## Summary
Implement support for RDJson output for `ruff check`, as requested in
#8655.
## Test Plan
Tested using a snapshot test. Same approach as for e.g. the JSON output
formatter.
## Additional info
I tried to keep the implementation close to the JSON implementation.
I had to deviate a bit to make the `suggestions` key work: If there are
no suggestions, then setting `suggestions` to `null` is invalid
according to the JSONSchema. Therefore, I opted for a slightly more
complex implementation, that skips the `suggestions` key entirely if
there are no fixes available for the given diagnostic. Maybe it would
have been easier to set `"suggestions": []`, but I ended up doing it
this way.
I didn't consider notebooks, as I _think_ that RDJson doesn't work with
notebooks. This should be confirmed, and if so, there should be some
form of warning or error emitted when trying to output diagnostics for a
notebook.
I also didn't consider `ruff format`, as this comment:
https://github.com/astral-sh/ruff/issues/8655#issuecomment-1811446160
suggests that that wouldn't be compatible.
I'm new to Rust, any feedback is appreciated. 🙂 I
implemented this in order to have a productive rainy saturday afternoon,
I'm not knowledgeable about RDJson beyond the sources linked in the
issue.
## Summary
This PR implements the rule B901, which is part of the opinionated rules
of `flake8-bugbear`.
This rule seems to be desired in `ruff` as per
https://github.com/astral-sh/ruff/issues/3758 and
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976.
## Test Plan
As this PR was made closely following the
[CONTRIBUTING.md](8a25531a71/CONTRIBUTING.md),
it tests using the snapshot approach, that is described there.
## Sources
The implementation is inspired by [the original implementation in the
`flake8-bugbear`
repository](d1aec4cbef/bugbear.py (L1092)).
The error message and [test
file](d1aec4cbef/tests/b901.py)
where also copied from there.
The documentation I came up with on my own and needs improvement. Maybe
the example given in
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976
could be used, but maybe they are too complex, I'm not sure.
## Open Questions
- [ ] Documentation. (See above.)
- [x] Can I access the parent in a visitor?
The [original
implementation](d1aec4cbef/bugbear.py (L1100))
references the `yield` statement's parent to check if it is an
expression statement. I didn't find a way to do this in `ruff` and used
the `is_expresssion_statement` field on the visitor instead. What are
your thoughts on this? Is it possible and / or desired to access the
parent node here?
- [x] Is `Option::is_some(...)` -> `...unwrap()` the right thing to do?
Referring to [this piece of
code](9d5a280f71/crates/ruff_linter/src/rules/flake8_bugbear/rules/return_x_in_generator.rs?plain=1#L91-L96).
From my understanding, the `.unwrap()` is safe, because it is checked
that `return_` is not `None`. However, I feel like I missed a more
elegant solution that does both in one.
## Other
I don't know a lot about this rule, I just implemented it because I
found it in a
https://github.com/astral-sh/ruff/labels/good%20first%20issue.
I'm new to Rust, so any constructive critisism is appreciated.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
- Implements `Y066` from `flake8-pyi` as `PYI066`
- Fixes `PYI006` not being raised for `elif` clauses. This would have
conflicted with PYI006's implementation, so decided to do it in the same
PR.
## Test Plan
`cargo test` / `cargo insta review`
## Summary
Addresses #8451 by implementing rule 116 to add an unsafe fix when sleep
is used with a >24 hour interval to instead consider sleeping forever.
This rule is added as async instead as I my understanding was that these
trio rules would be moved to async anyway.
There are a couple of TODOs, which address further extending the rule by
adding support for lookups and evaluations, and also supporting `anyio`.
## Summary
* Update documentation for F401 following recent PRs
* #11168
* #11314
* Deprecate `ignore_init_module_imports`
* Add a deprecation pragma to the option and a "warn user once" message
when the option is used.
* Restore the old behavior for stable (non-preview) mode:
* When `ignore_init_module_imports` is set to `true` (default) there are
no `__init_.py` fixes (but we get nice fix titles!).
* When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
* When preview mode is enabled, it overrides
`ignore_init_module_imports`.
* Fixed a bug in fix titles where `import foo as bar` would recommend
reexporting `bar as bar`. It now says to reexport `foo as foo`. (In this
case we don't issue a fix, fwiw; it was just a fix title bug.)
## Test plan
Added new fixture tests that reuse the existing fixtures for
`__init__.py` files. Each of the three situations listed above has
fixture tests. The F401 "stable" tests cover:
> * When `ignore_init_module_imports` is set to `true` (default) there
are no `__init_.py` fixes (but we get nice fix titles!).
The F401 "deprecated option" tests cover:
> * When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
These complement existing "preview" tests that show the new behavior
which recommends fixes in `__init__.py` according to whether the import
is 1st party and other circumstances (for more on that behavior see:
#11314).
## Summary
Based on discussion in #10850.
As it stands today `RUF100` will attempt to replace code redirects with
their target codes even though this is not the "goal" of `RUF100`. This
behavior is confusing and inconsistent, since code redirects which don't
otherwise violate `RUF100` will not be updated. The behavior is also
undocumented. Additionally, users who want to use `RUF100` but do not
want to update redirects have no way to opt out.
This PR explicitly detects redirects with a new rule `RUF101` and
patches `RUF100` to keep original codes in fixes and reporting.
## Test Plan
Added fixture.
## Summary
Fixes#10463
Add `FURB192` which detects violations like this:
```python
# Bad
a = sorted(l)[0]
# Good
a = min(l)
```
There is a caveat that @Skylion007 has pointed out, which is that
violations with `reverse=True` technically aren't compatible with this
change, in the edge case where the unstable behavior is intended. For
example:
```python
from operator import itemgetter
data = [('red', 1), ('blue', 1), ('red', 2), ('blue', 2)]
min(data, key=itemgetter(0)) # ('blue', 1)
sorted(data, key=itemgetter(0))[0] # ('blue', 1)
sorted(data, key=itemgetter(0), reverse=True)[-1] # ('blue, 2')
```
This seems like a rare edge case, but I can make the `reverse=True`
fixes unsafe if that's best.
## Test Plan
This is unit tested.
## References
https://github.com/dosisod/refurb/pull/333/files
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
Add pylint rule invalid-hash-returned (PLE0309)
See https://github.com/astral-sh/ruff/issues/970 for rules
Test Plan: `cargo test`
TBD: from the description: "Strictly speaking `bool` is a subclass of
`int`, thus returning `True`/`False` is valid. To be consistent with
other rules (e.g.
[PLE0305](https://github.com/astral-sh/ruff/pull/10962)
invalid-index-returned), ruff will raise, compared to pylint which will
not raise."
Add pylint rule invalid-length-returned (PLE0303)
See https://github.com/astral-sh/ruff/issues/970 for rules
Test Plan: `cargo test`
TBD: from the description: "Strictly speaking `bool` is a subclass of
`int`, thus returning `True`/`False` is valid. To be consistent with
other rules (e.g.
[PLE0305](https://github.com/astral-sh/ruff/pull/10962)
invalid-index-returned), ruff will raise, compared to pylint which will
not raise."
## Summary
This change adds a rule to detect functions declared `async` but lacking
any of `await`, `async with`, or `async for`. This resolves#9951.
