Add support for declared types to the semantic index. This involves a
lot of renaming to clarify the distinction between bindings and
declarations. The Definition (or more specifically, the DefinitionKind)
becomes responsible for determining which definitions are bindings,
which are declarations, and which are both, and the symbol table
building is refactored a bit so that the `IS_BOUND` (renamed from
`IS_DEFINED` for consistent terminology) flag is always set when a
binding is added, rather than being set separately (and requiring us to
ensure it is set properly).
The `SymbolState` is split into two parts, `SymbolBindings` and
`SymbolDeclarations`, because we need to store live bindings for every
declaration and live declarations for every binding; the split lets us
do this without storing more than we need.
The massive doc comment in `use_def.rs` is updated to reflect bindings
vs declarations.
The `UseDefMap` gains some new APIs which are allow-unused for now,
since this PR doesn't yet update type inference to take declarations
into account.
## Summary
Follow-up from #13268, this PR updates the test case to use
`assert_snapshot` now that the output is limited to only include the
rules with diagnostics.
## Test Plan
`cargo insta test`
Add `::is_empty` and `::union` methods to the `BitSet` implementation.
Allowing unused for now, until these methods become used later with the
declared-types implementation.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
These are quite incomplete, but I needed to start stubbing them out in
order to build and test declared-types.
Allowing unused for now, until they are used later in the declared-types
PR.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR adds a new `Type` variant called `TupleType` which is used for
heterogeneous elements.
### Display notes
* For an empty tuple, I'm using `tuple[()]` as described in the docs:
https://docs.python.org/3/library/typing.html#annotating-tuples
* For nested elements, it'll use the literal type instead of builtin
type unlike Pyright which does `tuple[Literal[1], tuple[int, int]]`
instead of `tuple[Literal[1], tuple[Literal[2], Literal[3]]]`. Also,
mypy would give `tuple[builtins.int, builtins.int]` instead of
`tuple[Literal[1], Literal[2]]`
## Test Plan
Update test case to account for the display change and add cases for
multiple elements and nested tuple elements.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR adds support for control flow for match statement.
It also adds the necessary infrastructure required for narrowing
constraints in case blocks and implements the logic for
`PatternMatchSingleton` which is either `None` / `True` / `False`. Even
after this the inferred type doesn't get simplified completely, there's
a TODO for that in the test code.
## Test Plan
Add test cases for control flow for (a) when there's a wildcard pattern
and (b) when there isn't. There's also a test case to verify the
narrowing logic.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
When a type of the form `Literal["..."]` would be constructed with too
large of a string, this PR converts it to `LiteralString` instead.
We also extend inference for binary operations to include the case where
one of the operands is `LiteralString`.
Closes#13224
Pull the tests from `types.rs` into `infer.rs`.
All of these are integration tests with the same basic form: create a
code sample, run type inference or check on it, and make some assertions
about types and/or diagnostics. These are the sort of tests we will want
to move into a test framework with a low-boilerplate custom textual
format. In the meantime, having them together (and more importantly,
their helper utilities together) means that it's easy to keep tests for
related language features together (iterable tests with other iterable
tests, callable tests with other callable tests), without an artificial
split based on tests which test diagnostics vs tests which test
inference. And it allows a single test to more easily test both
diagnostics and inference. (Ultimately in the test framework, they will
likely all test diagnostics, just in some cases the diagnostics will
come from `reveal_type()`.)
My plan for handling declared types is to introduce a `Declaration` in
addition to `Definition`. A `Declaration` is an annotation of a name
with a type; a `Definition` is an actual runtime assignment of a value
to a name. A few things (an annotated function parameter, an
annotated-assignment with an RHS) are both a `Definition` and a
`Declaration`.
This more cleanly separates type inference (only cares about
`Definition`) from declared types (only impacted by a `Declaration`),
and I think it will work out better than trying to squeeze everything
into `Definition`. One of the tests in this PR
(`annotation_only_assignment_transparent_to_local_inference`)
demonstrates one reason why. The statement `x: int` should have no
effect on local inference of the type of `x`; whatever the locally
inferred type of `x` was before `x: int` should still be the inferred
type after `x: int`. This is actually quite hard to do if `x: int` is
considered a `Definition`, because a core assumption of the use-def map
is that a `Definition` replaces the previous value. To achieve this
would require some hackery to effectively treat `x: int` sort of as if
it were `x: int = x`, but it's not really even equivalent to that, so
this approach gets quite ugly.
As a first step in this plan, this PR stops treating AnnAssign with no
RHS as a `Definition`, which fixes behavior in a couple added tests.
This actually makes things temporarily worse for the ellipsis-type test,
since it is defined in typeshed only using annotated assignments with no
RHS. This will be fixed properly by the upcoming addition of
declarations, which should also treat a declared type as sufficient to
import a name, at least from a stub.
Initially I had deferred annotation name lookups reuse the "public
symbol type", since that gives the correct "from end of scope" view of
reaching definitions that we want. But there is a key difference; public
symbol types are based only on definitions in the queried scope (or
"name in the given namespace" in runtime terms), they don't ever look up
a name in nonlocal/global/builtin scopes. Deferred annotation resolution
should do this lookup.
Add a test, and fix deferred name resolution to support
nonlocal/global/builtin names.
Fixes#13176
## Summary
Part of #13085, this PR updates the comprehension definition to handle
multiple targets.
## Test Plan
Update existing semantic index test case for comprehension with multiple
targets. Running corpus tests shouldn't panic.
Add support for non-local name lookups.
There's one TODO around annotated assignments without a RHS; these need
a fair amount of attention, which they'll get in an upcoming PR about
declared vs inferred types.
Fixes#11663
Test coverage for #13131 wasn't as good as I thought it was, because
although we infer a lot of types in stubs in typeshed, we don't check
typeshed, and therefore we don't do scope-level inference and pull all
types for a scope. So we didn't really have good test coverage for
scope-level inference in a stub. And because of this, I got the code for
supporting that wrong, meaning that if we did scope-level inference with
deferred types, we'd end up never populating the deferred types in the
scope's `TypeInference`, which causes panics like #13160.
Here I both add test coverage by running the corpus tests both as `.py`
and as `.pyi` (which reveals the panic), and I fix the code to support
deferred types in scope inference.
This also revealed a problem with deferred types in generic functions,
which effectively span two scopes. That problem will require a bit more
thought, and I don't want to block this PR on it, so for now I just
don't defer annotations on generic functions.
Fixes#13160.
## Summary
Follow-up to #13147, this PR implements the `AstNode` for `Identifier`.
This makes it easier to create the `NodeKey` in red knot because it uses
a generic method to construct the key from `AnyNodeRef` and is important
for definitions that are created only on identifiers instead of
`ExprName`.
## Test Plan
`cargo test` and `cargo clippy`
## Summary
This PR adds definition for match patterns.
## Test Plan
Update the existing test case for match statement symbols to verify that
the definitions are added as well.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [quick-junit](https://redirect.github.com/nextest-rs/quick-junit) |
workspace.dependencies | minor | `0.4.0` -> `0.5.0` |
---
### Release Notes
<details>
<summary>nextest-rs/quick-junit (quick-junit)</summary>
###
[`v0.5.0`](https://redirect.github.com/nextest-rs/quick-junit/blob/HEAD/CHANGELOG.md#050---2024-09-01)
[Compare
Source](https://redirect.github.com/nextest-rs/quick-junit/compare/quick-junit-0.4.0...quick-junit-0.5.0)
##### Changed
- The `Output` type, which strips invalid XML characters from a string,
has been renamed to
`XmlString`.
- All internal storage now uses `XmlString` rather than `String`.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOC41Ni4wIiwidXBkYXRlZEluVmVyIjoiMzguNTkuMiIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
The `SequenceIndexVisitor` currently does not recurse into
subexpressions of subscripts when searching for subscript accesses that
would trigger this rule. That means that we don't currently detect
violations of the rule on snippets like this:
```py
data = {"a": 1, "b": 2}
column_names = ["a", "b"]
for index, column_name in enumerate(column_names):
_ = data[column_names[index]]
```
Fixes#13183
## Test Plan
`cargo test -p ruff_linter`
The `UnionBuilder` builds `builtins.bool` when handed `Literal[True]`
and `Literal[False]`.
Caveat: If the builtins module is unfindable somehow, the builder falls
back to the union type of these two literals.
First task from #12694
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Adds basic support for inferring the type resulting from a call
expression. This only works for the *result* of call expressions; it
performs no inference on parameters. It also intentionally does nothing
with class instantiation, `__call__` implementors, or lambdas.
## Test Plan
Adds a test that it infers the right thing!
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
- Introduce methods for inferring annotation and type expressions.
- Correctly infer explicit return types from functions where they are
simple names that can be resolved in scope.
Contributes to #12701 by way of helping unlock call expressions (this
does not remotely finish that, as it stands, but it gets us moving that
direction).
## Test Plan
Added a test for function return types which use the name form of an
annotation expression, since this is aiming toward call expressions.
When we extend this to working for other annotation and type expression
positions, we should add explicit tests for those as well.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Extends deletions for RUF100, deleting trailing text from noqa
directives, while preserving upcoming comments on the same line if any.
In cases where it deletes a comment up to another comment on the same
line, the whitespace between them is now shown to be in the autofix in
the diagnostic as well. Leading whitespace before the removed comment is
not, though.
Fixes#12251
## Test Plan
`cargo test`
Prototype deferred evaluation of type expressions by deferring
evaluation of class bases in a stub file. This allows self-referential
class definitions, as occur with the definition of `str` in typeshed
(which inherits `Sequence[str]`).
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Just what it says on the tin: adds basic `EllipsisType` inference for
any time `...` appears in the AST.
## Test Plan
Test that `x = ...` produces exactly what we would expect.
---------
Co-authored-by: Carl Meyer <carl@oddbird.net>
## Summary
The resulting type when multiplying a string literal by an integer
literal is one of two types:
- `StringLiteral`, in the case where it is a reasonably small resulting
string (arbitrarily bounded here to 4096 bytes, roughly a page on many
operating systems), including the fully expanded string.
- `LiteralString`, matching Pyright etc., for strings larger than that.
Additionally:
- Switch to using `Box<str>` instead of `String` for the internal value
of `StringLiteral`, saving some non-trivial byte overhead (and keeping
the total number of allocations the same).
- Be clearer and more accurate about which types we ought to defer to in
`StringLiteral` and `LiteralString` member lookup.
## Test Plan
Added a test case covering multiplication times integers: positive,
negative, zero, and in and out of bounds.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This fixes the outstanding TODO and make it easier to work with new
cases. (Tidy first, *then* implement, basically!)
## Test Plan
After making this change all the existing tests still pass. A classic
refactor win. 🎉
# Summary
Add support for the first unary operator: negating integer literals. The
resulting type is another integer literal, with the value being the
negated value of the literal. All other types continue to return
`Type::Unknown` for the present, but this is designed to make it easy to
extend easily with other combinations of operator and operand.
Contributes to #12701.
## Test Plan
Add tests with basic negation, including of very large integers and
double negation.
## Summary
Introduce a `StringLiteralType` with corresponding `Display` type and a
relatively basic test that the resulting representation is as expected.
Note: we currently always allocate for `StringLiteral` types. This may
end up being a perf issue later, at which point we may want to look at
other ways of representing `value` here, i.e. with some kind of smarter
string structure which can reuse types. That is most likely to show up
with e.g. concatenation.
Contributes to #12701.
## Test Plan
Added a test for individual strings with both single and double quotes
as well as concatenated strings with both forms.
## Summary
Now that Ruff provides a formatter, there is no need to rely on Black to
check that the docs are formatted correctly in
`check_docs_formatted.py`. This PR swaps out Black for the Ruff
formatter and updates inconsistencies between the two.
This PR will be a precursor to another PR
([branch](https://github.com/calumy/ruff/tree/format-pyi-in-docs)),
updating the `check_docs_formatted.py` script to check for pyi files,
fixing #11568.
## Test Plan
- CI to check that the docs are formatted correctly using the updated
script.
This PR has the `SemanticIndexBuilder` visit function definition
annotations before adding the function symbol/name to the builder.
For example, the following snippet no longer causes a panic:
```python
def bool(x) -> bool:
Return True
```
Note: This fix changes the ordering of the global symbol table.
Closes#13069
## Summary
This PR adds symbols introduced by `for` loops to red-knot:
- `x` in `for x in range(10): pass`
- `x` and `y` in `for x, y in d.items(): pass`
- `a`, `b`, `c` and `d` in `for [((a,), b), (c, d)] in foo: pass`
## Test Plan
Several tests added, and the assertion in the benchmarks has been
updated.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR simplifies the virtual file support in the red knot core,
specifically:
* Update `File::add_virtual_file` method to `File::virtual_file` which
will always create a new virtual file and override the existing entry in
the lookup table
* Add `VirtualFile` which is a wrapper around `File` and provides
methods to increment the file revision / close the virtual file
* Add a new `File::try_virtual_file` to lookup the `VirtualFile` from
`Files`
* Add `File::sync_virtual_path` which takes in the `SystemVirtualPath`,
looks up the `VirtualFile` for it and calls the `sync` method to
increment the file revision
* Removes the `virtual_path_metadata` method on `System` trait
## Test Plan
- [x] Make sure the existing red knot tests pass
- [x] Updated code works well with the LSP
## Summary
This PR adds support for `textDocument/didChange` notification.
There seems to be a bug (probably in Salsa) where it panics with:
```
2024-08-22 15:33:38.802 [info] panicked at /Users/dhruv/.cargo/git/checkouts/salsa-61760caba2b17ca5/f608ff8/src/tracked_struct.rs:377:9:
two concurrent writers to Id(4800), should not be possible
```
## Test Plan
https://github.com/user-attachments/assets/81055feb-ba8e-4acf-ad2f-94084a3efead
## Summary
This PR adds basic support for files outside of any workspace in the red
knot server.
This also limits the red knot server to only work in a single workspace.
The server will not start if there are multiple workspaces.
## Test Plan
https://github.com/user-attachments/assets/de601387-0ad5-433c-9d2c-7b6ae5137654
## Summary
This PR adds the `bytes` type to red-knot:
- Added the `bytes` type
- Added support for bytes literals
- Support for the `+` operator
Improves on #12701
Big TODO on supporting and normalizing r-prefixed bytestrings
(`rb"hello\n"`)
## Test Plan
Added a test for a bytes literals, concatenation, and corner values
The `SemanticIndexBuilder` was causing a cycle in a salsa query by
attempting to resolve the target before the value in a named expression
(e.g. `x := x+1`). This PR swaps the order, avoiding a panic.
Closes#13012.
## Summary
This PR removes notebook sync support from server capabilities because
it isn't tested, it'll be added back once we actually add full support
for notebook.
## Summary
This PR adds symbols and definitions introduced by `with` statements.
The symbols and definitions are introduced for each with item. The type
inference is updated to call the definition region type inference
instead.
## Test Plan
Add test case to check for symbol table and definitions.
## Summary
This PR adds symbols introduced by `match` statements.
There are three patterns that introduces new symbols:
* `as` pattern
* Sequence pattern
* Mapping pattern
The recursive nature of the visitor makes sure that all symbols are
added.
## Test Plan
Add test case for all types of patterns that introduces a symbol.
## Summary
This PR adds definition for augmented assignment. This is similar to
annotated assignment in terms of implementation.
An augmented assignment should also record a use of the variable but
that's a TODO for now.
## Test Plan
Add test case to validate that a definition is added.
## Summary
As suggested by @MichaReiser in
https://github.com/astral-sh/ruff/pull/12886#pullrequestreview-2237679793,
this adds an exemption to `RUF027` for `fastAPI` paths, which require
template strings rather than eagerly evaluated f-strings.
## Test Plan
I added a fixture that causes Ruff to emit a false-positive error on
`main` but no longer does with this PR.
Extend the `UseDefMap` to also track which constraints (provided by e.g.
`if` tests) apply to each visible definition.
Uses a custom `BitSet` and `BitSetArray` to track which constraints
apply to which definitions, while keeping data inline as much as
possible.
## Summary
This PR is a pure refactor to simplify some of the logic for `RUF027`.
This will make it easier to file some followup PRs to help reduce the
false positives from this rule. I'm separating the refactor out into a
separate PR so it's easier to review, and so I can double-check from the
ecosystem report that this doesn't have any user-facing impact.
## Test Plan
`cargo test -p ruff_linter --lib`
## Summary
This PR adds support for adding symbols and definitions for function and
lambda parameters to the semantic index.
### Notes
* The default expression of a parameter is evaluated in the enclosing
scope (not the type parameter or function scope).
* The annotation expression of a parameter is evaluated in the type
parameter scope if they're present other in the enclosing scope.
* The symbols and definitions are added in the function parameter scope.
### Type Inference
There are two definitions `Parameter` and `ParameterWithDefault` and
their respective `*_definition` methods on the type inference builder.
These methods are preferred and are re-used when checking from a
different region.
## Test Plan
Add test case for validating that the parameters are defined in the
function / lambda scope.
### Benchmark update
Validated the difference in diagnostics for benchmark code between
`main` and this branch. All of them are either directly or indirectly
referencing one of the function parameters. The diff is in the PR description.
This adds the `fast-api-unused-path-parameter` lint rule, as described
in #12632.
I'm still pretty new to rust, so the code can probably be improved, feel
free to tell me if there's any changes i should make.
Also, i needed to add the `add_parameter` edit function, not sure if it
was in the scope of the PR or if i should've made another one.
If a builtin is conditionally shadowed by a global, we didn't correctly
fall back to builtins for the not-defined-in-globals path (see added
test for an example.)
List and set comprehensions using `async for` cannot be replaced with
underlying generators; this PR modifies C419 to skip such
comprehensions.
Closes#12891.
## Summary
Occasionally, we receive bug reports that imports in `src` directories
aren't correctly detected. The root of the problem is that we default to
`src = ["."]`, so users have to set `src = ["src"]` explicitly. This PR
extends the default to cover _both_ of them: `src = [".", "src"]`.
Closes https://github.com/astral-sh/ruff/issues/12454.
## Test Plan
I replicated the structure described in
https://github.com/astral-sh/ruff/issues/12453, and verified that the
imports were considered sorted, but that adding `src = ["."]` showed an
error.
## Summary
This PR adds very basic support for using the line / column information
from the diagnostic message. This makes it easier to validate
diagnostics in an editor as oppose to going through the diff one
diagnostic at a time and confirming it at the location.
## Summary
This PR adds a fallback logic for `is_python_notebook` to check the
`kernelspec.language` field.
Reference implementation in VS Code:
1c31e75898/extensions/ipynb/src/deserializers.ts (L20-L22)
It's also required for the kernel to provide the `language` they're
implementing based on
https://jupyter-client.readthedocs.io/en/stable/kernels.html#kernel-specs
reference although that's for the `kernel.json` file but is also
included in the notebook metadata.
Closes: #12281
## Test Plan
Add a test case for `is_python_notebook` and include the test notebook
for round trip validation.
The test notebook contains two cells, one is JavaScript (denoted via the
`vscode.languageId` metadata) and the other is Python (no metadata). The
notebook metadata only contains `kernelspec` and the `language_info` is
absent.
I also verified that this is a valid notebook by opening it in Jupyter
Lab, VS Code and using `nbformat` validator.
## Summary
This PR adds support for VS Code specific cell metadata to consider when
collecting valid code cells.
For context, Ruff only runs on valid code cells. These are the code
cells that doesn't contain cell magics. Previously, Ruff only used the
notebook's metadata to determine whether it's a Python notebook. But, in
VS Code, a notebook's preferred language might be Python but it could
still contain code cells for other languages. This can be determined
with the `metadata.vscode.languageId` field.
### References:
* https://code.visualstudio.com/docs/languages/identifiers
* e6c009a3d4/extensions/ipynb/src/serializers.ts (L104-L107)
*
e6c009a3d4/extensions/ipynb/src/serializers.ts (L117-L122)
This brings us one step closer to fixing #12281.
## Test Plan
Add test cases for `is_valid_python_code_cell` and an integration test
case which showcase running it end to end. The test notebook contains a
JavaScript code cell and a Python code cell.
## Summary
This PR fixes a bug in the semantic model where it would evaluate the
default parameter value in the type parameter scope. For example,
```py
def foo[T1: int](a = T1):
pass
```
Here, the `T1` in `a = T1` is undefined but Ruff doesn't flag it
(https://play.ruff.rs/ba2f7c2f-4da6-417e-aa2a-104aa63e6d5e).
The fix here is to evaluate the default parameter value in the
_enclosing_ scope instead.
## Test Plan
Add a test case which includes the above code under `F821`
(`undefined-name`) and validate the snapshot.
## Summary
See #12703. This only addresses the first bullet point, adding a space
after the comma in the suggested fix from list/tuple to string.
## Test Plan
Updated the snapshots and compared.
## Summary
This PR adds scope and definition for comprehension nodes. This includes
the following nodes:
* List comprehension
* Dictionary comprehension
* Set comprehension
* Generator expression
### Scope
Each expression here adds it's own scope with one caveat - the `iter`
expression of the first generator is part of the parent scope. For
example, in the following code snippet the `iter1` variable is evaluated
in the outer scope.
```py
[x for x in iter1]
```
> The iterable expression in the leftmost for clause is evaluated
directly in the enclosing scope and then passed as an argument to the
implicitly nested scope.
>
> Reference:
https://docs.python.org/3/reference/expressions.html#displays-for-lists-sets-and-dictionaries
There's another special case for assignment expressions:
> There is one special case: an assignment expression occurring in a
list, set or dict comprehension or in a generator expression (below
collectively referred to as “comprehensions”) binds the target in the
containing scope, honoring a nonlocal or global declaration for the
target in that scope, if one exists.
>
> Reference: https://peps.python.org/pep-0572/#scope-of-the-target
For example, in the following code snippet, the variables `a` and `b`
are available after the comprehension while `x` isn't:
```py
[a := 1 for x in range(2) if (b := 2)]
```
### Definition
Each comprehension node adds a single definition, the "target" variable
(`[_ for target in iter]`). This has been accounted for and a new
variant has been added to `DefinitionKind`.
### Type Inference
Currently, type inference is limited to a single scope. It doesn't
_enter_ in another scope to infer the types of the remaining expressions
of a node. To accommodate this, the type inference for a **scope**
requires new methods which _doesn't_ infer the type of the `iter`
expression of the leftmost outer generator (that's defined in the
enclosing scope).
The type inference for the scope region is split into two parts:
* `infer_generator_expression` (similarly for comprehensions) infers the
type of the `iter` expression of the leftmost outer generator
* `infer_generator_expression_scope` (similarly for comprehension)
infers the type of the remaining expressions except for the one
mentioned in the previous point
The type inference for the **definition** also needs to account for this
special case of leftmost generator. This is done by defining a `first`
boolean parameter which indicates whether this comprehension definition
occurs first in the enclosing expression.
## Test Plan
New test cases were added to validate multiple scenarios. Refer to the
documentation for each test case which explains what is being tested.
Make `cargo doc -p red_knot_python_semantic --document-private-items`
run warning-free. I'd still like to do this for all of ruff and start
enforcing it in CI (https://github.com/astral-sh/ruff/issues/12372) but
haven't gotten to it yet. But in the meantime I'm trying to maintain it
for at least `red_knot_python_semantic`, as it helps to ensure our doc
comments stay up to date.
A few of the comments I just removed or shortened, as their continued
relevance wasn't clear to me; please object in review if you think some
of them are important to keep!
Also remove a no-longer-needed `allow` attribute.
For type narrowing, we'll need intersections (since applying type
narrowing is just a type intersection.)
Add `IntersectionBuilder`, along with some tests for it and
`UnionBuilder` (renamed from `UnionTypeBuilder`).
We use smart builders to ensure that we always keep these types in
disjunctive normal form (DNF). That means that we never have deeply
nested trees of unions and intersections: unions flatten into unions,
intersections flatten into intersections, and intersections distribute
over unions, so the most complex tree we can ever have is a union of
intersections. We also never have a single-element union or a
single-positive-element intersection; these both just simplify to the
contained type.
Maintaining these invariants means that `UnionBuilder` doesn't
necessarily end up building a `Type::Union` (e.g. if you only add a
single type to the union, it'll just return that type instead), and
`IntersectionBuilder` doesn't necessarily build a `Type::Intersection`
(if you add a union to the intersection, we distribute the intersection
over that union, and `IntersectionBuilder` will end up returning a
`Type::Union` of intersections).
We also simplify intersections by ensuring that if a type and its
negation are both in an intersection, they simplify out. (In future this
should also respect subtyping, not just type identity, but we don't have
subtyping yet.) We do implement subtyping of `Never` as a special case
for now.
Most of this PR is unused for now until type narrowing lands; I'm just
breaking it out to reduce the review fatigue of a single massive PR.
## Summary
I'm not sure if this is useful but this is a hacky implementation to add
the filename and row / column numbers to the current Red Knot
diagnostics.
## Summary
Related to https://github.com/astral-sh/ruff-vscode/issues/571, this PR
updates the settings index builder to trace all the errors it
encountered. Without this, there's no way for user to know that
something failed and some of the capability might not work as expected.
For example, in the linked PR, the settings were invalid which means
notebooks weren't included and there were no log messages for it.
## Test Plan
Create an invalid `ruff.toml` file:
```toml
[tool.ruff]
extend-exclude = ["*.ipynb"]
```
Logs:
```
2024-08-12 18:33:09.873 [info] [Trace - 6:33:09 PM] 12.217043000s ERROR ruff:main ruff_server::session::index::ruff_settings: Failed to parse /Users/dhruv/playground/ruff/pyproject.toml
```
Notification Preview:
<img width="483" alt="Screenshot 2024-08-12 at 18 33 20"
src="https://github.com/user-attachments/assets/a4f303e5-f073-454f-bdcd-ba6af511e232">
Another way to trigger is to provide an invalid `cache-dir` value:
```toml
[tool.ruff]
cache-dir = "$UNKNOWN"
```
Same notification preview but different log message:
```
2024-08-12 18:41:37.571 [info] [Trace - 6:41:37 PM] 21.700112208s ERROR ThreadId(30) ruff_server::session::index::ruff_settings: Error while resolving settings from /Users/dhruv/playground/ruff/pyproject.toml: Invalid `cache-dir` value: error looking key 'UNKNOWN' up: environment variable not found
```
With multiple `pyproject.toml` file:
```
2024-08-12 18:41:15.887 [info] [Trace - 6:41:15 PM] 0.016636833s ERROR ThreadId(04) ruff_server::session::index::ruff_settings: Error while resolving settings from /Users/dhruv/playground/ruff/pyproject.toml: Invalid `cache-dir` value: error looking key 'UNKNOWN' up: environment variable not found
2024-08-12 18:41:15.888 [info] [Trace - 6:41:15 PM] 0.017378833s ERROR ThreadId(13) ruff_server::session::index::ruff_settings: Failed to parse /Users/dhruv/playground/ruff/tools/pyproject.toml
```
In most cases we should suggest a ternary operator, but there are three
edge cases where a binary operator is more appropriate.
Given an if-else block of the form
```python
if test:
target_var = body_value
else:
target_var = else_value
```
This PR updates the check for SIM108 to the following:
- If `test == body_value` and preview enabled, suggest to replace with
`target_var = test or else_value`
- If `test == not body_value` and preview enabled, suggest to replace
with `target_var = body_value and else_value`
- If `not test == body_value` and preview enabled, suggest to replace
with `target_var = body_value and else_value`
- Otherwise, suggest to replace with `target_var = body_value if test
else else_value`
Closes#12189.
## Summary
Adding parentheses to a tuple in a subscript with elements that include
slice expressions causes a syntax error. For example, `d[(1,2,:)]` is a
syntax error.
So, when `lint.ruff.parenthesize-tuple-in-subscript = true` and the
tuple includes a slice expression, we skip this check and fix.
Closes#12766.
> ~Builtins are also more efficient than `for` loops.~
Let's not promise performance because this code transformation does not
deliver.
Benchmark written by @dcbaker
> `any()` seems to be about 1/3 as fast (Python 3.11.9, NixOS):
```python
loop = 'abcdef'.split()
found = 'f'
nfound = 'g'
def test1():
for x in loop:
if x == found:
return True
return False
def test2():
return any(x == found for x in loop)
def test3():
for x in loop:
if x == nfound:
return True
return False
def test4():
return any(x == nfound for x in loop)
if __name__ == "__main__":
import timeit
print('for loop (found) :', timeit.timeit(test1))
print('for loop (not found):', timeit.timeit(test3))
print('any() (found) :', timeit.timeit(test2))
print('any() (not found) :', timeit.timeit(test4))
```
```
for loop (found) : 0.051076093994197436
for loop (not found): 0.04388196699437685
any() (found) : 0.15422860698890872
any() (not found) : 0.15568504799739458
```
I have retested with longer lists and on multiple Python versions with
similar results.
Implements the new fixable lint rule `RUF031` which checks for the use or omission of parentheses around tuples in subscripts, depending on the setting `lint.ruff.parenthesize-tuple-in-getitem`. By default, the use of parentheses is considered a violation.
## Summary
Follow-up from https://github.com/astral-sh/ruff/pull/12725, this is
just a small refactor to use a wrapper struct instead of type alias for
workspace settings index. This avoids the need to have the
`register_workspace_settings` as a static method on `Index` and instead
is a method on the new struct itself.
## Summary
This PR updates the server to ignore non-file workspace URL.
This is to avoid crashing the server if the URL scheme is not "file".
We'd still raise an error if the URL to file path conversion fails.
Also, as per the docs of
[`to_file_path`](https://docs.rs/url/2.5.2/url/struct.Url.html#method.to_file_path):
> Note: This does not actually check the URL’s scheme, and may give
nonsensical results for other schemes. It is the user’s responsibility
to check the URL’s scheme before calling this.
resolves: #12660
## Test Plan
I'm not sure how to test this locally but the change is small enough to
validate on its own.
## Summary
This PR updates the `red_knot` CLI to make the subcommand optional.
## Test Plan
Run the following commands:
* `cargo run --bin red_knot --
--current-directory=~/playground/ruff/type_inference` (no subcommand
requirement)
* `cargo run --bin red_knot -- server` (should start the server)
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves#12636
Consider docstrings which begin with the word "Returns" as having
satisfactorily documented they're returns. For example
```python
def f():
"""Returns 1."""
return 1
```
is valid.
## Test Plan
Added example to test fixture.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Removes set comprehension as a violation for `sum` when checking `C419`,
because set comprehension may de-duplicate entries in a generator,
thereby modifying the value of the sum.
