we'll uncomment the field.*)
* Adds a few tests that the `IS_DEFINED` and `IS_USED` fields are
correctly set and/or merged:
* Unit test that subsequent calls to `add_or_update_symbol` will merge
the flag arguments.
* Unit test that in the statement `x = foo`, the variable `foo` is
considered used but not defined.
* Unit test that in the statement `from bar import foo`, the variable
`foo` is considered defined but not used.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR adds a basic README for the `ruff_python_parser` crate and
updates the CONTRIBUTING docs with the fuzzer and benchmark section.
Additionally, it also updates some inline documentation within the
parser crate and splits the `parse_program` function into
`parse_single_expression` and `parse_module` which will be called by
matching against the `Mode`.
This PR doesn't go into too much internal detail around the parser logic
due to the following reasons:
1. Where should the docs go? Should it be as a module docs in `lib.rs`
or in README?
2. The parser is still evolving and could include a lot of refactors
with the future work (feedback loop and improved error recovery and
resilience)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
`cargo build --release` currently fails to compile on `main`:
<details>
```
error[E0599]: no method named `hit` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:22:29
|
22 | self.statistics.hit();
| ^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `hit` not found for this struct
error[E0599]: no method named `miss` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:25:29
|
25 | self.statistics.miss();
| ^^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `miss` not found for this struct
error[E0599]: no method named `hit` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:36:33
|
36 | self.statistics.hit();
| ^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `hit` not found for this struct
error[E0599]: no method named `miss` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:41:33
|
41 | self.statistics.miss();
| ^^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `miss` not found for this struct
```
</details>
This is because in a release build, `CacheStatistics` is a type alias
for `ReleaseStatistics`, and `ReleaseStatistics` doesn't have `hit()` or
`miss()` methods. (In a debug build, `CacheStatistics` is a type alias
for `DebugStatistics`, which _does_ have those methods.)
Possibly we could make this less likely to happen in the future by
making both structs implement a common trait instead of using type
aliases that vary depending on whether it's a debug build or not? For
now, though, this PR just brings the two structs in sync w.r.t. the
methods they expose.
## Test Plan
`cargo build --release` now once again compiles for me locally
## Summary
This PR adds an override to the fixer to ensure that we apply any
`redefined-while-unused` fixes prior to `unused-import`.
Closes https://github.com/astral-sh/ruff/issues/10905.
## Summary
Implement duplicate code detection as part of `RUF100`, mirroring the
behavior of `flake8-noqa` (`NQA005`) mentioned in #850. The idea to
merge the rule into `RUF100` was suggested by @MichaReiser
https://github.com/astral-sh/ruff/pull/10325#issuecomment-2025535444.
## Test Plan
Test cases were added to the fixture.
This syntax wasn't "deprecated" in Python 3; it was removed.
I started looking at this rule because I was curious how Ruff could even
detect this without a Python 2 parser. Then I realized that
"print >> f, x" is actually valid Python 3 syntax: it creates a tuple
containing a right-shifted version of the print function.
## Summary
Based on discussion in #10850.
As it stands today `RUF100` will attempt to replace code redirects with
their target codes even though this is not the "goal" of `RUF100`. This
behavior is confusing and inconsistent, since code redirects which don't
otherwise violate `RUF100` will not be updated. The behavior is also
undocumented. Additionally, users who want to use `RUF100` but do not
want to update redirects have no way to opt out.
This PR explicitly detects redirects with a new rule `RUF101` and
patches `RUF100` to keep original codes in fixes and reporting.
## Test Plan
Added fixture.
## Summary
Closes#10985.
The server now supports a custom TOML configuration file as a client
setting. The setting must be an absolute path to a file. If the file is
called `pyproject.toml`, the server will attempt to parse it as a
pyproject file - otherwise, it will attempt to parse it as a `ruff.toml`
file, even if the file has a name besides `ruff.toml`.
If an option is set in both the custom TOML configuration file and in
the client settings directly, the latter will be used.
## Test Plan
1. Create a `ruff.toml` file outside of the workspace you are testing.
Set an option that is different from the one in the configuration for
your test workspace.