## Test Plan
This change was tested by following
https://docs.astral.sh/ruff/contributing/#rule-testing-fixtures-and-snapshots
and adding positive and negative cases for each of `await` vs nothing,
`async with` vs `with`, and `async for` vs `for`.
## Summary
Implement new rule: Prefer augmented assignment (#8877). It checks for
the assignment statement with the form of `<expr> = <expr>
<binary-operator> …` with a unsafe fix to use augmented assignment
instead.
## Test Plan
1. Snapshot test is included in the PR.
2. Manually test with playground.
## Summary
This PR adds the implementation for the current
[flake8-bugbear](https://github.com/PyCQA/flake8-bugbear)'s B038 rule.
The B038 rule checks for mutation of loop iterators in the body of a for
loop and alerts when found.
Rational:
Editing the loop iterator can lead to undesired behavior and is probably
a bug in most cases.
Closes#9511.
Note there will be a second iteration of B038 implemented in
`flake8-bugbear` soon, and this PR currently only implements the weakest
form of the rule.
I'd be happy to also implement the further improvements to B038 here in
ruff 🙂
See https://github.com/PyCQA/flake8-bugbear/issues/454 for more
information on the planned improvements.
## Test Plan
Re-using the same test file that I've used for `flake8-bugbear`, which
is included in this PR (look for the `B038.py` file).
Note: this is my first time using `rust` (beside `rustlings`) - I'd be
very happy about thorough feedback on what I could've done better
🙂 - Bring it on 😀
## Summary
Implement `write-whole-file` (`FURB103`), part of #1348. This is largely
a copy and paste of `read-whole-file` #7682.
## Test Plan
Text fixture added.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Fixes#3172
## Summary
Allow prefixing [extend-]per-file-ignores patterns with `!` to negate
the pattern; listed rules / prefixes will be ignored in all files that
don't match the pattern.
## Test Plan
Added tests for the feature.
Rendered docs and checked rendered output.
## Summary
Add new rule `pyupgrade - UP042` (I picked next available number).
Closes https://github.com/astral-sh/ruff/discussions/3867
Closes https://github.com/astral-sh/ruff/issues/9569
It should warn + provide a fix `class A(str, Enum)` -> `class
A(StrEnum)` for py311+.
## Test Plan
Added UP042.py test.
## Notes
I did not find a way to call `remove_argument` 2 times consecutively, so
the automatic fixing works only for classes that inherit exactly `str,
Enum` (regardless of the order).
I also plan to extend this rule to support IntEnum in next PR.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Implement FURB164 in the issue #1348.
Relevant Refurb docs is here:
https://github.com/dosisod/refurb/blob/v2.0.0/docs/checks.md#furb164-no-from-float
I've changed the name from `no-from-float` to
`verbose-decimal-fraction-construction`.
## Test Plan
<!-- How was it tested? -->
I've written it in the `FURB164.py`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Add a setting `extend-allowed-calls` to allow users to define their own
list of calls which allow boolean traps.
Resolves#10485.
Resolves#10356.
## Test Plan
Extended text fixture and added setting test.
## Summary
PEP 420 says [nested namespace
packages](https://peps.python.org/pep-0420/#nested-namespace-packages)
are allowed, i.e. marking a directory as a namespace package marks all
subdirectories in the subtree as namespace packages.
`is_package` is modified to use `Path::starts_with` and the order of
checks is reversed to do in-memory checks first before hitting the disk.
## Test Plan
Added unit tests. Previously all tests were run with `namespace_packages
== &[]`. Verified that one of the tests was failing before changing the
implementation.
## Future Improvements
The `is_package_with_cache` can probably be rewritten to avoid repeated
calls to `Path::starts_with`, by caching all directories up to the
`namespace_root`:
```ruff
let namespace_root = namespace_packages
.iter()
.filter(|namespace_package| path.starts_with(namespace_package))
.min();
```
## Summary
Adds commas as an accepted separator between copyright years by default,
which is actually documented in one spot, but not currently accurate.
Fixes#9477.
## Summary
Implement `singledispatchmethod-function` from pylint, part of #970.
This is essentially a copy paste of #8934 for `@singledispatchmethod`
decorator.
## Test Plan
Text fixture added.
Re-implementation of https://github.com/astral-sh/ruff/pull/5845 but
instead of deprecating the option I toggle the default. Now users can
_opt-in_ via the setting which will give them an unsafe fix to remove
the import. Otherwise, we raise violations but do not offer a fix. The
setting is a bit of a misnomer in either case, maybe we'll want to
remove it still someday.
As discussed there, I think the safe fix should be to import it as an
alias. I'm not sure. We need support for offering multiple fixes for
ideal behavior though? I think we should remove the fix entirely and
consider it separately.
Closes https://github.com/astral-sh/ruff/issues/5697
Supersedes https://github.com/astral-sh/ruff/pull/5845
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
We had a report of a test failure on a specific architecture, and
looking into it, I think the test assumes that the hash keys are
iterated in a specific order. This PR thus adds a variant to our
settings display macro specifically for maps and sets. Like `CacheKey`,
it sorts the keys when printing.
Closes https://github.com/astral-sh/ruff/issues/10359.
## Summary
Allows `required-version` to be set with a version specifier, like
`>=0.3.1`.
If a single version is provided, falls back to assuming `==0.3.1`, for
backwards compatibility.
Closes https://github.com/astral-sh/ruff/issues/10192.
## Summary
This fixes https://github.com/astral-sh/ruff/issues/7868.
Support isort's `default-section` feature which allows any imports that
match sections that are not in `section-order` to be mapped to a
specifically named section.
https://pycqa.github.io/isort/docs/configuration/options.html#default-section
This has a few implications:
- It is no longer required that all known sections are defined in
`section-order`.
- This is technically a bw-incompat change because currently if folks
define custom groups, and do not define a `section-order`, the code used
to add all known sections to `section-order` while emitting warnings.
**However, when this happened, users would be seeing warnings so I do
not think it should count as a bw-incompat change.**
## Test Plan
- Added a new test.
- Did not break any existing tests.
Finally, I ran the following config against Pyramid's complex codebase
that was previously using isort and this change worked there.
### pyramid's previous isort config
5f7e286b06/pyproject.toml (L22-L37)
```toml
[tool.isort]
profile = "black"
multi_line_output = 3
src_paths = ["src", "tests"]
skip_glob = ["docs/*"]
include_trailing_comma = true
force_grid_wrap = false
combine_as_imports = true
line_length = 79
force_sort_within_sections = true
no_lines_before = "THIRDPARTY"
sections = "FUTURE,THIRDPARTY,FIRSTPARTY,LOCALFOLDER"
default_section = "THIRDPARTY"
known_first_party = "pyramid"
```
### tested with ruff isort config
```toml
[tool.ruff.lint.isort]
case-sensitive = true
combine-as-imports = true
force-sort-within-sections = true
section-order = [
"future",
"third-party",
"first-party",
"local-folder",
]
default-section = "third-party"
known-first-party = [
"pyramid",
]
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
Fixes#6611
## Summary
This lint rule spots comments that are _intended_ to suppress or enable
the formatter, but will be ignored by the Ruff formatter.
We borrow some functions the formatter uses for determining comment
placement / putting them in context within an AST.