Closes#12690.
## Summary
Make it a violation of `C409` to call `tuple` with a list or set
comprehension, and
implement the (unsafe) fix of calling the `tuple` with the underlying
generator instead.
Closes#12648.
## Test Plan
Test fixture updated, cargo test, docs checked for updated description.
## Summary
Adds autofix for `RUF007`
## Test Plan
`cargo test`, however I get errors for `test resolver::tests::symlink
... FAILED` which seems to not be my fault
## Summary
Fixes#12630.
DOC501 and DOC502 now understand functions with constructs like this to
be explicitly raising `TypeError` (which should be documented in a
function's docstring):
```py
try:
foo():
except TypeError:
...
raise
```
I made an exception for `Exception` and `BaseException`, however.
Constructs like this are reasonably common, and I don't think anybody
would say that it's worth putting in the docstring that it raises "some
kind of generic exception":
```py
try:
foo()
except BaseException:
do_some_logging()
raise
```
## Test Plan
`cargo test -p ruff_linter --lib`
## Summary
Please see
https://github.com/astral-sh/ruff/pull/12605#discussion_r1699957443 for
a description of the issue.
They way I fixed it is to get the *last* timeout item in the `with`, and
if it's an `async with` and there are items after it, then don't trigger
the lint.
## Test Plan
Updated the fixture with some more cases.
Changes the red-knot benchmark to run on the stdlib "tomllib" library
(which is self-contained, four files, uses type annotations) instead of
on very small bits of handwritten code.
Also remove the `without_parse` benchmark: now that we are running on
real code that uses typeshed, we'd either have to pre-parse all of
typeshed (slow) or find some way to determine which typeshed modules
will be used by the benchmark (not feasible with reasonable complexity.)
## Test Plan
`cargo bench -p ruff_benchmark --bench red_knot`
## Summary
This PR separates the current `red_knot` crate into two crates:
1. `red_knot` - This will be similar to the `ruff` crate, it'll act as
the CLI crate
2. `red_knot_workspace` - This includes everything except for the CLI
functionality from the existing `red_knot` crate
Note that the code related to the file watcher is in
`red_knot_workspace` for now but might be required to extract it out in
the future.
The main motivation for this change is so that we can have a `red_knot
server` command. This makes it easier to test the server out without
making any changes in the VS Code extension. All we need is to specify
the `red_knot` executable path in `ruff.path` extension setting.
## Test Plan
- `cargo build`
- `cargo clippy --workspace --all-targets --all-features`
- `cargo shear --fix`
## Summary
There's still a problem here. Given:
```python
class Class():
pass
# comment
# another comment
a = 1
```
We only add one newline before `a = 1` on the first pass, because
`max_precedling_blank_lines` is 1... We then add the second newline on
the second pass, so it ends up in the right state, but the logic is
clearly wonky.
Closes https://github.com/astral-sh/ruff/issues/11508.
I hit this `todo!` trying to run type inference over some real modules.
Since it's a one-liner to implement it, I just did that rather than
changing to `Type::Unknown`.
## Summary
@zanieb noticed while we were discussing #12595 that this flag is now
unnecessary, so remove it and the flags which reference it.
## Test Plan
Question for maintainers: is there a test to add *or* remove here? (I’ve
opened this as a draft PR with that in view!)
## Summary
This pull request adds support for logging via `$/logTrace` RPC
messages. It also enables that code path for when a client is Zed editor
or VS Code (as there's no way for us to generically tell whether a client prefers
`$/logTrace` over stderr.
Related to: #12523
## Test Plan
I've built Ruff from this branch and tested it manually with Zed.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Extend `flake8-builtins` to imports, lambda-arguments, and modules to be
consistent with original checker
[flake8_builtins](https://github.com/gforcada/flake8-builtins/blob/main/flake8_builtins.py).
closes#12540
## Details
- Implement builtin-import-shadowing (A004)
- Stop tracking imports shadowing in builtin-variable-shadowing (A001)
in preview mode.
- Implement builtin-lambda-argument-shadowing (A005)
- Implement builtin-module-shadowing (A006)
- Add new option `linter.flake8_builtins.builtins_allowed_modules`
## Test Plan
cargo test
## Summary
If an import is marked as "required", we should never flag it as unused.
In practice, this is rare, since required imports are typically used for
`__future__` annotations, which are always considered "used".
Closes https://github.com/astral-sh/ruff/issues/12458.
Now that we have builtins available, resolve some simple cases to the
right builtin type.
We should also adjust the display for types to include their module
name; that's not done yet here.
## Summary
This PR adds support for untitled files in the Red Knot project.
Refer to the [design
discussion](https://github.com/astral-sh/ruff/discussions/12336) for
more details.
### Changes
* The `parsed_module` always assumes that the `SystemVirtual` path is of
`PySourceType::Python`.
* For the module resolver, as suggested, I went ahead by adding a new
`SystemOrVendoredPath` enum and renamed `FilePathRef` to
`SystemOrVendoredPathRef` (happy to consider better names here).
* The `file_to_module` query would return if it's a
`FilePath::SystemVirtual` variant because a virtual file doesn't belong
to any module.
* The sync implementation for the system virtual path is basically the
same as that of system path except that it uses the
`virtual_path_metadata`. The reason for this is that the system
(language server) would provide the metadata on whether it still exists
or not and if it exists, the corresponding metadata.
For point (1), VS Code would use `Untitled-1` for Python files and
`Untitled-1.ipynb` for Jupyter Notebooks. We could use this distinction
to determine whether the source type is `Python` or `Ipynb`.
## Test Plan
Added test cases in #12526
Extend red-knot type inference to cover all syntax, so that inferring
types for a scope gives all expressions a type. This means we can run
the red-knot semantic lint on all Python code without panics. It also
means we can infer types for `builtins.pyi` without panics.
To keep things simple, this PR intentionally doesn't add any new type
inference capabilities: the expanded coverage is all achieved with
`Type::Unknown`. But this puts the skeleton in place for adding better
inference of all these language features.
I also had to add basic Salsa cycle recovery (with just `Type::Unknown`
for now), because some `builtins.pyi` definitions are cyclic.
To test this, I added a comprehensive corpus of test snippets sourced
from Cinder under [MIT
license](https://github.com/facebookincubator/cinder/blob/cinder/3.10/cinderx/LICENSE),
which matches Ruff's license. I also added to this corpus some
additional snippets for newer language features: all the
`27_func_generic_*` and `73_class_generic_*` files, as well as
`20_lambda_default_arg.py`, and added a test which runs semantic-lint
over all these files. (The test doesn't assert the test-corpus files are
lint-free; just that they are able to lint without a panic.)
## Summary
Right now, in the isort comment model, there's nowhere for trailing
comments on the _statement_ to go, as in:
```python
from mylib import (
MyClient,
MyMgmtClient,
) # some comment
```
If the comment is on the _alias_, we do preserve it, because we attach
it to the alias, as in:
```python
from mylib import (
MyClient,
MyMgmtClient, # some comment
)
```
Similarly, if the comment is trailing on an import statement
(non-`from`), we again attach it to the alias, because it can't be
parenthesized, as in:
```python
import foo # some comment
```
This PR adds logic to track and preserve those trailing comments.
We also no longer drop several other comments, like:
```python
from mylib import (
# some comment
MyClient
)
```
Closes https://github.com/astral-sh/ruff/issues/12487.
## Summary
When working on improving Ruff integration with Zed I noticed that it
errors out when we try to resolve a code action of a `QUICKFIX` kind;
apparently, per @dhruvmanila we shouldn't need to resolve it, as the
edit is provided in the initial response for the code action. However,
it's possible for the `resolve` call to fill out other fields (such as
`command`).
AFAICT Helix also tries to resolve the code actions unconditionally (as
in, when either `edit` or `command` is absent); so does VSC. They can
still apply the quickfixes though, as they do not error out on a failed
call to resolve code actions - Zed does. Following suit on Zed's side
does not cut it though, as we still get a log request from Ruff for that
failure (which is surfaced in the UI).
There are also other language servers (such as
[rust-analyzer](c1c9e10f72/crates/rust-analyzer/src/handlers/request.rs (L1257)))
that fill out both `command` and `edit` fields as a part of code action
resolution.
This PR makes the resolve calls for quickfix actions return the input
value.
## Test Plan
N/A
Add support for while-loop control flow.
This doesn't yet include general support for terminals and reachability;
that is wider than just while loops and belongs in its own PR.
This also doesn't yet add support for cyclic definitions in loops; that
comes with enough of its own complexity in Salsa that I want to handle
it separately.
Add a lint rule to detect if a name is definitely or possibly undefined
at a given usage.
If I create the file `undef/main.py` with contents:
```python
x = int
def foo():
z
return x
if flag:
y = x
y
```
And then run `cargo run --bin red_knot -- --current-directory
../ruff-examples/undef`, I get the output:
```
Name 'z' used when not defined.
Name 'flag' used when not defined.
Name 'y' used when possibly not defined.
```
If I modify the file to add `y = 0` at the top, red-knot re-checks it
and I get the new output:
```
Name 'z' used when not defined.
Name 'flag' used when not defined.
```
Note that `int` is not flagged, since it's a builtin, and `return x` in
the function scope is not flagged, since it refers to the global `x`.
## Summary
This PR fixes a bug to raise a syntax error when an unparenthesized
generator expression is used as an argument to a call when there are
more than one argument.
For reference, the grammar is:
```
primary:
| ...
| primary genexp
| primary '(' [arguments] ')'
| ...
genexp:
| '(' ( assignment_expression | expression !':=') for_if_clauses ')'
```
The `genexp` requires the parenthesis as mentioned in the grammar. So,
the grammar for a call expression is either a name followed by a
generator expression or a name followed by a list of argument. In the
former case, the parenthesis are excluded because the generator
expression provides them while in the later case, the parenthesis are
explicitly provided for a list of arguments which means that the
generator expression requires it's own parenthesis.
This was discovered in https://github.com/astral-sh/ruff/issues/12420.
## Test Plan
Add test cases for valid and invalid syntax.
Make sure that the parser from CPython also raises this at the parsing
step:
```console
$ python3.13 -m ast parser/_.py
File "parser/_.py", line 1
total(1, 2, x for x in range(5), 6)
^^^^^^^^^^^^^^^^^^^
SyntaxError: Generator expression must be parenthesized
$ python3.13 -m ast parser/_.py
File "parser/_.py", line 1
sum(x for x in range(10), 10)
^^^^^^^^^^^^^^^^^^^^
SyntaxError: Generator expression must be parenthesized
```
## Summary
Fix panic reported in #12428. Where a string would sometimes get split
within a character boundary. This bypasses the need to split the string.
This does not guarantee the correct formatting of the docstring, but
neither did the previous implementation.
Resolves#12428
## Test Plan
Test case added to fixture
## Summary
These are the first rules implemented as part of #458, but I plan to
implement more.
Specifically, this implements `docstring-missing-exception` which checks
for raised exceptions not documented in the docstring, and
`docstring-extraneous-exception` which checks for exceptions in the
docstring not present in the body.
## Test Plan
Test fixtures added for both google and numpy style.
When poring over traces, the ones that just include a definition or
symbol or expression ID aren't very useful, because you don't know which
file it comes from. This adds that information to the trace.
I guess the downside here is that if calling `.file(db)` on a
scope/definition/expression would execute other traced code, it would be
marked as outside the span? I don't think that's a concern, because I
don't think a simple field access on a tracked struct should ever
execute our code. If I'm wrong and this is a problem, it seems like the
tracing crate has this feature where you can record a field as
`tracing::field::Empty` and then fill in its value later with
`span.record(...)`, but when I tried this it wasn't working for me, not
sure why.
I think there's a lot more we can do to make our tracing output more
useful for debugging (e.g. record an event whenever a
definition/symbol/expression/use id is created with the details of that
definition/symbol/expression/use), this is just dipping my toes in the
water.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR updates D301 rule to allow inclduing escaped docstring, e.g.
`\"""Foo.\"""` or `\"\"\"Bar.\"\"\"`, within a docstring.
Related issue: #12152
## Test Plan
Add more test cases to D301.py and update the snapshot file.
<!-- How was it tested? -->
In preparation for supporting resolving builtins, simplify the benchmark
so it doesn't look up `str`, which is actually a complex builtin to deal
with because it inherits `Sequence[str]`.
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
Per comments in https://github.com/astral-sh/ruff/pull/12269, "module
global" is kind of long, and arguably redundant.
I tried just using "module" but there were too many cases where I felt
this was ambiguous. I like the way "global" works out better, though it
does require an understanding that in Python "global" generally means
"module global" not "globally global" (though in a sense module globals
are also globally global since modules are singletons).
Support falling back to a global name lookup if a name isn't defined in
the local scope, in the cases where that is correct according to Python
semantics.
In class scopes, a name lookup checks the local namespace first, and if
the name isn't found there, looks it up in globals.
In function scopes (and type parameter scopes, which are function-like),
if a name has any definitions in the local scope, it is a local, and
accessing it when none of those definitions have executed yet just
results in an `UnboundLocalError`, it does not fall back to a global. If
the name does not have any definitions in the local scope, then it is an
implicit global.
Public symbol type lookups never include such a fall back. For example,
if a name is not defined in a class scope, it is not available as a
member on that class, even if a name lookup within the class scope would
have fallen back to a global lookup.
This PR makes the `@override` lint rule work again.
Not yet included/supported in this PR:
* Support for free variables / closures: a free symbol in a nested
function-like scope referring to a symbol in an outer function-like
scope.
* Support for `global` and `nonlocal` statements, which force a symbol
to be treated as global or nonlocal even if it has definitions in the
local scope.
* Module-global lookups should fall back to builtins if the name isn't
found in the module scope.
I would like to expose nicer APIs for the various kinds of symbols
(explicit global, implicit global, free, etc), but this will also wait
for a later PR, when more kinds of symbols are supported.
Adds inference tests sufficient to give full test coverage of the
`UseDefMapBuilder::merge` method.
In the process I realized that we could implement visiting of if
statements in `SemanticBuilder` with fewer `snapshot`, `restore`, and
`merge` operations, so I restructured that visit a bit.
I also found one correctness bug in the `merge` method (it failed to
extend the given snapshot with "unbound" for any missing symbols,
meaning we would just lose the fact that the symbol could be unbound in
the merged-in path), and two efficiency bugs (if one of the ranges to
merge is empty, we can just use the other one, no need for copies, and
if the ranges are overlapping -- which can occur with nested branches --
we can still just merge them with no copies), and fixed all three.
## Summary
This PR allows us to fix both expressions in `foo == "a" or foo == "b"
or ("c" != bar and "d" != bar)`, but limits the rule to consecutive
comparisons, following https://github.com/astral-sh/ruff/issues/7797.
I think this logic was _probably_ added because of
https://github.com/astral-sh/ruff/pull/12368 -- the intent being that
we'd replace the _entire_ expression.
## Summary
This PR adds documentation for the Ruff language server.
It mainly does the following:
1. Combines various READMEs containing instructions for different editor
setup in their respective section on the online docs
2. Provide an enumerated list of server settings. Additionally, it also
provides a section for VS Code specific options.
3. Adds a "Features" section which enumerates all the current
capabilities of the native server
For (2), the settings documentation is done manually but a future
improvement (easier after `ruff-lsp` is deprecated) is to move the docs
in to Rust struct and generate the documentation from the code itself.
And, the VS Code extension specific options can be generated by diffing
against the `package.json` in `ruff-vscode` repository.
### Structure
1. Setup: This section contains the configuration for setting up the
language server for different editors
2. Features: This section contains a list of capabilities provided by
the server along with short GIF to showcase it
3. Settings: This section contains an enumerated list of settings in a
similar format to the one for the linter / formatter
4. Migrating from `ruff-lsp`
> [!NOTE]
>
> The settings page is manually written but could possibly be
auto-generated via a macro similar to `OptionsMetadata` on the
`ClientSettings` struct
resolves: #11217
## Test Plan
Generate and open the documentation locally using:
1. `python scripts/generate_mkdocs.py`
2. `mkdocs serve -f mkdocs.insiders.yml`
## Summary
This PR removes the requirement of `--preview` flag to run the `ruff
server` and instead considers it to be an indicator to turn on preview
mode for the linter and the formatter.
resolves: #12161
## Test Plan
Add test cases to assert the `preview` value is updated accordingly.
In an editor context, I used the local `ruff` executable in Neovim with
the `--preview` flag and verified that the preview-only violations are
being highlighted.
Running with:
```lua
require('lspconfig').ruff.setup({
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
})
```
The screenshot shows that `E502` is highlighted with the below config in
`pyproject.toml`:
<img width="877" alt="Screenshot 2024-07-17 at 16 43 09"
src="https://github.com/user-attachments/assets/c7016ef3-55b1-4a14-bbd3-a07b1bcdd323">
## Summary
This PR updates the settings index building logic in the language server
to consider the fallback settings for applying ignore filters in
`WalkBuilder` and the exclusion via `exclude` / `extend-exclude`.
This flow matches the one in the `ruff` CLI where the root settings is
built by (1) finding the workspace setting in the ancestor directory (2)
finding the user configuration if that's missing and (3) fallback to
using the default configuration.
Previously, the index building logic was being executed before (2) and
(3). This PR reverses the logic so that the exclusion /
`respect_gitignore` is being considered from the default settings if
there's no workspace / user settings. This has the benefit that the
server no longer enters the `.git` directory or any other excluded
directory when a user opens a file in the home directory.
Related to #11366
## Test plan
Opened a test file from the home directory and confirmed with the debug
trace (removed in #12360) that the server excludes the `.git` directory
when indexing.
## Summary
Add new rule and implement for `unnecessary default type arguments`
under the `UP` category (`UP043`).
```py
// < py313
Generator[int, None, None]
// >= py313
Generator[int]
```
I think that as Python 3.13 develops, there might be more default type
arguments added besides `Generator` and `AsyncGenerator`. So, I made
this more flexible to accommodate future changes.
related issue: #12286
## Test Plan
snapshot included..!
## Summary
Pretty sure this should still be an error, but also, I think I added
this because of ecosystem CI? So want to see what pops up.
Closes https://github.com/astral-sh/ruff/issues/12164.
## Summary
This is the _intended_ default that PEP 597 _wants_, but it's not
backwards compatible. The fix is already unsafe, so it's better for us
to recommend the desired and expected behavior.
Closes https://github.com/astral-sh/ruff/issues/12069.
Improve semantic index tests with better assertions than just `.len()`,
and re-add use-definition test that was commented out in the switch to
Salsa initially.
Implements definition-level type inference, with basic control flow
(only if statements and if expressions so far) in Salsa.
There are a couple key ideas here:
1) We can do type inference queries at any of three region
granularities: an entire scope, a single definition, or a single
expression. These are represented by the `InferenceRegion` enum, and the
entry points are the salsa queries `infer_scope_types`,
`infer_definition_types`, and `infer_expression_types`. Generally
per-scope will be used for scopes that we are directly checking and
per-definition will be used anytime we are looking up symbol types from
another module/scope. Per-expression should be uncommon: used only for
the RHS of an unpacking or multi-target assignment (to avoid
re-inferring the RHS once per symbol defined in the assignment) and for
test nodes in type narrowing (e.g. the `test` of an `If` node). All
three queries return a `TypeInference` with a map of types for all
definitions and expressions within their region. If you do e.g.
scope-level inference, when it hits a definition, or an
independently-inferable expression, it should use the relevant query
(which may already be cached) to get all types within the smaller
region. This avoids double-inferring smaller regions, even though larger
regions encompass smaller ones.
2) Instead of building a control-flow graph and lazily traversing it to
find definitions which reach a use of a name (which is O(n^2) in the
worst case), instead semantic indexing builds a use-def map, where every
use of a name knows which definitions can reach that use. We also no
longer track all definitions of a symbol in the symbol itself; instead
the use-def map also records which defs remain visible at the end of the
scope, and considers these the publicly-visible definitions of the
symbol (see below).
Major items left as TODOs in this PR, to be done in follow-up PRs:
1) Free/global references aren't supported yet (only lookup based on
definitions in current scope), which means the override-check example
doesn't currently work. This is the first thing I'll fix as follow-up to
this PR.
2) Control flow outside of if statements and expressions.
3) Type narrowing.
There are also some smaller relevant changes here:
1) Eliminate `Option` in the return type of member lookups; instead
always return `Type::Unbound` for a name we can't find. Also use
`Type::Unbound` for modules we can't resolve (not 100% sure about this
one yet.)
2) Eliminate the use of the terms "public" and "root" to refer to
module-global scope or symbols. Instead consistently use the term
"module-global". It's longer, but it's the clearest, and the most
consistent with typical Python terminology. In particular I don't like
"public" for this use because it has other implications around author
intent (is an underscore-prefixed module-global symbol "public"?). And
"root" is just not commonly used for this in Python.
3) Eliminate the `PublicSymbol` Salsa ingredient. Many non-module-global
symbols can also be seen from other scopes (e.g. by a free var in a
nested scope, or by class attribute access), and thus need to have a
"public type" (that is, the type not as seen from a particular use in
the control flow of the same scope, but the type as seen from some other
scope.) So all symbols need to have a "public type" (here I want to keep
the use of the term "public", unless someone has a better term to
suggest -- since it's "public type of a symbol" and not "public symbol"
the confusion with e.g. initial underscores is less of an issue.) At
least initially, I would like to try not having special handling for
module-global symbols vs other symbols.
4) Switch to using "definitions that reach end of scope" rather than
"all definitions" in determining the public type of a symbol. I'm
convinced that in general this is the right way to go. We may want to
refine this further in future for some free-variable cases, but it can
be changed purely by making changes to the building of the use-def map
(the `public_definitions` index in it), without affecting any other
code. One consequence of combining this with no control-flow support
(just last-definition-wins) is that some inference tests now give more
wrong-looking results; I left TODO comments on these tests to fix them
when control flow is added.
And some potential areas for consideration in the future:
1) Should `symbol_ty` be a Salsa query? This would require making all
symbols a Salsa ingredient, and tracking even more dependencies. But it
would save some repeated reconstruction of unions, for symbols with
multiple public definitions. For now I'm not making it a query, but open
to changing this in future with actual perf evidence that it's better.
## Summary
I believe these should always bind more tightly -- e.g., in:
```python
for _ in bar(baz for foo in [1]):
pass
```
The inner `baz` and `foo` should be considered comprehension variables,
not for loop bindings.
We need to revisit this more holistically. In some of these cases,
`BindingKind` should probably be a flag, not an enum, since the values
aren't mutually exclusive. Separately, we should probably be more
precise in how we set it (e.g., by passing down from the parent rather
than sniffing in `handle_node_store`).
Closes https://github.com/astral-sh/ruff/issues/12339
When there is a function or class definition at the end of a suite
followed by the beginning of an alternative block, we have to insert a
single empty line between them.
In the if-else-statement example below, we insert an empty line after
the `foo` in the if-block, but none after the else-block `foo`, since in
the latter case the enclosing suite already adds empty lines.
```python
if sys.version_info >= (3, 10):
def foo():
return "new"
else:
def foo():
return "old"
class Bar:
pass
```
To do so, we track whether the current suite is the last one in the
current statement with a new option on the suite kind.
Fixes#12199
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR updates the server to build the settings index in parallel using
similar logic as `python_files_in_path`.
This should help with https://github.com/astral-sh/ruff/issues/11366 but
ideally we would want to build it lazily.
## Test Plan
`cargo insta test`
## Summary
I don't know that there's more to do here. We could consider not raising
the violation at all for arguments, but that would have some false
negatives and could also be surprising to users.
Closes https://github.com/astral-sh/ruff/issues/12267.
## Summary
Ensures that, e.g., the following is not considered a
redefinition-without-use:
```python
import contextlib
foo = None
with contextlib.suppress(ImportError):
from some_module import foo
```
Closes https://github.com/astral-sh/ruff/issues/12309.
## Summary
Closes https://github.com/astral-sh/ruff/issues/12291.
## Test Plan
```shell
❯ cargo run check ../uv/foo --select INP
/Users/crmarsh/workspace/uv/foo/bar/baz.py:1:1: INP001 File `/Users/crmarsh/workspace/uv/foo/bar/baz.py` is part of an implicit namespace package. Add an `__init__.py`.
Found 1 error.
```
## Summary
I don't fully understand the purpose of this. In #7905, it was just
copied over from the previous non-preview implementation. But it means
that (e.g.) we don't treat `type(self.foo)` as a type -- which is wrong.
Closes https://github.com/astral-sh/ruff/issues/12290.
## Summary
Update the name of `ASYNC109` to match
[upstream](https://flake8-async.readthedocs.io/en/latest/rules.html).
Also update to the functionality to match upstream by supporting
additional context managers from `asyncio` and `anyio`. This doesn't
change any of the detection functionality, but recommends additional
context managers from `asyncio` and `anyio` depending on context.
Part of https://github.com/astral-sh/ruff/issues/12039.
## Test Plan
Added fixture for asyncio recommendation
## Summary
S113 exists because `requests` doesn't have a default timeout, so
request without timeout may hang indefinitely
> B113: Test for missing requests timeout
This plugin test checks for requests or httpx calls without a timeout
specified.
>
> Nearly all production code should use this parameter in nearly all
requests, **Failure to do so can cause your program to hang
indefinitely.**
But httpx has default timeout 5s, so S113 for httpx request without
`timeout` argument is a false positive, only valid case would be
`timeout=None`.
https://www.python-httpx.org/advanced/timeouts/
> HTTPX is careful to enforce timeouts everywhere by default.
>
> The default behavior is to raise a TimeoutException after 5 seconds of
network inactivity.
## Test Plan
snap updated
Intern types using Salsa interning instead of in the `TypeInference`
result.
This eliminates the need for `TypingContext`, and also paves the way for
finer-grained type inference queries.
## Summary
This PR fixes the bug where the server was not considering the
`cells.structure.didOpen` field to sync up the new content of the newly
added cells.
The parameters corresponding to this request provides two fields to get
the newly added cells:
1. `cells.structure.array.cells`: This is a list of `NotebookCell` which
doesn't contain any cell content. The only useful information from this
array is the cell kind and the cell document URI which we use to
initialize the new cell in the index.
2. `cells.structure.didOpen`: This is a list of `TextDocumentItem` which
corresponds to the newly added cells. This actually contains the text
content and the version.
This wasn't a problem before because we initialize the cell with an
empty string and this isn't a problem when someone just creates an empty
cell. But, when someone copy-pastes a cell, the cell needs to be
initialized with the content.
fixes: #12201
## Test Plan
First, let's see the panic in action:
1. Press <kbd>Esc</kbd> to allow using the keyboard to perform cell
actions (move around, copy, paste, etc.)
2. Copy the second cell with <kbd>c</kbd> key
3. Delete the second cell with <kbd>dd</kbd> key
4. Paste the copied cell with <kbd>p</kbd> key
You can see that the content isn't synced up because the `unused-import`
for `sys` is still being highlighted but it's being used in the second
cell. And, the hover isn't working either. Then, as I start editing the
second cell, it panics.
https://github.com/astral-sh/ruff/assets/67177269/fc58364c-c8fc-4c11-a917-71b6dd90c1ef
Now, here's the preview of the fixed version:
https://github.com/astral-sh/ruff/assets/67177269/207872dd-dca6-49ee-8b6e-80435c7ef22e
This reverts commit b28dc9ac14.
We're not ready to stabilize the server yet. There's some pending work
for the VS Code extension and documentation improvements.
This change is to unblock Ruff release.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This is the implementation for the new rule of `pycodestyle (E204)`. It
follows the guidlines described in the contributing site, and as such it
has a new file named `whitespace_after_decorator.rs`, a new test file
called `E204.py`, and as such invokes the `function` in the `AST
statement checker` for functions and functions in classes. Linking #2402
because it has all the pycodestyle rules.
## Test Plan
<!-- How was it tested? -->
The file E204.py, has a `decorator` defined called wrapper, and this
decorator is used for 2 cases. The first one is when a `function` which
has a `decorator` is called in the file, and the second one is when
there is a `class` and 2 `methods` are defined for the `class` with a
`decorator` attached it.
Test file:
``` python
def foo(fun):
def wrapper():
print('before')
fun()
print('after')
return wrapper
# No error
@foo
def bar():
print('bar')
# E204
@ foo
def baz():
print('baz')
class Test:
# No error
@foo
def bar(self):
print('bar')
# E204
@ foo
def baz(self):
print('baz')
```
I am still new to rust and any suggestion is appreciated. Specially with
the way im using native ruff utilities.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Fixes a few typos and consistency issues in the "Settings"
documentation:
- use "Ruff" consistently in the few places where "ruff" is used
- use double quotes in the few places where single quotes are used
- add backticks around rule codes where they are currently missing
- update a few example values where they are the same as the defaults,
for consistency
2nd commit might be controversial, as there are many options mentioned
where we don't currently link to the documentation sections, so maybe
it's done on purpose, as this will also appear in the JSON schema where
it's not desirable? If that's the case, I can easily drop it.
## Test Plan
Local testing.
## Summary
This PR fixes various bugs for computing the replacement range between
the original and modified source for the language server.
1. When finding the end offset of the source and modified range, we
should apply `zip` on the reversed iterator. The bug was that it was
reversing the already zipped iterator. The problem here is that the
length of both slices aren't going to be the same unless the source
wasn't modified at all. Refer to the [Rust
playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=44f860d31bd26456f3586b6ab530c22f)
where you can see this in action.
2. Skip the first line when computing the start offset because the first
line start value will always be 0 and the default value of the source /
modified range start is also 0. So, comparing 0 and 0 is not useful
which means we can skip the first value.
3. While iterating in the reverse direction, we should only stop if the
line start is strictly less than the source start i.e., we should use
`<` instead of `<=`.
fixes: #12128
## Test Plan
Add test cases where the text is being inserted, deleted, and replaced
between the original and new source code, validate the replacement
ranges.
## Summary
Bandit now also reports `B113` on `httpx`
(https://github.com/PyCQA/bandit/pull/1060). This PR implements the same
logic, to detect missing or `None` timeouts for `httpx` alongside
`requests`.
## Test Plan
Snapshot tests.
Closes https://github.com/astral-sh/ruff/issues/12158
Hashing `Path` does not take into account path separators so `foo/bar`
is the same as `foobar` which is no good for our case. I'm guessing this
is an upstream bug, perhaps introduced by
45082b077b?
I'm investigating that further.
## Summary
This PR updates the linter, specifically the token-based rules, to work
on the tokens that come after a syntax error.
