## Summary
The problem: given a (row, column) number (e.g., for a token in the AST), we need to be able to map it to a precise byte index in the source code. A while ago, we moved to `ropey` for this, since it was faster in practice (mostly, I think, because it's able to defer indexing). However, at some threshold of accesses, it becomes faster to index the string in advance, as we're doing here.
## Benchmark
It looks like this is ~3.6% slower for the default rule set, but ~9.3% faster for `--select ALL`.
**I suspect there's a strategy that would be strictly faster in both cases**, based on deferring even more computation (right now, we lazily compute these offsets, but we do it for the entire file at once, even if we only need some slice at the top), or caching the `ropey` lookups in some way.
Before:
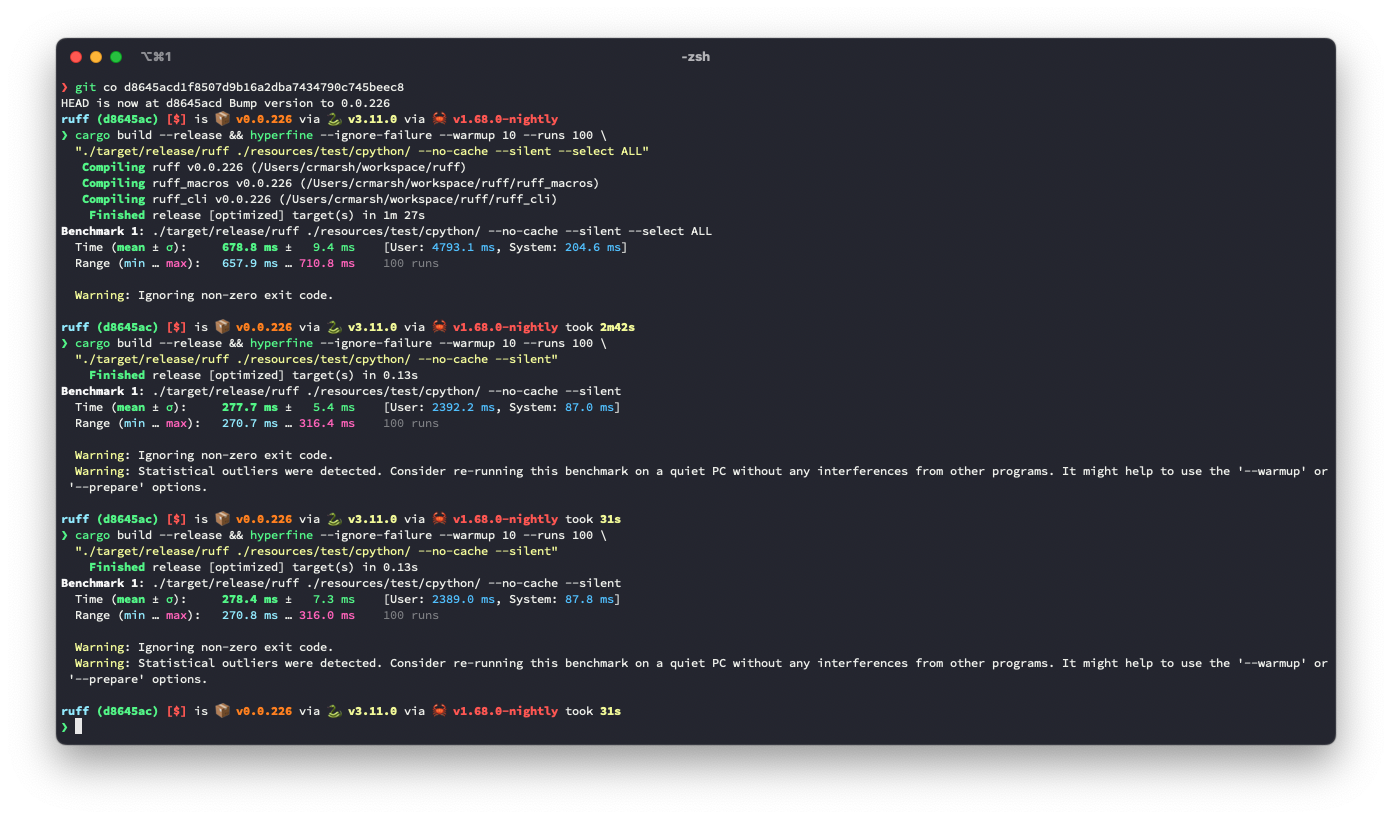
After:
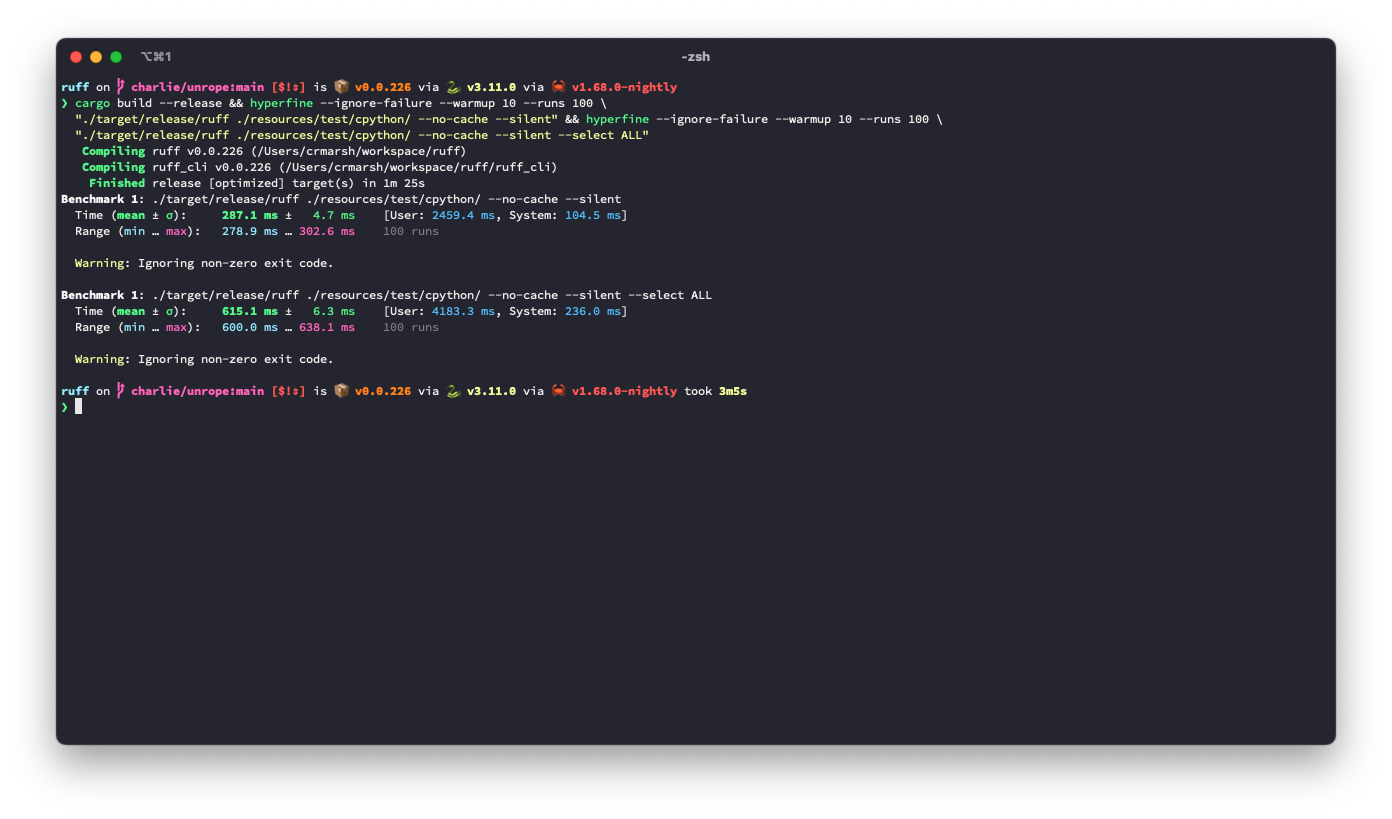
## Alternatives
I tried tweaking the `Vec::with_capacity` hints, and even trying `Vec::with_capacity(str_indices::lines_crlf::count_breaks(contents))` to do a quick scan of the number of lines, but that turned out to be slower.