2. Set the path to the configuration in NeoVim:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
configuration = "absolute/path/to/your/configuration"
}
}
}
```
3. Confirm that the option in the configuration file is used, regardless
of what the option is set to in the workspace configuration.
4. Add the same option, with a different value, to the NeoVim
configuration directly. For example:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
configuration = "absolute/path/to/your/configuration",
lint = {
select = []
}
}
}
}
```
5. Confirm that the option set in client settings is used, regardless of
the value in either the custom configuration file or in the workspace
configuration.
## Summary
This PR fixes the bug where the formatter would format an f-string and
could potentially change the AST.
For a triple-quoted f-string, the element can't be formatted into
multiline if it has a format specifier because otherwise the newline
would be treated as part of the format specifier.
Given the following f-string:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f} ddddddddddddddd eeeeeeee"""
```
The formatter sees that the f-string is already multiline so it assumes
that it can contain line breaks i.e., broken into multiple lines. But,
in this specific case we can't format it as:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f
} ddddddddddddddd eeeeeeee"""
```
Because the format specifier string would become ".3f\n", which is not
the original string (`.3f`).
If the original source code already contained a newline, they'll be
preserved. For example:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f
} ddddddddddddddd eeeeeeee"""
```
The above will be formatted as:
```py
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {variable:.3f
} ddddddddddddddd eeeeeeee"""
```
Note that the newline after `.3f` is part of the format specifier which
needs to be preserved.
The Python version is irrelevant in this case.
fixes: #10040
## Test Plan
Add some test cases to verify this behavior.
## Summary
This is intended to address
https://github.com/astral-sh/ruff-vscode/issues/425, and is a follow-up
to https://github.com/astral-sh/ruff/pull/11062.
A new client setting is now supported by the server,
`prioritizeFileConfiguration`. This is a boolean setting (default:
`false`) that, if set to `true`, will instruct the configuration
resolver to prioritize file configuration (aka discovered TOML files)
over configuration passed in by the editor.
A corresponding extension PR has been opened, which makes this setting
available for VS Code:
https://github.com/astral-sh/ruff-vscode/pull/457.
## Test Plan
To test this with VS Code, you'll need to check out [the VS Code
PR](https://github.com/astral-sh/ruff-vscode/pull/457) that adds this
setting.
The test process is similar to
https://github.com/astral-sh/ruff/pull/11062, but in scenarios where the
editor configuration would take priority over file configuration, file
configuration should take priority.
## Summary
Resolves#11102
The error stems from these lines
f5c7a62aa6/crates/ruff_linter/src/noqa.rs (L697-L702)
I don't really understand the purpose of incrementing the last index,
but it makes the resulting range invalid for indexing into `contents`.
For now I just detect if the index is too high in `blanket_noqa` and
adjust it if necessary.
## Test Plan
Created fixture from issue example.
## Summary
This PR updates the playground to display the AST even if it contains a
syntax error. This could be useful for development and also to give a
quick preview of what error recovery looks like.
Note that not all recovery is correct but this allows us to iterate
quickly on what can be improved.
## Test Plan
Build the playground locally and test it.
<img width="1688" alt="Screenshot 2024-04-25 at 21 02 22"
src="https://github.com/astral-sh/ruff/assets/67177269/2b94934c-4f2c-4a9a-9693-3d8460ed9d0b">
## Summary
Fixes#11114.
As part of the `onClose` handler, we publish an empty array of
diagnostics for the document being closed, similar to
[`ruff-lsp`](187d7790be/ruff_lsp/server.py (L459-L464)).
This prevent phantom diagnostics from lingering after a document is
closed. We'll only do this if the client doesn't support pull
diagnostics, because otherwise clearing diagnostics is their
responsibility.
## Test Plan
Diagnostics should no longer appear for a document in the Problems tab
after the document is closed.
## Summary
This allows `raise from` in BLE001.
```python
try:
...
except Exception as e:
raise ValueError from e
```
Fixes#10806
## Test Plan
Test case added.
## Summary
Continuation of https://github.com/astral-sh/ruff/pull/9444.
