## Summary
The problem: given a (row, column) number (e.g., for a token in the AST), we need to be able to map it to a precise byte index in the source code. A while ago, we moved to `ropey` for this, since it was faster in practice (mostly, I think, because it's able to defer indexing). However, at some threshold of accesses, it becomes faster to index the string in advance, as we're doing here.
## Benchmark
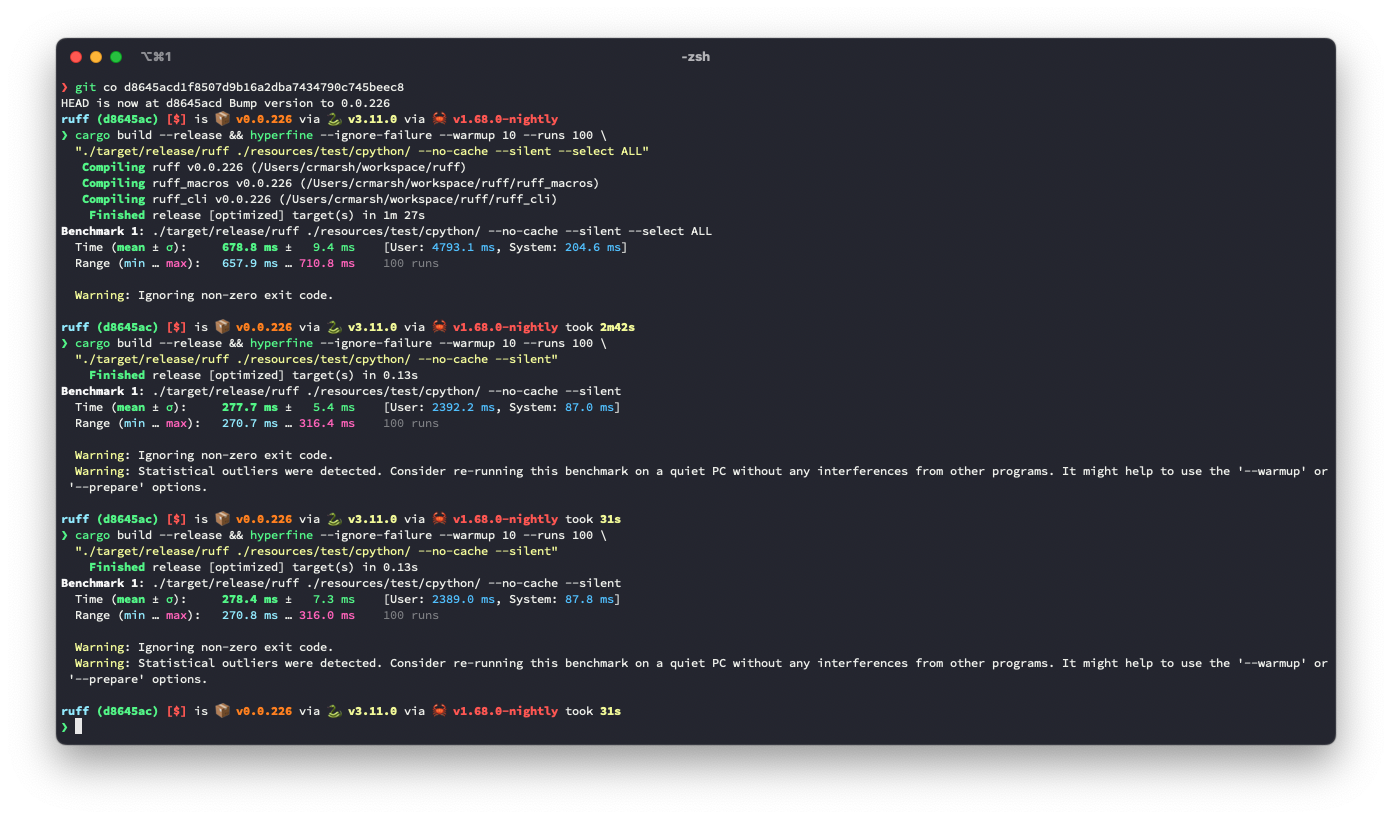
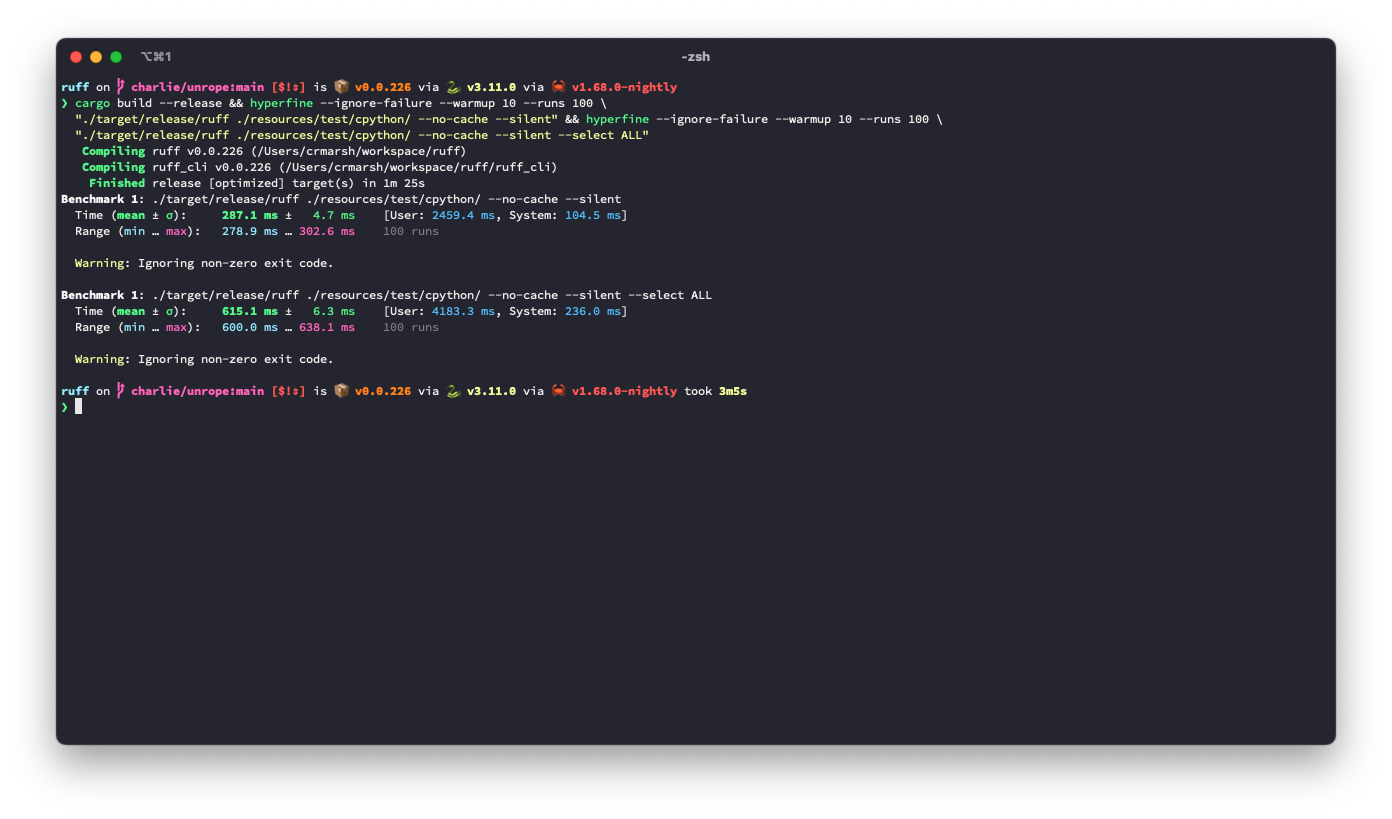
It looks like this is ~3.6% slower for the default rule set, but ~9.3% faster for `--select ALL`.
**I suspect there's a strategy that would be strictly faster in both cases**, based on deferring even more computation (right now, we lazily compute these offsets, but we do it for the entire file at once, even if we only need some slice at the top), or caching the `ropey` lookups in some way.
Before:
After:
## Alternatives
I tried tweaking the `Vec::with_capacity` hints, and even trying `Vec::with_capacity(str_indices::lines_crlf::count_breaks(contents))` to do a quick scan of the number of lines, but that turned out to be slower.
# This commit was automatically generated by running the following
# script (followed by `cargo +nightly fmt`):
import glob
import re
from typing import NamedTuple
class Rule(NamedTuple):
code: str
name: str
path: str
def rules() -> list[Rule]:
"""Returns all the rules defined in `src/registry.rs`."""
file = open('src/registry.rs')
rules = []