For context, the token-based rules only diagnose the tokens up to the
first lexical error. This PR builds up an error resilience by
introducing a `TokenIterWithContext` which updates the `nesting` level
and tries to reflect it with what the lexer is seeing. This isn't 100%
accurate because if the parser recovered from an unclosed parenthesis in
the middle of the line, the context won't reduce the nesting level until
it sees the newline token at the end of the line.
resolves: #11915
## Test Plan
* Add test cases for a bunch of rules that are affected by this change.
* Run the fuzzer for a long time, making sure to fix any other bugs.
## Summary
This PR updates Ruff to **not** generate auto-fixes if the source code
contains syntax errors as determined by the parser.
The main motivation behind this is to avoid infinite autofix loop when
the token-based rules are run over any source with syntax errors in
#11950.
Although even after this, it's not certain that there won't be an
infinite autofix loop because the logic might be incorrect. For example,
https://github.com/astral-sh/ruff/issues/12094 and
https://github.com/astral-sh/ruff/pull/12136.
This requires updating the test infrastructure to not validate for fix
availability status when the source contained syntax errors. This is
required because otherwise the fuzzer might fail as it uses the test
function to run the linter and validate the source code.
resolves: #11455
## Test Plan
`cargo insta test`
## Summary
This PR updates various references in the linter to compute the
line-width for summing the width of each `char` in a `str` instead of
computing the width of the `str` itself.
Refer to #12133 for more details.
fixes: #12130
## Test Plan
Add a file with null (`\0`) character which is zero-width. Run this test
case on `main` to make sure it panics and switch over to this branch to
make sure it doesn't panic now.
## Summary
Use the following to reproduce this:
```console
$ cargo run -- check --select=E275,E203 --preview --no-cache ~/playground/ruff/src/play.py --fix
debug error: Failed to converge after 100 iterations in `/Users/dhruv/playground/ruff/src/play.py` with rule codes E275:---
yield,x
---
/Users/dhruv/playground/ruff/src/play.py:1:1: E275 Missing whitespace after keyword
|
1 | yield,x
| ^^^^^ E275
|
= help: Added missing whitespace after keyword
Found 101 errors (100 fixed, 1 remaining).
[*] 1 fixable with the `--fix` option.
```
## Test Plan
Add a test case and run `cargo insta test`.
## Summary
This patch inverts the defaults for
[pytest-fixture-incorrect-parentheses-style
(PT001)](https://docs.astral.sh/ruff/rules/pytest-fixture-incorrect-parentheses-style/)
and [pytest-incorrect-mark-parentheses-style
(PT003)](https://docs.astral.sh/ruff/rules/pytest-incorrect-mark-parentheses-style/)
to prefer dropping superfluous parentheses.
Presently, Ruff defaults to adding superfluous parentheses on pytest
mark and fixture decorators for documented purpose of consistency; for
example,
```diff
import pytest
-@pytest.mark.foo
+@pytest.mark.foo()
def test_bar(): ...
```
This behaviour is counter to the official pytest recommendation and
diverges from the flake8-pytest-style plugin as of version 2.0.0 (see
https://github.com/m-burst/flake8-pytest-style/issues/272). Seeing as
either default satisfies the documented benefit of consistency across a
codebase, it makes sense to change the behaviour to be consistent with
pytest and the flake8 plugin as well.
This change is breaking, so is gated behind preview (at least under my
understanding of Ruff versioning). The implementation of this gating
feature is a bit hacky, but seemed to be the least disruptive solution
without performing invasive surgery on the `#[option()]` macro.
Related to #8796.
### Caveat
Whilst updating the documentation, I sought to reference the pytest
recommendation to drop superfluous parentheses, but couldn't find any
official instruction beyond it being a revealed preference within the
pytest documentation code examples (as well as the linked issues from a
core pytest developer). Thus, the wording of the preference is
deliberately timid; it's to cohere with pytest rather than follow an
explicit guidance.
## Test Plan
`cargo nextest run`
I also ran
```sh
cargo run -p ruff -- check crates/ruff_linter/resources/test/fixtures/flake8_pytest_style/PT001.py --no-cache --diff --select PT001
```
and compared against it with `--preview` to verify that the default does
change under preview (I also repeated this with `echo
'[tool.ruff]\npreview = true' > pyproject.toml` to verify that it works
with a configuration file).
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Implement mutable-contextvar-default (B039) which was added to
flake8-bugbear in https://github.com/PyCQA/flake8-bugbear/pull/476.
This rule is similar to [mutable-argument-default
(B006)](https://docs.astral.sh/ruff/rules/mutable-argument-default) and
[function-call-in-default-argument
(B008)](https://docs.astral.sh/ruff/rules/function-call-in-default-argument),
except that it checks the `default` keyword argument to
`contextvars.ContextVar`.
```
B039.py:19:26: B039 Do not use mutable data structures for ContextVar defaults
|
18 | # Bad
19 | ContextVar("cv", default=[])
| ^^ B039
20 | ContextVar("cv", default={})
21 | ContextVar("cv", default=list())
|
= help: Replace with `None`; initialize with `.set()` after checking for `None`
```
In the upstream flake8-plugin, this rule is written expressly as a
corollary to B008 and shares much of its logic. Likewise, this
implementation reuses the logic of the Ruff implementation of B008,
namely
f765d19402/crates/ruff_linter/src/rules/flake8_bugbear/rules/function_call_in_argument_default.rs (L104-L106)
and
f765d19402/crates/ruff_linter/src/rules/flake8_bugbear/rules/mutable_argument_default.rs (L106)
Thus, this rule deliberately replicates B006's and B008's heuristics.
For example, this rule assumes that all functions are mutable unless
otherwise qualified. If improvements are to be made to B039 heuristics,
they should probably be made to B006 and B008 as well (whilst trying to
match the upstream implementation).
This rule does not have an autofix as it is unknown where the ContextVar
next used (and it might not be within the same file).
Closes#12054
## Test Plan
`cargo nextest run`
## Summary
This adds a fix for the `duplicate-bases` rule that removes the
duplicate base from the class definition.
## Test Plan
`cargo nextest run duplicate_bases`, `cargo insta review`.
## Summary
`ruff server` has reached a point of stabilization, and `--preview` is
no longer required as a flag.
`--preview` is still supported as a flag, since future features may be
need to gated behind it initially.
## Test Plan
A simple way to test this is to run `ruff server` from the command line.
No error about a missing `--preview` argument should be reported.
## Summary
Follow-up to #11902
This PR simplifies the `LinterResult` struct by avoiding the generic and
not store the `ParseError`.
This is possible because the callers already have access to the
`ParseError` via the `Parsed` output. This also means that we can
simplify the return type of `check_path` and avoid the generic `T` on
`LinterResult`.
## Test Plan
`cargo insta test`
## Summary
Follow-up to #11901
This PR avoids displaying the syntax errors as log message now that the
`E999` diagnostic cannot be disabled.
For context on why this was added, refer to
https://github.com/astral-sh/ruff/pull/2505. Basically, we would allow
ignoring the syntax error diagnostic because certain syntax feature
weren't supported back then like `match` statement. And, if a user
ignored `E999`, Ruff would give no feedback if the source code contained
any syntax error. So, this log message was a way to indicate to the user
even if `E999` was disabled.
The current state of the parser is such that (a) it matches with the
latest grammar and (b) it's easy to add support for any new syntax.
**Note:** This PR doesn't remove the `DisplayParseError` struct because
it's still being used by the formatter.
## Test Plan
Update existing snapshots from the integration tests.
## Summary
This PR updates the way syntax errors are handled throughout the linter.
The main change is that it's now not considered as a rule which involves
the following changes:
* Update `Message` to be an enum with two variants - one for diagnostic
message and the other for syntax error message
* Provide methods on the new message enum to query information required
by downstream usages
This means that the syntax errors cannot be hidden / disabled via any
disablement methods. These are:
1. Configuration via `select`, `ignore`, `per-file-ignores`, and their
`extend-*` variants
```console
$ cargo run -- check ~/playground/ruff/src/lsp.py --extend-select=E999
--no-preview --no-cache
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.10s
Running `target/debug/ruff check /Users/dhruv/playground/ruff/src/lsp.py
--extend-select=E999 --no-preview --no-cache`
warning: Rule `E999` is deprecated and will be removed in a future
release. Syntax errors will always be shown regardless of whether this
rule is selected or not.
/Users/dhruv/playground/ruff/src/lsp.py:1:8: F401 [*] `abc` imported but
unused
|
1 | import abc
| ^^^ F401
2 | from pathlib import Path
3 | import os
|
= help: Remove unused import: `abc`
```
3. Command-line flags via `--select`, `--ignore`, `--per-file-ignores`,
and their `--extend-*` variants
```console
$ cargo run -- check ~/playground/ruff/src/lsp.py --no-cache
--config=~/playground/ruff/pyproject.toml
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.11s
Running `target/debug/ruff check /Users/dhruv/playground/ruff/src/lsp.py
--no-cache --config=/Users/dhruv/playground/ruff/pyproject.toml`
warning: Rule `E999` is deprecated and will be removed in a future
release. Syntax errors will always be shown regardless of whether this
rule is selected or not.
/Users/dhruv/playground/ruff/src/lsp.py:1:8: F401 [*] `abc` imported but
unused
|
1 | import abc
| ^^^ F401
2 | from pathlib import Path
3 | import os
|
= help: Remove unused import: `abc`
```
This also means that the **output format** needs to be updated:
1. The `code`, `noqa_row`, `url` fields in the JSON output is optional
(`null` for syntax errors)
2. Other formats are changed accordingly
For each format, a new test case specific to syntax errors have been
added. Please refer to the snapshot output for the exact format for
syntax error message.
The output of the `--statistics` flag will have a blank entry for syntax
errors:
```
315 F821 [ ] undefined-name
119 [ ] syntax-error
103 F811 [ ] redefined-while-unused
```
The **language server** is updated to consider the syntax errors by
convert them into LSP diagnostic format separately.
### Preview
There are no quick fixes provided to disable syntax errors. This will
automatically work for `ruff-lsp` because the `noqa_row` field will be
`null` in that case.
<img width="772" alt="Screenshot 2024-06-26 at 14 57 08"
src="https://github.com/astral-sh/ruff/assets/67177269/aaac827e-4777-4ac8-8c68-eaf9f2c36774">
Even with `noqa` comment, the syntax error is displayed:
<img width="763" alt="Screenshot 2024-06-26 at 14 59 51"
src="https://github.com/astral-sh/ruff/assets/67177269/ba1afb68-7eaf-4b44-91af-6d93246475e2">
Rule documentation page:
<img width="1371" alt="Screenshot 2024-06-26 at 16 48 07"
src="https://github.com/astral-sh/ruff/assets/67177269/524f01df-d91f-4ac0-86cc-40e76b318b24">
## Test Plan
- [x] Disablement methods via config shows a warning
- [x] `select`, `extend-select`
- [ ] ~`ignore`~ _doesn't show any message_
- [ ] ~`per-file-ignores`, `extend-per-file-ignores`~ _doesn't show any
message_
- [x] Disablement methods via command-line flag shows a warning
- [x] `--select`, `--extend-select`
- [ ] ~`--ignore`~ _doesn't show any message_
- [ ] ~`--per-file-ignores`, `--extend-per-file-ignores`~ _doesn't show
any message_
- [x] File with syntax errors should exit with code 1
- [x] Language server
- [x] Should show diagnostics for syntax errors
- [x] Should not recommend a quick fix edit for adding `noqa` comment
- [x] Same for `ruff-lsp`
resolves: #8447
The motivation for this rule is solid; it's been in preview for a long
time; the implementation and tests seem sound; there are no open issues
regarding it, and as far as I can tell there never have been any.
The only issue I see is that the docs don't really describe the rule
accurately right now; I fix that in this PR.
## Summary
This PR migrates our release workflow to
[`cargo-dist`](https://github.com/axodotdev/cargo-dist). The primary
motivation here is that we want to ship dedicated installers for Ruff
that work across platforms, and `cargo-dist` gives us those installers
out-of-the-box. The secondary motivation is that `cargo-dist` formalizes
some of the patterns that we've built up over time in our own release
process.
At a high level:
- The `release.yml` file is generated by `cargo-dist` with `cargo dist
generate`. It doesn't contain any modifications vis-a-vis the generated
file. (If it's edited out of band from generation, the release fails.)
- Our customizations are inserted as custom steps within the
`cargo-dist` workflow. Specifically, `build-binaries` builds the wheels
and packages them into binaries (as on `main`), while `build-docker.yml`
builds the Docker image. `publish-pypi.yml` publishes the wheels to
PyPI. This is effectively our `release.yaml` (on `main`), broken down
into individual workflows rather than steps within a single workflow.
### Changes from `main`
The workflow is _nearly_ unchanged. We kick off a release manually via
the GitHub Action by providing a tag. If the tag doesn't match the
`Cargo.toml`, the release fails. If the tag matches an already-existing
release, the release fails.
The release proceeds by (in order):
0. Doing some upfront validation via `cargo-dist`.
1. Creating the wheels and archives.
2. Building and pushing the Docker image.
3. Publishing to PyPI (if it's not a "dry run").
4. Creating the GitHub Release (if it's not a "dry run").
5. Notifying `ruff-pre-commit` (if it's not a "dry run").
There are a few changes in the workflow as compared to `main`:
- **We no longer validate the SHA** (just the tag). It's not an input to
the job. The Axo team is considering whether / how to support this.
- **Releases are now published directly** (rather than as draft). Again,
the Axo team is considering whether / how to support this. The downside
of drafts is that the URLs aren't stable, so the installers don't work
_as long as the release is in draft_. This is fine for our workflow. It
seems like the Axo team will add it.
- Releases already contain the latest entry from the changelog (we don't
need to copy it over). This "Just Works", which is nice, though we'll
still want to edit them to add contributors.
There are also a few **breaking changes** for consumers of the binaries:
- **We no longer include the version tag in the file name**. This
enables users to install via `/latest` URLs on GitHub, and is part of
the cargo-dist paradigm.
- **Archives now include an extra level of nesting,** which you can
remove with `--strip-components=1` when untarring.
Here's an example release that I created -- I omitted all the artifacts
since I was just testing a workflow, so none of the installers or links
work, but it gives you a sense for what the release looks like:
https://github.com/charliermarsh/cargodisttest/releases/tag/0.1.13.
### Test Plan
I ran a successful release to completion last night, and installed Ruff
via the installer:


The piece I'm least confident about is the Docker push. We build the
image, but the push fails in my test repo since I haven't wired up the
credentials.
## Summary
This rule removes `PLR1701` and redirects it to `SIM101`.
In addition to that, the `SIM101` autofix has been fixed to add padding
if required.
### `PLR1701` has bugs
It also seems that the implementation of `PLR1701` is incorrect in
multiple scenarios. For example, the following code snippet:
```py
# There are two _different_ variables `a` and `b`
if isinstance(a, int) or isinstance(b, bool) or isinstance(a, float):
pass
# There's another condition `or 1`
if isinstance(self.k, int) or isinstance(self.k, float) or 1:
pass
```
is fixed to:
```py
# Fixed to only considering variable `a`
if isinstance(a, (float, int)):
pass
# The additional condition is not present in the fix
if isinstance(self.k, (float, int)):
pass
```
Playground: https://play.ruff.rs/6cfbdfb7-f183-43b0-b59e-31e728b34190
## Documentation Preview
### `PLR1701`
<img width="1397" alt="Screenshot 2024-06-25 at 11 14 40"
src="https://github.com/astral-sh/ruff/assets/67177269/779ee84d-7c4d-4bb8-a3a4-c2b23a313eba">
## Test Plan
Remove the test cases for `PLR1701`, port the padding test case to
`SIM101` and update the snapshot.
## Summary
This PR splits the re-lexing logic into two parts:
1. `TokenSource`: The token source will be responsible to find the
position the lexer needs to be moved to
2. `Lexer`: The lexer will be responsible to reduce the nesting level
and move itself to the new position if recovered from a parenthesized
context
This split makes it easy to find the new lexer position without needing
to implement the backwards lexing logic again which would need to handle
cases involving:
* Different kinds of newlines
* Line continuation character(s)
* Comments
* Whitespaces
### F-strings
This change did reveal one thing about re-lexing f-strings. Consider the
following example:
```py
f'{'
# ^
f'foo'
```
Here, the quote as highlighted by the caret (`^`) is the start of a
string inside an f-string expression. This is unterminated string which
means the token emitted is actually `Unknown`. The parser tries to
recover from it but there's no newline token in the vector so the new
logic doesn't recover from it. The previous logic does recover because
it's looking at the raw characters instead.
The parser would be at `FStringStart` (the one for the second line) when
it calls into the re-lexing logic to recover from an unterminated
f-string on the first line. So, moving backwards the first character
encountered is a newline character but the first token encountered is an
`Unknown` token.
This is improved with #12067fixes: #12046fixes: #12036
## Test Plan
Update the snapshot and validate the changes.
## Summary
This PR fixes the lexer logic to **not** consume the newline character
for an unterminated string literal.
Currently, the lexer would consume it to be part of the string itself
but that would be bad for recovery because then the lexer wouldn't emit
the newline token ever. This PR fixes that to avoid consuming the
newline character in that case.
This was discovered during https://github.com/astral-sh/ruff/pull/12060.
## Test Plan
Update the snapshots and validate them.
## Summary
This PR fixes a bug introduced in
https://github.com/astral-sh/ruff/pull/12008 which didn't consider the
two character newline after the line continuation character.
For example, consider the following code highlighted with whitespaces:
```py
call(foo # comment \\r\n
\r\n
def bar():\r\n
....pass\r\n
```
The lexer is at `def` when it's running the re-lexing logic and trying
to move back to a newline character. It encounters `\n` and it's being
escaped (incorrect) but `\r` is being escaped, so it moves the lexer to
`\n` character. This creates an overlap in token ranges which causes the
panic.
```
Name 0..4
Lpar 4..5
Name 5..8
Comment 9..20
NonLogicalNewline 20..22 <-- overlap between
Newline 21..22 <-- these two tokens
NonLogicalNewline 22..23
Def 23..26
...
```
fixes: #12028
## Test Plan
Add a test case with line continuation and windows style newline
character.
## Summary
(I'm pretty sure I added this in the parser re-write but must've got
lost in the rebase?)
This PR raises a syntax error if the type parameter list is empty.
As per the grammar, there should be at least one type parameter:
```
type_params:
| invalid_type_params
| '[' type_param_seq ']'
type_param_seq: ','.type_param+ [',']
```
Verified via the builtin `ast` module as well:
```console
$ python3.13 -m ast parser/_.py
Traceback (most recent call last):
[..]
File "parser/_.py", line 1
def foo[]():
^
SyntaxError: Type parameter list cannot be empty
```
## Test Plan
Add inline test cases and update the snapshots.
## Summary
Right now, it's inconsistent... We sometimes match against the name, and
sometimes against the alias (`asname`). I could see a case for always
matching against the name, but matching against both seems fine too,
since the rule is really about the combination of the two?
Closes https://github.com/astral-sh/ruff/issues/12031.
## Summary
This PR fixes a bug where Ruff would raise `E203` for f-string debug
expression. This isn't valid because whitespaces are important for debug
expressions.
fixes: #12023
## Test Plan
Add test case and make sure there are no snapshot changes.
## Summary
This PR updates the parser test infrastructure to validate the token
ranges.
From the code documentation:
```
/// Verifies that:
/// * the ranges are strictly increasing when loop the tokens in insertion order
/// * all ranges are within the length of the source code
```
Follow-up from #12016 and #12017resolves: #11938
## Test Plan
Make sure that there are no failures.
## Summary
This PR updates the unterminated string error range to not include the
final newline character.
This is a follow-up to #12016 and required for #12019
This is not done for when the unterminated string goes till the end of
file (not a newline character). The unterminated f-string range is
correct.
### Why is this required for #12019 ?
Because otherwise the token ranges will overlap. For example:
```py
f"{"
f"{foo!r"
```
Here, the re-lexing logic recovers from an unterminated f-string and
thus emitting a `Newline` token for the one at the end of the first
line. But, currently the `Unknown` and the `Newline` token would overlap
because the `Unknown` token (unterminated string literal) range would
include the newline character.
## Test Plan
Update and validate the snapshot.
## Summary
This PR fixes the range highlighted for the line continuation error.
Previously, it would highlight an incorrect range:
```
1 | call(a, b, \\\
| ^^ Syntax Error: unexpected character after line continuation character
2 |
3 | def bar():
|
```
And now:
```
|
1 | call(a, b, \\\
| ^ Syntax Error: unexpected character after line continuation character
2 |
3 | def bar():
|
```
This is implemented by avoiding to update the token range for the
`Unknown` token which is emitted when there's a lexical error. Instead,
the `push_error` helper method will be responsible to update the range
to the error location.
This actually becomes a requirement which can be seen in follow-up PRs.
## Test Plan
Update and validate the snapshot.
## Summary
This PR fixes a bug where the re-lexing logic didn't consider the line
continuation character being present before the newline character. This
meant that the lexer was being moved back to the newline character which
is actually ignored via `\`.
Considering the following code:
```py
f'middle {'string':\
'format spec'}
```
The old token stream is:
```
...
Colon 18..19
FStringMiddle 19..29 (flags = F_STRING)
Newline 20..21
Indent 21..29
String 29..42
Rbrace 42..43
...
```
Notice how the ranges are overlapping between the `FStringMiddle` token
and the tokens emitted after moving the lexer backwards.
After this fix, the new token stream which is without moving the lexer
backwards in this scenario:
```
FStringStart 0..2 (flags = F_STRING)
FStringMiddle 2..9 (flags = F_STRING)
Lbrace 9..10
String 10..18
Colon 18..19
FStringMiddle 19..29 (flags = F_STRING)
FStringEnd 29..30 (flags = F_STRING)
Name 30..36
Name 37..41
Unknown 41..44
Newline 44..45
```
fixes: #12004
## Test Plan
Add test cases and update the snapshots.
## Summary
This PR updates `F811` rule to include assignment as possible shadowed
binding. This will fix issue: #11828 .
## Test Plan
Add a test file, F811_30.py, which includes a redefinition after an
assignment and a verified snapshot file.
## Summary
Addresses #11974 to add a `RUF` rule to replace `print` expressions in
`assert` statements with the inner message.
An autofix is available, but is considered unsafe as it changes
behaviour of the execution, notably:
- removal of the printout in `stdout`, and
- `AssertionError` instance containing a different message.
While the detection of the condition is a straightforward matter,
deciding how to resolve the print arguments into a string literal can be
a relatively subjective matter. The implementation of this PR chooses to
be as tolerant as possible, and will attempt to reformat any number of
`print` arguments containing single or concatenated strings or variables
into either a string literal, or a f-string if any variables or
placeholders are detected.
## Test Plan
`cargo test`.
## Examples
For ease of discussion, this is the diff for the tests:
```diff
# Standard Case
# Expects:
# - single StringLiteral
-assert True, print("This print is not intentional.")
+assert True, "This print is not intentional."
# Concatenated string literals
# Expects:
# - single StringLiteral
-assert True, print("This print" " is not intentional.")
+assert True, "This print is not intentional."
# Positional arguments, string literals
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", "is not intentional")
+assert True, "This print is not intentional"
# Concatenated string literals combined with Positional arguments
# Expects:
# - single stringliteral concatenated with " " only between `print` and `is`
-assert True, print("This " "print", "is not intentional.")
+assert True, "This print is not intentional."
# Positional arguments, string literals with a variable
# Expects:
# - single FString concatenated with " "
-assert True, print("This", print.__name__, "is not intentional.")
+assert True, f"This {print.__name__} is not intentional."
# Mixed brackets string literals
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", 'is not intentional', """and should be removed""")
+assert True, "This print is not intentional and should be removed"
# Mixed brackets with other brackets inside
# Expects:
# - single StringLiteral concatenated with " " and escaped brackets
-assert True, print("This print", 'is not "intentional"', """and "should" be 'removed'""")
+assert True, "This print is not \"intentional\" and \"should\" be 'removed'"
# Positional arguments, string literals with a separator
# Expects:
# - single StringLiteral concatenated with "|"
-assert True, print("This print", "is not intentional", sep="|")
+assert True, "This print|is not intentional"
# Positional arguments, string literals with None as separator
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", "is not intentional", sep=None)
+assert True, "This print is not intentional"
# Positional arguments, string literals with variable as separator, needs f-string
# Expects:
# - single FString concatenated with "{U00A0}"
-assert True, print("This print", "is not intentional", sep=U00A0)
+assert True, f"This print{U00A0}is not intentional"
# Unnecessary f-string
# Expects:
# - single StringLiteral
-assert True, print(f"This f-string is just a literal.")
+assert True, "This f-string is just a literal."
# Positional arguments, string literals and f-strings
# Expects:
# - single FString concatenated with " "
-assert True, print("This print", f"is not {'intentional':s}")
+assert True, f"This print is not {'intentional':s}"
# Positional arguments, string literals and f-strings with a separator
# Expects:
# - single FString concatenated with "|"
-assert True, print("This print", f"is not {'intentional':s}", sep="|")
+assert True, f"This print|is not {'intentional':s}"
# A single f-string
# Expects:
# - single FString
-assert True, print(f"This print is not {'intentional':s}")
+assert True, f"This print is not {'intentional':s}"
# A single f-string with a redundant separator
# Expects:
# - single FString
-assert True, print(f"This print is not {'intentional':s}", sep="|")
+assert True, f"This print is not {'intentional':s}"
# Complex f-string with variable as separator
# Expects:
# - single FString concatenated with "{U00A0}", all placeholders preserved
condition = "True is True"
maintainer = "John Doe"
-assert True, print("Unreachable due to", condition, f", ask {maintainer} for advice", sep=U00A0)
+assert True, f"Unreachable due to{U00A0}{condition}{U00A0}, ask {maintainer} for advice"
# Empty print
# Expects:
# - `msg` entirely removed from assertion
-assert True, print()
+assert True
# Empty print with separator
# Expects:
# - `msg` entirely removed from assertion
-assert True, print(sep=" ")
+assert True
# Custom print function that actually returns a string
# Expects:
@@ -100,4 +100,4 @@
# Use of `builtins.print`
# Expects:
# - single StringLiteral
-assert True, builtins.print("This print should be removed.")
+assert True, "This print should be removed."
```
## Known Issues
The current implementation resolves all arguments and separators of the
`print` expression into a single string, be it
`StringLiteralValue::single` or a `FStringValue::single`. This:
- potentially joins together strings well beyond the ideal character
limit for each line, and
- does not preserve multi-line strings in their original format, in
favour of a single line `"...\n...\n..."` format.
These are purely formatting issues only occurring in unusual scenarios.
Additionally, the autofix will tolerate `print` calls that were
previously invalid:
```python
assert True, print("this", "should not be allowed", sep=42)
```
This will be transformed into
```python
assert True, f"this{42}should not be allowed"
```
which some could argue is an alteration of behaviour.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Documentation mentions:
> PEP 563 enabled the use of a number of convenient type annotations,
such as `list[str]` instead of `List[str]`
but it meant [PEP 585](https://peps.python.org/pep-0585/) instead.
[PEP 563](https://peps.python.org/pep-0563/) is the one defining `from
__future__ import annotations`.
## Test Plan
No automated test required, just verify that
https://peps.python.org/pep-0585/ is the correct reference.
## Summary
I look at the token stream a lot, not specifically in the playground but
in the terminal output and it's annoying to scroll a lot to find
specific location. Most of the information is also redundant.
The final format we end up with is: `<kind> <range> (flags = ...)` e.g.,
`String 0..4 (flags = BYTE_STRING)` where the flags part is only
populated if there are any flags set.
## Summary
Fixes#11651.
Fixes#11851.
We were double-closing a notebook document from the index, once in
`textDocument/didClose` and then in the `notebookDocument/didClose`
handler. The second time this happens, taking a snapshot fails.
I've rewritten how we handle snapshots for closing notebooks / notebook
cells so that any failure is simply logged instead of propagating
upwards. This implementation works consistently even if we don't receive
`textDocument/didClose` notifications for each specific cell, since they
get closed (and the diagnostics get cleared) in the notebook document
removal process.
## Test Plan
1. Open an untitled, unsaved notebook with the `Create: New Jupyter
Notebook` command from the VS Code command palette (`Ctrl/Cmd + Shift +
P`)
2. Without saving the document, close it.
3. No error popup should appear.
4. Run the debug command (`Ruff: print debug information`) to confirm
that there are no open documents
## Summary
This PR does some housekeeping into moving certain structs into related
modules. Specifically,
1. Move `LexicalError` from `lexer.rs` to `error.rs` which also contains
the `ParseError`
2. Move `Token`, `TokenFlags` and `TokenValue` from `lexer.rs` to
`token.rs`
## Summary
This PR removes the duplication around `is_trivia` functions.
There are two of them in the codebase:
1. In `pycodestyle`, it's for newline, indent, dedent, non-logical
newline and comment
2. In the parser, it's for non-logical newline and comment
The `TokenKind::is_trivia` method used (1) but that's not correct in
that context. So, this PR introduces a new `is_non_logical_token` helper
method for the `pycodestyle` crate and updates the
`TokenKind::is_trivia` implementation with (2).
This also means we can remove `Token::is_trivia` method and the
standalone `token_source::is_trivia` function and use the one on
`TokenKind`.
## Test Plan
`cargo insta test`
## Summary
Closes#11914.
This PR introduces a snapshot test that replays the LSP requests made
during a document formatting request, and confirms that the notebook
document is updated in the expected way.
## Summary
Fixes#11911.
`shellexpand` is now used on `logFile` to expand the file path, allowing
the usage of `~` and environment variables.
## Test Plan
1. Set `logFile` in either Neovim or Helix to a file path that needs
expansion, like `~/.config/helix/ruff_logs.txt`.
2. Ensure that `RUFF_TRACE` is set to `messages` or `verbose`
3. Open a Python file in Neovim/Helix
4. Confirm that a file at the path specified was created, with the
expected logs.
## Summary
This PR updates the logical line rules entry-point function to only run
the logic if any of the rules within that group is enabled.
Although this shouldn't really give any performance improvements, it's
better not to do additional work if we can. This is also consistent with
how other rules are run.
## Test Plan
`cargo insta test`
## Summary
This PR avoids moving back the lexer for a triple-quoted f-string during
the re-lexing phase.