> When the formatter is fully cached, it turns out we actually spend
meaningful time mapping from file to `Settings` (since we use a
hierarchical approach to settings). Using `matchit` rather than
`BTreeMap` improves fully-cached performance by anywhere from 2-5%
depending on the project, and since these are all implementation details
of `Resolver`, it's minimally invasive.
`matchit` supports escaping routing characters so this change should now
be fully compatible.
## Test Plan
On my machine I'm seeing a ~3% improvement with this change.
```
hyperfine --warmup 20 -i "./target/release/main format ../airflow" "./target/release/ruff format ../airflow"
Benchmark 1: ./target/release/main format ../airflow
Time (mean ± σ): 58.1 ms ± 1.4 ms [User: 63.1 ms, System: 66.5 ms]
Range (min … max): 56.1 ms … 62.9 ms 49 runs
Benchmark 2: ./target/release/ruff format ../airflow
Time (mean ± σ): 56.6 ms ± 1.5 ms [User: 57.8 ms, System: 67.7 ms]
Range (min … max): 54.1 ms … 63.0 ms 51 runs
Summary
./target/release/ruff format ../airflow ran
1.03 ± 0.04 times faster than ./target/release/main format ../airflow
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Add support for hover menu to ruff_server, as requested in
[10595](https://github.com/astral-sh/ruff/issues/10595).
Majority of new code is in hover.rs.
I reused the regex from ruff-lsp's implementation. Also reused the
format_rule_text function from ruff/src/commands/rule.rs
Added capability registration in server.rs, and added the handler to
api.rs.
## Test Plan
Tested in NVIM v0.10.0-dev-2582+g2a8cef6bd, configured with lspconfig
using the default options (other than cmd pointing to my test build,
with options "server" and "--preview"). OS: Ubuntu 24.04, kernel
6.8.0-22.
---------
Co-authored-by: Jane Lewis <me@jane.engineering>
## Summary
This is a follow-up to https://github.com/astral-sh/ruff/pull/10984 that
implements configuration resolution for editor configuration. By 'editor
configuration', I'm referring to the client settings that correspond to
Ruff configuration/options, like `preview`, `select`, and so on. These
will be combined with 'project configuration' (configuration taken from
project files such as `pyproject.toml`) to generate the final linter and
formatter settings used by `RuffSettings`. Editor configuration takes
priority over project configuration.
In a follow-up pull request, I'll implement a new client setting that
allows project configuration to override editor configuration, as per
[this issue](https://github.com/astral-sh/ruff-vscode/issues/425).
## Review guide
The first commit, e38966d8843becc7234fa7d46009c16af4ba41e9, is just
doing re-arrangement so that we can pass the right things to
`RuffSettings::resolve`. The actual resolution logic is in the second
commit, 0eec9ee75c10e5ec423bd9f5ce1764f4d7a5ad86. It might help to look
at these comments individually since the diff is rather messy.
## Test Plan
For the settings to show up in VS Code, you'll need to checkout this
branch: https://github.com/astral-sh/ruff-vscode/pull/456.
To test that the resolution for a specific setting works as expected,
run through the following scenarios, setting it in project and editor
configuration as needed:
| Set in project configuration? | Set in editor configuration? |
Expected Outcome |
|-------------------------------|--------------------------------------------------|------------------------------------------------------------------------------------------|
| No | No | The editor should behave as if the setting was set to its
default value. |
| Yes | No | The editor should behave as if the setting was set to the
value in project configuration. |
| No | Yes | The editor should behave as if the setting was set to the
value in editor configuration. |
| Yes | Yes (but distinctive from project configuration) | The editor
should behave as if the setting was set to the value in editor
configuration. |
An exception to this is `extendSelect`, which does not have an analog in
TOML configuration. Instead, you should verify that `extendSelect`
amends the `select` setting. If `select` is set in both editor and
project configuration, `extendSelect` will only append to the `select`
value in editor configuration, so make sure to un-set it there if you're
testing `extendSelect` with `select` in project configuration.