The analysis function uses an AST visitor to visit each comment and
attach it to the AST. It then uses that context to check:
1. Is this comment in an expression?
2. Does this comment have bad placement? (e.g. a `# fmt: skip` above a
function instead of at the end of a line)
3. Is this comment redundant?
4. Does this comment actually suppress any code?
5. Does this comment have ambiguous placement? (e.g. a `# fmt: off`
above an `else:` block)
If any of these are true, a violation is thrown. The reported reason
depends on the order of the above check-list: in other words, a `# fmt:
skip` comment on its own line within a list expression will be reported
as being in an expression, since that reason takes priority.
The lint suggests removing the comment as an unsafe fix, regardless of
the reason.
## Test Plan
A snapshot test has been created.
## Summary
The `lxml` library has been modified to address known vulnerabilities
and unsafe defaults. As such, the `defusedxml`
library is no longer necessary, `defusedxml` has deprecated its `lxml`
module.
Closes https://github.com/astral-sh/ruff/issues/10030.
## Summary
Implement [implicit readlines
(FURB129)](https://github.com/dosisod/refurb/blob/master/refurb/checks/iterable/implicit_readlines.py)
lint.
## Notes
I need a help/an opinion about suggested implementations.
This implementation differs from the original one from `refurb` in the
following way. This implementation checks syntactically the call of the
method with the name `readlines()` inside `for` {loop|generator
expression}. The implementation from refurb also
[checks](https://github.com/dosisod/refurb/blob/master/refurb/checks/iterable/implicit_readlines.py#L43)
that callee is a variable with a type `io.TextIOWrapper` or
`io.BufferedReader`.
- I do not see a simple way to implement the same logic.
- The best I can have is something like
```rust
checker.semantic().binding(checker.semantic().resolve_name(attr_expr.value.as_name_expr()?)?).statement(checker.semantic())
```
and analyze cases. But this will be not about types, but about guessing
the type by assignment (or with) expression.
- Also this logic has several false negatives, when the callee is not a
variable, but the result of function call (e.g. `open(...)`).
- On the other side, maybe it is good to lint this on other things,
where this suggestion is not safe, and push the developers to change
their interfaces to be less surprising, comparing with the standard
library.
- Anyway while the current implementation has false-positives (I
mentioned some of them in the test) I marked the fixes to be unsafe.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#8151
This PR implements a new rule, `RUF027`.
## What it does
Checks for strings that contain f-string syntax but are not f-strings.
### Why is this bad?
An f-string missing an `f` at the beginning won't format anything, and
instead treat the interpolation syntax as literal.
### Example
```python
name = "Sarah"
dayofweek = "Tuesday"
msg = "Hello {name}! It is {dayofweek} today!"
```
It should instead be:
```python
name = "Sarah"
dayofweek = "Tuesday"
msg = f"Hello {name}! It is {dayofweek} today!"
```
## Heuristics
Since there are many possible string literals which contain syntax
similar to f-strings yet are not intended to be,
this lint will disqualify any literal that satisfies any of the
following conditions:
1. The string literal is a standalone expression. For example, a
docstring.
2. The literal is part of a function call with keyword arguments that
match at least one variable (for example: `format("Message: {value}",
value = "Hello World")`)
3. The literal (or a parent expression of the literal) has a direct
method call on it (for example: `"{value}".format(...)`)
4. The string has no `{...}` expression sections, or uses invalid
f-string syntax.
5. The string references variables that are not in scope, or it doesn't
capture variables at all.
6. Any format specifiers in the potential f-string are invalid.
## Test Plan
I created a new test file, `RUF027.py`, which is both an example of what
the lint should catch and a way to test edge cases that may trigger
false positives.
## Summary
This rule was added to `flake8-type-checking` as `TC010`. We're about to
stabilize it, so we might as well use the correct code.
See: https://github.com/astral-sh/ruff/issues/9573.
Fixes#7350
## Summary
* `--show-source` and `--no-show-source` are now deprecated.
* `output-format` supports two new variants, `full` and `concise`.
`text` is now a deprecated variant, and any use of it is treated as the
default serialization format.
* `--output-format` now default to `concise`
* In preview mode, `--output-format` defaults to `full`
* `--show-source` will still set `--output-format` to `full` if the
output format is not otherwise specified.
* likewise, `--no-show-source` can override an output format that was
set in a file-based configuration, though it will also be overridden by
`--output-format`
## Test Plan
A lot of tests were updated to use `--output-format=full`. Additional
tests were added to ensure the correct deprecation warnings appeared,
and that deprecated options behaved as intended.
# Conflicts:
# crates/ruff/tests/integration_test.rs
## Summary
This rule was added to flake8-bugbear. In general, we tend to prefer
redirecting to prominent plugins when our own rules are reimplemented
(since more projects have `B` activated than `RUF`).
## Test Plan
`cargo test`
# Conflicts:
# crates/ruff_linter/src/rules/ruff/rules/mod.rs
## Summary
Add a rule for defaultdict(default_factory=callable). Instead suggest
using defaultdict(callable).
See: https://github.com/astral-sh/ruff/issues/9509
If a user tries to bind a "non-callable" to default_factory, the rule
ignores it. Another option would be to warn that it's probably not what
you want. Because Python allows the following:
```python
from collections import defaultdict
defaultdict(default_factory=1)
```
this raises after you actually try to use it:
```python
dd = defaultdict(default_factory=1)
dd[1]
```
=>
```bash
KeyError: 1
```
Instead using callable directly in the constructor it will raise (not
being a callable):
```python
from collections import defaultdict
defaultdict(1)
```
=>
```bash
TypeError: first argument must be callable or None
```
## Test Plan
```bash
cargo test
```
## Summary
If you paste in the TOML for our default configuration (from the docs),
it's rejected by our JSON Schema:

It seems like the issue is with:
```toml
# Set the line length limit used when formatting code snippets in
# docstrings.
#
# This only has an effect when the `docstring-code-format` setting is
# enabled.
docstring-code-line-length = "dynamic"
```
Specifically, since that value uses a custom Serde implementation, I
guess Schemars bails out? This PR adds a custom representation to allow
`"dynamic"` (but no other strings):

This seems like it should work but I don't have a great way to test it.
Closes https://github.com/astral-sh/ruff/issues/9630.
## Summary
Checks for unnecessary `dict` comprehension when creating a new
dictionary from iterable. Suggest to replace with
`dict.fromkeys(iterable)`
See: https://github.com/astral-sh/ruff/issues/9592
## Test Plan
```bash
cargo test
```
## Summary
This PR introduces a new rule to sort `__slots__` and `__match_args__`
according to a [natural sort](https://en.wikipedia.org/wiki/Natural_sort_order), as was
requested in https://github.com/astral-sh/ruff/issues/1198#issuecomment-1881418365.
The implementation here generalises some of the machinery introduced in
3aae16f1bd
so that different kinds of sorts can be applied to lists of string
literals. (We use an "isort-style" sort for `__all__`, but that isn't
really appropriate for `__slots__` and `__match_args__`, where nearly
all items will be snake_case.) Several sections of code have been moved
from `sort_dunder_all.rs` to a new module, `sorting_helpers.rs`, which
`sort_dunder_all.rs` and `sort_dunder_slots.rs` both make use of.