The reason this is a problem is that for a triple-quoted f-string the
newlines are part of the f-string itself, specifically they'll be part
of the `FStringMiddle` token. So, if we moved the lexer back, there
would be a `Newline` token whose range would be in between an
`FStringMiddle` token. This creates a panic in downstream usage.
fixes: #11937
## Test Plan
Add test cases and validate the snapshots.
## Summary
This PR avoids the `depth` counter when detecting indentation from
non-logical lines because it seems to never be used. It might have been
a leftover when the logic was added originally in #11608.
## Test Plan
`cargo insta test`
## Summary
This PR updates the linter to show all the parse errors as diagnostics
instead of just the first one.
Note that this doesn't affect the parse error displayed as error log
message. This will be removed in a follow-up PR.
### Breaking?
I don't think this is a breaking change even though this might give more
diagnostics. The main reason is that this shouldn't affect any users
because it'll only give additional diagnostics in the case of multiple
syntax errors.
## Test Plan
Add an integration test case which would raise more than one parse
error.
## Summary
This PR updates the re-lexing logic to avoid consuming the trailing
whitespace and move the lexer explicitly to the last newline character
encountered while moving backwards.
Consider the following code snippet as taken from the test case
highlighted with whitespace (`.`) and newline (`\n`) characters:
```py
# There are trailing whitespace before the newline character but those whitespaces are
# part of the comment token
f"""hello {x # comment....\n
# ^
y = 1\n
```
The parser is at `y` when it's trying to recover from an unclosed `{`,
so it calls into the re-lexing logic which tries to move the lexer back
to the end of the previous line. But, as it consumed all whitespaces it
moved the lexer to the location marked by `^` in the above code snippet.
But, those whitespaces are part of the comment token. This means that
the range for the two tokens were overlapping which introduced the
panic.
Note that this is only a bug when there's a comment with a trailing
whitespace otherwise it's fine to move the lexer to the whitespace
character. This is because the lexer would just skip the whitespace
otherwise. Nevertheless, this PR updates the logic to move it explicitly
to the newline character in all cases.
fixes: #11929
## Test Plan
Add test cases and update the snapshot. Make sure that it doesn't panic
on the code snippet in the linked issue.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
related to https://github.com/astral-sh/ruff/issues/5306
The check right now only checks in the first 1024 bytes, and that's
really not enough when there's a docstring at the beginning of a file.
A more proper fix might be needed, which might be more complex (and I
don't have the `rust` skills to implement that). But this temporary
"fix" might enable more users to use this.
Context: We want to use this rule in
https://github.com/scikit-learn/scikit-learn/ and we got blocked because
of this hardcoded rule (which TBH took us quite a while to figure out
why it was failing since it's not documented).
## Test Plan
This is already kinda tested, modified the test for the new byte number.
<!-- How was it tested? -->
## Summary
This PR removes most of the syntax errors from the test cases. This
would create noise when https://github.com/astral-sh/ruff/pull/11901 is
complete. These syntax errors are also just noise for the test itself.
## Test Plan
Update the snapshots and verify that they're still the same.
## Summary
This PR is a follow-up on #11845 to add the re-lexing logic for normal
list parsing.
A normal list parsing is basically parsing elements without any
separator in between i.e., there can only be trivia tokens in between
the two elements. Currently, this is only being used for parsing
**assignment statement** and **f-string elements**. Assignment
statements cannot be in a parenthesized context, but f-string can have
curly braces so this PR is specifically for them.
I don't think this is an ideal recovery but the problem is that both
lexer and parser could add an error for f-strings. If the lexer adds an
error it'll emit an `Unknown` token instead while the parser adds the
error directly. I think we'd need to move all f-string errors to be
emitted by the parser instead. This way the parser can correctly inform
the lexer that it's out of an f-string and then the lexer can pop the
current f-string context out of the stack.
## Test Plan
Add test cases, update the snapshots, and run the fuzzer.
## Summary
Fixes https://github.com/astral-sh/ruff-vscode/issues/496.
Cells are no longer removed from the notebook index when a notebook gets
updated, but rather when `textDocument/didClose` is called for them.
This solves an issue where their premature removal from the notebook
cell index would cause their URL to be un-queryable in the
`textDocument/didClose` handler.
## Test Plan
Create and then delete a notebook cell in VS Code. No error should
appear.
## Summary
This PR implements the re-lexing logic in the parser.
This logic is only applied when recovering from an error during list
parsing. The logic is as follows:
1. During list parsing, if an unexpected token is encountered and it
detects that an outer context can understand it and thus recover from
it, it invokes the re-lexing logic in the lexer
2. This logic first checks if the lexer is in a parenthesized context
and returns if it's not. Thus, the logic is a no-op if the lexer isn't
in a parenthesized context
3. It then reduces the nesting level by 1. It shouldn't reset it to 0
because otherwise the recovery from nested list parsing will be
incorrect
4. Then, it tries to find last newline character going backwards from
the current position of the lexer. This avoids any whitespaces but if it
encounters any character other than newline or whitespace, it aborts.
5. Now, if there's a newline character, then it needs to be re-lexed in
a logical context which means that the lexer needs to emit it as a
`Newline` token instead of `NonLogicalNewline`.
6. If the re-lexing gives a different token than the current one, the
token source needs to update it's token collection to remove all the
tokens which comes after the new current position.
It turns out that the list parsing isn't that happy with the results so
it requires some re-arranging such that the following two errors are
raised correctly:
1. Expected comma
2. Recovery context error
For (1), the following scenarios needs to be considered:
* Missing comma between two elements
* Half parsed element because the grammar doesn't allow it (for example,
named expressions)
For (2), the following scenarios needs to be considered:
1. If the parser is at a comma which means that there's a missing
element otherwise the comma would've been consumed by the first `eat`
call above. And, the parser doesn't take the re-lexing route on a comma
token.
2. If it's the first element and the current token is not a comma which
means that it's an invalid element.
resolves: #11640
## Test Plan
- [x] Update existing test snapshots and validate them
- [x] Add additional test cases specific to the re-lexing logic and
validate the snapshots
- [x] Run the fuzzer on 3000+ valid inputs
- [x] Run the fuzzer on invalid inputs
- [x] Run the parser on various open source projects
- [x] Make sure the ecosystem changes are none
## Summary
This PR updates the server capabilities to include the commands that
Ruff supports. This is similar to how there's a list of possible code
actions supported by the server.
I noticed this when I was trying to find whether Helix supported
workspace commands or not based on Jane's comment
(https://github.com/astral-sh/ruff/pull/11831#discussion_r1634984921)
and I found the `:lsp-workspace-command` in the editor but it didn't
show up anything in the picker.
So, I looked at the implementation in Helix
(9c479e6d2d/helix-term/src/commands/typed.rs (L1372-L1384))
which made me realize that Ruff doesn't provide this in its
capabilities. Currently, this does require `ruff` to be first in the
list of language servers in the user config but that should be resolved
by https://github.com/helix-editor/helix/pull/10176. So, the following
config should work:
```toml
[[language]]
name = "python"
# Ruff should come first until https://github.com/helix-editor/helix/pull/10176 is released
language-servers = ["ruff", "pyright"]
```
## Test Plan
1. Neovim's server capabilities output should include the supported
commands:
```
executeCommandProvider = {
commands = { "ruff.applyFormat", "ruff.applyAutofix", "ruff.applyOrganizeImports", "ruff.printDebugInformation" },
workDoneProgress = false
},
```
2. Helix should now display the commands to pick from when
`:lsp-workspace-command` is invoked:
<img width="832" alt="Screenshot 2024-06-13 at 08 47 14"
src="https://github.com/astral-sh/ruff/assets/67177269/09048ecd-c974-4e09-ab56-9482ff3d780b">
## Summary
This PR adds a new enum to determine the kind of terminator token i.e.,
is it actually terminates the list or is it used for error recovery.
This is important because the parser should take the error recovery
route in case the terminator token is used for better error recovery.
This will then try to re-lex the token if it's the case.
I haven't updated any reference to use this new enum as otherwise it'll
update the snapshots. I plan to do that in a follow-up PR so that it's
easier to reason about.
## Test plan
`cargo insta test`
## Summary
This PR separates the terminator token for f-string elements depending
on the context. A list of f-string element can occur either in a regular
f-string or a format spec of an f-string. The terminator token is
different depending on that context.
## Test Plan
`cargo insta test` and verify the updated snapshots.
## Summary
This PR re-uses the `ruff_python_trivia::is_python_whitespace` in the
lexer instead of defining its own. This was mainly to avoid circular
dependency which was resolved in #11261.
## Summary
Add Constraint nodes to flow graph, and narrow types based on that (only
`is None` and `is not None` narrowing supported for now, to prototype
the structure.)
Also add simplification of zero- and one-element unions and
intersections, and flattening of intersections.
There's a lot more normalization logic needed for unions and
intersections (as is obvious from the inferred type in the added
`narrow_none` test), but this will be non-trivial and I'd rather do it
in a separate PR.
Here's a flowchart diagram for the code in the added `narrow_none` test:

The top branch is for the `if` expression in the initial assignment to
`x`; that `Constraint` node would only affect the type of `flag`, which
we don't care about in this test.
The second branch is for the `if` statement, with `Constraint` node
affecting the type of `x`.
## Test Plan
Added tests.
## Summary
Fixes#11744.
We now show a distinct popup message when we fail to get a document
snapshot during command execution. This message more clearly
communicates the issue to the user, instead of a generic "ruff
encountered an error" message.
## Test Plan
Try running `Fix all auto-fixable problems` on an incompatible file (for
example: `settings.json`). You should see the following popup message:
<img width="456" alt="Screenshot 2024-06-11 at 11 47 16 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/3a28e3d7-3896-4dd0-b117-f87300dd3b68">
## Summary
Closes#11715.
Introduces a new command, `ruff.printDebugInformation`. This will print
useful information about the status of the server to `stderr`.
Right now, the information shown by this command includes:
* The path to the server executable
* The version of the executable
* The text encoding being used
* The number of open documents and workspaces
* A list of registered configuration files
* The capabilities of the client
## Test Plan
First, checkout and use [the corresponding `ruff-vscode`
PR](https://github.com/astral-sh/ruff-vscode/pull/495).
Running the `Print debug information` command in VS Code should show
something like the following in the Output channel:
<img width="991" alt="Screenshot 2024-06-11 at 11 41 46 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/ab93c009-bb7b-4291-b057-d44fdc6f9f86">
## Summary
Fixes#10968.
Fixes#11545.
The server's tracing system has been rewritten from the ground up. The
server now has trace level and log level settings which restrict the
tracing events and spans that get logged.
* A `logLevel` setting has been added, which lets a user set the log
level. By default, it is set to `"info"`.
* A `logFile` setting has also been added, which lets the user supply an
optional file to send tracing output (it does not have to exist as a
file yet). By default, if this is unset, tracing output will be sent to
`stderr`.
* A `$/setTrace` handler has also been added, and we also set the trace
level from the initialization options. For editors without direct
support for tracing, the environment variable `RUFF_TRACE` can override
the trace level.
* Small changes have been made to how we display tracing output. We no
longer use `tracing-tree`, and instead use
`tracing_subscriber::fmt::Layer` to format output. Thread names are now
included in traces, and I've made some adjustment to thread worker names
to be more useful.
## Test Plan
In VS Code, with `ruff.trace.server` set to its default value, no logs
from Ruff should appear.
After changing `ruff.trace.server` to either `messages` or `verbose`,
you should see log messages at `info` level or higher appear in Ruff's
output:
<img width="1005" alt="Screenshot 2024-06-10 at 10 35 04 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/6050d107-9815-4bd2-96d0-e86f096a57f5">
In Helix, by default, no logs from Ruff should appear.
To set the trace level in Helix, you'll need to modify your language
configuration as follows:
```toml
[language-server.ruff]
command = "/Users/jane/astral/ruff/target/debug/ruff"
args = ["server", "--preview"]
environment = { "RUFF_TRACE" = "messages" }
```
After doing this, logs of `info` level or higher should be visible in
Helix:
<img width="1216" alt="Screenshot 2024-06-10 at 10 39 26 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/8ff88692-d3f7-4fd1-941e-86fb338fcdcc">
You can use `:log-open` to quickly open the Helix log file.
In Neovim, by default, no logs from Ruff should appear.
To set the trace level in Neovim, you'll need to modify your
configuration as follows:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" }
}
```
You should see logs appear in `:LspLog` that look like the following:
<img width="1490" alt="Screenshot 2024-06-11 at 11 24 01 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/576cd5fa-03cf-477a-b879-b29a9a1200ff">
You can adjust `logLevel` and `logFile` in `settings`:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" },
settings = {
logLevel = "debug",
logFile = "your/log/file/path/log.txt"
}
}
```
The `logLevel` and `logFile` can also be set in Helix like so:
```toml
[language-server.ruff.config.settings]
logLevel = "debug"
logFile = "your/log/file/path/log.txt"
```
Even if this log file does not exist, it should now be created and
written to after running the server:
<img width="1148" alt="Screenshot 2024-06-10 at 10 43 44 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/ab533cf7-d5ac-4178-97f1-e56da17450dd">
## Summary
This PR updates the parser to remove building the `CommentRanges` and
instead it'll be built by the linter and the formatter when it's
required.
For the linter, it'll be built and owned by the `Indexer` while for the
formatter it'll be built from the `Tokens` struct and passed as an
argument.
## Test Plan
`cargo insta test`
## Summary
The fix for E203 now produces the same result as ruff format in cases
where a slice ends on a colon and the closing square bracket is on the
following line.
Refers to https://github.com/astral-sh/ruff/issues/10973
## Test Plan
The minimal reproduction case in the ticket was added as test case
producing no error. Additional cases with multiple spaces or a tab
before the colon where added to make sure that the rule still finds
these.
## Summary
As-is, we're using the URL path for all files, leading us to use paths
like:
```
/c%3A/Users/crmar/workspace/fastapi/tests/main.py
```
This doesn't match against per-file ignores and other patterns in Ruff
configuration.
This PR modifies the LSP to use the real file path if available, and the
virtual file path if not.
Closes https://github.com/astral-sh/ruff/issues/11751.
## Test Plan
Ran the LSP on Windows. In the FastAPI repo, added:
```toml
[tool.ruff.lint.per-file-ignores]
"tests/**/*.py" = ["F401"]
```
And verified that an unused import was ignored in `tests` after this
change, but not before.
## Summary
This PR removes the `result-like` dependency and instead implement the
required functionality. The motivation being that `noqa.is_enabled()` is
easier to read than `noqa.into()`.
For context, I was just trying to understand the syntax error workflow
and I saw these flags which were being converted via `into`. I always
find `into` confusing because you never know what's it being converted
into unless you know the type. Later realized that it's just a boolean
flag. After removing the usages from these two flags, it turns out that
the dependency is only being used in one rule so I thought to remove
that as well.
## Test Plan
`cargo insta test`
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements the [consider dict
items](https://pylint.pycqa.org/en/latest/user_guide/messages/convention/consider-using-dict-items.html)
rule from Pylint. Enabling this rule flags:
```python
ORCHESTRA = {
"violin": "strings",
"oboe": "woodwind",
"tuba": "brass",
"gong": "percussion",
}
for instrument in ORCHESTRA:
print(f"{instrument}: {ORCHESTRA[instrument]}")
for instrument in ORCHESTRA.keys():
print(f"{instrument}: {ORCHESTRA[instrument]}")
for instrument in (inline_dict := {"foo": "bar"}):
print(f"{instrument}: {inline_dict[instrument]}")
```
For not using `items()` to extract the value out of the dict. We ignore
the case of an assignment, as you can't modify the underlying
representation with the value in the list of tuples returned.
## Test Plan
<!-- How was it tested? -->
`cargo test`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Definitions are used in symbol table and in flow graph, and aren't
inherently owned by one or the other; move them into their own
submodule.
## Test Plan
Existing tests.
## Summary
Add support for inferring int literal types from basic arithmetic on int
literals. Just to begin showing examples of resolving more complex
expression types, and because this will be useful in testing walrus
expressions.
## Test Plan
Added test.
## Summary
After looking at this a bit, I think it does make sense to have
`Unbound` as part of the `Definition` enum; if we are modeling `Unbound`
as a type (which currently we are), then every symbol implicitly starts
each scope with a "definition" as unbound, and the cleanest way to model
that is as a real `Definition`. We should be able to handle a definition
of "unbound" anywhere we handle definitions.
But the name `None` wasn't clear enough; changing the name to `Unbound`
and adding a doc comment.
Also change `[first].into_iter()` to `std::iter::once(first)`, from
post-land code review on a prior PR.
## Test Plan
Existing tests.
## Summary
This PR is a follow-up to #11740 to restrict access to the `Parsed`
output by replacing the `parsed` API function with a more specific one.
Currently, that is `comment_ranges` but the linked PR exposes a `tokens`
method.
The main motivation is so that there's no way to get an incorrect
information from the checker. And, it also encapsulates the source of
the comment ranges and the tokens itself. This way it would become
easier to just update the checker if the source for these information
changes in the future.
## Test Plan
`cargo insta test`
## Summary
This PR fixes a bug where the checker would require the tokens for an
invalid offset w.r.t. the source code.
Taking the source code from the linked issue as an example:
```py
relese_version :"0.0is 64"
```
Now, this isn't really a valid type annotation but that's what this PR
is fixing. Regardless of whether it's valid or not, Ruff shouldn't
panic.
The checker would visit the parsed type annotation (`0.0is 64`) and try
to detect any violations. Certain rule logic requests the tokens for the
same but it would fail because the lexer would only have the `String`
token considering original source code. This worked before because the
lexer was invoked again for each rule logic.
The solution is to store the parsed type annotation on the checker if
it's in a typing context and use the tokens from that instead if it's
available. This is enforced by creating a new API on the checker to get
the tokens.
But, this means that there are two ways to get the tokens via the
checker API. I want to restrict this in a follow-up PR (#11741) to only
expose `tokens` and `comment_ranges` as methods and restrict access to
the parsed source code.
fixes: #11736
## Test Plan
- [x] Add a test case for `F632` rule and update the snapshot
- [x] Check all affected rules
- [x] No ecosystem changes
## Summary
This PR updates the return type of `parse_type_annotation` from `Expr`
to `Parsed<ModExpression>`. This is to allow accessing the tokens for
the parsed sub-expression in the follow-up PR.
## Test Plan
`cargo insta test`
## Summary
Fixes https://github.com/astral-sh/ruff-vscode/issues/482.
I've made adjustments to `format` and `format_range` that handle parsing
errors before they become server errors. We'll still log this as a
problem, but there will no longer be a visible popup.
## Test Plan
Instead of seeing a visible error when formatting a document with syntax
issues, you should see this warning in the LSP logs:
<img width="991" alt="Screenshot 2024-06-04 at 3 38 23 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/9d68947d-6462-4ca6-ab5a-65e573c91db6">
Similarly, if you try to format a range with syntax issues, you should
see this warning in the LSP logs instead of a visible error popup:
<img width="1010" alt="Screenshot 2024-06-04 at 3 39 10 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/99fff098-798d-406a-976e-81ead0da0352">
---------
Co-authored-by: Zanie Blue <contact@zanie.dev>
## Summary
This PR fixes a bug where the lexer didn't consider the BOM into the
start offset.
fixes: #11731
## Test Plan
Add multiple test cases which involves BOM character in the source for
the lexer and verify the snapshot.
## Summary
This PR updates the lexer checkpoint to store the cursor offset instead
of cloning the cursor itself. This reduces the size of `LexerCheckpoint`
from 136 to 112 bytes and also removes the need for lifetime.
## Test Plan
`cargo insta test`
## Summary
Ensures that we respect per-file ignores and exemptions for these rules.
Specifically, we allow:
```python
# ruff: noqa: PGH004
```
...to ignore `PGH004`.
## Summary
Should resolve https://github.com/astral-sh/ruff/issues/11454.
This is my first PR to `ruff`, so I may have missed something.
If I understood the suggestion in the issue correctly, rule `PGH004`
should be set to `Preview` again.
## Test Plan
Created two fixtures derived from the issue.
## Summary
Switch name resolution in `infer_expression_type` from resolving the
public type of a symbol, to resolving the reachable definitions of that
symbol from the reference point, using the flow graph.
This surfaced a bug in the flow graph implementation and a bug in symbol
table building, both of which are also fixed here.
The bug in flow graph implementation was that when we pushed and popped
scopes, we didn't maintain a stack of "current flow nodes" in all
stacked scopes, to be restored when we returned to that scope. Now we
do.
The bug in symbol table building that we didn't visit the parts of
functions and class definitions in the correct scopes. E.g. decorators
should be visited in the outer scope, arguments should be visited inside
the type-params scope (if any) but not inside the function body scope,
and only the body itself should actually be visited inside the body
scope. Fixing this requires that we no longer use `walk_stmt` here,
instead we have to visit each individual component.
## Test Plan
Added test.
## Summary
Rename `infer_symbol_type` to `infer_symbol_public_type`, and allow it
to work on symbols with more than one definition. For now, use the most
cautious/sound inference, which is the union of all definitions. We can
prune this union more in future by eliminating definitions if we can
show that they can't be visible (this requires both that the symbol is
definitely later reassigned, and that there is no intervening
call/import that might be able to see the over-written definition).
## Test Plan
Added a test showing inference of union from multiple definitions.
## Summary
This PR fixes a bug where the `Generator` wouldn't add a newline before
a type alias statement. This is because it wasn't using the `statement`
macro which takes care of the newline.
Without this fix, a code like:
```py
type X = int
type Y = str
```
The generator would produce:
```py
type X = inttype Y = str
```
## Test Plan
Add a test case.
## Summary
This PR removes the following dependencies from the `ruff_python_parser`
crate:
* `anyhow` (moved to dev dependencies)
* `is-macro`
* `itertools`
The main motivation is that they aren't used much.
Additionally, it updates the return type of `parse_type_annotation` to
use a more specific `ParseError` instead of the generic `anyhow::Error`.
## Test Plan
`cargo insta test`
## Summary
This PR updates the logic for parsing type annotation to accept a
`ExprStringLiteral` node instead of the string value and the range.
The main motivation of this change is to simplify the implementation of
`parse_type_annotation` function with:
* Use the `opener_len` and `closer_len` from the string flags to get the
raw contents range instead of extracting it via
* `str::leading_quote(expression).unwrap().text_len()`
* `str::trailing_quote(expression).unwrap().text_len()`
* Avoid comparing the string content if we already know that it's
implicitly concatenated
## Test Plan
`cargo insta test`
## Summary
This PR re-orders the lexer methods in the following order:
1. `next_token`
2. `lex_token`
3. `eat_indentation`
4. `handle_indentation`
5. `skip_whitespace`
6. `consume_ascii_character`
7. `try_single_char_prefix`
8. `try_double_char_prefix`
9. `lex_identifier`
10. `lex_fstring_start`
11. `lex_fstring_middle_or_end`
12. `lex_string`
13. `lex_number`
14. `lex_number_radix`
15. `lex_decimal_number`
16. `radix_run`
17. `lex_comment`
18. `lex_ipython_escape_command`
19. `consume_end`
Following was considered for the ordering:
* 1 is the main entry point which delegates to 2
* 3, 4, 5 are all related to whitespace which is done first
* 6 is the entrypoint for an ascii character which delegates to 9, 12,
13, 17, 18, 19
* Others are grouped around similar kind of methods
## Summary
This PR updates the entire parser stack in multiple ways:
### Make the lexer lazy
* https://github.com/astral-sh/ruff/pull/11244
* https://github.com/astral-sh/ruff/pull/11473
Previously, Ruff's lexer would act as an iterator. The parser would
collect all the tokens in a vector first and then process the tokens to
create the syntax tree.
The first task in this project is to update the entire parsing flow to
make the lexer lazy. This includes the `Lexer`, `TokenSource`, and
`Parser`. For context, the `TokenSource` is a wrapper around the `Lexer`
to filter out the trivia tokens[^1]. Now, the parser will ask the token
source to get the next token and only then the lexer will continue and
emit the token. This means that the lexer needs to be aware of the
"current" token. When the `next_token` is called, the current token will
be updated with the newly lexed token.
The main motivation to make the lexer lazy is to allow re-lexing a token
in a different context. This is going to be really useful to make the
parser error resilience. For example, currently the emitted tokens
remains the same even if the parser can recover from an unclosed
parenthesis. This is important because the lexer emits a
`NonLogicalNewline` in parenthesized context while a normal `Newline` in
non-parenthesized context. This different kinds of newline is also used
to emit the indentation tokens which is important for the parser as it's
used to determine the start and end of a block.
Additionally, this allows us to implement the following functionalities:
1. Checkpoint - rewind infrastructure: The idea here is to create a
checkpoint and continue lexing. At a later point, this checkpoint can be
used to rewind the lexer back to the provided checkpoint.
2. Remove the `SoftKeywordTransformer` and instead use lookahead or
speculative parsing to determine whether a soft keyword is a keyword or
an identifier
3. Remove the `Tok` enum. The `Tok` enum represents the tokens emitted
by the lexer but it contains owned data which makes it expensive to
clone. The new `TokenKind` enum just represents the type of token which
is very cheap.
This brings up a question as to how will the parser get the owned value
which was stored on `Tok`. This will be solved by introducing a new
`TokenValue` enum which only contains a subset of token kinds which has
the owned value. This is stored on the lexer and is requested by the
parser when it wants to process the data. For example:
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L1260-L1262)
[^1]: Trivia tokens are `NonLogicalNewline` and `Comment`
### Remove `SoftKeywordTransformer`
* https://github.com/astral-sh/ruff/pull/11441
* https://github.com/astral-sh/ruff/pull/11459
* https://github.com/astral-sh/ruff/pull/11442
* https://github.com/astral-sh/ruff/pull/11443
* https://github.com/astral-sh/ruff/pull/11474
For context,
https://github.com/RustPython/RustPython/pull/4519/files#diff-5de40045e78e794aa5ab0b8aacf531aa477daf826d31ca129467703855408220
added support for soft keywords in the parser which uses infinite
lookahead to classify a soft keyword as a keyword or an identifier. This
is a brilliant idea as it basically wraps the existing Lexer and works
on top of it which means that the logic for lexing and re-lexing a soft
keyword remains separate. The change here is to remove
`SoftKeywordTransformer` and let the parser determine this based on
context, lookahead and speculative parsing.
* **Context:** The transformer needs to know the position of the lexer
between it being at a statement position or a simple statement position.
This is because a `match` token starts a compound statement while a
`type` token starts a simple statement. **The parser already knows
this.**
* **Lookahead:** Now that the parser knows the context it can perform
lookahead of up to two tokens to classify the soft keyword. The logic
for this is mentioned in the PR implementing it for `type` and `match
soft keyword.
* **Speculative parsing:** This is where the checkpoint - rewind
infrastructure helps. For `match` soft keyword, there are certain cases
for which we can't classify based on lookahead. The idea here is to
create a checkpoint and keep parsing. Based on whether the parsing was
successful and what tokens are ahead we can classify the remaining
cases. Refer to #11443 for more details.
If the soft keyword is being parsed in an identifier context, it'll be
converted to an identifier and the emitted token will be updated as
well. Refer
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L487-L491).
The `case` soft keyword doesn't require any special handling because
it'll be a keyword only in the context of a match statement.
### Update the parser API
* https://github.com/astral-sh/ruff/pull/11494
* https://github.com/astral-sh/ruff/pull/11505
Now that the lexer is in sync with the parser, and the parser helps to
determine whether a soft keyword is a keyword or an identifier, the
lexer cannot be used on its own. The reason being that it's not
sensitive to the context (which is correct). This means that the parser
API needs to be updated to not allow any access to the lexer.
Previously, there were multiple ways to parse the source code:
1. Passing the source code itself
2. Or, passing the tokens
Now that the lexer and parser are working together, the API
corresponding to (2) cannot exists. The final API is mentioned in this
PR description: https://github.com/astral-sh/ruff/pull/11494.
### Refactor the downstream tools (linter and formatter)
* https://github.com/astral-sh/ruff/pull/11511
* https://github.com/astral-sh/ruff/pull/11515
* https://github.com/astral-sh/ruff/pull/11529
* https://github.com/astral-sh/ruff/pull/11562
* https://github.com/astral-sh/ruff/pull/11592
And, the final set of changes involves updating all references of the
lexer and `Tok` enum. This was done in two-parts:
1. Update all the references in a way that doesn't require any changes
from this PR i.e., it can be done independently
* https://github.com/astral-sh/ruff/pull/11402
* https://github.com/astral-sh/ruff/pull/11406
* https://github.com/astral-sh/ruff/pull/11418
* https://github.com/astral-sh/ruff/pull/11419
* https://github.com/astral-sh/ruff/pull/11420
* https://github.com/astral-sh/ruff/pull/11424
2. Update all the remaining references to use the changes made in this
PR
For (2), there were various strategies used:
1. Introduce a new `Tokens` struct which wraps the token vector and add
methods to query a certain subset of tokens. These includes:
1. `up_to_first_unknown` which replaces the `tokenize` function
2. `in_range` and `after` which replaces the `lex_starts_at` function
where the former returns the tokens within the given range while the
latter returns all the tokens after the given offset
2. Introduce a new `TokenFlags` which is a set of flags to query certain
information from a token. Currently, this information is only limited to
any string type token but can be expanded to include other information
in the future as needed. https://github.com/astral-sh/ruff/pull/11578
3. Move the `CommentRanges` to the parsed output because this
information is common to both the linter and the formatter. This removes
the need for `tokens_and_ranges` function.
## Test Plan
- [x] Update and verify the test snapshots
- [x] Make sure the entire test suite is passing
- [x] Make sure there are no changes in the ecosystem checks
- [x] Run the fuzzer on the parser
- [x] Run this change on dozens of open-source projects
### Running this change on dozens of open-source projects
Refer to the PR description to get the list of open source projects used
for testing.
Now, the following tests were done between `main` and this branch:
1. Compare the output of `--select=E999` (syntax errors)
2. Compare the output of default rule selection
3. Compare the output of `--select=ALL`
**Conclusion: all output were same**
## What's next?
The next step is to introduce re-lexing logic and update the parser to
feed the recovery information to the lexer so that it can emit the
correct token. This moves us one step closer to having error resilience
in the parser and provides Ruff the possibility to lint even if the
source code contains syntax errors.
## Summary
Implement support for RDJson output for `ruff check`, as requested in
#8655.
## Test Plan
Tested using a snapshot test. Same approach as for e.g. the JSON output
formatter.
## Additional info
I tried to keep the implementation close to the JSON implementation.