## Summary
This PR refactors unary expression parsing with the following changes:
* Ability to get `OperatorPrecedence` from a unary operator (`UnaryOp`)
* Implement methods on `TokenKind`
* Add `as_unary_operator` which returns an `Option<UnaryOp>`
* Add `as_unary_arithmetic_operator` which returns an `Option<UnaryOp>`
(used for pattern parsing)
* Rename `is_unary` to `is_unary_arithmetic_operator` (used in the
linter)
resolves: #10752
## Test Plan
Verify that the existing test cases pass, no ecosystem changes, run the
Python based fuzzer on 3000 random inputs and run it on dozens of
open-source repositories.
## Summary
This PR refactors the binary expression parsing in a way to make it
readable and easy to understand. It draws inspiration from the suggested
edits in the linked messages in #10752.
### Changes
* Ability to get the precedence of an operator
* From a boolean operator (`BinOp`) to `OperatorPrecedence`
* From a binary operator (`Operator`) to `OperatorPrecedence`
* No comparison operator because all of them have the same precedence
* Implement methods on `TokenKind` to convert it to an appropriate
operator enum
* Add `as_boolean_operator` which returns an `Option<BoolOp>`
* Add `as_binary_operator` which returns an `Option<Operator>`
* No `as_comparison_operator` because it requires lookahead and I'm not
sure if `token.as_comparison_operator(peek)` is a good way to implement
it
* Introduce `BinaryLikeOperator`
* Constructed from two tokens using the methods from the second point
* Add `precedence` method using the conversion methods mentioned in the
first point
* Make most of the functions in `TokenKind` private to the module
* Use `self` instead of `&self` for `TokenKind`
fixes: #11072
## Test Plan
Refer #11088
## Summary
This PR does a few things but the main change is that is makes
associativity a property of operator precedence.
1. Rename `Precedence` -> `OperatorPrecedence`
2. Rename `parse_expression_with_precedence` ->
`parse_binary_expression_or_higher`
3. Move `current_binding_power` to `OperatorPrecedence::try_from_tokens`
[^1]
4. Add a `OperatorPrecedence::is_right_associative` method
5. Move from `increment_precedence` to using `<=` / `<` to check if the
parsing loop needs to stop [^2]
[^1]: Another alternative would be to have two separate methods to avoid
lookahead as it's required only for once case (`not in`). So,
`try_from_current_token(current).or_else(|| try_from_next_token(current,
peek))`
[^2]: This will allow us to easily make the refactors mentioned in
#10752
## Test Plan
Make sure the precedence parsing algorithm is still correct by running
the test suite, fuzz testing it and running it against a dozen or so
open-source repositories.
## Summary
This PR adds a new `ExpressionContext` struct which is used in
expression parsing.
This solves the following problem:
1. Allowing starred expression with different precedence
2. Allowing yield expression in certain context
3. Remove ambiguity with `in` keyword when parsing a `for ... in`
statement
For context, (1) was solved by adding `parse_star_expression_list` and
`parse_star_expression_or_higher` in #10623, (2) was solved by by adding
`parse_yield_expression_or_else` in #10809, and (3) was fixed in #11009.
All of the mentioned functions have been removed in favor of the context
flags.
As mentioned in #11009, an ideal solution would be to implement an
expression context which is what this PR implements. This is passed
around as function parameter and the call stack is used to automatically
reset the context.
### Recovery
How should the parser recover if the target expression is invalid when
an expression can consume the `in` keyword?
1. Should the `in` keyword be part of the target expression?
2. Or, should the expression parsing stop as soon as `in` keyword is
encountered, no matter the expression?
For example:
```python
for yield x in y: ...
# Here, should this be parsed as
for (yield x) in (y): ...
# Or
for (yield x in y): ...
# where the `in iter` part is missing
```
Or, for binary expression parsing:
```python
for x or y in z: ...
# Should this be parsed as
for (x or y) in z: ...
# Or
for (x or y in z): ...