`__match_args__` is very similar to `__all__`, in that it can only be a
tuple or a list. `__slots__` differs from the other two, however, in
that it can be any iterable of strings. If slots is a dictionary, the
values are used by the builtin `help()` function as per-attribute
docstrings that show up in the output of `help()`. (There's no
particular use-case for making `__slots__` a set, but it's perfectly
legal at runtime, so there's no reason for us not to handle it in this
rule.)
Note that we don't do an autofix for multiline `__slots__` if `__slots__` is a dictionary: that's out of scope. Everything else, we can nearly always fix, however.
## Test Plan
`cargo test` / `cargo insta review`.
I also ran this rule on CPython, and the diff looked pretty good
---
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Implement rule `mutable-fromkeys-value` (`RUF023`).
Autofixes
```python
dict.fromkeys(foo, [])
```
to
```python
{key: [] for key in foo}
```
The fix is marked as unsafe as it changes runtime behaviour. It also
uses `key` as the comprehension variable, which may not always be
desired.
Closes#4613.
## Test Plan
`cargo test`
## Summary
#5920 with a fix for the erroneous slice in `module_name`. Fixes#9547.
## Test Plan
Added `import bbb.ccc._ddd as eee` to the test fixture to ensure it no
longer panics.
`cargo test`
## Summary
This implements the rule proposed in #1198 (though it doesn't close the
issue, as there are some open questions about configuration that might
merit some further discussion).
## Test Plan
`cargo test` / `cargo insta review`. I also ran this PR branch on the CPython
codebase with `--fix --select=RUF022 --preview `, and the results looked
pretty good to me.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Andrew Gallant <andrew@astral.sh>
Implements SIM113 from #998
Added tests
Limitations
- No fix yet
- Only flag cases where index variable immediately precede `for` loop
@charliermarsh please review and let me know any improvements
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Closes#9319, implements the [`SIM911` rule from
`flake8-simplify`](https://github.com/MartinThoma/flake8-simplify/pull/183).
#### Note
I wasn't sure whether or not to include
```rs
if checker.settings.preview.is_disabled() {
return;
}
```
at the beginning of the function with violation logic if the rule's
already declared as part of `RuleGroup::Preview`.
I've seen both variants, so I'd appreciate some feedback on that :)
Fixes#8721
## Summary
This implements the rule proposed in #8721, as RUF021. `and` always
binds more tightly than `or` when chaining the two together.
(This should definitely be autofixable, but I'm leaving that to a
followup PR for now.)
## Test Plan
`cargo test` / `cargo insta review`
## Summary
This PR implements Y058 from flake8-pyi -- this is a new flake8-pyi rule
that was released as part of `flake8-pyi 23.11.0`. I've followed the
Python implementation as closely as possible (see
858c0918a8),
except that for the Ruff version, the rule also applies to `.py` files
as well as for `.pyi` files. (For `.py` files, we only emit the
diagnostic in very specific situations, however, as there's a much
higher likelihood of emitting false positives when applying this rule to
a `.py` file.)
## Test Plan
`cargo test`/`cargo insta review`
## Summary
This PR modifies the semantics of `runtime-evaluated-decorators` to
respect decorators on both classes _and_ functions. Historically, this
only respected classes, since the common use-case is (e.g.)
`pydantic.BaseModel` -- but functions are equally valid.
Closes https://github.com/astral-sh/ruff/issues/9312.
## Test Plan
`cargo test`
## Summary
Part of #970.
This adds Pylint's [R0244
empty_comment](https://pylint.pycqa.org/en/latest/user_guide/messages/refactor/empty-comment.html)
lint as well as an always-safe fix.
## Test Plan
The included snapshot verifies the following:
- A line containing only a non-empty comment is not changed
- A line containing leading whitespace before a non-empty comment is not
changed
- A line containing only an empty comment has its content deleted
- A line containing only leading whitespace before an empty comment has
its content deleted
- A line containing only leading and trailing whitespace on an empty
comment has its content deleted
- A line containing trailing whitespace after a non-empty comment is not
changed
- A line containing only a single newline character (i.e. a blank line)
is not changed
- A line containing code followed by a non-empty comment is not changed
- A line containing code followed by an empty comment has its content
deleted after the last non-whitespace character
- Lines containing code and no comments are not changed
- Empty comment lines within block comments are ignored
- Empty comments within triple-quoted sections are ignored
## Comparison to Pylint
Running Ruff and Pylint 3.0.3 with Python 3.12.0 against the
`empty_comment.py` file added in this PR, we see the following:
* Identical behavior:
* empty_comment.py:3:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:4:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:5:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:18:0: R2044: Line with empty comment (empty-comment)
* Differing behavior:
* Pylint doesn't ignore empty comments in block comments commonly used
for visual spacing; I decided these were fine in this implementation
since many projects use these and likely do not want them removed.
* empty_comment.py:28:0: R2044: Line with empty comment (empty-comment)
* Pylint detects "empty comments" within the triple-quoted section at
the bottom of the file, which is arguably a bug in the Pylint
implementation since these are not truly comments. These are ignored by
this implementation.
* empty_comment.py:37:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:38:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:39:0: R2044: Line with empty comment (empty-comment)
## Summary
Adds a rule to detect unions that include `typing.NoReturn` or
`typing.Never`. In such cases, the use of the bottom type is redundant.
Closes https://github.com/astral-sh/ruff/issues/9113.
## Test Plan
`cargo test`
## Summary
A common mistake is to add quotes around one member in an `X | Y`-style
type union, as in:
```python
contract_versions_list: list[ContractVersion] | 'QuerySet[ContractVersion]' | None = None
```
However, doing so will lead to a runtime error if the annotation is
runtime-evaluated. This PR lints against such patterns.
Closes https://github.com/astral-sh/ruff/issues/9139.
This PR does the plumbing to make a new formatting option,
`docstring-code-format`, available in the configuration for end users.
It is disabled by default (opt-in). It is opt-in at least initially to
reflect a conservative posture. The intent is to make it opt-out at some
point in the future.
This was split out from #8811 in order to make #8811 easier to merge.
Namely, once this is merged, docstring code snippet formatting will
become available to end users. (See comments below for how we arrived at
the name.)
Closes#7146
## Test Plan
Other than the standard test suite, I ran the formatter over the CPython
and polars projects to ensure both that the result looked sensible and
that tests still passed. At time of writing, one issue that currently
appears is that reformatting code snippets trips the long line lint:
https://github.com/BurntSushi/polars/actions/runs/7006619426/job/19058868021
## Summary
Adds support for sarif v2.1.0 output to cli, usable via the
output-format paramter.
`ruff . --output-format=sarif`
Includes a few changes I wasn't sure of, namely:
* Adds a few derives for Clone & Copy, which I think could be removed
with a little extra work as well.
## Test Plan
I built and ran this against several large open source projects and
verified that the output sarif was valid, using [Microsoft's SARIF
validator tool](https://sarifweb.azurewebsites.net/Validation)
I've also attached an output of the sarif generated by this version of
ruff on the main branch of django at commit: b287af5dc9
[django_main_b287af5dc9_sarif.json](https://github.com/astral-sh/ruff/files/13626222/django_main_b287af5dc9_sarif.json)
Note: this needs to be regenerated with the latest changes and
confirmed.
## Open Points
[ ] Convert to just using all Rules all the time
[ ] Fix the issue with getting the file URI when compiling for web
assembly
## Summary
This allows us to fix usages like:
```python
from pandas import DataFrame
def baz() -> DataFrame:
...