I had to deviate a bit to make the `suggestions` key work: If there are
no suggestions, then setting `suggestions` to `null` is invalid
according to the JSONSchema. Therefore, I opted for a slightly more
complex implementation, that skips the `suggestions` key entirely if
there are no fixes available for the given diagnostic. Maybe it would
have been easier to set `"suggestions": []`, but I ended up doing it
this way.
I didn't consider notebooks, as I _think_ that RDJson doesn't work with
notebooks. This should be confirmed, and if so, there should be some
form of warning or error emitted when trying to output diagnostics for a
notebook.
I also didn't consider `ruff format`, as this comment:
https://github.com/astral-sh/ruff/issues/8655#issuecomment-1811446160
suggests that that wouldn't be compatible.
I'm new to Rust, any feedback is appreciated. 🙂 I
implemented this in order to have a productive rainy saturday afternoon,
I'm not knowledgeable about RDJson beyond the sources linked in the
issue.
## Summary
This PR implements the rule B901, which is part of the opinionated rules
of `flake8-bugbear`.
This rule seems to be desired in `ruff` as per
https://github.com/astral-sh/ruff/issues/3758 and
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976.
## Test Plan
As this PR was made closely following the
[CONTRIBUTING.md](8a25531a71/CONTRIBUTING.md),
it tests using the snapshot approach, that is described there.
## Sources
The implementation is inspired by [the original implementation in the
`flake8-bugbear`
repository](d1aec4cbef/bugbear.py (L1092)).
The error message and [test
file](d1aec4cbef/tests/b901.py)
where also copied from there.
The documentation I came up with on my own and needs improvement. Maybe
the example given in
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976
could be used, but maybe they are too complex, I'm not sure.
## Open Questions
- [ ] Documentation. (See above.)
- [x] Can I access the parent in a visitor?
The [original
implementation](d1aec4cbef/bugbear.py (L1100))
references the `yield` statement's parent to check if it is an
expression statement. I didn't find a way to do this in `ruff` and used
the `is_expresssion_statement` field on the visitor instead. What are
your thoughts on this? Is it possible and / or desired to access the
parent node here?
- [x] Is `Option::is_some(...)` -> `...unwrap()` the right thing to do?
Referring to [this piece of
code](9d5a280f71/crates/ruff_linter/src/rules/flake8_bugbear/rules/return_x_in_generator.rs?plain=1#L91-L96).
From my understanding, the `.unwrap()` is safe, because it is checked
that `return_` is not `None`. However, I feel like I missed a more
elegant solution that does both in one.
## Other
I don't know a lot about this rule, I just implemented it because I
found it in a
https://github.com/astral-sh/ruff/labels/good%20first%20issue.
I'm new to Rust, so any constructive critisism is appreciated.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Introduces the skeleton of the flow graph. So far it doesn't actually
handle any non-linear control flow :) But it does show how we can go
from an expression that references a symbol, backward through the flow
graph, to find reachable definitions of that symbol.
Adding non-linear control flow will mean adding flow nodes with multiple
predecessors, which will introduce more complexity into
`ReachableDefinitionsIterator.next()`. But one step at a time.
## Test Plan
Added a (very basic) test.
## Summary
Give red-knot the ability to infer int literal types. This is quick and
easy, mostly because these types are a convenient way to observe
control-flow handling with simple assignments.
## Test Plan
Added test.
## Summary
In the [roadmap for `ruff
server`](https://github.com/astral-sh/ruff/discussions/10581) support
for vim and kate is listed. Therefore I added setup guides for them
based on the neovim guide. As I don't use pyright I wasn't able to
translate the corresponding part from the neovim guide.
## Test Plan
Doesn't apply.
* Potentially resolves#11619 (nondeterministic hashmap order across
different architectures) in F401 by replacing a hashmap with
nondeterministic traversal order with an ordered mapping.
I'm not sure how to test this with our CI/CD. I don't have an s390x
machine at home. Should I try it in Qemu?
## Summary
In an `__init__.py` file, it's not uncommon to lack a logical indent
(since it may just contain imports). In such cases, we were always
falling back to four-space indent. This PR adds detection for indents
within import groups.
Closes https://github.com/astral-sh/ruff/issues/11606.
## Summary
This PR aims to close#10095 by adding an option
`init-allow-undef-export` to the `pyflakes` settings. This option is
currently set to `true` such that behavior is kept identical.
But setting this option to `false` will lead to `F822` warnings to be
shown in all files, **including** `__init__.py` files.
As I've mentioned on #10095, I think `init-allow-undef-export=false`
would be the more user-friendly default option, as it creates fewer
surprises. @charliermarsh what do you think about making that the
default?
With this option in place, it's a single line fix for people that rely
on the old behavior.
And thinking longer term, for future major releases, one could probably
consider deprecating the option and eventually having people just `noqa`
these warnings if they are not wanted.
## Test Plan
I've added a `test_init_f822_enabled` test which repeats the test that
is done in the `init` test but this time with
`init-allow-undef-export=false` and the snap file correctly shows that
ruff will then trigger the otherwise suppressed F822 warning.
closes#10095
## Summary
Removed stray space in sample code snippet that is against ruff's own
default formatting rules.
This documentation appears on
https://docs.astral.sh/ruff/rules/unused-import/
## Test Plan
This is a trivially obvious change, verifiable with `ruff format
--check`
## Summary
Closes https://github.com/astral-sh/ruff/issues/11587.
## Test Plan
- Added a lint error to `test_server.py` in `vscode-ruff`.
- Validated that, prior to this change, diagnostics appeared in the
file.
- Validated that, with this change, no diagnostics were shown.
- Validated that, with this change, no diagnostics were fixed on-save.
## Summary
- Implements `Y066` from `flake8-pyi` as `PYI066`
- Fixes `PYI006` not being raised for `elif` clauses. This would have
conflicted with PYI006's implementation, so decided to do it in the same
PR.
## Test Plan
`cargo test` / `cargo insta review`
* Add a module type, `ModuleTypeId`
* Add an attribute lookup method `get_member` for `Type`
* Only implemented for `ModuleTypeId` and `ClassTypeId`
* [x] Should this be a trait?
*Answer: no*
* [x] Uses `unwrap`, but we should remove that. Maybe add a new variant
to `QueryError`?
*Answer: Return `Option<Type>` as is done elsewhere*
* Add `infer_definition_type` case for `Import`
* Add `infer_expr_type` case for `Attribute`
* Add a test to exercise these
* [x] remove all NOTE/FIXME/TODO after discussing with reviewers
## Summary
This PR ensures that if a variable is bound via `global`, and then the
`global` is read, the originating variable is also marked as read. It's
not perfect, in that it won't detect _rebindings_, like:
```python
from app import redis_connection
def func():
global redis_connection
redis_connection = 1
redis_connection()
```
So, above, `redis_connection` is still marked as unused.
But it does avoid flagging `redis_connection` as unused in:
```python
from app import redis_connection
def func():
global redis_connection
redis_connection()
```
Closes https://github.com/astral-sh/ruff/issues/11518.
## Summary
Follow up to https://github.com/astral-sh/ruff/pull/11521
Removes the extra added complexity for catch all match cases. This
matches the implementation of plain `else` statements.
## Test Plan
Added new test cases.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR fixes the bug to avoid flattening the global-only settings for
the new server.
This was added in https://github.com/astral-sh/ruff/pull/11497, possibly
to correctly de-serialize an empty value (`{}`). But, this lead to a bug
where the configuration under the `settings` key was not being read for
global-only variant.
By using #[serde(default)], we ensure that the settings field in the
`GlobalOnly` variant is optional and that an empty JSON object `{}` is
correctly deserialized into `GlobalOnly` with a default `ClientSettings`
instance.
fixes: #11507
## Test Plan
Update the snapshot and existing test case. Also, verify the following
settings in Neovim:
1. Nothing
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
}
```
2. Empty dictionary
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = vim.empty_dict(),
}
```
3. Empty `settings`
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = {
settings = vim.empty_dict(),
},
}
```
4. With some configuration:
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = {
settings = {
configuration = '/tmp/ruff-repro/pyproject.toml',
},
},
}
```
## Summary
This PR brings back the functionality to remove empty strings when
converting to an f-string in `UP032`.
For context, https://github.com/astral-sh/ruff/pull/8712 added this
functionality to remove _trailing_ empty strings but it got removed in
https://github.com/astral-sh/ruff/pull/8697 possibly unexpectedly so.
There's one difference which is that this PR will remove _any_ empty
strings and not just trailing ones. For example,
```diff
--- /Users/dhruv/playground/ruff/src/UP032.py
+++ /Users/dhruv/playground/ruff/src/UP032.py
@@ -1,7 +1,5 @@
(
- "{a}"
- ""
- "{b}"
- ""
-).format(a=1, b=1)
+ f"{1}"
+ f"{1}"
+)
```
## Test Plan
Run `cargo insta test` and update the snapshots.
## Summary
This PR updates the sequence sorting (`RUF022` and `RUF023`) to avoid
using the owned data from the string token. Instead, we will directly
use the reference to the data on the AST. This does introduce a lot of
lifetimes but that's required.
The main motivation for this is to allow removing the `lex_starts_at`
usage easily.
### Alternatives
1. Extract the raw string content (stripping the prefix and quotes)
using the `Locator` and use that for comparison
2. Build up an
[`IndexVec`](3e30962077/crates/ruff_index/src/vec.rs)
and use the newtype index in place of the string value itself. This also
does require lifetimes so we might as well just use the method in this
PR.
## Test Plan
`cargo insta test` and no ecosystem changes
## Summary
Fixes#11506.
`RuffSettingsIndex::new` now searches for configuration files in parent
directories.
## Test Plan
I confirmed that the original test case described in the issue worked as
expected.
## Summary
Concurrent GitLab runners clone projects into separate directories, e.g.
`{builds_dir}/$RUNNER_TOKEN_KEY/$CONCURRENT_ID/$NAMESPACE/$PROJECT_NAME`.
Since the fingerprint uses the full path to the file, the fingerprints
calculated by Ruff are different depending on which concurrent runner it
executes on, so often an MR will appear to remove all existing issues
and add them with new fingerprints.
I've adjusted the fingerprint function to use the project relative path,
which fixes this. Unfortunately this will have a breaking change for any
current users of this output - the fingerprints will change and appear
in GitLab as all linting messages having been fixed and then created.
## Test Plan
`cargo nextest run`
Running `ruff check --output-format gitlab` in a git repo, moving the
repo and running again, verifying no diffs between the outputs
## Summary
Fixes#11534.
`DocumentQuery::source_type` now returns `PySourceType::Stub` when the
document is a `.pyi` file.
## Test Plan
I confirmed that stub-specific rule violations appeared with a build
from this PR (they were not visible from a `main` build).
<img width="1066" alt="Screenshot 2024-05-24 at 2 15 38 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/cd519b7e-21e4-41c8-bc30-43eb6d4d438e">
Hi!
I left out some of the functions in the migration rule which became
removed in NumPy 2.0:
- `np.alltrue`
- `np.anytrue`
- `np.cumproduct`
- `np.product`
Addressing: https://github.com/numpy/numpy/issues/26493
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Current doc says `sys.version[0]` will select the first digit of a major
version number (correct) then as an example says
> e.g., `"3.10"` would evaluate to `"1"`
(would actually evaluate to `"3"`). Changed the example version to a
two-digit number to make the problem more clear.
## Test Plan
<!-- How was it tested? -->
ran the following:
- `cargo run -p ruff -- check
crates/ruff_linter/resources/test/fixtures/flake8_2020/YTT301.py
--no-cache`
- `cargo insta review`
- `cargo test`
which all passed.
## Summary
Rule `logging-warn` (`G010`) prescribes a change from `warn` to
`warning` and has a corresponding autofix, but the autofix is mistakenly
titled ```"Convert to `warn`"``` instead of ```"Convert to `warning`"```
(the latter is what the autofix actually does). Seems to be a plain
typo.
## Summary
Fixes#11516
`ruff server` was sending both regular source actions and notebook
source actions back when passed an empty action filter. This PR makes a
few small changes so that notebook source actions are not sent when
regular source actions are sent, which means that an empty filter will
only return regular source actions.
## Test Plan
I confirmed that duplicate code actions no longer appeared in Neovim,
using a configuration similar to the one from the original issue.
<img width="509" alt="Screenshot 2024-05-23 at 11 48 48 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/9a5d6907-dd41-48bd-b015-8a344c5e0b3f">
## Summary
It turns out that `singledispatch` does end up evaluating all arguments,
even though only the first is used to dispatch.
Closes https://github.com/astral-sh/ruff/issues/11520.
## Summary
Addresses #8451 by implementing rule 116 to add an unsafe fix when sleep
is used with a >24 hour interval to instead consider sleeping forever.
This rule is added as async instead as I my understanding was that these
trio rules would be moved to async anyway.
There are a couple of TODOs, which address further extending the rule by
adding support for lookups and evaluations, and also supporting `anyio`.
## Summary
This PR updates the `FA102` rule logic to use the `Importer` which is
available on the `Checker`.
The main motivation is that this would make updating the `Importer` to
use the `Tokens` struct which will be required to remove the
`lex_starts_at` usage in `Insertion::start_of_block` method.
## Test Plan
`cargo insta test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11236.
This PR fixes several issues, most of which relate to non-VS Code
editors (Helix and Neovim).
1. Global-only initialization options are now correctly deserialized
from Neovim and Helix
2. Empty diagnostics are now published correctly for Neovim and Helix.
3. A workspace folder is created at the current working directory if the
initialization parameters send an empty list of workspace folders.
4. The server now gracefully handles opening files outside of any known
workspace, and will use global fallback settings taken from client
editor settings and a user settings TOML, if it exists.
## Test Plan
I've tested to confirm that each issue has been fixed.
* Global-only initialization options are now correctly deserialized from
Neovim and Helix + the server gracefully handles opening files outside
of any known workspace
https://github.com/astral-sh/ruff/assets/19577865/4f33477f-20c8-4e50-8214-6608b1a1ea6b
* Empty diagnostics are now published correctly for Neovim and Helix
https://github.com/astral-sh/ruff/assets/19577865/c93f56a0-f75d-466f-9f40-d77f99cf0637
* A workspace folder is created at the current working directory if the
initialization parameters send an empty list of workspace folders.
https://github.com/astral-sh/ruff/assets/19577865/b4b2e818-4b0d-40ce-961d-5831478cc726
## Summary
Similar to #11414, this PR extends `UP037` to flag quoted annotations
that are located in positions that won't be evaluated at runtime.
For example, the quotes on `Tuple` are unnecessary in:
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from typing import Tuple
def foo():
x: "Tuple[int, int]" = (0, 0)
foo()
```
## Summary
Recent changes made in the [Jupyter Notebook feature
PR](https://github.com/astral-sh/ruff/pull/11206) caused automatic
configuration reloading to stop working. This was because we would check
for paths to reload using the changed path, when we should have been
using the parent path of the changed path (to get the directory it was
changed in).
Additionally, this PR fixes an issue where `ruff.toml` and `.ruff.toml`
files were not being automatically reloaded.
Finally, this PR improves configuration reloading by actively publishing
diagnostics for notebook documents (which won't be affected by the
workspace refresh since they don't use pull diagnostics). It will also
publish diagnostics for text documents if pull diagnostics aren't
supported.
## Test Plan
To test this, open an existing configuration file in a codebase, and
make modifications that will affect one or more open Python / Jupyter
Notebook files. You should observe that the diagnostics for both kinds
of files update automatically when the file changes are saved.
Here's a test video showing what a successful test should look like:
https://github.com/astral-sh/ruff/assets/19577865/7172b598-d6de-4965-b33c-6cb8b911ef6c
## Summary
Previously, `ruff.applyFormat`, seen in VS Code as the command `Ruff:
Format Document`, would only format the currently active notebook cell
inside a notebook document. This PR makes `ruff.applyFormat` format the
entire notebook document at once, operating on each code cell in order.
## Test Plan
1. Open a notebook document that has multiple unformatted code cells.
2. Run `Ruff: Format Document` through the Command Palette
(`Ctrl/Cmd+Shift+P` by default)
3. Observe that all code cells in the notebook have been formatted.
## Summary
This PR moves the `has_comments` function from `Indexer` to
`CommentRanges`. The main motivation is that the `CommentRanges` will
now be built by the parser which is shared between the linter and the
formatter. Thus, the `CommentRanges` will be removed from the `Indexer`.
## Test Plan
`cargo test`
## Summary
Matching Pylint, we now omit the `try` body itself from branch counting.
Each `except` counts as a branch, as does the `else` and the `finally`.
Closes https://github.com/astral-sh/ruff/issues/11205.
## Summary
Closes https://github.com/astral-sh/ruff/issues/10858.
`ruff server` now supports `*.ipynb` (aka Jupyter Notebook) files.
Extensive internal changes have been made to facilitate this, which I've
done some work to contextualize with documentation and an pre-review
that highlights notable sections of the code.
`*.ipynb` cells should behave similarly to `*.py` documents, with one
major exception. The format command `ruff.applyFormat` will only apply
to the currently selected notebook cell - if you want to format an
entire notebook document, use `Format Notebook` from the VS Code context
menu.
## Test Plan
The VS Code extension does not yet have Jupyter Notebook support
enabled, so you'll first need to enable it manually. To do this,
checkout the `pre-release` branch and modify `src/common/server.ts` as
follows:
Before:

After:

I recommend testing this PR with large, complicated notebook files. I
used notebook files from [this popular
repository](https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks)
in my preliminary testing.
The main thing to test is ensuring that notebook cells behave the same
as Python documents, besides the aforementioned issue with
`ruff.applyFormat`. You should also test adding and deleting cells (in
particular, deleting all the code cells and ensure that doesn't break
anything), changing the kind of a cell (i.e. from markup -> code or vice
versa), and creating a new notebook file from scratch. Finally, you
should also test that source actions work as expected (and across the
entire notebook).
Note: `ruff.applyAutofix` and `ruff.applyOrganizeImports` are currently
broken for notebook files, and I suspect it has something to do with
https://github.com/astral-sh/ruff/issues/11248. Once this is fixed, I
will update the test plan accordingly.
---------
Co-authored-by: nolan <nolan.king90@gmail.com>
The wording 'negative comparison' is a rather vague description of the
'is not' operation and does not describe what the 'not in' operation
does (potentially copied from 'is not'). This was replaced with more
precise language to describe the operators taken from the official
python docs[1].
Both rules didn't have a strong reasoning besides 'it's bad, use the
other'. The origin of these rules seems to be PEP8[2] which prefers 'is
not' over 'not ... is' for readability. This is now reflected in the
description.
[1]:
https://docs.python.org/3/reference/expressions.html#membership-test-operations
[2]: https://peps.python.org/pep-0008/#programming-recommendations
## Summary
If an annotation won't be evaluated at runtime, we don't need to flag
`from __future__ import annotations` as required. This applies both to
quoted annotations and annotations outside of runtime-evaluated
positions, like:
```python
def main() -> None:
a_list: list[str] | None = []
a_list.append("hello")
```
Closes https://github.com/astral-sh/ruff/issues/11397.
## Summary
* Update documentation for F401 following recent PRs
* #11168
* #11314
* Deprecate `ignore_init_module_imports`
* Add a deprecation pragma to the option and a "warn user once" message
when the option is used.
* Restore the old behavior for stable (non-preview) mode:
* When `ignore_init_module_imports` is set to `true` (default) there are
no `__init_.py` fixes (but we get nice fix titles!).
* When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
* When preview mode is enabled, it overrides
`ignore_init_module_imports`.
* Fixed a bug in fix titles where `import foo as bar` would recommend
reexporting `bar as bar`. It now says to reexport `foo as foo`. (In this
case we don't issue a fix, fwiw; it was just a fix title bug.)
## Test plan
Added new fixture tests that reuse the existing fixtures for
`__init__.py` files. Each of the three situations listed above has
fixture tests. The F401 "stable" tests cover:
> * When `ignore_init_module_imports` is set to `true` (default) there
are no `__init_.py` fixes (but we get nice fix titles!).
The F401 "deprecated option" tests cover:
> * When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
These complement existing "preview" tests that show the new behavior
which recommends fixes in `__init__.py` according to whether the import
is 1st party and other circumstances (for more on that behavior see:
#11314).
## Summary
This is a follow-up PR to #11445 update the `E27` rules to consider soft
keywords as well.
## Test Plan
Add test cases consisting of soft keywords and update the snapshot.
## Summary
We weren't treating the escaped newline as a valid condition to trigger
the safer fix (add an extra backslash before each invalid escape
sequence).
Closes https://github.com/astral-sh/ruff/issues/11461.
## Summary
This PR updates the `TokenKind::is_keyword` check to include soft
keywords. To account for this change, it adds a new
`is_non_soft_keyword` method.
The usage in logical line rules were updated to use the
`is_non_soft_keyword` method but it'll be updated to use `is_keyword` in
a follow-up PR (#11446).
While, the parser usages were kept as is. And because of that, the
snapshots for two test cases were updated in a better direction.
## Test Plan
`cargo insta test`
## Summary
We already have handling for "references that get quoted within our
quoted references", but we were assuming a specific ordering in the way
edits were generated.
Closes https://github.com/astral-sh/ruff/issues/11449.
This is useful for extracting the defaults in order to construct
equivalent configs by external scripts. This is my first non-hello-world
rust code, comments and suggested tests appreciated.
## Summary
We already have `ruff linter --output-format json`, this provides `ruff
config x --output-format json` as well. I plan to use this to construct
an equivalent config snippet to include in some managed repos, so when
we update their version of ruff and it adds new lints, they get a PR
that includes the commented-out new lints.
Note that the no-args form of `ruff config` ignores output-format
currently, but probably should obey it (although array-of-strings
doesn't seem that useful, looking for input on format).
## Test Plan
I could use a hand coming up with a typical way to write automated tests
for this.
```sh-session
(.venv) [timhatch:ruff ]$ ./target/debug/ruff config lint.select
A list of rule codes or prefixes to enable. Prefixes can specify exact
rules (like `F841`), entire categories (like `F`), or anything in
between.
When breaking ties between enabled and disabled rules (via `select` and
`ignore`, respectively), more specific prefixes override less
specific prefixes.
Default value: ["E4", "E7", "E9", "F"]
Type: list[RuleSelector]
Example usage:
``toml
# On top of the defaults (`E4`, E7`, `E9`, and `F`), enable flake8-bugbear (`B`) and flake8-quotes (`Q`).
select = ["E4", "E7", "E9", "F", "B", "Q"]
``
(.venv) [timhatch:ruff ]$ ./target/debug/ruff config lint.select --output-format json
{
"Field": {
"doc": "A list of rule codes or prefixes to enable. Prefixes can specify exact\nrules (like `F841`), entire categories (like `F`), or anything in\nbetween.\n\nWhen breaking ties between enabled and disabled rules (via `select` and\n`ignore`, respectively), more specific prefixes override less\nspecific prefixes.",
"default": "[\"E4\", \"E7\", \"E9\", \"F\"]",
"value_type": "list[RuleSelector]",
"scope": null,
"example": "# On top of the defaults (`E4`, E7`, `E9`, and `F`), enable flake8-bugbear (`B`) and flake8-quotes (`Q`).\nselect = [\"E4\", \"E7\", \"E9\", \"F\", \"B\", \"Q\"]",
"deprecated": null
}
}
```
## Summary
As discussed in issue #11408, PLR0912 has a broader definition of
"branches" than I expected. This updates the documentation to include
this definition.
I also updated the example to include several different types of
branches, while still maintaining dictionary lookup as an alternative
solution. (Crafting a realistic example was quite a challenge 😅).
Closes https://github.com/astral-sh/ruff/issues/11408.
## Summary
This moves the string-prefix enumerations in `ruff_python_ast` to a
separate submodule. I think this helps clarify that these prefixes are
purely abstract: they only depend on each other, and do not depend on
any of the other code in `nodes.rs` in any way. Moreover, while various
AST nodes _use_ them, they're not really nodes themselves, so they feel
slightly out of place in `nodes.rs`.
I considered moving all of them to `str.rs`, but it felt like enough
code that it could be a separate submodule.
## Test Plan
`cargo test`
Followup on #11168 and resolve#10391
# User facing changes
* F401 now recommends a fix to add unused import bindings to to
`__all__` if a single `__all__` list or tuple is found in `__init__.py`.
* If there are no `__all__` found in the file, fall back to recommending
redundant-aliases.
* If there are multiple `__all__` or only one but of the wrong type (non
list or tuple) then diagnostics are generated without fixes.
* `fix_title` is updated to reflect what the fix/recommendation is.
Subtlety: For a renamed import such as `import foo as bees`, we can
generate a fix to add `bees` to `__all__` but cannot generate a fix to
produce a redundant import (because that would break uses of the binding
`bees`).
# Implementation changes
* Add `name` field to `ImportBinding` to contain the name of the
_binding_ we want to add to `__all__` (important for the `import foo as
bees` case). It previously only contained the `AnyImport` which can give
us information about the import but not the binding.
* Add `binding` field to `UnusedImport` to contain the same. (Naming
note: the field `name` field already existed on `UnusedImport` and
contains the qualified name of the imported symbol/module)
* Change `fix_by_reexporting` to branch on the size of `dunder_all:
Vec<&Expr>`
* For length 0 call the edit-producing function `make_redundant_alias`.
* For length 1 call edit-producing function `add_to_dunder_all`.
* Otherwise, produce no fix.
* Implement the edit-producing function `add_to_dunder_all` and add unit
tests.
* Implement several fixture tests: empty `__all__ = []`, nonempty
`__all__ = ["foo"]`, mis-typed `__all__ = None`, plus-eq `__all__ +=
["foo"]`
* `UnusedImportContext::Init` variant now has two fields: whether the
fix is in `__init__.py` and how many `__all__` were found.
# Other changes
* Remove a spurious pattern match and instead use field lookups b/c the
addition of a field would have required changing the unrelated pattern.
* Tweak input type of `make_redundant_alias`
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR follows up from #11420 to move `UP034` to use `TokenKind`
instead of `Tok`.
The main reason to have a separate PR is so that the reviewing is easy.
This required a lot more updates because the rule used an index (`i`) to
keep track of the current position in the token vector. Now, as it's
just an iterator, we just use `next` to move the iterator forward and
extract the relevant information.
This is part of https://github.com/astral-sh/ruff/issues/11401
## Test Plan
`cargo test`
## Summary
This PR moves the following rules to use `TokenKind` instead of `Tok`:
* `PLE2510`, `PLE2512`, `PLE2513`, `PLE2514`, `PLE2515`
* `E701`, `E702`, `E703`
* `ISC001`, `ISC002`
* `COM812`, `COM818`, `COM819`
* `W391`
I've paused here because the next set of rules
(`pyupgrade::rules::extraneous_parentheses`) indexes into the token
slice but we only have an iterator implementation. So, I want to isolate
that change to make sure the logic is still the same when I move to
using the iterator approach.
This is part of #11401
## Test Plan
`cargo test`
## Summary
Alternative to #11237
This PR adds a new `Tokens` struct which is a newtype wrapper around a
vector of lexer output. This allows us to add a `kinds` method which
returns an iterator over the corresponding `TokenKind`. This iterator is
implemented as a separate `TokenKindIter` struct to allow using the type
and provide additional methods like `peek` directly on the iterator.
This exposes the linter to access the stream of `TokenKind` instead of
`Tok`.
Edit: I've made the necessary downstream changes and plan to merge the
entire stack at once.
## Summary
This PR updates the linter benchmark to use the `tokenize` function
instead of the lexer.
The linter expects the token list to be up to and including the first
error which is what the `ruff_python_parser::tokenize` function returns.
This was not a problem before because the benchmarks only uses valid
Python code.
## Summary
This PR adds a newtype wrapper around `Vec<FStringElement>` that derefs
to a `&Vec<FStringElement>`.
Both f-string and format specifier are made up of `Vec<FStringElement>`.
By creating a newtype wrapper around it, we can share the methods for
both parent types.
## Summary
This PR adds support to iterate over each part of a string-like
expression.
This similar to the one in the formatter:
128414cd95/crates/ruff_python_formatter/src/string/any.rs (L121-L125)
Although I don't think it's a 1-1 replacement in the formatter because
the one implemented in the formatter has another information for certain
variants (as can be seen for `FString`).
The main motivation for this is to avoid duplication for rules which
work only on the parts of the string and doesn't require any information
from the parent node. Here, the parent node being the expression node
which could be an implicitly concatenated string.
This PR also updates certain rule implementation to make use of this and
avoids logic duplication.
## Summary
This PR renames `AnyStringKind` to `AnyStringFlags` and `AnyStringFlags`
to `AnyStringFlagsInner`.
The main motivation is to have consistent usage of "kind" and "flags".
For each string kind, it's "flags" like `StringLiteralFlags`,
`BytesLiteralFlags`, and `FStringFlags` but it was `AnyStringKind` for
the "any" variant.
## Summary
Changes `future-rewritable-type-annotation` (`FA100`) message to be less
confusing. Uses phrasing from the rule documentation to be consistent.
For example,
```
from_typing_import.py:5:13: FA100 Add `from __future__ import annotations` to rewrite `typing.List` more succinctly
```
Closes#10573.
## Test Plan
`cargo nextest run`
## Summary
Should this consider the decorator only if the name is actually a
property or is the logic in this PR correct?
fixes: #11358
## Test Plan
Add test case.
## Summary
This PR fixes a bug where the auto-fix for `TCH005` would delete the
entire `if` statement.
The fix in this PR is to not consider it a violation if there are any
`elif`/`else` blocks. This also matches the behavior of the original
plugin.
fixes: #11368
## Test plan
Add test cases.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/10594.
Code actions to disable a diagnostic via `noqa` comment are now
available.
https://github.com/astral-sh/ruff/assets/19577865/6d3bcf11-a9d9-499b-8c7f-a10cd39cfbba
`DiagnosticFix` has been changed so that `noqa` code actions appear even
for diagnostics with no available quick fix. It can contain quick fix
edits, `noqa` comment edits, or both.
## Test Plan
The scenarios that need to be tested are as follows:
* A code action to disable a diagnostic should be available for every
diagnostic.
* Using this code action should append to the appropriate line with the
diagnostic, or modify an existing `noqa` comment.
* Adding a `noqa` comment manually should make a diagnostic disappear
* `Fix all auto-fixable problems` should not add `noqa` comments
* Removing a code from a `noqa` comment should make the diagnostic
re-appear
## Summary
`--add-noqa` now runs in two stages: first, the linter finds all
diagnostics that need noqa comments and generate edits on a per-line
basis. Second, these edits are applied, in order, to the document.