# where the `in iter` part is missing
```
This need not be solved now, but is very easy to change. For context
this PR does the following:
* For binary, comparison, and unary expressions, stop at `in`
* For lambda, yield expressions, consume the `in`
## Test Plan
1. Add test cases for the `for ... in` statement and verify the
snapshots
2. Make sure the existing test suite pass
3. Run the fuzzer for around 3000 generated source code
4. Run the updated logic on a dozen or so open source repositories
(codename "parser-checkouts")
## Summary
Fixes#11059
Several major editors don't support [pull
diagnostics](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#textDocument_pullDiagnostics),
a method of sending diagnostics to the client that was introduced in
version `0.3.17` of the specification. Until now, `ruff server` has only
used pull diagnostics, which resulted in diagnostics not being available
on Neovim and Helix, which don't support pull diagnostics yet (though
Neovim `10.0` will have support for this).
`ruff server` will now utilize the older method of sending diagnostics,
known as 'publish diagnostics', when pull diagnostics aren't supported
by the client. This involves re-linting a document every time it is
opened or modified, and then sending the diagnostics generated from that
lint to the client via the `textDocument/publishDiagnostics`
notification.
## Test Plan
The easiest way to test that this PR works is to check if diagnostics
show up on Neovim `<=0.9`.
## Summary
Fixes#10463
Add `FURB192` which detects violations like this:
```python
# Bad
a = sorted(l)[0]
# Good
a = min(l)
```
There is a caveat that @Skylion007 has pointed out, which is that
violations with `reverse=True` technically aren't compatible with this
change, in the edge case where the unstable behavior is intended. For
example:
```python
from operator import itemgetter
data = [('red', 1), ('blue', 1), ('red', 2), ('blue', 2)]
min(data, key=itemgetter(0)) # ('blue', 1)
sorted(data, key=itemgetter(0))[0] # ('blue', 1)
sorted(data, key=itemgetter(0), reverse=True)[-1] # ('blue, 2')
```
This seems like a rare edge case, but I can make the `reverse=True`
fixes unsafe if that's best.
## Test Plan
This is unit tested.
## References
https://github.com/dosisod/refurb/pull/333/files
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
The `operator.itemgetter` behavior changes where there's more than one
argument, such that `operator.itemgetter(0)` yields `r[0]`, rather than
`(r[0],)`.
Closes https://github.com/astral-sh/ruff/issues/11075.
## Summary
There is no class `integer` in python, nor is there a type `integer`, so
I updated the docs to remove the backticks on these references, such
that it is the representation of an integer, and not a reference.
## Summary
Move `blanket-noqa` rule from the token checker to the noqa checker.
This allows us to make use of the line directives already computed in
the noqa checker.
## Test Plan
Verified test results are unchanged.
Resolves#10187
<details>
<summary>Old PR description; accurate through commit e86dd7d; probably
best to leave this fold closed</summary>
## Description of change
In the case of a printf-style format string with only one %-placeholder
and a variable at right (e.g. `"%s" % var`):
* The new behavior attempts to dereference the variable and then match
on the bound expression to distinguish between a 1-tuple (fix), n-tuple
(bug 🐛), or a non-tuple (fix). Dereferencing is via
`analyze::typing::find_binding_value`.
* If the variable cannot be dereferenced, then the type-analysis routine
is called to distinguish only tuple (no-fix) or non-tuple (fix). Type
analysis is via `analyze::typing::is_tuple`.
* If any of the above fails, the rule still fires, but no fix is
offered.
## Alternatives
* If the reviewers think that singling out the 1-tuple case is too
complicated, I will remove that.
* The ecosystem results show that no new fixes are detected. So I could
probably delete all the variable dereferencing code and code that tries
to generate fixes, tbh.
## Changes to existing behavior
**All the previous rule-firings and fixes are unchanged except for** the
"false negatives" in
`crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_1.py`. Those
previous "false negatives" are now true positives and so I moved them to
`crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py`.