Add tests.
Ensure that these cases are caught by ICN001:
```python
from xml.dom import minidom
from xml.dom.minidom import parseString
```
with config:
```toml
[tool.ruff.flake8-import-conventions.extend-aliases]
"dask.dataframe" = "dd"
"xml.dom.minidom" = "md"
"xml.dom.minidom.parseString" = "pstr"
```
This _did_ fix https://github.com/charliermarsh/ruff/issues/1894, but was a little premature. `toml` doesn't actually depend on `toml-edit` yet, and `v0.5.11` was mostly about deprecations AFAICT. So upgrading might solve that issue, but could introduce other incompatibilities, and I'd like to minimize churn. I expect that `toml` will have a new release soon, so we can revert this revert.
Reverts charliermarsh/ruff#2040.
The idea is the same as #1867. Avoids emitting `SIM102` twice for the following code:
```python
if a:
if b:
if c:
d
```
```
resources/test/fixtures/flake8_simplify/SIM102.py:1:1: SIM102 Use a single `if` statement instead of nested `if` statements
resources/test/fixtures/flake8_simplify/SIM102.py:2:5: SIM102 Use a single `if` statement instead of nested `if` statements
```
This PR adds the scaffolding files for `flake8-type-checking`, along with the simplest rule (`empty-type-checking-block`), just as an example to get us started.
See: #1785.
543865c96b introduced
RuleCode::origin() -> RuleOrigin generation via a macro, while that
signature now has been renamed to Rule::origin() -> Linter we actually
want to get rid of it since rules and linters shouldn't be this tightly
coupled (since one rule can exist in multiple linters).
Another disadvantage of the previous approach was that the prefixes
had to be defined in ruff_macros/src/prefixes.rs, which was easy to
miss when defining new linters in src/*, case in point
INP001 => violations::ImplicitNamespacePackage has in the meantime been
added without ruff_macros/src/prefixes.rs being updated accordingly
which resulted in `ruff --explain INP001` mistakenly reporting that the
rule belongs to isort (since INP001 starts with the isort prefix "I").
The derive proc macro introduced in this commit requires every variant
to have at least one #[prefix = "..."], eliminating such mistakes.
More accurate since the enum also encompasses:
* ALL (which isn't a prefix at all)
* fully-qualified rule codes (which aren't prefixes unless you say
they're a prefix to the empty string but that's not intuitive)
"origin" was accurate since ruff rules are currently always modeled
after one origin (except the Ruff-specific rules).
Since we however want to introduce a many-to-many mapping between codes
and rules, the term "origin" no longer makes much sense. Rules usually
don't have multiple origins but one linter implements a rule first and
then others implement it later (often inspired from another linter).
But we don't actually care much about where a rule originates from when
mapping multiple rule codes to one rule implementation, so renaming
RuleOrigin to Linter is less confusing with the many-to-many system.
Tracking issue: https://github.com/charliermarsh/ruff/issues/2024
Implementation for EXE003, EXE004 and EXE005 of `flake8-executable`
(shebang should contain "python", not have whitespace before, and should be on the first line)
Please take in mind that this is my first rust contribution.
The remaining EXE-rules are a combination of shebang (`lines.rs`), file permissions (`fs.rs`) and if-conditions (`ast.rs`). I was not able to find other rules that have interactions/dependencies in them. Any advice on how this can be best implemented would be very welcome.