A public-facing function, `generate_noqa_edits`, has also been
introduced, which returns noqa edits generated on a per-diagnostic
basis. This will be used by `ruff server` for noqa comment quick-fixes.
## Test Plan
Unit tests have been updated.
## Summary
This PR adds updates the semantic model to detect attribute docstring.
Refer to [PEP 258](https://peps.python.org/pep-0258/#attribute-docstrings)
for the definition of an attribute docstring.
This PR doesn't add full support for it but only considers string
literals as attribute docstring for the following cases:
1. A string literal following an assignment statement in the **global
scope**.
2. A global class attribute
For an assignment statement, it's considered an attribute docstring only
if the target expression is a name expression (`x = 1`). So, chained
assignment, multiple assignment or unpacking, and starred expression,
which are all valid in the target position, aren't considered here.
In `__init__` method, an assignment to the `self` variable like `self.x = 1`
is also a candidate for an attribute docstring. **This PR does not
support this position.**
## Test Plan
I used the following source code along with a print statement to verify
that the attribute docstring detection is correct.
Refer to the PR description for the code snippet.
I'll add this in the follow-up PR
(https://github.com/astral-sh/ruff/pull/11302) which uses this method.
## Summary
Lots of TODOs and things to clean up here, but it demonstrates the
working lint rule.
## Test Plan
```
➜ cat main.py
from typing import override
from base import B
class C(B):
@override
def method(self): pass
➜ cat base.py
class B: pass
➜ cat typing.py
def override(func):
return func
```
(We provide our own `typing.py` since we don't have typeshed vendored or
type stub support yet.)
```
➜ ./target/debug/red_knot main.py
...
1 0.012086s TRACE red_knot Main Loop: Tick
[crates/red_knot/src/main.rs:157:21] diagnostics = [
"Method C.method is decorated with `typing.override` but does not override any base class method",
]
```
If we add `def method(self): pass` to class `B` in `base.py` and run
red_knot again, there is no lint error.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves#11263
Detect `pathlib.Path.open` calls which do not specify a file encoding.
## Test Plan
Test cases added to fixture.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
This PR vendors typeshed!
- The first commit vendors the stdlib directory from typeshed into a new crates/red_knot/vendored_typeshed directory.
- The second commit adjusts various linting config files to make sure that the vendored code is excluded from typo checks, formatting checks, etc.
- The LICENSE and README.md files are also vendored, but all other directories and files (stubs, scripts, tests, test_cases, etc.) are excluded. We should have no need for them (except possibly stubs/, discussed in more depth below).
- Similar to the way pyright has a commit.txt file in its vendored copy of typeshed, to indicate which typeshed commit the vendored code corresponds to, I've also added a crates/red_knot/vendored_typeshed/source_commit.txt file in the third commit of this PR.
One open question is: should we vendor the stdlib and stubs directories, or just the stdlib directory? The stubs/ directory contains stubs for 162 third-party packages outside the stdlib. Mypy and typeshed_client1 only vendor the stdlib directory; pyright and pyre vendor both the stdlib and stubs directories; pytype vendors the entire typeshed repo (scripts/, tests/ and all).
In this PR, I've chosen to copy mypy and typeshed_client. Unlike vendoring the stdlib, which is unavoidable if we want to do typechecking of the stdlib, it's not strictly necessary to vendor the stubs directory: each subdirectory in stubs is published to PyPI as a standalone stubs distribution that can be (uv)-pip-installed into a virtual environment. It might be useful for our users if we vendored those stubs anyway, but there are costs as well as benefits to doing so (apart from just the sheer amount of vendored code in the ruff repository), so I'd rather consider it separately.
Resolves https://github.com/astral-sh/ruff/issues/11313
## Summary
PLR0912(too-many-branches) did not count branches inside with: blocks.
With this fix, the branches inside with statements are also counted.
## Test Plan
Added a new test case.
## Summary
This PR removes the cyclic dev dependency some of the crates had with
the parser crate.
The cyclic dependencies are:
* `ruff_python_ast` has a **dev dependency** on `ruff_python_parser` and
`ruff_python_parser` directly depends on `ruff_python_ast`
* `ruff_python_trivia` has a **dev dependency** on `ruff_python_parser`
and `ruff_python_parser` has an indirect dependency on
`ruff_python_trivia` (`ruff_python_parser` - `ruff_python_ast` -
`ruff_python_trivia`)
Specifically, this PR does the following:
* Introduce two new crates
* `ruff_python_ast_integration_tests` and move the tests from the
`ruff_python_ast` crate which uses the parser in this crate
* `ruff_python_trivia_integration_tests` and move the tests from the
`ruff_python_trivia` crate which uses the parser in this crate
### Motivation
The main motivation for this PR is to help development. Before this PR,
`rust-analyzer` wouldn't provide any intellisense in the
`ruff_python_parser` crate regarding the symbols in `ruff_python_ast`
crate.
```
[ERROR][2024-05-03 13:47:06] .../vim/lsp/rpc.lua:770 "rpc" "/Users/dhruv/.cargo/bin/rust-analyzer" "stderr" "[ERROR project_model::workspace] cyclic deps: ruff_python_parser(Idx::<CrateData>(50)) -> ruff_python_ast(Idx::<CrateData>(37)), alternative path: ruff_python_ast(Idx::<CrateData>(37)) -> ruff_python_parser(Idx::<CrateData>(50))\n"
```
## Test Plan
Check the logs of `rust-analyzer` to not see any signs of cyclic
dependency.
## Summary
While I was here, I also updated the rule to use
`function_type::classify` rather than hard-coding `staticmethod` and
friends.
Per Carl:
> Enum instances are already referred to by the class, forming a cycle
that won't get collected until the class itself does. At which point the
`lru_cache` itself would be collected, too.
Closes https://github.com/astral-sh/ruff/issues/9912.
## Summary
Historically, we only ignored `flake8-blind-except` if you re-raised or
logged the exception as a _direct_ child statement; but it could be
nested somewhere. This was just a known limitation at the time of adding
the previous logic.
Closes https://github.com/astral-sh/ruff/issues/11289.
## Summary
A follow-up to https://github.com/astral-sh/ruff/pull/11222. `ruff
server` stalls during shutdown with Neovim because after it receives an
exit notification and closes the I/O thread, it attempts to log a
success message to `stderr`. Removing this log statement fixes this
issue.
## Test Plan
Track the instances of `ruff` in the OS task manager as you open and
close Neovim. A new instance should appear when Neovim starts and it
should disappear once Neovim is closed.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11258.
This PR fixes the settings resolver to match the expected behavior when
file-based configuration is not available.
## Test Plan
In a workspace with no file-based configuration, set a setting in your
editor and confirm that this setting is used instead of the default.
## Summary
Users can now include tildes and environment variables in the provided
path, just like with `--config`.
Closes#11277.
## Test Plan
Set the configuration path to `"ruff.configuration": "~/x.toml"`;
verified that the server attempted to read from `/Users/crmarsh/x.toml`.
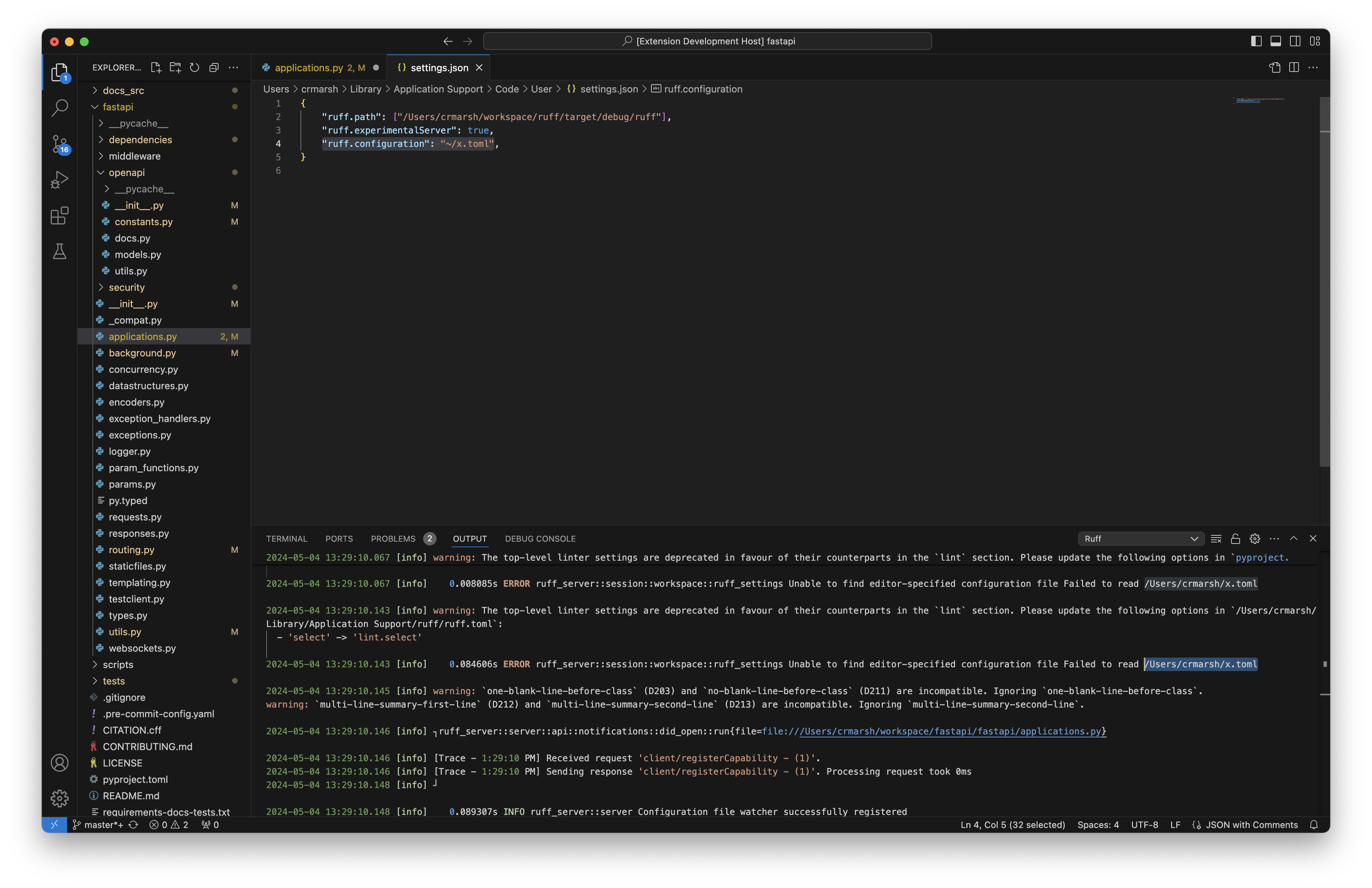
## Summary
Change `hardcoded-tmp-directory-extend` example to follow the schema:
1e91a09918/ruff.schema.json (L896-L901)
<!-- What's the purpose of the change? What does it do, and why? -->
## Summary
In #9218 `Rule::NeverUnion` was partially removed from a
`checker.any_enabled` call. This makes the change consistent.
## Test Plan
`cargo test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11207.
The server would hang after handling a shutdown request on
`IoThreads::join()` because a global sender (`MESSENGER`, used to send
`window/showMessage` notifications) would remain allocated even after
the event loop finished, which kept the writer I/O thread channel open.
To fix this, I've made a few structural changes to `ruff server`. I've
wrapped the send/receive channels and thread join handle behind a new
struct, `Connection`, which facilitates message sending and receiving,
and also runs `IoThreads::join()` after the event loop finishes. To
control the number of sender channels, the `Connection` wraps the sender
channel in an `Arc` and only allows the creation of a wrapper type,
`ClientSender`, which hold a weak reference to this `Arc` instead of
direct channel access. The wrapper type implements the channel methods
directly to prevent access to the inner channel (which would allow the
channel to be cloned). ClientSender's function is analogous to
[`WeakSender` in
`tokio`](https://docs.rs/tokio/latest/tokio/sync/mpsc/struct.WeakSender.html).
Additionally, the receiver channel cannot be accessed directly - the
`Connection` only exposes an iterator over it.
These changes will guarantee that all channels are closed before the I/O
threads are joined.
## Test Plan
Repeatedly open and close an editor utilizing `ruff server` while
observing the task monitor. The net total amount of open `ruff`
instances should be zero once all editor windows have closed.
The following logs should also appear after the server is shut down:
<img width="835" alt="Screenshot 2024-04-30 at 3 56 22 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/404b74f5-ef08-4bb4-9fa2-72e72b946695">
This can be tested on VS Code by changing the settings and then checking
`Output`.
* Add `decorators: Vec<Type>` to `FunctionType` struct
* Thread decorators through two `add_function` definitions
* Populate decorators at the callsite in `infer_symbol_type`
* Small test
Resolves#10390 and starts to address #10391
# Changes to behavior
* In `__init__.py` we now offer some fixes for unused imports.
* If the import binding is first-party this PR suggests a fix to turn it
into a redundant alias.
* If the import binding is not first-party, this PR suggests a fix to
remove it from the `__init__.py`.
* The fix-titles are specific to these new suggested fixes.
* `checker.settings.ignore_init_module_imports` setting is
deprecated/ignored. There is probably a documentation change to make
that complete which I haven't done.
---
<details><summary>Old description of implementation changes</summary>
# Changes to the implementation
* In the body of the loop over import statements that contain unused
bindings, the bindings are partitioned into `to_reexport` and
`to_remove` (according to how we want to resolve the fact they're
unused) with the following predicate:
```rust
in_init && is_first_party(checker, &import.qualified_name().to_string())
// true means make it a reexport
```
* Instead of generating a single fix per import statement, we now
generate up to two fixes per import statement:
```rust
(fix_by_removing_imports(checker, node_id, &to_remove, in_init).ok(),
fix_by_reexporting(checker, node_id, &to_reexport, dunder_all).ok())
```
* The `to_remove` fixes are unsafe when `in_init`.
* The `to_explicit` fixes are safe. Currently, until a future PR, we
make them redundant aliases (e.g. `import a` would become `import a as
a`).
## Other changes
* `checker.settings.ignore_init_module_imports` is deprecated/ignored.
Instead, all fixes are gated on `checker.settings.preview.is_enabled()`.
* Got rid of the pattern match on the import-binding bound by the inner
loop because it seemed less readable than referencing fields on the
binding.
* [x] `// FIXME: rename "imports" to "bindings"` if reviewer agrees (see
code)
* [x] `// FIXME: rename "node_id" to "import_statement"` if reviewer
agrees (see code)
<details>
<summary><h2>Scope cut until a future PR</h2></summary>
* (Not implemented) The `to_explicit` fixes will be added to `__all__`
unless it doesn't exist. When `__all__` doesn't exist they're resolved
by converting to redundant aliases (e.g. `import a` would become `import
a as a`).
---
</details>
# Test plan
* [x] `crates/ruff_linter/resources/test/fixtures/pyflakes/F401_24`
contains an `__init__.py` with*out* `__all__` that exercises the
features in this PR, but it doesn't pass.
* [x]
`crates/ruff_linter/resources/test/fixtures/pyflakes/F401_25_dunder_all`
contains an `__init__.py` *with* `__all__` that exercises the features
in this PR, but it doesn't pass.
* [x] Write unit tests for the new edit functions in
`fix::edits::make_redundant_alias`.
</details>
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR removes the `ImportMap` implementation and all its routing
through ruff.
The import map was added in https://github.com/astral-sh/ruff/pull/3243
but we then never ended up using it to do cross file analysis.
We are now working on adding multifile analysis to ruff, and revisit
import resolution as part of it.
```
hyperfine --warmup 10 --runs 20 --setup "./target/release/ruff clean" \
"./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I" \
"./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 37.6 ms ± 0.9 ms [User: 52.2 ms, System: 63.7 ms]
Range (min … max): 35.8 ms … 39.8 ms 20 runs
Benchmark 2: ./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 36.0 ms ± 0.7 ms [User: 50.3 ms, System: 58.4 ms]
Range (min … max): 34.5 ms … 37.6 ms 20 runs
Summary
./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I ran
1.04 ± 0.03 times faster than ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
```
I suspect that the performance improvement should even be more
significant for users that otherwise don't have any diagnostics.
```
hyperfine --warmup 10 --runs 20 --setup "cd ../ecosystem/airflow && ../../ruff/target/release/ruff clean" \
"./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I" \
"./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 53.7 ms ± 1.8 ms [User: 68.4 ms, System: 63.0 ms]
Range (min … max): 51.1 ms … 58.7 ms 20 runs
Benchmark 2: ./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 50.8 ms ± 1.4 ms [User: 50.7 ms, System: 60.9 ms]
Range (min … max): 48.5 ms … 55.3 ms 20 runs
Summary
./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I ran
1.06 ± 0.05 times faster than ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
```
## Test Plan
`cargo test`
## Summary
Fixes#11185Fixes#11214
Document path and package information is now forwarded to the Ruff
linter, which allows `per-file-ignores` to correctly match against the
file name. This also fixes an issue where the import sorting rule didn't
distinguish between third-party and first-party packages since we didn't
pass in the package root.
## Test Plan
`per-file-ignores` should ignore files as expected. One quick way to
check is by adding this to your `pyproject.toml`:
```toml
[tool.ruff.lint.per-file-ignores]
"__init__.py" = ["ALL"]
```
Then, confirm that no diagnostics appear when you add code to an
`__init__.py` file (besides syntax errors).
The import sorting fix can be verified by failing to reproduce the
original issue - an `I001` diagnostic should not appear in
`other_module.py`.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11158.
A settings file in the ruff user configuration directory will be used as
a configuration fallback, if it exists.
## Test Plan
Create a `pyproject.toml` or `ruff.toml` configuration file in the ruff
user configuration directory.
* On Linux, that will be `$XDG_CONFIG_HOME/ruff/` or `$HOME/.config`
* On macOS, that will be `$HOME/Library/Application Support`
* On Windows, that will be `{FOLDERID_LocalAppData}`
Then, open a file inside of a workspace with no configuration. The
settings in the user configuration file should be used.
## Summary
I think the check included here does make sense, but I don't see why we
would allow it if a value is provided for the attribute -- since, in
that case, isn't it _not_ abstract?
Closes: https://github.com/astral-sh/ruff/issues/11208.
## Summary
This PR changes the `DebugStatistics` and `ReleaseStatistics` structs so
that they implement a common `StatisticsRecorder` trait, and makes the
`KeyValueCache` struct generic over a type parameter bound to that
trait. The advantage of this approach is that it's much harder for the
`DebugStatistics` and `ReleaseStatistics` structs to accidentally grow
out of sync in the methods that they implement, which was the cause of
the release-build failure recently fixed in #11177.
## Test Plan
`cargo test -p red_knot` and `cargo build --release` both continue to
pass for me locally
* Adds `Symbol.flag` bitfield. Populates it from (the three renamed)
`add_or_update_symbol*` methods.
* Currently there are these flags supported:
* `IS_DEFINED` is set in a scope where a variable is defined.
* `IS_USED` is set in a scope where a variable is referenced. (To have
both this and `IS_DEFINED` would require two separate appearances of a
variable in the same scope-- one def and one use.)
* `MARKED_GLOBAL` and `MARKED_NONLOCAL` are **not yet implemented**.
(*TODO: While traversing, if you find these declarations, add these
flags to the variable.*)
* Adds `Symbol.kind` field (commented) and the data structure which will
populate it: `Kind` which is an enum of freevar, cellvar,
implicit_global, and implicit_local. **Not yet populated**. (*TODO: a
second pass over the scope (or the ast?) will observe the
`MARKED_GLOBAL` and `MARKED_NONLOCAL` flags to populate this field. When
that's added, we'll uncomment the field.*)
* Adds a few tests that the `IS_DEFINED` and `IS_USED` fields are
correctly set and/or merged:
* Unit test that subsequent calls to `add_or_update_symbol` will merge
the flag arguments.
* Unit test that in the statement `x = foo`, the variable `foo` is
considered used but not defined.
* Unit test that in the statement `from bar import foo`, the variable
`foo` is considered defined but not used.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR adds a basic README for the `ruff_python_parser` crate and
updates the CONTRIBUTING docs with the fuzzer and benchmark section.
Additionally, it also updates some inline documentation within the
parser crate and splits the `parse_program` function into
`parse_single_expression` and `parse_module` which will be called by
matching against the `Mode`.
This PR doesn't go into too much internal detail around the parser logic
due to the following reasons:
1. Where should the docs go? Should it be as a module docs in `lib.rs`
or in README?
2. The parser is still evolving and could include a lot of refactors
with the future work (feedback loop and improved error recovery and
resilience)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
`cargo build --release` currently fails to compile on `main`:
<details>
```
error[E0599]: no method named `hit` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:22:29
|
22 | self.statistics.hit();
| ^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `hit` not found for this struct
error[E0599]: no method named `miss` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:25:29
|
25 | self.statistics.miss();
| ^^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `miss` not found for this struct
error[E0599]: no method named `hit` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:36:33
|
36 | self.statistics.hit();
| ^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `hit` not found for this struct
error[E0599]: no method named `miss` found for struct `ReleaseStatistics` in the current scope
--> crates/red_knot/src/cache.rs:41:33
|
41 | self.statistics.miss();
| ^^^^ method not found in `ReleaseStatistics`
...
145 | pub struct ReleaseStatistics;
| ---------------------------- method `miss` not found for this struct
```
</details>
This is because in a release build, `CacheStatistics` is a type alias
for `ReleaseStatistics`, and `ReleaseStatistics` doesn't have `hit()` or
`miss()` methods. (In a debug build, `CacheStatistics` is a type alias
for `DebugStatistics`, which _does_ have those methods.)
Possibly we could make this less likely to happen in the future by
making both structs implement a common trait instead of using type
aliases that vary depending on whether it's a debug build or not? For
now, though, this PR just brings the two structs in sync w.r.t. the
methods they expose.
## Test Plan
`cargo build --release` now once again compiles for me locally
## Summary
This PR adds an override to the fixer to ensure that we apply any
`redefined-while-unused` fixes prior to `unused-import`.
Closes https://github.com/astral-sh/ruff/issues/10905.
## Summary
Implement duplicate code detection as part of `RUF100`, mirroring the
behavior of `flake8-noqa` (`NQA005`) mentioned in #850. The idea to
merge the rule into `RUF100` was suggested by @MichaReiser
https://github.com/astral-sh/ruff/pull/10325#issuecomment-2025535444.
## Test Plan
Test cases were added to the fixture.
This syntax wasn't "deprecated" in Python 3; it was removed.
I started looking at this rule because I was curious how Ruff could even
detect this without a Python 2 parser. Then I realized that
"print >> f, x" is actually valid Python 3 syntax: it creates a tuple
containing a right-shifted version of the print function.
## Summary
Based on discussion in #10850.
As it stands today `RUF100` will attempt to replace code redirects with
their target codes even though this is not the "goal" of `RUF100`. This
behavior is confusing and inconsistent, since code redirects which don't
otherwise violate `RUF100` will not be updated. The behavior is also
undocumented. Additionally, users who want to use `RUF100` but do not
want to update redirects have no way to opt out.
This PR explicitly detects redirects with a new rule `RUF101` and
patches `RUF100` to keep original codes in fixes and reporting.
## Test Plan
Added fixture.
## Summary
Closes#10985.
The server now supports a custom TOML configuration file as a client
setting. The setting must be an absolute path to a file. If the file is
called `pyproject.toml`, the server will attempt to parse it as a
pyproject file - otherwise, it will attempt to parse it as a `ruff.toml`
file, even if the file has a name besides `ruff.toml`.
If an option is set in both the custom TOML configuration file and in
the client settings directly, the latter will be used.
## Test Plan
1. Create a `ruff.toml` file outside of the workspace you are testing.
Set an option that is different from the one in the configuration for
your test workspace.
2. Set the path to the configuration in NeoVim:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
configuration = "absolute/path/to/your/configuration"
}
}
}
```
3. Confirm that the option in the configuration file is used, regardless
of what the option is set to in the workspace configuration.
4. Add the same option, with a different value, to the NeoVim
configuration directly. For example:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
configuration = "absolute/path/to/your/configuration",
lint = {
select = []
}
}
}
}
```
5. Confirm that the option set in client settings is used, regardless of
the value in either the custom configuration file or in the workspace
configuration.
## Summary
This PR fixes the bug where the formatter would format an f-string and
could potentially change the AST.
For a triple-quoted f-string, the element can't be formatted into
multiline if it has a format specifier because otherwise the newline
would be treated as part of the format specifier.
Given the following f-string:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f} ddddddddddddddd eeeeeeee"""
```
The formatter sees that the f-string is already multiline so it assumes
that it can contain line breaks i.e., broken into multiple lines. But,
in this specific case we can't format it as:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f
} ddddddddddddddd eeeeeeee"""
```
Because the format specifier string would become ".3f\n", which is not
the original string (`.3f`).
If the original source code already contained a newline, they'll be
preserved. For example:
```python
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {
variable:.3f
} ddddddddddddddd eeeeeeee"""
```
The above will be formatted as:
```py
f"""aaaaaaaaaaaaaaaa bbbbbbbbbbbbbbbbbb ccccccccccc {variable:.3f
} ddddddddddddddd eeeeeeee"""
```
Note that the newline after `.3f` is part of the format specifier which
needs to be preserved.
The Python version is irrelevant in this case.
fixes: #10040
## Test Plan
Add some test cases to verify this behavior.
## Summary
This is intended to address
https://github.com/astral-sh/ruff-vscode/issues/425, and is a follow-up
to https://github.com/astral-sh/ruff/pull/11062.
A new client setting is now supported by the server,
`prioritizeFileConfiguration`. This is a boolean setting (default:
`false`) that, if set to `true`, will instruct the configuration
resolver to prioritize file configuration (aka discovered TOML files)
over configuration passed in by the editor.
A corresponding extension PR has been opened, which makes this setting
available for VS Code:
https://github.com/astral-sh/ruff-vscode/pull/457.
## Test Plan
To test this with VS Code, you'll need to check out [the VS Code
PR](https://github.com/astral-sh/ruff-vscode/pull/457) that adds this
setting.
The test process is similar to
https://github.com/astral-sh/ruff/pull/11062, but in scenarios where the
editor configuration would take priority over file configuration, file
configuration should take priority.
## Summary
Resolves#11102
The error stems from these lines
f5c7a62aa6/crates/ruff_linter/src/noqa.rs (L697-L702)
I don't really understand the purpose of incrementing the last index,
but it makes the resulting range invalid for indexing into `contents`.
For now I just detect if the index is too high in `blanket_noqa` and
adjust it if necessary.
## Test Plan
Created fixture from issue example.
## Summary
This PR updates the playground to display the AST even if it contains a
syntax error. This could be useful for development and also to give a
quick preview of what error recovery looks like.
Note that not all recovery is correct but this allows us to iterate
quickly on what can be improved.
## Test Plan
Build the playground locally and test it.
<img width="1688" alt="Screenshot 2024-04-25 at 21 02 22"
src="https://github.com/astral-sh/ruff/assets/67177269/2b94934c-4f2c-4a9a-9693-3d8460ed9d0b">
## Summary
Fixes#11114.
As part of the `onClose` handler, we publish an empty array of
diagnostics for the document being closed, similar to
[`ruff-lsp`](187d7790be/ruff_lsp/server.py (L459-L464)).
This prevent phantom diagnostics from lingering after a document is
closed. We'll only do this if the client doesn't support pull
diagnostics, because otherwise clearing diagnostics is their
responsibility.
## Test Plan
Diagnostics should no longer appear for a document in the Problems tab
after the document is closed.
## Summary
This allows `raise from` in BLE001.
```python
try:
...
except Exception as e:
raise ValueError from e
```
Fixes#10806
## Test Plan
Test case added.
## Summary
Continuation of https://github.com/astral-sh/ruff/pull/9444.
> When the formatter is fully cached, it turns out we actually spend
meaningful time mapping from file to `Settings` (since we use a
hierarchical approach to settings). Using `matchit` rather than
`BTreeMap` improves fully-cached performance by anywhere from 2-5%
depending on the project, and since these are all implementation details
of `Resolver`, it's minimally invasive.
`matchit` supports escaping routing characters so this change should now
be fully compatible.
## Test Plan
On my machine I'm seeing a ~3% improvement with this change.
```
hyperfine --warmup 20 -i "./target/release/main format ../airflow" "./target/release/ruff format ../airflow"
Benchmark 1: ./target/release/main format ../airflow
Time (mean ± σ): 58.1 ms ± 1.4 ms [User: 63.1 ms, System: 66.5 ms]
Range (min … max): 56.1 ms … 62.9 ms 49 runs
Benchmark 2: ./target/release/ruff format ../airflow
Time (mean ± σ): 56.6 ms ± 1.5 ms [User: 57.8 ms, System: 67.7 ms]
Range (min … max): 54.1 ms … 63.0 ms 51 runs
Summary
./target/release/ruff format ../airflow ran
1.03 ± 0.04 times faster than ./target/release/main format ../airflow
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Add support for hover menu to ruff_server, as requested in
[10595](https://github.com/astral-sh/ruff/issues/10595).
Majority of new code is in hover.rs.
I reused the regex from ruff-lsp's implementation. Also reused the
format_rule_text function from ruff/src/commands/rule.rs
Added capability registration in server.rs, and added the handler to
api.rs.
## Test Plan
Tested in NVIM v0.10.0-dev-2582+g2a8cef6bd, configured with lspconfig
using the default options (other than cmd pointing to my test build,
with options "server" and "--preview"). OS: Ubuntu 24.04, kernel
6.8.0-22.
---------
Co-authored-by: Jane Lewis <me@jane.engineering>
## Summary
This is a follow-up to https://github.com/astral-sh/ruff/pull/10984 that
implements configuration resolution for editor configuration. By 'editor
configuration', I'm referring to the client settings that correspond to
Ruff configuration/options, like `preview`, `select`, and so on. These
will be combined with 'project configuration' (configuration taken from
project files such as `pyproject.toml`) to generate the final linter and
formatter settings used by `RuffSettings`. Editor configuration takes
priority over project configuration.
In a follow-up pull request, I'll implement a new client setting that
allows project configuration to override editor configuration, as per
[this issue](https://github.com/astral-sh/ruff-vscode/issues/425).
## Review guide
The first commit, e38966d8843becc7234fa7d46009c16af4ba41e9, is just
doing re-arrangement so that we can pass the right things to
`RuffSettings::resolve`. The actual resolution logic is in the second
commit, 0eec9ee75c10e5ec423bd9f5ce1764f4d7a5ad86. It might help to look
at these comments individually since the diff is rather messy.