<details>
<summary>Existing false negatives that are now true positives</summary>
```
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:134:1: UP031 Use format specifiers instead of percent format
|
133 | # UP031 (no longer false negatives)
134 | 'Hello %s' % bar
| ^^^^^^^^^^^^^^^^ UP031
135 |
136 | 'Hello %s' % bar.baz
|
= help: Replace with format specifiers
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:136:1: UP031 Use format specifiers instead of percent format
|
134 | 'Hello %s' % bar
135 |
136 | 'Hello %s' % bar.baz
| ^^^^^^^^^^^^^^^^^^^^ UP031
137 |
138 | 'Hello %s' % bar['bop']
|
= help: Replace with format specifiers
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:138:1: UP031 Use format specifiers instead of percent format
|
136 | 'Hello %s' % bar.baz
137 |
138 | 'Hello %s' % bar['bop']
| ^^^^^^^^^^^^^^^^^^^^^^^ UP031
|
= help: Replace with format specifiers
```
One of them newly offers a fix.
```
# UP031 (no longer false negatives)
-'Hello %s' % bar
+'Hello {}'.format(bar)
```
This fix occurs because the new code dereferences `bar` to where it was
defined earlier in the file as a non-tuple:
```python
bar = {"bar": y}
```
---
</details>
## Behavior requiring new tests
Additionally, we now handle a few cases that we didn't previously test.
These cases are when a string has a single %-placeholder and the
righthand operand to the modulo operator is a variable **which can be
dereferenced.** One of those was shown in the previous section (the
"dereference non-tuple" case).
<details>
<summary>New cases handled</summary>
```
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:126:1: UP031 [*] Use format specifiers instead of percent format
|
125 | t1 = (x,)
126 | "%s" % t1
| ^^^^^^^^^ UP031
127 | # UP031: deref t1 to 1-tuple, offer fix
|
= help: Replace with format specifiers
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:130:1: UP031 Use format specifiers instead of percent format
|
129 | t2 = (x,y)
130 | "%s" % t2
| ^^^^^^^^^ UP031
131 | # UP031: deref t2 to n-tuple, this is a bug
|
= help: Replace with format specifiers
```
One of these offers a fix.
```
t1 = (x,)
-"%s" % t1
+"{}".format(t1[0])
# UP031: deref t1 to 1-tuple, offer fix
```
The other doesn't offer a fix because it's a bug.
---
</details>
---
</details>
## Changes to existing behavior
In the case of a string with a single %-placeholder and a single
ambiguous righthand argument to the modulo operator, (e.g. `"%s" % var`)
the rule now fires and offers a fix. We explain about this in the "fix
safety" section of the updated documentation.
## Documentation changes
I swapped the order of the "known problems" and the "examples" sections
so that the examples which describe the rule are first, before the
exceptions to the rule are described. I also tweaked the language to be
more explicit, as I had trouble understanding the documentation at
first. The "known problems" section is now "fix safety" but the content
is largely similar.
The diff of the documentation changes looks a little difficult unless
you look at the individual commits.
## Summary
I happened to notice that we box `TypeParams` on `StmtClassDef` but not
on `StmtFunctionDef` and wondered why, since `StmtFunctionDef` is bigger
and sets the size of `Stmt`.
@charliermarsh found that at the time we started boxing type params on
classes, classes were the largest statement type (see #6275), but that's
no longer true.
So boxing type-params also on functions reduces the overall size of
`Stmt`.
## Test Plan
The `<=` size tests are a bit irritating (since their failure doesn't
tell you the actual size), but I manually confirmed that the size is
actually 120 now.
Occasionally you intentionally have iterables of differing lengths. The
rule permits this by explicitly adding `strict=False`, but this was not
documented.
## Summary
The rule does not currently document how to avoid it when having
differing length iterables is intentional. This PR adds that to the rule
documentation.
## Summary
This fixes a bug where the parser would panic when there is a "gap" in
the token source.
What's a gap?
The reason it's `<=` instead of just `==` is because there could be
whitespaces between
the two tokens. For example:
```python
# last token end
# | current token (newline) start
# v v
def foo \n
# ^
# assume there's trailing whitespace here
```
Or, there could tokens that are considered "trivia" and thus aren't
emitted by the token
source. These are comments and non-logical newlines. For example:
```python
# last token end
# v
def foo # comment\n
# ^ current token (newline) start
```
In either of the above cases, there's a "gap" between the end of the
last token and start
of the current token.
