From discussion on https://github.com/charliermarsh/ruff/pull/2123
I didn't originally have a helpers file so I put the function in both
places but now that a helpers file exists it seems logical for it to be
there.
Yet another refactor to let us implement the many-to-many mapping
between codes and rules in a prefix-agnostic way.
We want to break up the RuleCodePrefix[1] enum into smaller enums.
To facilitate that this commit introduces a new wrapping type around
RuleCodePrefix so that we can start breaking it apart.
[1]: Actually `RuleCodePrefix` is the previous name of the autogenerated
enum ... I renamed it in b19258a243 to
RuleSelector since `ALL` isn't a prefix. This commit now renames it back
but only because the new `RuleSelector` wrapper type, introduced in this
commit, will let us move the `ALL` variant from `RuleCodePrefix` to
`RuleSelector` in the next commit.
At present, `ISC001` and `ISC002` flag concatenations like the following:
```py
"a" "b" # ISC001
"a" \
"b" # ISC002
```
However, multiline concatenations are allowed.
This PR adds a setting:
```toml
[tool.ruff.flake8-implicit-str-concat]
allow-multiline = false
```
Which extends `ISC002` to _also_ flag multiline concatenations, like:
```py
(
"a" # ISC002
"b"
)
```
Note that this is backwards compatible, as `allow-multiline` defaults to `true`.
Extend test fixture to verify the targeting.
Includes two "attribute docstrings" which per PEP 257 are not recognized by the Python bytecode compiler or available as runtime object attributes. They are not available for us either at time of writing, but include them for completeness anyway in case they one day are.
If a file doesn't have a `package`, then it must both be in a directory that lacks an `__init__.py`, and a directory that _isn't_ marked as a namespace package.
Closes#2075.
## Summary
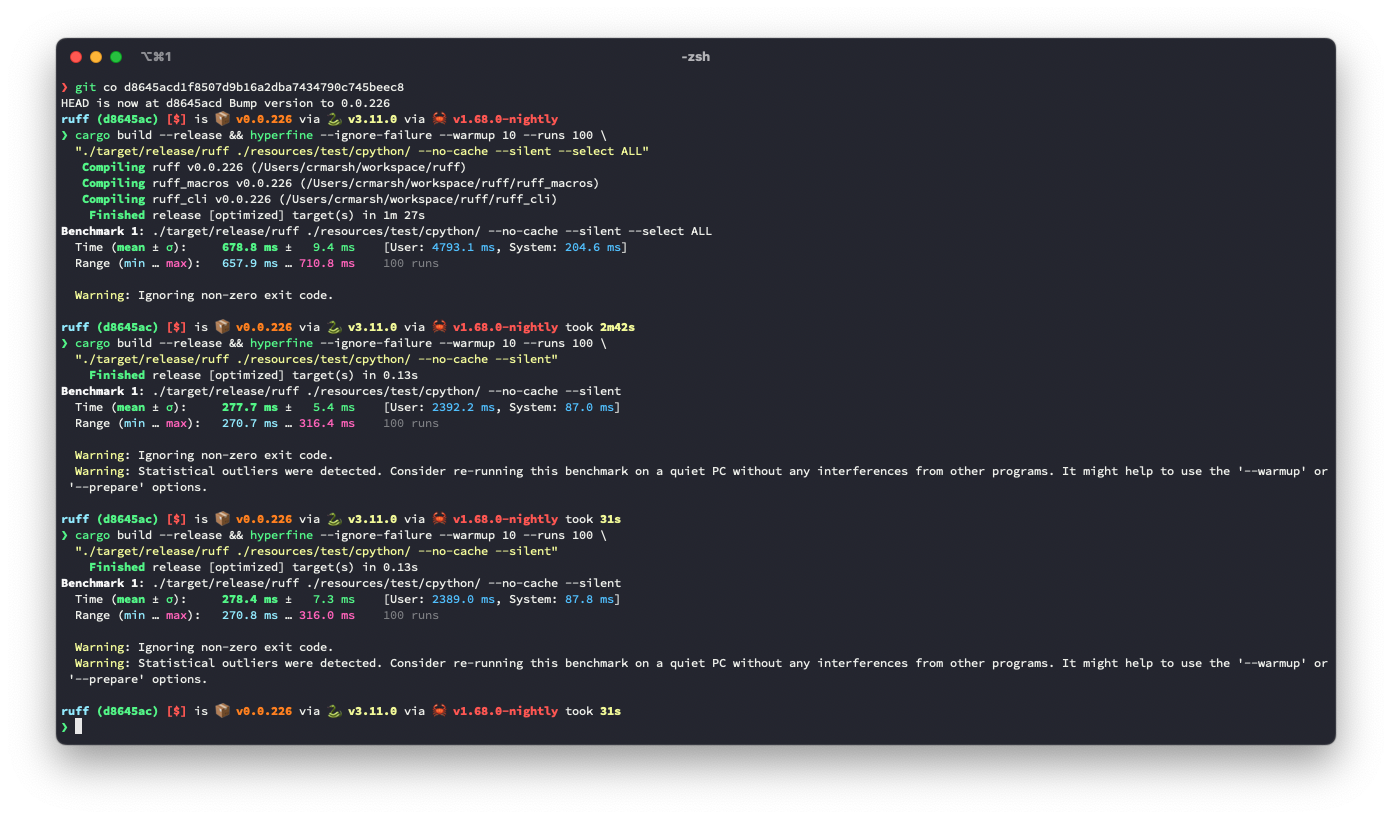
The problem: given a (row, column) number (e.g., for a token in the AST), we need to be able to map it to a precise byte index in the source code. A while ago, we moved to `ropey` for this, since it was faster in practice (mostly, I think, because it's able to defer indexing). However, at some threshold of accesses, it becomes faster to index the string in advance, as we're doing here.