For autofixing `EXE005`, I had in mind to _move_ the shebang line to the top op the file. This could be achieved by a combination of `Fix::insert` and `Fix::delete` (multiple fixes per diagnostic), or by implementing a dedicated `Fix::move`, or perhaps in other ways. For now I've left it out, but keen on hearing what you think would be most consistent with the package, and pointer where to start (if at all).
---
If you care about another testimonial:
`ruff` not only helps staying on top of the many excellent flake8 plugins and other Python code quality tools that are available, it also applies them at baffling speed.
(Planning to implement it soon for github.com/pandas-profiling/pandas-profiling (as largest contributor) and github.com/ing-bank/popmon.)
Rule described here: https://www.flake8rules.com/rules/E101.html
I tried to follow contributing guidelines closely, I've never worked with Rust before. Stumbled across Ruff a few days ago and would like to use it in our project, but we use a bunch of flake8 rules that are not yet implemented in ruff, so I decided to give it a go.
For now, we're just gonna avoid flagging this for `elif` blocks, following the same reasoning as for ternaries. We can handle all of these cases, but we'll knock out the TODOs as a pair, and this avoids broken code.
Closes#2007.
This PR adds a new check that turns expressions such as `[1, 2, 3] + foo` into `[1, 2, 3, *foo]`, since the latter is easier to read and faster:
```
~ $ python3.11 -m timeit -s 'b = [6, 5, 4]' '[1, 2, 3] + b'
5000000 loops, best of 5: 81.4 nsec per loop
~ $ python3.11 -m timeit -s 'b = [6, 5, 4]' '[1, 2, 3, *b]'
5000000 loops, best of 5: 66.2 nsec per loop
```
However there's a couple of gotchas:
* This felt like a `simplify` rule, so I borrowed an unused `SIM` code even if the upstream `flake8-simplify` doesn't do this transform. If it should be assigned some other code, let me know 😄
* **More importantly** this transform could be unsafe if the other operand of the `+` operation has overridden `__add__` to do something else. What's the `ruff` policy around potentially unsafe operations? (I think some of the suggestions other ported rules give could be semantically different from the original code, but I'm not sure.)
* I'm not a very established Rustacean, so there's no doubt my code isn't quite idiomatic. (For instance, is there a neater way to write that four-way `match` statement?)
Thanks for `ruff`, by the way! :)
# This commit has been generated via the following Python script:
# (followed by `cargo +nightly fmt` and `cargo dev generate-all`)
# For the reasoning see the previous commit(s).
import re
import sys
for path in (
'src/violations.rs',
'src/rules/flake8_tidy_imports/banned_api.rs',
'src/rules/flake8_tidy_imports/relative_imports.rs',
):
with open(path) as f:
text = ''
while line := next(f, None):
if line.strip() != 'fn message(&self) -> String {':
text += line
continue
text += ' #[derive_message_formats]\n' + line
body = next(f)
while (line := next(f)) != ' }\n':
body += line
# body = re.sub(r'(?<!code\| |\.push\()format!', 'format!', body)
body = re.sub(
r'("[^"]+")\s*\.to_string\(\)', r'format!(\1)', body, re.DOTALL
)
body = re.sub(
r'(r#".+?"#)\s*\.to_string\(\)', r'format!(\1)', body, re.DOTALL
)
text += body + ' }\n'
while (line := next(f)).strip() != 'fn placeholder() -> Self {':
text += line
while (line := next(f)) != ' }\n':
pass
with open(path, 'w') as f:
f.write(text)
The idea is nice and simple we replace:
fn placeholder() -> Self;
with
fn message_formats() -> &'static [&'static str];
So e.g. if a Violation implementation defines:
fn message(&self) -> String {
format!("Local variable `{name}` is assigned to but never used")
}
it would also have to define:
fn message_formats() -> &'static [&'static str] {
&["Local variable `{name}` is assigned to but never used"]
}
Since we however obviously do not want to duplicate all of our format
strings we simply introduce a new procedural macro attribute
#[derive_message_formats] that can be added to the message method
declaration in order to automatically derive the message_formats
implementation.