```
By quoting the `DataFrame` in `-> DataFrame`. Without quotes, moving
`from pandas import DataFrame` into an `if TYPE_CHECKING:` block will
fail at runtime, since Python tries to evaluate the annotation to add it
to the function's `__annotations__`.
Unfortunately, this does require us to split our "annotation kind" flags
into three categories, rather than two:
- `typing-only`: The annotation is only evaluated at type-checking-time.
- `runtime-evaluated`: Python will evaluate the annotation at runtime
(like above) -- but we're willing to quote it.
- `runtime-required`: Python will evaluate the annotation at runtime
(like above), and some library (like Pydantic) needs it to be available
at runtime, so we _can't_ quote it.
This functionality is gated behind a setting
(`flake8-type-checking.quote-annotations`).
Closes https://github.com/astral-sh/ruff/issues/5559.
Hides hints about unsafe fixes when they are disabled e.g. with
`--no-unsafe-fixes` or `unsafe-fixes = false`. By default, unsafe fix
hints are still displayed. This seems like a nice way to remove the nag
for users who have chosen not to apply unsafe fixes.
Inspired by comment at
https://github.com/astral-sh/ruff/issues/9063#issuecomment-1850289675
## Summary
Closes#1567.
Add both `length-sort` and `length-sort-straight` settings for isort.
Here are a few notable points:
- The length is determined using the
[`unicode_width`](https://crates.io/crates/unicode-width) crate, i.e. we
are talking about displayed length (this is explicitly mentioned in the
description of the setting)
- The dots are taken into account in the length to be compatible with
the original isort
- I had to reorder a few fields of the module key struct for it all to
make sense (notably the `force_to_top` field is now the first one)
## Test Plan
I added tests for the following cases:
- Basic tests for length-sort with ASCII characters only
- Tests with non-ASCII characters
- Tests with relative imports
- Tests for length-sort-straight
closes#8732
I noticed that the reference to the setting in the rule docs doesn't
work, but there seem to be something wrong with pylint settings in
general in the docs - the "For related settings, see ...." is also
missing there.
# Summary
This setting behaves similarly to the ``from_first`` setting in isort
upstream, and sorts "from X import Y" type imports before straight
imports.
Like the other PR I added, happy to refactor if this is better in
another form.
Fixes#8662
# Test plan
I've added a unit test, and ran this on a large codebase that relies on
this setting in isort to verify it doesn't have unexpected side effects.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Adds the Pylint rule E1132 to check for repeated keyword arguments in a
function call.
## Test Plan
Tested via the included unit tests and manual spot checking.
## Summary
Implements
[FURB136](https://github.com/dosisod/refurb/blob/master/docs/checks.md#furb136-use-min-max)
that checks for `if` expressions that can be replaced with `min()` or
`max()` calls. See issue #1348 for more information.
This implementation diverges from Refurb's original implementation by
retaining the order of equal values. For example, Refurb suggest that
the following expressions:
```python
highest_score1 = score1 if score1 > score2 else score2
highest_score2 = score1 if score1 >= score2 else score2
```
should be to rewritten as:
```python
highest_score1 = max(score1, score2)
highest_score2 = max(score1, score2)
```
whereas this implementation provides more correct alternatives:
```python
highest_score1 = max(score2, score1)
highest_score2 = max(score1, score2)
```
## Test Plan
Unit test checks all eight possibilities.
## Summary
This adds a ``no-sections`` option for isort in the linter, similar to
the ``no_sections`` option that exists in upstream isort
(https://pycqa.github.io/isort/docs/configuration/options.html#no-sections)
This option puts all imports except for ``__future__`` into the same
section, and is mostly used by monorepos.
I've taken a bit of a leap in assuming that ruff wants to support the
exact same option; more than happy to refactor if you'd prefer a
different way of setting this up.
Fixes#8653
## Test Plan
I've added a test and have run it on a large Python codebase that uses
isort with --no-sections. The option is disabled by default.
When using the autofixer for `Q000` it does not remove the backslashes
from quotes that no longer need escaping.
This new rule checks for such backslashes (regardless whether they come
from the autofixer or not) and can remove them.
fixes#8617
## Summary
This fixes#2606 by moving where we apply the convention ignores --
instead of applying that at the very end, e track, we now track which
rules have been specifically enabled (via `Specificity::Rule`). If they
have, then we do *not* apply the docstring overrides at the end.
## Test Plan
Added unit tests to `ruff_workspace` and an integration test to
`ruff_cli`
## Summary
This brings ruff's behavior in line with what `pep8-naming` already does
and thus closes#8397.
I had initially implemented this to look at the last segment of a dotted
path only when the entry in the `*-decorators` setting started with a
`.`, but in the end I thought it's better to remain consistent w/
`pep8-naming` and doing a match against the last segment of the
decorator name in any case.
If you prefer to diverge from this in favor of less ambiguity in the
configuration let me know and I'll change it so you would need to put
e.g. `.expression` in the `classmethod-decorators` list.
## Test Plan
Tested against the file in the issue linked below, plus the new testcase
added in this PR.
## Summary
Implement
[`no-is-type-none`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/no_is_type_none.py)
as `type-none-comparison` (`FURB169`).
Auto-fixes comparisons that use `type` to compare the type of an object
to `type(None)` to a `None` identity check. For example,
```python
type(foo) is type(None)
```
becomes
```python
foo is None
```
Related to #1348.
## Test Plan
`cargo test`
## Summary
Adds `TRIO105` from the [flake8-trio
plugin](https://github.com/Zac-HD/flake8-trio). The `MethodName` logic
mirrors that of `TRIO100` to stay consistent within the plugin.
It is at 95% parity with the exception of upstream also checking for a
slightly more complex scenario where a call to `start()` on a
`trio.Nursery` context should also be immediately awaited. Upstream
plugin appears to just check for anything named `nursery` judging from
[the relevant issue](https://github.com/Zac-HD/flake8-trio/issues/56).
Unsure if we want to do so something similar or, alternatively, if there
is some capability in ruff to check for calls made on this context some
other way
## Test Plan
Added a new fixture, based on [the one from upstream
plugin](https://github.com/Zac-HD/flake8-trio/blob/main/tests/eval_files/trio105.py)
## Issue link
Refers: https://github.com/astral-sh/ruff/issues/8451
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Hi! Currently NumPy Python API is undergoing a cleanup process that will
be delivered in NumPy 2.0 (release is planned for the end of the year).
Most changes are rather simple (renaming, removing or moving a member of
the main namespace to a new place), and they could be flagged/fixed by
an additional ruff rule for numpy (e.g. changing occurrences of
`np.float_` to `np.float64`).
Would you accept such rule?
I named it `NPY201` in the existing group, so people will receive a
heads-up for changes arriving in 2.0 before actually migrating to it.
~~This is still a draft PR.~~ I'm not an expert in rust so if any part
of code can be done better please share!
NumPy 2.0 migration guide:
https://numpy.org/devdocs/numpy_2_0_migration_guide.html
NEP 52: https://numpy.org/neps/nep-0052-python-api-cleanup.html
NumPy cleanup tracking issue:
https://github.com/numpy/numpy/issues/23999
## Test Plan
A unit test is provided that checks all rule's fix cases.