while next(file) != 'ruff_macros::define_rule_mapping!(\n':
continue
while (line := next(file)) != ');\n':
line = line.strip().rstrip(',')
if line.startswith('//'):
continue
code, path = line.split(' => ')
name = path.rsplit('::')[-1]
rules.append(Rule(code, name, path))
return rules
code2name = {r.code: r.name for r in rules()}
for pattern in ('src/**/*.rs', 'ruff_cli/**/*.rs', 'ruff_dev/**/*.rs', 'scripts/add_*.py'):
for name in glob.glob(pattern, recursive=True):
with open(name) as f:
text = f.read()
text = re.sub('Rule(?:Code)?::([A-Z]\w+)', lambda m: 'Rule::' + code2name[m.group(1)], text)
text = re.sub(r'(?<!"<FilePattern>:<)RuleCode\b', 'Rule', text)
text = re.sub('(use crate::registry::{.*, Rule), Rule(.*)', r'\1\2', text) # fix duplicate import
with open(name, 'w') as f:
f.write(text)
The Settings struct previously contained the fields:
pub enabled: HashableHashSet<RuleCode>,
pub fixable: HashableHashSet<RuleCode>,
This commit merges both fields into one by introducing a new
RuleTable type, wrapping HashableHashMap<RuleCode, bool>,
which has the following benefits:
1. It makes the invalid state that a rule is
disabled but fixable unrepresentable.
2. It encapsulates the implementation details of the table.
(It currently uses an FxHashMap but that may change.)
3. It results in more readable code.
settings.rules.enabled(rule)
settings.rules.should_fix(rule)
is more readable than:
settings.enabled.contains(rule)
settings.fixable.contains(rule)
{kind=link}
{kind=link}