## Test Plan
Add test cases and update the snapshots.
## Summary
This PR adds a new `Clause::Case` and uses it to parse the body of a
`case` block. Earlier, it was using `Match` which would give an
incorrect error message like:
```
|
1 | match subject:
2 | case 1:
3 | case 2: ...
| ^^^^ Syntax Error: Expected an indented block after `match` statement
|
```
## Test Plan
Add test case and update the snapshot.
Add pylint rule invalid-hash-returned (PLE0309)
See https://github.com/astral-sh/ruff/issues/970 for rules
Test Plan: `cargo test`
TBD: from the description: "Strictly speaking `bool` is a subclass of
`int`, thus returning `True`/`False` is valid. To be consistent with
other rules (e.g.
[PLE0305](https://github.com/astral-sh/ruff/pull/10962)
invalid-index-returned), ruff will raise, compared to pylint which will
not raise."
## Summary
This PR fixes the bug in with items parsing where it would fail to
recognize that the parenthesized expression is part of a large binary
expression.
## Test Plan
Add test cases and verified the snapshots.
## Summary
This PR fixes the bug in parenthesized with items parsing where the `if`
expression would result into a syntax error.
The reason being that once we identify that the ambiguous left
parenthesis belongs to the context expression, the parser converts the
parsed with item into an equivalent expression. Then, the parser
continuous to parse any postfix expressions. Now, attribute, subscript,
and call are taken into account as they're grouped in
`parse_postfix_expression` but `if` expression has it's own parsing
function.
Use `parse_if_expression` once all postfix expressions have been parsed.
Ideally, I think that `if` could be included in postfix expression
parsing as they can be chained as well (`x if True else y if True else
z`).
## Test Plan
Add test cases and verified the snapshots.
## Summary
This PR fixes a bug in the new parser which involves the parser context
w.r.t. for statement. This is specifically around the `in` keyword which
can be present in the target expression and shouldn't be considered to
be part of the `for` statement header. Ideally it should use a context
which is passed between functions, thus using a call stack to set /
unset a specific variant which will be done in a follow-up PR as it
requires some amount of refactor.
## Test Plan
Add test cases and update the snapshots.
(Supersedes #9152, authored by @LaBatata101)
## Summary
This PR replaces the current parser generated from LALRPOP to a
hand-written recursive descent parser.
It also updates the grammar for [PEP
646](https://peps.python.org/pep-0646/) so that the parser outputs the
correct AST. For example, in `data[*x]`, the index expression is now a
tuple with a single starred expression instead of just a starred
expression.
Beyond the performance improvements, the parser is also error resilient
and can provide better error messages. The behavior as seen by any
downstream tools isn't changed. That is, the linter and formatter can
still assume that the parser will _stop_ at the first syntax error. This
will be updated in the following months.
For more details about the change here, refer to the PR corresponding to
the individual commits and the release blog post.
## Test Plan
Write _lots_ and _lots_ of tests for both valid and invalid syntax and
verify the output.
## Acknowledgements
- @MichaReiser for reviewing 100+ parser PRs and continuously providing
guidance throughout the project
- @LaBatata101 for initiating the transition to a hand-written parser in
#9152
- @addisoncrump for implementing the fuzzer which helped
[catch](https://github.com/astral-sh/ruff/pull/10903)
[a](https://github.com/astral-sh/ruff/pull/10910)
[lot](https://github.com/astral-sh/ruff/pull/10966)
[of](https://github.com/astral-sh/ruff/pull/10896)
[bugs](https://github.com/astral-sh/ruff/pull/10877)
---------
Co-authored-by: Victor Hugo Gomes <labatata101@linuxmail.org>
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
The following client settings have been introduced to the language
server:
* `lint.preview`
* `format.preview`
* `lint.select`
* `lint.extendSelect`
* `lint.ignore`
* `exclude`
* `lineLength`
`exclude` and `lineLength` apply to both the linter and formatter.
This does not actually use the settings yet, but makes them available
for future use.
## Test Plan
Snapshot tests have been updated.