## Summary
Implements pylint C0415 (import-outside-toplevel) — imports should be at
the top level of a file.
The great debate I had on this implementation is whether "top-level" is
one word or two (`toplevel` or `top_level`). I opted for 2 because that
seemed to be how it is used in the codebase but the rule string itself
uses one-word "toplevel." 🤷 I'd be happy to change it as desired.
I suppose this could be auto-fixed by moving the import to the
top-level, but it seems likely that the author's intent was to actually
import this dynamically, so I view the main point of this rule is to
force some sort of explanation, and auto-fixing might be annoying.
For reference, this is what "pylint" reports:
```
> pylint crates/ruff/resources/test/fixtures/pylint/import_outside_top_level.py
************* Module import_outside_top_level
...
crates/ruff/resources/test/fixtures/pylint/import_outside_top_level.py:4:4: C0415: Import outside toplevel (string) (import-outside-toplevel)
```
ruff would now report:
```
import_outside_top_level.py:4:5: PLC0415 `import` should be used only at the top level of a file
|
3 | def import_outside_top_level():
4 | import string # [import-outside-toplevel]
| ^^^^^^^^^^^^^ PLC0415
|
```
Contributes to https://github.com/astral-sh/ruff/issues/970.
## Test Plan
Snapshot test.
## Summary
Implement
[`no-isinstance-type-none`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/no_isinstance_type_none.py)
as `isinstance-type-none` (`FURB168`).
Auto-fixes calls to `isinstance` to check if an object is `None` to a
`None` identity check. For example,
```python
isinstance(foo, type(None))
```
becomes
```python
foo is None
```
Related to #1348.
## Test Plan
`cargo test`
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Remove wrong note on `tool.ruff.format` `exclude` option from
documentation which is referencing `extend-exclude` even if it's not
relevant for the formatter options (`exclude` is additive). See #8301
## Test Plan
N/A (Docs change)
## Summary
Avoid warning about incompatible rules except if their configuration
directly conflicts with the formatter. This should reduce the noise and
potentially the need for https://github.com/astral-sh/ruff/issues/8175
and https://github.com/astral-sh/ruff/issues/8185
I also extended the rule and option documentation to mention any
potential formatter incompatibilities or whether they're redundant when
using the formatter.
* `LineTooLong`: This is a use case we explicitly want to support. Don't
warn about it
* `TabIndentation`, `IndentWithSpaces`: Only warn if
`indent-style="tab"`
* `IndentationWithInvalidMultiple`,
`IndentationWithInvalidMultipleComment`: Only warn if `indent-width !=
4`
* `OverIndented`: Don't warn, but mention that the rule is redundant
* `BadQuotesInlineString`: Warn if quote setting is different from
`format.quote-style`
* `BadQuotesMultilineString`, `BadQuotesDocstring`: Warn if `quote !=
"double"`
## Test Plan
I added a new integration test for the default configuration with `ALL`.
`ruff format` now only shows two incompatible rules, which feels more
reasonable.
## Summary
This PR renames the `tab-size` configuration option to `indent-width` to
express that the formatter uses the option to determine the indentation
width AND as tab width.
I first preferred naming the option `tab-width` but then decided to go
with `indent-width` because:
* It aligns with the `indent-style` option
* It would allow us to write a lint rule that asserts that each
indentation uses `indent-width` spaces.
Closes#7643
## Test Plan
Added integration test
## Summary
This PR introduces a new `pycodestyl.max-line-length` option that allows overriding the global `line-length` option for `E501` only.
This is useful when using the formatter and `E501` together, where the formatter uses a lower limit and `E501` is only used to catch extra-long lines.
Closes#7644
## Considerations
~~Our fix infrastructure asserts in some places that the fix doesn't exceed the configured `line-width`. With this change, the question is whether it should use the `pycodestyle.max-line-width` or `line-width` option to make that decision.
I opted for the global `line-width` for now, considering that it should be the lower limit. However, this constraint isn't enforced and users not using the formatter may only specify `pycodestyle.max-line-width` because they're unaware of the global option (and it solves their need).~~
~~I'm interested to hear your thoughts on whether we should use `pycodestyle.max-line-width` or `line-width` to decide on whether to emit a fix or not.~~
Edit: The linter users `pycodestyle.max-line-width`. The `line-width` option has been removed from the `LinterSettings`
## Test Plan
Added integration test. Built the documentation and verified that the links are correct.
This is my first PR and I'm new at rust, so feel free to ask me to
rewrite everything if needed ;)
The rule must be called after deferred lambas have been visited because
of the last check (whether the lambda parameters are used in the body of
the function that's being called). I didn't know where to do it, so I
did what I could to be able to work on the rule itself:
- added a `ruff_linter::checkers::ast::analyze::lambda` module
- build a vec of visited lambdas in `visit_deferred_lambdas`
- call `analyze::lambda` on the vec after they all have been visited
Building that vec of visited lambdas was necessary so that bindings
could be properly resolved in the case of nested lambdas.
Note that there is an open issue in pylint for some false positives, do
we need to fix that before merging the rule?
https://github.com/pylint-dev/pylint/issues/8192
Also, I did not provide any fixes (yet), maybe we want do avoid merging
new rules without fixes?
## Summary
Checks for lambdas whose body is a function call on the same arguments
as the lambda itself.
### Bad
```python
df.apply(lambda x: str(x))
```
### Good
```python
df.apply(str)
```
## Test Plan
Added unit test and snapshot.
Manually compared pylint and ruff output on pylint's test cases.
## References
- [pylint
documentation](https://pylint.readthedocs.io/en/latest/user_guide/messages/warning/unnecessary-lambda.html)
- [pylint
implementation](https://github.com/pylint-dev/pylint/blob/main/pylint/checkers/base/basic_checker.py#L521-L587)
- https://github.com/astral-sh/ruff/issues/970
## Summary
Fix a typo in the docs for quote style.
> a = "a string without any quotes"
> b = "It's monday morning"
> Ruff will change a to use single quotes when using quote-style =
"single". However, a will be unchanged, as converting to single quotes
would require the inner ' to be escaped, which leads to less readable
code: 'It\'s monday morning'.
It should read "However, **b** will be unchanged".
## Test Plan
N/A.
## Summary
### What it does
This rule triggers an error when a bare raise statement is not in an
except or finally block.
### Why is this bad?
If raise statement is not in an except or finally block, there is no
active exception to
re-raise, so it will fail with a `RuntimeError` exception.
### Example
```python
def validate_positive(x):
if x <= 0:
raise
```
Use instead:
```python
def validate_positive(x):
if x <= 0:
raise ValueError(f"{x} is not positive")
```
## Test Plan
Added unit test and snapshot.
Manually compared ruff and pylint outputs on pylint's tests.
## References
- [pylint
documentation](https://pylint.pycqa.org/en/stable/user_guide/messages/error/misplaced-bare-raise.html)
- [pylint
implementation](https://github.com/pylint-dev/pylint/blob/main/pylint/checkers/exceptions.py#L339)
See the provided breaking changes note for details.
Removes support for the deprecated `--format`option in the `ruff check`
CLI, `format` inference as `output-format` in the configuration file,
and the `RUFF_FORMAT` environment variable.
The error message for use of `format` in the configuration file could be
better, but would require some awkward serde wrappers and it seems hard
to present the correct schema to the user still.