## Benchmark
It looks like this is ~3.6% slower for the default rule set, but ~9.3% faster for `--select ALL`.
**I suspect there's a strategy that would be strictly faster in both cases**, based on deferring even more computation (right now, we lazily compute these offsets, but we do it for the entire file at once, even if we only need some slice at the top), or caching the `ropey` lookups in some way.
Before:
After:
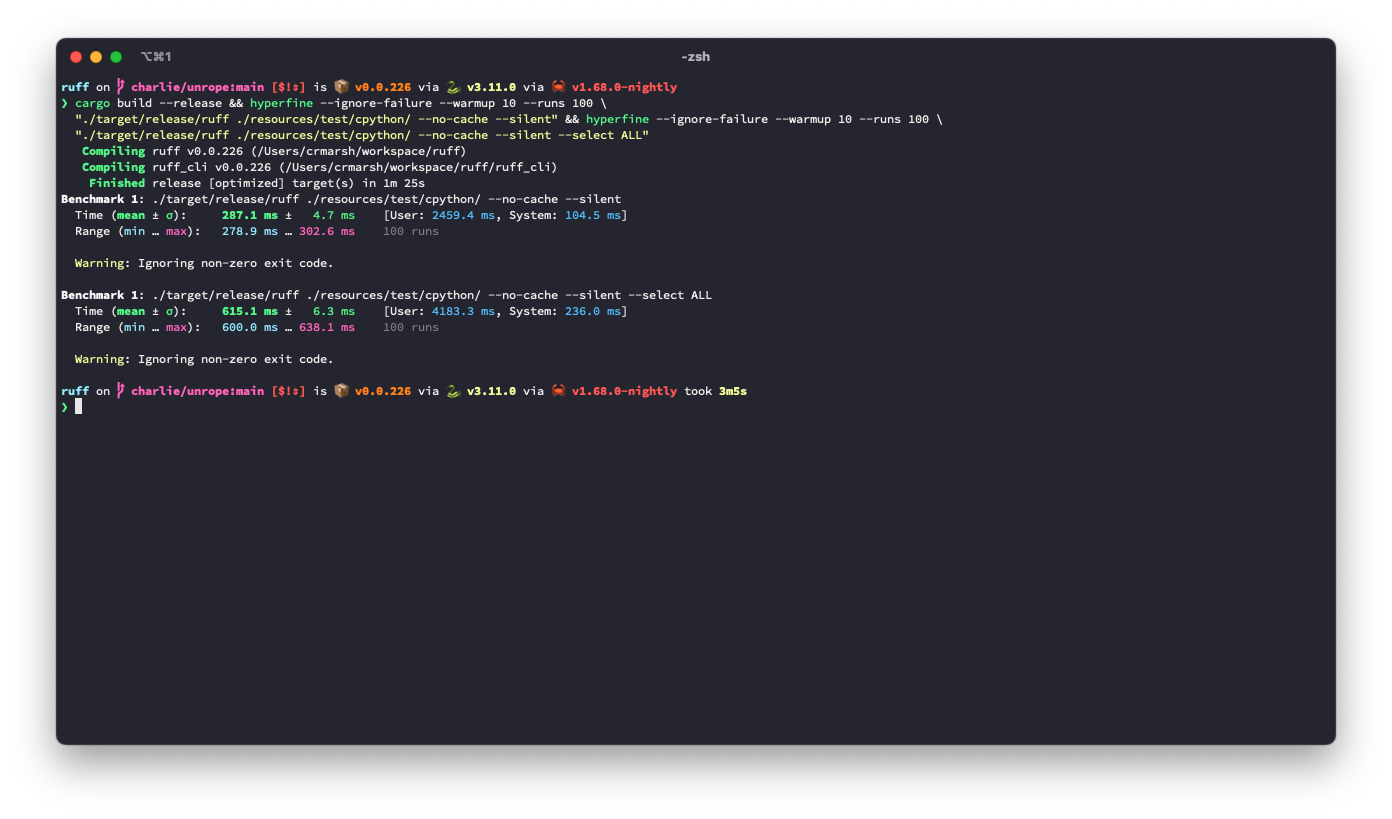
## Alternatives
I tried tweaking the `Vec::with_capacity` hints, and even trying `Vec::with_capacity(str_indices::lines_crlf::count_breaks(contents))` to do a quick scan of the number of lines, but that turned out to be slower.
Add tests.
Ensure that these cases are caught by ICN001:
```python
from xml.dom import minidom
from xml.dom.minidom import parseString
```
with config:
```toml
[tool.ruff.flake8-import-conventions.extend-aliases]
"dask.dataframe" = "dd"
"xml.dom.minidom" = "md"
"xml.dom.minidom.parseString" = "pstr"
```
{kind=link}
{kind=link}