## Summary
A setup guide has been written for NeoVim under a new
`crates/ruff_server/docs/setup` folder, where future setup guides will
also go. This setup guide was adapted from the [`ruff-lsp`
guide](https://github.com/astral-sh/ruff-lsp?tab=readme-ov-file#example-neovim).
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Add pylint rule invalid-length-returned (PLE0303)
See https://github.com/astral-sh/ruff/issues/970 for rules
Test Plan: `cargo test`
TBD: from the description: "Strictly speaking `bool` is a subclass of
`int`, thus returning `True`/`False` is valid. To be consistent with
other rules (e.g.
[PLE0305](https://github.com/astral-sh/ruff/pull/10962)
invalid-index-returned), ruff will raise, compared to pylint which will
not raise."
## Summary
If the user is analyzing a script (i.e., we have no module path), it
seems reasonable to use the script name when trying to identify paths to
objects defined _within_ the script.
Closes https://github.com/astral-sh/ruff/issues/10960.
## Test Plan
Ran:
```shell
check --isolated --select=B008 \
--config 'lint.flake8-bugbear.extend-immutable-calls=["test.A"]' \
test.py
```
On:
```python
class A: pass
def f(a=A()):
pass
```
## Summary
The server now requests a [workspace diagnostic
refresh](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#diagnostic_refresh)
when a configuration file gets changed. This means that diagnostics for
all open files will be automatically re-requested by the client on a
config change.
## Test Plan
You can test this by opening several files in VS Code, setting `select`
in your file configuration to `[]`, and observing that the diagnostics
go away once the file is saved (besides any `Pylance` diagnostics).
Restore it to what it was before, and you should see the diagnostics
automatically return once a save happens.
## Summary
I've added support for configuring the `ruff check` output file via the
environment variable `RUFF_OUTPUT_FILE` akin to #1731.
This is super useful when, e.g., generating a [GitLab code quality
report](https://docs.gitlab.com/ee/ci/testing/code_quality.html#implement-a-custom-tool)
while running Ruff as a pre-commit hook. Usually, `ruff check` should
print its human-readable output to `stdout`, but when run through
`pre-commit` _in a GitLab CI job_ it should write its output in `gitlab`
format to a file. So, to override these two settings only during CI,
environment variables come handy, and `RUFF_OUTPUT_FORMAT` already
exists but `RUFF_OUTPUT_FILE` has been missing.
A (simplified) GitLab CI job config for this scenario might look like
this:
```yaml
pre-commit:
stage: test
image: python
variables:
RUFF_OUTPUT_FILE: gl-code-quality-report.json
RUFF_OUTPUT_FORMAT: gitlab
before_script:
- pip install pre-commit
script:
- pre-commit run --all-files --show-diff-on-failure
artifacts:
reports:
codequality: gl-code-quality-report.json
```
## Test Plan
I tested it manually.
## Summary
This PR switches more callsites of `SemanticModel::is_builtin` to move
over to the new methods I introduced in #10919, which are more concise
and more accurate. I missed these calls in the first PR.
## Summary
Fixes#10866.
Introduces the `show_err_msg!` macro which will send a message to be
shown as a popup to the client via the `window/showMessage` LSP method.
## Test Plan
Insert various `show_err_msg!` calls in common code paths (for example,
at the beginning of `event_loop`) and confirm that these messages appear
in your editor.
To test that panicking works correctly, add this to the top of the `fn
run` definition in
`crates/ruff_server/src/server/api/requests/execute_command.rs`:
```rust
panic!("This should appear");
```
Then, try running a command like `Ruff: Format document` from the
command palette (`Ctrl/Cmd+Shift+P`). You should see the following
messages appear:

## Summary
Fixes#10780.
The server now send code actions to the client with a Ruff-specific
kind, `source.*.ruff`. The kind filtering logic has also been reworked
to support this.
## Test Plan
Add this to your `settings.json` in VS Code:
```json
{
"[python]": {
"editor.codeActionsOnSave": {
"source.organizeImports.ruff": "explicit",
},
}
}
```
Imports should be automatically organized when you manually save with
`Ctrl/Cmd+S`.