Adds two configuration-file only settings `extend-safe-fixes` and
`extend-unsafe-fixes` which can be used to promote and demote the
applicability of fixes for rules.
Fixes with `Never` applicability cannot be promoted.
## Summary
Restores functionality of #7875 but in the correct place. Closes#7877.
~~I couldn't figure out how to get cargo fmt to work, so hopefully
that's run in CI.~~ Nevermind, figured it out.
## Test Plan
Can see output of json.
## Summary
Implement
[`no-single-item-in`](https://github.com/dosisod/refurb/blob/master/refurb/checks/iterable/no_single_item_in.py)
as `single-item-membership-test` (`FURB171`).
Uses the helper function `generate_comparison` from the `pycodestyle`
implementations; this function should probably be moved, but I am not
sure where at the moment.
Update: moved it to `ruff_python_ast::helpers`.
Related to #1348.
## Test Plan
`cargo test`
Rebase of https://github.com/astral-sh/ruff/pull/5119 authored by
@evanrittenhouse with additional refinements.
## Changes
- Adds `--unsafe-fixes` / `--no-unsafe-fixes` flags to `ruff check`
- Violations with unsafe fixes are not shown as fixable unless opted-in
- Fix applicability is respected now
- `Applicability::Never` fixes are no longer applied
- `Applicability::Sometimes` fixes require opt-in
- `Applicability::Always` fixes are unchanged
- Hints for availability of `--unsafe-fixes` added to `ruff check`
output
## Examples
Check hints at hidden unsafe fixes
```
❯ ruff check example.py --no-cache --select F601,W292
example.py:1:14: F601 Dictionary key literal `'a'` repeated
example.py:2:15: W292 [*] No newline at end of file
Found 2 errors.
[*] 1 fixable with the `--fix` option (1 hidden fix can be enabled with the `--unsafe-fixes` option).
```
We could add an indicator for which violations have hidden fixes in the
future.
Check treats unsafe fixes as applicable with opt-in
```
❯ ruff check example.py --no-cache --select F601,W292 --unsafe-fixes
example.py:1:14: F601 [*] Dictionary key literal `'a'` repeated
example.py:2:15: W292 [*] No newline at end of file
Found 2 errors.
[*] 2 fixable with the --fix option.
```
Also can be enabled in the config file
```
❯ cat ruff.toml
unsafe-fixes = true
```
And opted-out per invocation
```
❯ ruff check example.py --no-cache --select F601,W292 --no-unsafe-fixes
example.py:1:14: F601 Dictionary key literal `'a'` repeated
example.py:2:15: W292 [*] No newline at end of file
Found 2 errors.
[*] 1 fixable with the `--fix` option (1 hidden fix can be enabled with the `--unsafe-fixes` option).
```
Diff does not include unsafe fixes
```
❯ ruff check example.py --no-cache --select F601,W292 --diff
--- example.py
+++ example.py
@@ -1,2 +1,2 @@
x = {'a': 1, 'a': 1}
-print(('foo'))
+print(('foo'))
\ No newline at end of file
Would fix 1 error.
```
Unless there is opt-in
```
❯ ruff check example.py --no-cache --select F601,W292 --diff --unsafe-fixes
--- example.py
+++ example.py
@@ -1,2 +1,2 @@
-x = {'a': 1}
-print(('foo'))
+x = {'a': 1, 'a': 1}
+print(('foo'))
\ No newline at end of file
Would fix 2 errors.
```
https://github.com/astral-sh/ruff/pull/7790 will improve the diff
messages following this pull request
Similarly, `--fix` and `--fix-only` require the `--unsafe-fixes` flag to
apply unsafe fixes.
## Related
Replaces #5119
Closes https://github.com/astral-sh/ruff/issues/4185
Closes https://github.com/astral-sh/ruff/issues/7214
Closes https://github.com/astral-sh/ruff/issues/4845
Closes https://github.com/astral-sh/ruff/issues/3863
Addresses https://github.com/astral-sh/ruff/issues/6835
Addresses https://github.com/astral-sh/ruff/issues/7019
Needs follow-up https://github.com/astral-sh/ruff/issues/6962
Needs follow-up https://github.com/astral-sh/ruff/issues/4845
Needs follow-up https://github.com/astral-sh/ruff/issues/7436
Needs follow-up https://github.com/astral-sh/ruff/issues/7025
Needs follow-up https://github.com/astral-sh/ruff/issues/6434
Follow-up #7790
Follow-up https://github.com/astral-sh/ruff/pull/7792
---------
Co-authored-by: Evan Rittenhouse <evanrittenhouse@gmail.com>
Part of #1646.
## Summary
Implement `S505`
([`weak_cryptographic_key`](https://bandit.readthedocs.io/en/latest/plugins/b505_weak_cryptographic_key.html))
rule from `bandit`.
For this rule, `bandit` [reports the issue
with](https://github.com/PyCQA/bandit/blob/1.7.5/bandit/plugins/weak_cryptographic_key.py#L47-L56):
- medium severity for DSA/RSA < 2048 bits and EC < 224 bits
- high severity for DSA/RSA < 1024 bits and EC < 160 bits
Since Ruff does not handle severities for `bandit`-related rules, we
could either report the issue if we have lower values than medium
severity, or lower values than high one. Two reasons led me to choose
the first option:
- a medium severity issue is still a security issue we would want to
report to the user, who can then decide to either handle the issue or
ignore it
- `bandit` [maps the EC key algorithms to their respective key lengths
in
bits](https://github.com/PyCQA/bandit/blob/1.7.5/bandit/plugins/weak_cryptographic_key.py#L112-L133),
but there is no value below 160 bits, so technically `bandit` would
never report medium severity issues for EC keys, only high ones
Another consideration is that as shared just above, for EC key
algorithms, `bandit` has a mapping to map the algorithms to their
respective key lengths. In the implementation in Ruff, I rather went
with an explicit list of EC algorithms known to be vulnerable (which
would thus be reported) rather than implementing a mapping to retrieve
the associated key length and comparing it with the minimum value.
## Test Plan
Snapshot tests from
https://github.com/PyCQA/bandit/blob/1.7.5/examples/weak_cryptographic_key_sizes.py.
Closes#7434
Replaces the `PREVIEW` selector (removed in #7389) with a configuration
option `explicit-preview-rules` which requires selectors to use exact
rule codes for all preview rules. This allows users to enable preview
without opting into all preview rules at once.
## Test plan
Unit tests
## Summary
At present, `quote-style` is used universally. However, [PEP
8](https://peps.python.org/pep-0008/) and [PEP
257](https://peps.python.org/pep-0257/) suggest that while either single
or double quotes are acceptable in general (as long as they're
consistent), docstrings and triple-quoted strings should always use
double quotes. In our research, the vast majority of Ruff users that
enable the `flake8-quotes` rules only enable them for inline strings
(i.e., non-triple-quoted strings).
Additionally, many Black forks (like Blue and Pyink) use double quotes
for docstrings and triple-quoted strings.
Our decision for now is to always prefer double quotes for triple-quoted
strings (which should include docstrings). Based on feedback, we may
consider adding additional options (e.g., a `"preserve"` mode, to avoid
changing quotes; or a `"multiline-quote-style"` to override this).