This commit implements the macro. The following and final commit
updates violations.rs to use the macro. (The changes have been separated
because the next commit is autogenerated via a Python script.)
ruff_dev::generate_rules_table previously documented which rules are
autofixable via DiagnosticKind::fixable ... since the DiagnosticKind was
obtained via Rule::kind (and Violation::placeholder) which we both want
to get rid of we have to obtain the autofixability via another way.
This commit implements such another way by adding an AUTOFIX
associated constant to the Violation trait. The constant is of the type
Option<AutoFixkind>, AutofixKind is a new struct containing an
Availability enum { Sometimes, Always}, letting us additionally document
that some autofixes are only available sometimes (which previously
wasn't documented). We intentionally introduce this information in a
struct so that we can easily introduce further autofix metadata in the
future such as autofix applicability[1].
[1]: https://doc.rust-lang.org/stable/nightly-rustc/rustc_errors/enum.Applicability.html
While ruff displays the string returned by Violation::message in its
output for detected violations the messages displayed in the README
and in the `--explain <code>` output previously used the
DiagnosticKind::summary() function which for some verbose messages
provided shorter descriptions.
This commit removes DiagnosticKind::summary, and moves the more
extensive documentation into doc comments ... these are not displayed
yet to the user but doing that is very much planned.
This commit series removes the following associated
function from the Violation trait:
fn placeholder() -> Self;
ruff previously used this placeholder approach for the messages it
listed in the README and displayed when invoked with --explain <code>.
This approach is suboptimal for three reasons:
1. The placeholder implementations are completely boring code since they
just initialize the struct with some dummy values.
2. Displaying concrete error messages with arbitrary interpolated values
can be confusing for the user since they might not recognize that the
values are interpolated.
3. Some violations have varying format strings depending on the
violation which could not be documented with the previous approach
(while we could have changed the signature to return Vec<Self> this
would still very much suffer from the previous two points).
We therefore drop Violation::placeholder in favor of a new macro-based
approach, explained in commit 4/5.
Violation::placeholder is only invoked via Rule::kind, so we firstly
have to get rid of all Rule::kind invocations ... this commit starts
removing the trivial cases.
Fixes: #1953
@charliermarsh thank you for the tips in the issue.
I'm not very familiar with Rust, so please excuse if my string formatting syntax is messy.
In terms of testing, I compared output of `flake8 --format=pylint ` and `cargo run --format=pylint` on the same code and the output syntax seems to check out.
# This commit was automatically generated by running the following
# script (followed by `cargo +nightly fmt`):
import glob
import re
from typing import NamedTuple
class Rule(NamedTuple):
code: str
name: str
path: str
def rules() -> list[Rule]:
"""Returns all the rules defined in `src/registry.rs`."""
file = open('src/registry.rs')
rules = []
while next(file) != 'ruff_macros::define_rule_mapping!(\n':
continue
while (line := next(file)) != ');\n':
line = line.strip().rstrip(',')
if line.startswith('//'):
continue
code, path = line.split(' => ')
name = path.rsplit('::')[-1]
rules.append(Rule(code, name, path))
return rules
code2name = {r.code: r.name for r in rules()}
for pattern in ('src/**/*.rs', 'ruff_cli/**/*.rs', 'ruff_dev/**/*.rs', 'scripts/add_*.py'):
for name in glob.glob(pattern, recursive=True):
with open(name) as f:
text = f.read()
text = re.sub('Rule(?:Code)?::([A-Z]\w+)', lambda m: 'Rule::' + code2name[m.group(1)], text)
text = re.sub(r'(?<!"<FilePattern>:<)RuleCode\b', 'Rule', text)
text = re.sub('(use crate::registry::{.*, Rule), Rule(.*)', r'\1\2', text) # fix duplicate import
with open(name, 'w') as f:
f.write(text)
{kind=link}
{kind=link}