## Test Plan
For the settings to show up in VS Code, you'll need to checkout this
branch: https://github.com/astral-sh/ruff-vscode/pull/456.
To test that the resolution for a specific setting works as expected,
run through the following scenarios, setting it in project and editor
configuration as needed:
| Set in project configuration? | Set in editor configuration? |
Expected Outcome |
|-------------------------------|--------------------------------------------------|------------------------------------------------------------------------------------------|
| No | No | The editor should behave as if the setting was set to its
default value. |
| Yes | No | The editor should behave as if the setting was set to the
value in project configuration. |
| No | Yes | The editor should behave as if the setting was set to the
value in editor configuration. |
| Yes | Yes (but distinctive from project configuration) | The editor
should behave as if the setting was set to the value in editor
configuration. |
An exception to this is `extendSelect`, which does not have an analog in
TOML configuration. Instead, you should verify that `extendSelect`
amends the `select` setting. If `select` is set in both editor and
project configuration, `extendSelect` will only append to the `select`
value in editor configuration, so make sure to un-set it there if you're
testing `extendSelect` with `select` in project configuration.
## Summary
This PR refactors unary expression parsing with the following changes:
* Ability to get `OperatorPrecedence` from a unary operator (`UnaryOp`)
* Implement methods on `TokenKind`
* Add `as_unary_operator` which returns an `Option<UnaryOp>`
* Add `as_unary_arithmetic_operator` which returns an `Option<UnaryOp>`
(used for pattern parsing)
* Rename `is_unary` to `is_unary_arithmetic_operator` (used in the
linter)
resolves: #10752
## Test Plan
Verify that the existing test cases pass, no ecosystem changes, run the
Python based fuzzer on 3000 random inputs and run it on dozens of
open-source repositories.
## Summary
This PR refactors the binary expression parsing in a way to make it
readable and easy to understand. It draws inspiration from the suggested
edits in the linked messages in #10752.
### Changes
* Ability to get the precedence of an operator
* From a boolean operator (`BinOp`) to `OperatorPrecedence`
* From a binary operator (`Operator`) to `OperatorPrecedence`
* No comparison operator because all of them have the same precedence
* Implement methods on `TokenKind` to convert it to an appropriate
operator enum
* Add `as_boolean_operator` which returns an `Option<BoolOp>`
* Add `as_binary_operator` which returns an `Option<Operator>`
* No `as_comparison_operator` because it requires lookahead and I'm not
sure if `token.as_comparison_operator(peek)` is a good way to implement
it
* Introduce `BinaryLikeOperator`
* Constructed from two tokens using the methods from the second point
* Add `precedence` method using the conversion methods mentioned in the
first point
* Make most of the functions in `TokenKind` private to the module
* Use `self` instead of `&self` for `TokenKind`
fixes: #11072
## Test Plan
Refer #11088
## Summary
This PR does a few things but the main change is that is makes
associativity a property of operator precedence.
1. Rename `Precedence` -> `OperatorPrecedence`
2. Rename `parse_expression_with_precedence` ->
`parse_binary_expression_or_higher`
3. Move `current_binding_power` to `OperatorPrecedence::try_from_tokens`
[^1]
4. Add a `OperatorPrecedence::is_right_associative` method
5. Move from `increment_precedence` to using `<=` / `<` to check if the
parsing loop needs to stop [^2]
[^1]: Another alternative would be to have two separate methods to avoid
lookahead as it's required only for once case (`not in`). So,
`try_from_current_token(current).or_else(|| try_from_next_token(current,
peek))`
[^2]: This will allow us to easily make the refactors mentioned in
#10752
## Test Plan
Make sure the precedence parsing algorithm is still correct by running
the test suite, fuzz testing it and running it against a dozen or so
open-source repositories.
## Summary
This PR adds a new `ExpressionContext` struct which is used in
expression parsing.
This solves the following problem:
1. Allowing starred expression with different precedence
2. Allowing yield expression in certain context
3. Remove ambiguity with `in` keyword when parsing a `for ... in`
statement
For context, (1) was solved by adding `parse_star_expression_list` and
`parse_star_expression_or_higher` in #10623, (2) was solved by by adding
`parse_yield_expression_or_else` in #10809, and (3) was fixed in #11009.
All of the mentioned functions have been removed in favor of the context
flags.
As mentioned in #11009, an ideal solution would be to implement an
expression context which is what this PR implements. This is passed
around as function parameter and the call stack is used to automatically
reset the context.
### Recovery
How should the parser recover if the target expression is invalid when
an expression can consume the `in` keyword?
1. Should the `in` keyword be part of the target expression?
2. Or, should the expression parsing stop as soon as `in` keyword is
encountered, no matter the expression?
For example:
```python
for yield x in y: ...
# Here, should this be parsed as
for (yield x) in (y): ...
# Or
for (yield x in y): ...
# where the `in iter` part is missing
```
Or, for binary expression parsing:
```python
for x or y in z: ...
# Should this be parsed as
for (x or y) in z: ...
# Or
for (x or y in z): ...
# where the `in iter` part is missing
```
This need not be solved now, but is very easy to change. For context
this PR does the following:
* For binary, comparison, and unary expressions, stop at `in`
* For lambda, yield expressions, consume the `in`
## Test Plan
1. Add test cases for the `for ... in` statement and verify the
snapshots
2. Make sure the existing test suite pass
3. Run the fuzzer for around 3000 generated source code
4. Run the updated logic on a dozen or so open source repositories
(codename "parser-checkouts")
## Summary
Fixes#11059
Several major editors don't support [pull
diagnostics](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#textDocument_pullDiagnostics),
a method of sending diagnostics to the client that was introduced in
version `0.3.17` of the specification. Until now, `ruff server` has only
used pull diagnostics, which resulted in diagnostics not being available
on Neovim and Helix, which don't support pull diagnostics yet (though
Neovim `10.0` will have support for this).
`ruff server` will now utilize the older method of sending diagnostics,
known as 'publish diagnostics', when pull diagnostics aren't supported
by the client. This involves re-linting a document every time it is
opened or modified, and then sending the diagnostics generated from that
lint to the client via the `textDocument/publishDiagnostics`
notification.
## Test Plan
The easiest way to test that this PR works is to check if diagnostics
show up on Neovim `<=0.9`.
## Summary
Fixes#10463
Add `FURB192` which detects violations like this:
```python
# Bad
a = sorted(l)[0]
# Good
a = min(l)
```
There is a caveat that @Skylion007 has pointed out, which is that
violations with `reverse=True` technically aren't compatible with this
change, in the edge case where the unstable behavior is intended. For
example:
```python
from operator import itemgetter
data = [('red', 1), ('blue', 1), ('red', 2), ('blue', 2)]
min(data, key=itemgetter(0)) # ('blue', 1)
sorted(data, key=itemgetter(0))[0] # ('blue', 1)
sorted(data, key=itemgetter(0), reverse=True)[-1] # ('blue, 2')
```
This seems like a rare edge case, but I can make the `reverse=True`
fixes unsafe if that's best.
## Test Plan
This is unit tested.
## References
https://github.com/dosisod/refurb/pull/333/files
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
The `operator.itemgetter` behavior changes where there's more than one
argument, such that `operator.itemgetter(0)` yields `r[0]`, rather than
`(r[0],)`.
Closes https://github.com/astral-sh/ruff/issues/11075.
## Summary
There is no class `integer` in python, nor is there a type `integer`, so
I updated the docs to remove the backticks on these references, such
that it is the representation of an integer, and not a reference.
## Summary
Move `blanket-noqa` rule from the token checker to the noqa checker.
This allows us to make use of the line directives already computed in
the noqa checker.
## Test Plan
Verified test results are unchanged.
Resolves#10187
<details>
<summary>Old PR description; accurate through commit e86dd7d; probably
best to leave this fold closed</summary>
## Description of change
In the case of a printf-style format string with only one %-placeholder
and a variable at right (e.g. `"%s" % var`):
* The new behavior attempts to dereference the variable and then match
on the bound expression to distinguish between a 1-tuple (fix), n-tuple
(bug 🐛), or a non-tuple (fix). Dereferencing is via
`analyze::typing::find_binding_value`.
* If the variable cannot be dereferenced, then the type-analysis routine
is called to distinguish only tuple (no-fix) or non-tuple (fix). Type
analysis is via `analyze::typing::is_tuple`.
* If any of the above fails, the rule still fires, but no fix is
offered.
## Alternatives
* If the reviewers think that singling out the 1-tuple case is too
complicated, I will remove that.
* The ecosystem results show that no new fixes are detected. So I could
probably delete all the variable dereferencing code and code that tries
to generate fixes, tbh.
## Changes to existing behavior
**All the previous rule-firings and fixes are unchanged except for** the
"false negatives" in
`crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_1.py`. Those
previous "false negatives" are now true positives and so I moved them to
`crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py`.
<details>
<summary>Existing false negatives that are now true positives</summary>
```
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:134:1: UP031 Use format specifiers instead of percent format
|
133 | # UP031 (no longer false negatives)
134 | 'Hello %s' % bar
| ^^^^^^^^^^^^^^^^ UP031
135 |
136 | 'Hello %s' % bar.baz
|
= help: Replace with format specifiers
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:136:1: UP031 Use format specifiers instead of percent format
|
134 | 'Hello %s' % bar
135 |
136 | 'Hello %s' % bar.baz
| ^^^^^^^^^^^^^^^^^^^^ UP031
137 |
138 | 'Hello %s' % bar['bop']
|
= help: Replace with format specifiers
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:138:1: UP031 Use format specifiers instead of percent format
|
136 | 'Hello %s' % bar.baz
137 |
138 | 'Hello %s' % bar['bop']
| ^^^^^^^^^^^^^^^^^^^^^^^ UP031
|
= help: Replace with format specifiers
```
One of them newly offers a fix.
```
# UP031 (no longer false negatives)
-'Hello %s' % bar
+'Hello {}'.format(bar)
```
This fix occurs because the new code dereferences `bar` to where it was
defined earlier in the file as a non-tuple:
```python
bar = {"bar": y}
```
---
</details>
## Behavior requiring new tests
Additionally, we now handle a few cases that we didn't previously test.
These cases are when a string has a single %-placeholder and the
righthand operand to the modulo operator is a variable **which can be
dereferenced.** One of those was shown in the previous section (the
"dereference non-tuple" case).
<details>
<summary>New cases handled</summary>
```
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:126:1: UP031 [*] Use format specifiers instead of percent format
|
125 | t1 = (x,)
126 | "%s" % t1
| ^^^^^^^^^ UP031
127 | # UP031: deref t1 to 1-tuple, offer fix
|
= help: Replace with format specifiers
crates/ruff_linter/resources/test/fixtures/pyupgrade/UP031_0.py:130:1: UP031 Use format specifiers instead of percent format
|
129 | t2 = (x,y)
130 | "%s" % t2
| ^^^^^^^^^ UP031
131 | # UP031: deref t2 to n-tuple, this is a bug
|
= help: Replace with format specifiers
```
One of these offers a fix.
```
t1 = (x,)
-"%s" % t1
+"{}".format(t1[0])
# UP031: deref t1 to 1-tuple, offer fix
```
The other doesn't offer a fix because it's a bug.
---
</details>
---
</details>
## Changes to existing behavior
In the case of a string with a single %-placeholder and a single
ambiguous righthand argument to the modulo operator, (e.g. `"%s" % var`)
the rule now fires and offers a fix. We explain about this in the "fix
safety" section of the updated documentation.
## Documentation changes
I swapped the order of the "known problems" and the "examples" sections
so that the examples which describe the rule are first, before the
exceptions to the rule are described. I also tweaked the language to be
more explicit, as I had trouble understanding the documentation at
first. The "known problems" section is now "fix safety" but the content
is largely similar.
The diff of the documentation changes looks a little difficult unless
you look at the individual commits.
## Summary
I happened to notice that we box `TypeParams` on `StmtClassDef` but not
on `StmtFunctionDef` and wondered why, since `StmtFunctionDef` is bigger
and sets the size of `Stmt`.
@charliermarsh found that at the time we started boxing type params on
classes, classes were the largest statement type (see #6275), but that's
no longer true.
So boxing type-params also on functions reduces the overall size of
`Stmt`.
## Test Plan
The `<=` size tests are a bit irritating (since their failure doesn't
tell you the actual size), but I manually confirmed that the size is
actually 120 now.
Occasionally you intentionally have iterables of differing lengths. The
rule permits this by explicitly adding `strict=False`, but this was not
documented.
## Summary
The rule does not currently document how to avoid it when having
differing length iterables is intentional. This PR adds that to the rule
documentation.
## Summary
This fixes a bug where the parser would panic when there is a "gap" in
the token source.
What's a gap?
The reason it's `<=` instead of just `==` is because there could be
whitespaces between
the two tokens. For example:
```python
# last token end
# | current token (newline) start
# v v
def foo \n
# ^
# assume there's trailing whitespace here
```
Or, there could tokens that are considered "trivia" and thus aren't
emitted by the token
source. These are comments and non-logical newlines. For example:
```python
# last token end
# v
def foo # comment\n
# ^ current token (newline) start
```
In either of the above cases, there's a "gap" between the end of the
last token and start
of the current token.
## Test Plan
Add test cases and update the snapshots.
## Summary
This PR adds a new `Clause::Case` and uses it to parse the body of a
`case` block. Earlier, it was using `Match` which would give an
incorrect error message like:
```
|
1 | match subject:
2 | case 1:
3 | case 2: ...
| ^^^^ Syntax Error: Expected an indented block after `match` statement
|
```
## Test Plan
Add test case and update the snapshot.
Add pylint rule invalid-hash-returned (PLE0309)
See https://github.com/astral-sh/ruff/issues/970 for rules
Test Plan: `cargo test`
TBD: from the description: "Strictly speaking `bool` is a subclass of
`int`, thus returning `True`/`False` is valid. To be consistent with
other rules (e.g.
[PLE0305](https://github.com/astral-sh/ruff/pull/10962)
invalid-index-returned), ruff will raise, compared to pylint which will
not raise."
## Summary
This PR fixes the bug in with items parsing where it would fail to
recognize that the parenthesized expression is part of a large binary
expression.
## Test Plan
Add test cases and verified the snapshots.
## Summary
This PR fixes the bug in parenthesized with items parsing where the `if`
expression would result into a syntax error.
The reason being that once we identify that the ambiguous left
parenthesis belongs to the context expression, the parser converts the
parsed with item into an equivalent expression. Then, the parser
continuous to parse any postfix expressions. Now, attribute, subscript,
and call are taken into account as they're grouped in
`parse_postfix_expression` but `if` expression has it's own parsing
function.
Use `parse_if_expression` once all postfix expressions have been parsed.
Ideally, I think that `if` could be included in postfix expression
parsing as they can be chained as well (`x if True else y if True else
z`).
## Test Plan
Add test cases and verified the snapshots.
## Summary
This PR fixes a bug in the new parser which involves the parser context
w.r.t. for statement. This is specifically around the `in` keyword which
can be present in the target expression and shouldn't be considered to
be part of the `for` statement header. Ideally it should use a context
which is passed between functions, thus using a call stack to set /
unset a specific variant which will be done in a follow-up PR as it
requires some amount of refactor.
## Test Plan
Add test cases and update the snapshots.
(Supersedes #9152, authored by @LaBatata101)
## Summary
This PR replaces the current parser generated from LALRPOP to a
hand-written recursive descent parser.
It also updates the grammar for [PEP
646](https://peps.python.org/pep-0646/) so that the parser outputs the
correct AST. For example, in `data[*x]`, the index expression is now a
tuple with a single starred expression instead of just a starred
expression.
Beyond the performance improvements, the parser is also error resilient
and can provide better error messages. The behavior as seen by any
downstream tools isn't changed. That is, the linter and formatter can
still assume that the parser will _stop_ at the first syntax error. This
will be updated in the following months.
For more details about the change here, refer to the PR corresponding to
the individual commits and the release blog post.
## Test Plan
Write _lots_ and _lots_ of tests for both valid and invalid syntax and
verify the output.
## Acknowledgements
- @MichaReiser for reviewing 100+ parser PRs and continuously providing
guidance throughout the project
- @LaBatata101 for initiating the transition to a hand-written parser in
#9152
- @addisoncrump for implementing the fuzzer which helped
[catch](https://github.com/astral-sh/ruff/pull/10903)
[a](https://github.com/astral-sh/ruff/pull/10910)
[lot](https://github.com/astral-sh/ruff/pull/10966)
[of](https://github.com/astral-sh/ruff/pull/10896)
[bugs](https://github.com/astral-sh/ruff/pull/10877)
---------
Co-authored-by: Victor Hugo Gomes <labatata101@linuxmail.org>
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
The following client settings have been introduced to the language
server:
* `lint.preview`
* `format.preview`
* `lint.select`
* `lint.extendSelect`
* `lint.ignore`
* `exclude`
* `lineLength`
`exclude` and `lineLength` apply to both the linter and formatter.
This does not actually use the settings yet, but makes them available
for future use.
## Test Plan
Snapshot tests have been updated.
## Summary
A setup guide has been written for NeoVim under a new
`crates/ruff_server/docs/setup` folder, where future setup guides will
also go. This setup guide was adapted from the [`ruff-lsp`
guide](https://github.com/astral-sh/ruff-lsp?tab=readme-ov-file#example-neovim).
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Add pylint rule invalid-length-returned (PLE0303)
See https://github.com/astral-sh/ruff/issues/970 for rules
Test Plan: `cargo test`
TBD: from the description: "Strictly speaking `bool` is a subclass of
`int`, thus returning `True`/`False` is valid. To be consistent with
other rules (e.g.
[PLE0305](https://github.com/astral-sh/ruff/pull/10962)
invalid-index-returned), ruff will raise, compared to pylint which will
not raise."
## Summary
If the user is analyzing a script (i.e., we have no module path), it
seems reasonable to use the script name when trying to identify paths to
objects defined _within_ the script.
Closes https://github.com/astral-sh/ruff/issues/10960.
## Test Plan
Ran:
```shell
check --isolated --select=B008 \
--config 'lint.flake8-bugbear.extend-immutable-calls=["test.A"]' \
test.py
```
On:
```python
class A: pass
def f(a=A()):
pass
```
## Summary
The server now requests a [workspace diagnostic
refresh](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#diagnostic_refresh)
when a configuration file gets changed. This means that diagnostics for
all open files will be automatically re-requested by the client on a
config change.
## Test Plan
You can test this by opening several files in VS Code, setting `select`
in your file configuration to `[]`, and observing that the diagnostics
go away once the file is saved (besides any `Pylance` diagnostics).
Restore it to what it was before, and you should see the diagnostics
automatically return once a save happens.
## Summary
I've added support for configuring the `ruff check` output file via the
environment variable `RUFF_OUTPUT_FILE` akin to #1731.
This is super useful when, e.g., generating a [GitLab code quality
report](https://docs.gitlab.com/ee/ci/testing/code_quality.html#implement-a-custom-tool)
while running Ruff as a pre-commit hook. Usually, `ruff check` should
print its human-readable output to `stdout`, but when run through
`pre-commit` _in a GitLab CI job_ it should write its output in `gitlab`
format to a file. So, to override these two settings only during CI,
environment variables come handy, and `RUFF_OUTPUT_FORMAT` already
exists but `RUFF_OUTPUT_FILE` has been missing.
A (simplified) GitLab CI job config for this scenario might look like
this:
```yaml
pre-commit:
stage: test
image: python
variables:
RUFF_OUTPUT_FILE: gl-code-quality-report.json
RUFF_OUTPUT_FORMAT: gitlab
before_script:
- pip install pre-commit
script:
- pre-commit run --all-files --show-diff-on-failure
artifacts:
reports:
codequality: gl-code-quality-report.json
```
## Test Plan
I tested it manually.
## Summary
This PR switches more callsites of `SemanticModel::is_builtin` to move
over to the new methods I introduced in #10919, which are more concise
and more accurate. I missed these calls in the first PR.
## Summary
Fixes#10866.
Introduces the `show_err_msg!` macro which will send a message to be
shown as a popup to the client via the `window/showMessage` LSP method.
## Test Plan
Insert various `show_err_msg!` calls in common code paths (for example,
at the beginning of `event_loop`) and confirm that these messages appear
in your editor.
To test that panicking works correctly, add this to the top of the `fn
run` definition in
`crates/ruff_server/src/server/api/requests/execute_command.rs`:
```rust
panic!("This should appear");
```
Then, try running a command like `Ruff: Format document` from the
command palette (`Ctrl/Cmd+Shift+P`). You should see the following
messages appear:

## Summary
Fixes#10780.
The server now send code actions to the client with a Ruff-specific
kind, `source.*.ruff`. The kind filtering logic has also been reworked
to support this.
## Test Plan
Add this to your `settings.json` in VS Code:
```json
{
"[python]": {
"editor.codeActionsOnSave": {
"source.organizeImports.ruff": "explicit",
},
}
}
```
Imports should be automatically organized when you manually save with
`Ctrl/Cmd+S`.
## Summary
Configuration is no longer the property of a workspace but rather of
individual documents. Just like the Ruff CLI, each document is
configured based on the 'nearest' project configuration. See [the Ruff
documentation](https://docs.astral.sh/ruff/configuration/#config-file-discovery)
for more details.
To reduce the amount of times we resolve configuration for a file, we
have an index for each workspace that stores a reference-counted pointer
to a configuration for a given folder. If another file in the same
folder is opened, the configuration is simply re-used rather than us
re-resolving it.
## Guide for reviewing
The first commit is just the restructuring work, which adds some noise
to the diff. If you want to quickly understand what's actually changed,
I recommend looking at the two commits that come after it.
f7c073d441 makes configuration a property
of `DocumentController`/`DocumentRef`, moving it out of `Workspace`, and
it also sets up the `ConfigurationIndex`, though it doesn't implement
its key function, `get_or_insert`. In the commit after it,
fc35618f17, we implement `get_or_insert`.
## Test Plan
The best way to test this would be to ensure that the behavior matches
the Ruff CLI. Open a project with multiple configuration files (or add
them yourself), and then introduce problems in certain files that won't
show due to their configuration. Add those same problems to a section of
the project where those rules are run. Confirm that the lint rules are
run as expected with `ruff check`. Then, open your editor and confirm
that the diagnostics shown match the CLI output.
As an example - I have a workspace with two separate folders, `pandas`
and `scipy`. I created a `pyproject.toml` file in `pandas/pandas/io` and
a `ruff.toml` file in `pandas/pandas/api`. I changed the `select` and
`preview` settings in the sub-folder configuration files and confirmed
that these were reflected in the diagnostics. I also confirmed that this
did not change the diagnostics for the `scipy` folder whatsoever.
## Summary
This change adds a rule to detect functions declared `async` but lacking
any of `await`, `async with`, or `async for`. This resolves#9951.
## Test Plan
This change was tested by following
https://docs.astral.sh/ruff/contributing/#rule-testing-fixtures-and-snapshots
and adding positive and negative cases for each of `await` vs nothing,
`async with` vs `with`, and `async for` vs `for`.
## Summary
This PR moves the `Q003` rule to AST checker.
This is the final rule that used the docstring detection state machine
and thus this PR removes it as well.
resolves: #7595resolves: #7808
## Test Plan
- [x] `cargo test`
- [x] Make sure there are no changes in the ecosystem
## Summary
Adds more aggressive logic to PLR1730, `if-stmt-min-max`
Closes#10907
## Test Plan
`cargo test`
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Hi! 👋
Thanks for sharing ruff as software libre — it helps me keep Python code
quality up with pre-commit, both locally and CI 🙏
While studying the examples at
https://docs.astral.sh/ruff/rules/function-uses-loop-variable/#example I
noticed that the last of the examples had a bug: prior to this fix, `ì`
was passed to the lambda for `x` rather than for `i` — the two are
mixed-up. The reason it's easy to overlook is because addition is an
commutative operation and so `x + i` and `i + x` give the same result
(and least with integers), despite the mix-up. For proof, let me demo
the relevant part with before and after:
```python
In [1]: from functools import partial
In [2]: [partial(lambda x, i: (x, i), i)(123) for i in range(3)]
Out[2]: [(0, 123), (1, 123), (2, 123)]
In [3]: [partial(lambda x, i: (x, i), i=i)(123) for i in range(3)]
Out[3]: [(123, 0), (123, 1), (123, 2)]
```
Does that make sense?
## Test Plan
<!-- How was it tested? -->
Was manually tested using IPython.
CC @r4f @grandchild
## Summary
If `RUF100` was included in a per-file-ignore, we respected it on cases
like `# noqa: F401`, but not the blanket variant (`# noqa`).
Closes https://github.com/astral-sh/ruff/issues/10906.
## Summary
Implement new rule: Prefer augmented assignment (#8877). It checks for
the assignment statement with the form of `<expr> = <expr>
<binary-operator> …` with a unsafe fix to use augmented assignment
instead.
## Test Plan
1. Snapshot test is included in the PR.
2. Manually test with playground.
Refs #3172
## Summary
Fix a typo in the docs example, and add a test for the case where a
negative pattern and a positive pattern overlap.
The behavior here is simple: patterns (positive or negative) are always
additive if they hit (i.e. match for a positive pattern, don't match for
a negated pattern). We never "un-ignore" previously-ignored rules based
on a pattern (positive or negative) failing to hit.
It's simple enough that I don't really see other cases we need to add
tests for (the tests we have cover all branches in the ignores_from_path
function that implements the core logic), but open to reviewer feedback.
I also didn't end up changing the docs to explain this more, because I
think they are accurate as written and don't wrongly imply any more
complex behavior. Open to reviewer feedback on this as well!
After some discussion, I think allowing negative patterns to un-ignore
rules is too confusing and easy to get wrong; if we need that, we should
add `per-file-selects` instead.
## Test Plan
Test/docs only change; tests pass, docs render and look right.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@gmail.com>
## Summary
This PR adds the implementation for the current
[flake8-bugbear](https://github.com/PyCQA/flake8-bugbear)'s B038 rule.
The B038 rule checks for mutation of loop iterators in the body of a for
loop and alerts when found.
Rational:
Editing the loop iterator can lead to undesired behavior and is probably
a bug in most cases.
Closes#9511.
Note there will be a second iteration of B038 implemented in
`flake8-bugbear` soon, and this PR currently only implements the weakest
form of the rule.
I'd be happy to also implement the further improvements to B038 here in
ruff 🙂
See https://github.com/PyCQA/flake8-bugbear/issues/454 for more
information on the planned improvements.
## Test Plan
Re-using the same test file that I've used for `flake8-bugbear`, which
is included in this PR (look for the `B038.py` file).
Note: this is my first time using `rust` (beside `rustlings`) - I'd be
very happy about thorough feedback on what I could've done better
🙂 - Bring it on 😀
## Summary
Code cleanup for per-file ignores; use a struct instead of a tuple.
Named the structs for individual ignores and the list of ignores
`CompiledPerFileIgnore` and `CompiledPerFileIgnoreList`. Name choice is
because we already have a `PerFileIgnore` struct for a
pre-compiled-matchers form of the config. Name bikeshedding welcome.
## Test Plan
Refactor, should not change behavior; existing tests pass.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
## Summary
I believe this should close
https://github.com/astral-sh/ruff/issues/10880? The `.gitignore`
creation seems ok, since it truncates, but using `cachedir::is_tagged`
followed by `cachedir::add_tag` is not safe, as `cachedir::add_tag`
_fails_ if the file already exists.
This also matches the structure of the code in `uv`.
Closes https://github.com/astral-sh/ruff/issues/10880.
## Summary
Implement `write-whole-file` (`FURB103`), part of #1348. This is largely
a copy and paste of `read-whole-file` #7682.
## Test Plan
Text fixture added.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Improve `blanket-noqa` error message in cases where codes are provided
but not detected due to formatting issues. Namely `# noqa X100` (missing
colon) or `noqa : X100` (space before colon). The behavior is similar to
`NQA002` and `NQA003` from `flake8-noqa` mentioned in #850. The idea to
merge the rules into `PGH004` was suggested by @MichaReiser
https://github.com/astral-sh/ruff/pull/10325#issuecomment-2025535444.
## Test Plan
Test cases added to fixture.
Fixes#3172
## Summary
Allow prefixing [extend-]per-file-ignores patterns with `!` to negate
the pattern; listed rules / prefixes will be ignored in all files that
don't match the pattern.
## Test Plan
Added tests for the feature.
Rendered docs and checked rendered output.
Fixes#5499
## Summary
Add support for `FORCE_COLOR` env var, as specified at
https://force-color.org/
## Test Plan
I wrote an integration test for this, and then realized that can't work,
since we use a dev-dependency on `colored` with the `no-color` feature
to avoid ANSI color codes in test snapshots.
So this is just tested manually.
`cargo run --features test-rules -- check --no-cache --isolated -
--select RUF901 --diff < /dev/null` shows a colored diff.
`cargo run --features test-rules -- check --no-cache --isolated -
--select RUF901 --diff < /dev/null | less` does not have color, since we
pipe it to `less`.
`FORCE_COLOR=1 cargo run --features test-rules -- check --no-cache
--isolated - --select RUF901 --diff < /dev/null | less` does have color
(after this diff), even though we pipe it to `less`.
## Summary
Came across this code while digging into the semantic model with
@AlexWaygood, and found it confusing because of how it splits
`push_scope` from the paired `pop_scope` (took me a few minutes to even
figure out if/where we were popping the pushed scope). Since this
"cleanup" is already totally split by node type, there doesn't seem to
be any gain in having it as a separate "step" rather than just
incorporating it into the traversal clauses for those node types.
I left the equivalent cleanup step alone for the expression case,
because in that case it is actually generic across several different
node types, and due to the use of the common `visit_generators` utility
there isn't a clear way to keep the pushes and corresponding pops
localized.
Feel free to just reject this if I've missed a good reason for it to
stay this way!
## Test Plan
Tests and clippy.
## Summary
This is a follow-up to https://github.com/astral-sh/ruff/pull/10764.
Support for diagnostics, quick fixes, and source actions can now be
disabled via client settings.
## Test Plan
### Manual Testing
Set up your workspace as described in the test plan in
https://github.com/astral-sh/ruff/pull/10764, up to step 2. You don't
need to add a debug statement.
The configuration for `folder_a` and `folder_b` should be as follows:
`folder_a`:
```json
{
"ruff.codeAction.fixViolation": {
"enable": true
}
}
```
`folder_b`
```json
{
"ruff.codeAction.fixViolation": {
"enable": false
}
}
```
Finally, open up your VS Code User Settings and un-check the `Ruff > Fix
All` setting.