Closes https://github.com/astral-sh/ruff/issues/7615.
## Test Plan
`cargo test`
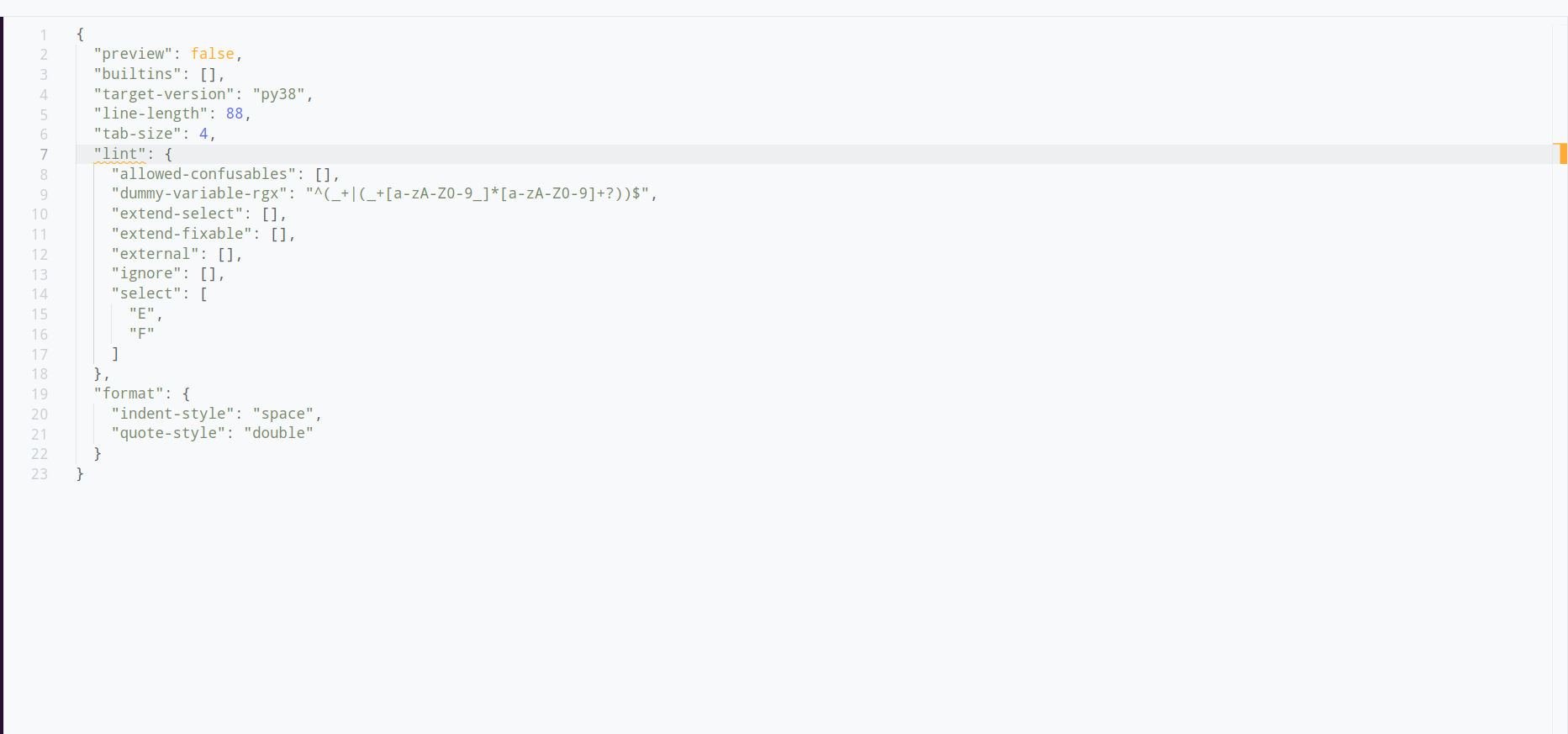
## Summary
This PR adds a new `lint` section to the configuration that groups all linter-specific settings. The existing top-level configurations continue to work without any warning because the `lint.*` settings are experimental.
The configuration merges the top level and `lint.*` settings where the settings in `lint` have higher precedence (override the top-level settings). The reasoning behind this is that the settings in `lint.` are more specific and more specific settings should override less specific settings.
I decided against showing the new `lint.*` options on our website because it would make the page extremely long (it's technically easy to do, just attribute `lint` with `[option_group`]). We may want to explore adding an `alias` field to the `option` attribute and show the alias on the website along with its regular name.
## Test Plan
* I added new integration tests
* I verified that the generated `options.md` is identical
* Verified the default settings in the playground
## Summary
Implement
[`simplify-print`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/print.py)
as `print-empty-string` (`FURB105`).
Extends the original rule in that it also checks for multiple empty
string positional arguments with an empty string separator.
Related to #1348.
## Test Plan
`cargo test`
## Summary
Implement
[`no-ignored-enumerate-items`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/no_ignored_enumerate.py)
as `unnecessary-enumerate` (`FURB148`).
The auto-fix considers if a `start` argument is passed to the
`enumerate()` function. If only the index is used, then the suggested
fix is to pass the `start` value to the `range()` function. So,
```python
for i, _ in enumerate(xs, 1):
...
```
becomes
```python
for i in range(1, len(xs)):
...
```
If the index is ignored and only the value is ignored, and if a start
value greater than zero is passed to `enumerate()`, the rule doesn't
produce a suggestion. I couldn't find a unanimously accepted best way to
iterate over a collection whilst skipping the first n elements. The rule
still triggers, however.
Related to #1348.
## Test Plan
`cargo test`
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR implements a new rule for `flake8-logging` plugin that checks
for uses of `logging.exception()` with `exc_info` set to `False` or a
falsy value. It suggests using `logging.error` in these cases instead.
I am unsure about the name. Open to suggestions there, went with the
most explicit name I could think of in the meantime.
Refer https://github.com/astral-sh/ruff/issues/7248
## Test Plan
Added a new fixture cases and ran `cargo test`
## Summary
This PR implements a new rule for `flake8-logging` plugin that checks
for
`logging.getLogger` calls with either `__file__` or `__cached__` as the
first
argument and generates a suggested fix to use `__name__` instead.
Refer: #7248
## Test Plan
Add test cases and `cargo test`
## Summary
We're planning to move the documentation from
[https://beta.ruff.rs/docs](https://beta.ruff.rs/docs) to
[https://docs.astral.sh/ruff](https://docs.astral.sh/ruff), for a few
reasons:
1. We want to remove the `beta` from the domain, as Ruff is no longer
considered beta software.
2. We want to migrate to a structure that could accommodate multiple
future tools living under one domain.
The docs are actually already live at
[https://docs.astral.sh/ruff](https://docs.astral.sh/ruff), but later
today, I'll add a permanent redirect from the previous to the new
domain. **All existing links will continue to work, now and in
perpetuity.**
This PR contains the code changes necessary for the updated
documentation. As part of this effort, I moved the playground and
documentation from my personal Cloudflare account to our team Cloudflare
account (hence the new `--project-name` references). After merging, I'll
also update the secrets on this repo.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Adds the maximum of 320 for the line-length setting to the JSON schema
for better integration with IDEs.
Related https://github.com/astral-sh/ruff/pull/6873
## Test Plan
<!-- How was it tested? -->