1. Open a Python file in `folder_a` that has existing problems. The
problems should be highlighted, and quick fix should be available.
`source.fixAll` should not be available as a source action.
2. Open a Python file in `folder_b` that has existing problems. The
problems should be highlighted, but quick fixes should not be available
for any of them. `source.fixAll` should not be available as a source
action.
3. Open up your VS Code Workspace Settings (second tab under the search
bar) and un-check `Ruff > Lint: Enable`
4. Both files you tested in steps 1 and 2 should now lack any visible
diagnostics. `source.organizeImports` should still be available as a
source action.
## Summary
Fixes#3011.
Type checkers currently allow forward references in all contexts in stub
files, and stubs frequently make use of this capability (although it
doesn't actually seem to be specc'd anywhere --neither in PEP 484, nor
https://typing.readthedocs.io/en/latest/source/stubs.html#id6, nor the
CPython typing docs). Implementing it so that Ruff allows forward
references in _all contexts_ in stub files seems non-trivial, however
(or at least, I couldn't figure out how to do it easily), so this PR
does not do that. Perhaps it _should_; if we think this apporach isn't
principled enough, I'm happy to close it and postpone changing anything
here.
However, this does reduce the number of F821 errors Ruff emits on
typeshed down from 76 to 2, which would mean that we could enable the
rule at typeshed. The remaining 2 F821 errors can be trivially fixed at
typeshed by moving definitions around; forward references in class bases
were really the only remaining places where there was a real _use case_
for forward references in stub files that Ruff wasn't yet allowing.
## Test plan
`cargo test`. I also ran this PR branch on typeshed to check to see if
there were any new false positives caused by the changes here; there
were none.
## Summary
`Path.read_bytes()` does not support any keyword arguments, so `FURB101`
should not be triggered if the file is opened in `rb` mode with any
keyword arguments.
## Test Plan
Move erroneous test to "Non-error" section of fixture.
## Summary
Historically, given:
```python
__all__ = [ # noqa: F822
"Bernoulli",
"Beta",
"Binomial",
]
```
The F822 violations would be attached to the `__all__`, so this `# noqa`
would be enforced for _all_ definitions in the list. This changed in
https://github.com/astral-sh/ruff/pull/10525 for the better, in that we
now use the range of each string. But these `# noqa` directives stopped
working.
This PR sets the `__all__` as a parent range in the diagnostic, so that
these directives are respected once again.
Closes https://github.com/astral-sh/ruff/issues/10795.
## Test Plan
`cargo test`
## Summary
Add new rule `pyupgrade - UP042` (I picked next available number).
Closes https://github.com/astral-sh/ruff/discussions/3867
Closes https://github.com/astral-sh/ruff/issues/9569
It should warn + provide a fix `class A(str, Enum)` -> `class
A(StrEnum)` for py311+.
## Test Plan
Added UP042.py test.
## Notes
I did not find a way to call `remove_argument` 2 times consecutively, so
the automatic fixing works only for classes that inherit exactly `str,
Enum` (regardless of the order).
I also plan to extend this rule to support IntEnum in next PR.
## Summary
This builds off of the work in
https://github.com/astral-sh/ruff/pull/10652 to implement a command
executor, backwards compatible with the commands from the previous LSP
(`ruff.applyAutofix`, `ruff.applyFormat` and
`ruff.applyOrganizeImports`).
This involved a lot of refactoring and tweaks to the code action
resolution code - the most notable change is that workspace edits are
specified in a slightly different way, using the more general `changes`
field instead of the `document_changes` field (which isn't supported on
all LSP clients). Additionally, the API for synchronous request handlers
has been updated to include access to the `Requester`, which we use to
send a `workspace/applyEdit` request to the client.
## Test Plan
https://github.com/astral-sh/ruff/assets/19577865/7932e30f-d944-4e35-b828-1d81aa56c087
## Summary
When a language server initializes, it is passed a serialized JSON
object, which is known as its "initialization options". Until now, `ruff
server` has ignored those initialization options, meaning that
user-provided settings haven't worked. This PR is the first step for
supporting settings from the LSP client. It implements procedures to
deserialize initialization options into a settings object, and then
resolve those settings objects into concrete settings for each
workspace.
One of the goals for user settings implementation in `ruff server` is
backwards compatibility with `ruff-lsp`'s settings. We won't support all
settings that `ruff-lsp` had, but the ones that we do support should
work the same and use the same schema as `ruff-lsp`.
These are the existing settings from `ruff-lsp` that we will continue to
support, and which are part of the settings schema in this PR:
| Setting | Default Value | Description |
|----------------------------------------|---------------|----------------------------------------------------------------------------------------|
| `codeAction.disableRuleComment.enable` | `true` | Whether to display
Quick Fix actions to disable rules via `noqa` suppression comments. |
| `codeAction.fixViolation.enable` | `true` | Whether to display Quick
Fix actions to autofix violations. |
| `fixAll` | `true` | Whether to register Ruff as capable of handling
`source.fixAll` actions. |
| `lint.enable` | `true` | Whether to enable linting. Set to `false` to
use Ruff exclusively as a formatter. |
| `organizeImports` | `true` | Whether to register Ruff as capable of
handling `source.organizeImports` actions. |
To be clear: this PR does not implement 'support' for these settings,
individually. Rather, it constructs a framework for these settings to be
used by the server in the future.
Notably, we are choosing *not* to support `lint.args` and `format.args`
as settings for `ruff server`. This is because we're now interfacing
with Ruff at a lower level than its CLI, and converting CLI arguments
back into configuration is too involved.
We will have support for linter and formatter specific settings in
follow-up PRs. We will also 'hook up' user settings to work with the
server in follow up PRs.
## Test Plan
### Snapshot Tests
Tests have been created in
`crates/ruff_server/src/session/settings/tests.rs` to ensure that
deserialization and settings resolution works as expected.
### Manual Testing
Since we aren't using the resolved settings anywhere yet, we'll have to
add a few printing statements.
We want to capture what the resolved settings look like when sent as
part of a snapshot, so modify `Session::take_snapshot` to be the
following:
```rust
pub(crate) fn take_snapshot(&self, url: &Url) -> Option<DocumentSnapshot> {
let resolved_settings = self.workspaces.client_settings(url, &self.global_settings);
tracing::info!("Resolved settings for document {url}: {resolved_settings:?}");
Some(DocumentSnapshot {
configuration: self.workspaces.configuration(url)?.clone(),
resolved_client_capabilities: self.resolved_client_capabilities.clone(),
client_settings: resolved_settings,
document_ref: self.workspaces.snapshot(url)?,
position_encoding: self.position_encoding,
url: url.clone(),
})
}
```
Once you've done that, build the server and start up your extension
testing environment.
1. Set up a workspace in VS Code with two workspace folders, each one
having some variant of Ruff file-based configuration (`pyproject.toml`,
`ruff.toml`, etc.). We'll call these folders `folder_a` and `folder_b`.
2. In each folder, open up `.vscode/settings.json`.
3. In folder A, use these settings:
```json
{
"ruff.codeAction.disableRuleComment": {
"enable": true
}
}
```
4. In folder B, use these settings:
```json
{
"ruff.codeAction.disableRuleComment": {
"enable": false
}
}
```
5. Finally, open up your VS Code User Settings and un-check the `Ruff >
Code Action: Disable Rule Comment` setting.
6. When opening files in `folder_a`, you should see logs that look like
this:
```
Resolved settings for document <file>: ResolvedClientSettings { fix_all: true, organize_imports: true, lint_enable: true, disable_rule_comment_enable: true, fix_violation_enable: true }
```
7. When opening files in `folder_b`, you should see logs that look like
this:
```
Resolved settings for document <file>: ResolvedClientSettings { fix_all: true, organize_imports: true, lint_enable: true, disable_rule_comment_enable: false, fix_violation_enable: true }
```
8. To test invalid configuration, change `.vscode/settings.json` in
either folder to be this:
```json
{
"ruff.codeAction.disableRuleComment": {
"enable": "invalid"
},
}
```
10. You should now see these error logs:
```
<time> [info] <duration> ERROR ruff_server::session::settings Failed to deserialize initialization options: data did not match any variant of untagged enum InitializationOptions. Falling back to default client settings...
<time> [info] <duration> WARN ruff_server::server No workspace settings found for file:///Users/jane/testbed/pandas
<duration> WARN ruff_server::server No workspace settings found for file:///Users/jane/foss/scipy
```
11. Opening files in either folder should now print the following
configuration:
```
Resolved settings for document <file>: ResolvedClientSettings { fix_all: true, organize_imports: true, lint_enable: true, disable_rule_comment_enable: true, fix_violation_enable: true }
```
## Summary
This PR adds a new semantic model flag to indicate that the checker is
inside an f-string replacement field. This will be used to ignore
certain checks if the target version doesn't support a specific feature
like PEP 701.
fixes: #10761
## Test Plan
Add a test case from the raised issue.
Fixes#3259
## Summary
Renames `UnnecessaryComprehensionAnyAll` to
`UnnecessaryComprehensionInCall` and extends the check to `sum`, `min`,
and `max`, in addition to `any` and `all`.
## Test Plan
Updated snapshot test.
Built docs locally and verified the docs for this rule still render
correctly.
## Summary
Needed for https://github.com/astral-sh/ruff/pull/10686.
We no longer support `root_uri` as an initialization parameter, relying
solely on `workspace_folders` to find the working directories. This
means that the minimum supported LSP version is now `0.3.6`.
## Test Plan
When opening a folder in VS Code, you shouldn't see any errors in the
log which say `No workspace(s) were provided(...)`.
## Summary
We may not have had access to this in the past, but in short, if the
diagnostic is related to a specific section of a docstring, it seems
better to highlight the section (via the header) than the _entire_
docstring.
This should be completely compatible with existing `# noqa` since it's
always inside of a multi-line string anyway, and in such cases the `#
noqa` is always placed at the end of the multiline string.
Closes https://github.com/astral-sh/ruff/issues/10736.
## Summary
This PR adds the `as_str` implementation for all the operator methods.
It already exists for `CmpOp` which is being [used in the
linter](ffcd77860c/crates/ruff_linter/src/rules/flake8_simplify/rules/key_in_dict.rs (L117))
and it makes sense to implement it for the rest as well. This will also
be utilized in error messages for the new parser.
## Summary
This PR removes unused operator methods and impl traits. There is
already the `is_macro::Is` implementation for all the operators and this
seems unnecessary.
## Summary
We lost the per-rule ignores when these were migrated to the AST, so if
_any_ `Q` rule is enabled, they're now all enabled.
Closes https://github.com/astral-sh/ruff/issues/10724.
## Test Plan
Ran:
```shell
ruff check . --isolated --select Q --ignore Q000
ruff check . --isolated --select Q --ignore Q001
ruff check . --isolated --select Q --ignore Q002
ruff check . --isolated --select Q --ignore Q000,Q001
ruff check . --isolated --select Q --ignore Q000,Q002
ruff check . --isolated --select Q --ignore Q001,Q002
```
...against:
```python
'''
bad docsting
'''
a = 'single'
b = '''
bad multi line
'''
```
## Summary
An annotated lambda assignment within a class scope is often
intentional. For example, within a dataclass or Pydantic model, these
are treated as fields rather than methods (and so can be passed values
in constructors).
I originally wrote this to special-case dataclasses and Pydantic
models... But was left feeling like we'd see more false positives here
for little gain (an annotated lambda within a `class` is likely
intentional?). Open to opinions, though.
Closes https://github.com/astral-sh/ruff/issues/10718.
## Summary
Currently, [this
line](716688d44e/crates/ruff_linter/src/fix/edits.rs (L101))
assumes that the `noqa` comment begins with an octothorpe followed by a
space. (`# `) With anyone's random code, this of course is not always
true.
When there's a multi-byte character after the leading octothorpe, such
as
[`\u0085`](https://www.fileformat.info/info/unicode/char/85/index.htm),
we try slicing from within the character, causing a panic.
To fix this, the logic has been changed to remove unused `noqa`
directives and keep any trailing comments, or removing the whole comment
if the comment is just the unused `noqa`
Fixes#10097.
## Test Plan
`cargo test`
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Implement FURB164 in the issue #1348.
Relevant Refurb docs is here:
https://github.com/dosisod/refurb/blob/v2.0.0/docs/checks.md#furb164-no-from-float
I've changed the name from `no-from-float` to
`verbose-decimal-fraction-construction`.
## Test Plan
<!-- How was it tested? -->
I've written it in the `FURB164.py`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
When `relative-imports-order = "closest-to-furthest"` is set, we should
_still_ put non-relative imports after relative imports. It's rare for
them to be in the same section, but _possible_ if you use
`known-local-folder`.
Closes https://github.com/astral-sh/ruff/issues/10655.
## Test Plan
New tests.
Also sorted this file:
```python
from ..models import ABC
from .models import Question
from .utils import create_question
from django_polls.apps.polls.models import Choice
```
With both:
- `isort view.py`
- `ruff check view.py --select I --fix`
And the following `pyproject.toml`:
```toml
[tool.ruff.lint.isort]
order-by-type = false
relative-imports-order = "closest-to-furthest"
known-local-folder = ["django_polls"]
[tool.isort]
profile = "black"
reverse_relative = true
known_local_folder = ["django_polls"]
```
I verified that Ruff and isort gave the same result, and that they
_still_ gave the same result when removing the relevant setting:
```toml
[tool.ruff.lint.isort]
order-by-type = false
known-local-folder = ["django_polls"]
[tool.isort]
profile = "black"
known_local_folder = ["django_polls"]
```
## Summary
Add a setting `extend-allowed-calls` to allow users to define their own
list of calls which allow boolean traps.
Resolves#10485.
Resolves#10356.
## Test Plan
Extended text fixture and added setting test.
## Summary
This PR fixes the bug for `DTZ007` rule where it didn't consider to
check for the presence of `%z` in f-strings. It also considers the
string parts of an implicitly concatenated f-strings for which I want to
find a better solution (#10308).
fixes: #10601
## Test Plan
Add test cases and update the snapshots.
## Summary
Fixes#10589.
Code that violates `F401` or `F841` (in other words, unused variables or
imports) should now appear greyed out or 'unused' in an editor.
## Test Plan
Put the following test code in a new file within the extension
development host window:
```python
import math
def func():
if False:
unused = "<- this should be greyed out"
```
The following test code should have greyed out/unused import and
variable names, like so:
<img width="294" alt="Screenshot 2024-03-28 at 4 23 18 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/e84a6e7a-49e2-4fed-9624-f8f9559e0837">
## Summary
Fixes#10588.
Most diagnostics from `ruff server` now appear as a much less alarming
warning instead of an error. Three diagnostics still appear as errors:
`F821` (`undefined name <name>`), `E902` (`IOError`) and `E999`
(`SyntaxError`).
## Test Plan
With an extension using the path to a locally-built executable, open a
file with multiple highlighted problems. Toggle the `Experimental
Server` setting on and off. The highlights should stay as warnings.
Then, modify the file to have a syntactically incorrect element. The
start of the invalid syntax should now have a red highlight.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR updates the warning message for rule S305 to accurately reflect
the security concern over using ECB mode in block ciphers, which is
considered insecure compared to other modes like CBC or CTR. The
previous message incorrectly mentioned AES as a [block cipher
mode](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation),
which has been corrected to avoid confusion.
Ref:
c85576d903/bandit/blacklists/calls.py (L99-L102)825fd7c990/crates/ruff_linter/src/rules/flake8_bandit/rules/suspicious_function_call.rs (L187-L216)
## Test Plan
No testing required as the change is limited to a minor change of
warning message update.
## Summary
The example for tab-after-comma (E242):
```python
a = 4,\t5
```
Use instead:
```python
a = 4, 3
```
is confusing since both the whitespace and the numbers are changed.
Change so the examples use the same numbers before/after.
## Test Plan
Untested.
- Clearly state in the documentation that passing `tz=None` is just as bad as not passing a `tz=` argument, from the perspective of these rules.
- Clearly state in the error messages exactly what the user is doing wrong, if the user is passing `tz=None` rather than failing to pass a `tz=` argument at all.
- Make error messages more concise, and separate out the suggested remedy from the thing that the user is identified as doing wrong.
Co-authored-by: Christian Clauss <cclauss@me.com>
## Summary
Fixes#10618.
This PR introduces a proper API for sending requests to the client and
handling any response sent back. Dynamic capability registration now
uses this new API, fixing an issue where a much more simplistic response
handler silently flushes a code action request that needed a response.
## Test Plan
#10618 can no longer be reproduced. No errors about unhandled responses
should appear in the extension output, and you should see this new log
when the server starts:
```
<DATE> <TIME> [info] <DURATION> INFO ruff_server::server Configuration file watcher successfully registered
```
## Summary
This PR adds an overview and roadmap to the `README.md` for the
`ruff_server` crate along with a rudimentary `CONTRIBUTING.md` that
explains some of the technical decisions behind the project and basic
information about local testing.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Similar to #10419, there was a case where there is a collision of C401
and C416 (as discussed in #10101).
Fixed this by implementing short-circuit for the comprehension of the
form `{x for x in foo}`.
## Test Plan
<!-- How was it tested? -->
Extended `C401.py` with the case where `set` is not builtin function,
and divided the case where the short-circuit should occur.
Removed the last testcase of `print(f"{ {set(a for a in 'abc')} }")`
test as this is invalid as a python code, but should I keep this?
## Summary
This is just a nitpicky improvement, but I thought it'd be a good
opportunity to look at the ruff source.
> The rules list in the documentation is generated using the registry
order. Currently, flake8-logging is separated from the rest of the
flake8 plugins. This patch puts it next to them.
https://docs.astral.sh/ruff/rules/
If it makes sense, we could alternatively just sort the linters in
https://github.com/astral-sh/ruff/blob/main/crates/ruff_dev/src/generate_rules_table.rs.
Signed-off-by: Filipe Laíns <lains@riseup.net>
## Summary
This is not the holistic solution but just to fix that issue.
fixes: #10546
## Test Plan
Add a regression test for it and check the snapshots.
## Summary
Fixed false-positive on the rule `PLW1641`, where the explicit
assignment on the `__hash__` method is not counted as an definition of
`__hash__`. (Discussed in #10557).
Also, added one new testcase.
## Test Plan
Checked on `cargo test` in `eq_without_hash.py`.
Before the change, for the assignment into `__hash__`, only `__hash__ =
None` was counted as an explicit definition of `__hash__` method.
Probably any assignment into `__hash__` property could be counted as an
explicit definition of hash, so I removed `value.is_none_literal_expr()`
check.
## Summary
Closes#10228
The PR makes the blank lines rules keep track of the cell status when
running on a notebook, and makes the rules not trigger when the line is
the first of the cell.
## Test Plan
The example given in #10228 is added as a fixture, along with a few
tests from the main blank lines fixtures.
## Summary
Continuing with #7595, this PR moves the `Q004` rule to the AST checker.
## Test Plan
- [x] Existing test cases should pass
- [x] No ecosystem updates
## Summary
PEP 420 says [nested namespace
packages](https://peps.python.org/pep-0420/#nested-namespace-packages)
are allowed, i.e. marking a directory as a namespace package marks all
subdirectories in the subtree as namespace packages.
`is_package` is modified to use `Path::starts_with` and the order of
checks is reversed to do in-memory checks first before hitting the disk.
## Test Plan
Added unit tests. Previously all tests were run with `namespace_packages
== &[]`. Verified that one of the tests was failing before changing the
implementation.
## Future Improvements
The `is_package_with_cache` can probably be rewritten to avoid repeated
calls to `Path::starts_with`, by caching all directories up to the
`namespace_root`:
```ruff
let namespace_root = namespace_packages
.iter()
.filter(|namespace_package| path.starts_with(namespace_package))
.min();
```
## Summary
Closes#10337.
I've fixed the code to count usage of variable.
Usage count inside the block is reset when there is a following
statement.
- continue
- break
- return
## Test Plan
Add test case.
## Summary
The fix for PYI025 is currently marked as unsafe in non-global scopes
for both `.py` and `.pyi` files, on the grounds that all global-scope
symbols in Python are implicitly exported from the module, so changing
the name of something in the global scope could break other modules that
import the module we're fixing. Unlike in `.py` files, however, imported
symbols are never implicitly re-exported from stub files. Symbols are
only understood by static analysis tools as being re-exported from stubs
if they are marked as explicit re-exports, which take three forms:
```py
from foo import * # all symbols from foo are re-exported from the stub
# the "redundant" alias marks it as an explicit re-export
# (note that the alias needs to be identical to the symbol's "actual" name
# in order for it to be a re-export)
from bar import barrr as barrr
# inclusion in __all__ also marks it as an explicit re-export,
# just like in `.py` files
from baz import bazzz
__all__ = ["bazzz"]
```
This is [specc'd in PEP
484](https://peps.python.org/pep-0484/#stub-files), and means that we
can mark the fix for PYI025 as safe in more cases for `.pyi` files.
## Test Plan
`cargo test`. An existing test case goes from being an unsafe fix to a
safe fix in a `.pyi` fixture. I also added a new fixture so we have
coverage of global-scope imports that are marked as re-exports using
"redundant" `from collections.abc import Set as Set` aliases.
## Summary
Continuing with https://github.com/astral-sh/ruff/issues/7595, this PR
moves the `Q001`, `Q002`, `Q003` rules to the AST based checker.
## Test Plan
Make sure all of the existing test cases pass and verify there are no
ecosystem changes.
## Summary
This error was found browsing
https://github.com/qarmin/Automated-Fuzzer/actions/runs/8396966850.
Which failed when trying to autofix the PT014 violation in the following
code:
```python
@pytest.mark.parametrize('data, spec', [(1.0, 1.0), (1.0, 1.0)])
def test_numbers(data, spec):
...
```
Investigation revealed that the implementation was not properly tested,
when the duplicate value was also the last in the list. In particular
the following function, which is in charge of finding the comma
following an element to create the suggested fix,
0a99bd84ce/crates/ruff_linter/src/rules/flake8_pytest_style/rules/parametrize.rs (L647-L651)
would find the next comma even if it was outside the list itself leading
to a lot of code being deleted.
This PR fixes that.
## Test Plan
Added misbehaving code to the test fixture.
## Summary
Ensures that we use the raw identifier as provided in the source code,
rather than the normalized Unicode identifier.
This _does_ mean that we treat these as two separate identifiers, and
_don't_ merge them, even though Python will treat them as the same
symbol:
```python
import numpy as ℂℇℊℋℌℍℎℐℑℒℓℕℤΩℨKÅℬℭℯℰℱℹℴ
import numpy as CƐgHHHhIILlNZΩZKÅBCeEFio
```
I think that's fine, this is super rare anyway and would likely be
confusing for users.
Closes https://github.com/astral-sh/ruff/issues/10528.
## Test Plan
`cargo test`
## Summary
Adds commas as an accepted separator between copyright years by default,
which is actually documented in one spot, but not currently accurate.
Fixes#9477.
## Summary
Fixes#10366.
`ruff server` now registers a file watcher on the client side using the
LSP protocol, and listen for events on configuration files. On such an
event, it reloads the configuration in the 'nearest' workspace to the
file that was changed.
## Test Plan
N/A
## Summary
Some contributors have referenced settings in their documentation
without adding the settings to an options section, this has lead to some
rendering issues (#10427). This PR addresses this looking for potential
inline links to settings, cross-checking them with the options sections,
and then linking them anyway if they are not found.
Resolves#10427.
## Test Plan
Manually verified that the correct modifications were made and no docs
were broken.
## Summary
In https://github.com/astral-sh/ruff/pull/10341, we fixed some false
positives in `.pyi` files, but introduced others. This PR effectively
reverts the change in #10341 and fixes it in a slightly different way.
Instead of changing the _bindings_ we generate in the semantic model in
`.pyi` files, we instead change how we _resolve_ them.
Closes https://github.com/astral-sh/ruff/issues/10509.
- Improve clarity over the motivation for some rules
- Improve links to external references. In particular, reduce links to PEPs, as PEPs are generally historical documents rather than pieces of living documentation. Where possible, it's better to link to the official typing spec, the other docs at typing.readthedocs.io/en/latest, or the docs at docs.python.org/3/library/typing.html.
- Use more concise language in a few places
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fix `E231` bug: Inconsistent catch compared to pycodestyle, such as when
dict nested in list. Resolves#10113.
## Test Plan
Example from #10113 added to test fixture.
## Summary
This is a follow up on https://github.com/astral-sh/ruff/pull/10492
I incorrectly assumed that `subscript.value.end()` always points past
the value. However, this isn't the case for parenthesized values where
the end "ends" before the parentheses.
## Test Plan
I added new tests for the parenthesized case.
## Summary
This PR fixes an instability where formatting a subscribt
where the `slice` is not an `ExprSlice` and it has a trailing
end-of-line comment after its opening `[` required two formatting passes
to be stable.
The fix is to associate the trailing end-of-line comment as dangling
comment on `[` to preserve its position, similar to how Ruff does it for
other parenthesized expressions.
This also matches how trailing end-of-line subscript comments are
handled when the `slice` is an `ExprSlice`.
Fixes https://github.com/astral-sh/ruff/issues/10355
## Versioning
Shipping this as part of a patch release is fine because:
* It fixes a stability issue
* It doesn't impact already formatted code because Ruff would already
have moved to the comment to the end of the line (instead of preserving
it)
## Test Plan
Added tests
Fix a typos in the error message of rule C400
With the latest version of Ruff (0.3.3) if I have a `scratch.py` script
like that:
```python
from typing import Dict, List, Tuple
def generate_samples(test_cases: Dict) -> List[Tuple]:
return list(
(input, expected)
for input, expected in zip(test_cases["input_value"], test_cases["expected_value"])
)
```
and I run ruff
```shell
>>> ruff check scratch.py --select C400
>>> scratch.py:5:12: C400 Unnecessary generator (rewrite using `list()`
```
This PR fixes the error message from _"(rewrite using `list()`"_ to
_"(rewrite using `list()`)"_, and it fixes also the doc.
Related question: why I have this error message? The rule is not correct
in this case. Should I open an issue for that?
## Summary
This PR fixes a panic in the linter for `W605`.
Consider the following f-string:
```python
f"{{}}ab"
```
The `FStringMiddle` token would contain `{}ab`. Notice that the escaped
braces have _reduced_ the string. This means we cannot use the text
value from the token to determine the location of the escape sequence
but need to extract it from the source code.
fixes: #10434
## Test Plan
Add new test cases and update the snapshots.
## Summary
We're seeing failures in https://github.com/astral-sh/ruff/issues/10470
because `resolve_qualified_import_name` isn't guaranteed to return a
specific import if a symbol is accessible in two ways (e.g., you have
both `import logging` and `from logging import error` in scope, and you
want `logging.error`). This PR breaks up the failing tests such that the
imports aren't in the same scope.
Closes https://github.com/astral-sh/ruff/issues/10470.
## Test Plan
I added a `bindings.reverse()` to `resolve_qualified_import_name` to
ensure that the tests pass regardless of the binding order.
## Summary
I used `cargo-shear` (see
[tweet](https://twitter.com/boshen_c/status/1770106165923586395)) to
remove some unused dependencies that `cargo udeps` wasn't reporting.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
`cargo test`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Clarify `extend-select` documentation to avoid confusion regarding the
default `select`. Also match the `select` documentation. Resolves
#10389.
## Test Plan
<!-- How was it tested? -->
## Summary
This adds automatic fixes for the `PT007` rule.
I am currently reviewing and adding Ruff rules to Home Assistant. One
rule is PT007, which has multiple hundred occurrences in the codebase,
but no automatic fix, and this is not fun to do manually, especially
because using Regexes are not really possible with this.
My knowledge of the Ruff codebase and Rust in general is not good and
this is my first PR here, so I hope it is not too bad.
One thing where I need help is: How can I have the transformed code to
be formatted automatically, instead of it being minimized as it does it
now?
## Test Plan
Using the existing fixtures and updated snapshots.
## Summary
This PR removes the `Iterator::chain(...)` sequence in
`RuleCodePrefix::iter()` with `Vec::expand` to avoid an
overlong-recursive types.
The existing `RuleCodePrefix::iter` method chains all rule group
iterators together. This leads to very long recursive types
`Chain<Map<Chain<Map<Chain<Map.....>>>>` (proportional to the number of
rule groups).
This PR rewrites the macro to use `Vec::extend` instead, which removes
the long recursive type (at the cost of introducing a potential
allocation).
## Alternatives
An alternative would be to use a stack allocated array by unrolling the
`Linter::iter` methods (generated by `EnumIter`).
I don't think it's worth the extra complexity, considering that
`RuleCodePrefix::iter` isn't a hot function.
## Test Plan
`cargo test`
## Summary
Fixes#10324
This removes an overeager failure case where we would exit early if no
root directory or workspace folders were provided on server
initialization. We now fall-back to the current working directory as a
workspace for that file.
## Test Plan
N/A
## Summary
#10151 documented the deviations between Ruff and Black with the new
2024 style guide in the `ruff-python-formatter/README.md`. However,
that's not the documentation shown
on the website when navigating to [intentional
deviations](https://docs.astral.sh/ruff/formatter/black/).
This PR streamlines the `ruff-python-formatter/README.md` and links to
the documentation on the website instead of repeating the same content.
The PR also makes the 2024 style guide deviations available on the
website documentation.
## Test Plan
I built the documentation locally and verified that the 2024 style guide
known deviations are now shown on the website.
## Summary
In issue https://github.com/astral-sh/ruff/issues/6785 it is reported
that a docstring in the form of `''"assert" ' SAM macro definitions '''`
is autocorrected to `"""assert" ' SAM macro definitions '''` (note the
triple quotes one only one side), which breaks the python program due
`undetermined string lateral`.
* `Q002`: Not only would docstrings in the form of `''"assert" ' SAM
macro definitions '''` (single quotes) be autofixed wrongly, but also
e.g. `""'assert' ' SAM macro definitions '''` (double quotes). The bug
is present for docstrings in all scopes (e.g. module docstrings, class
docstrings, function docstrings)
* `Q000`: The autofix error is not only present for `Q002` (docstrings),
but also for inline strings (`Q000`). Therefore `s = ''"assert" ' SAM
macro definitions '''` will also be wrongly autofixed.
Note that situation in which the first string is non-empty can be fixed,
e.g. `'123'"assert" ' SAM macro definitions '''` -> `"123""assert" ' SAM
macro definitions '''` is valid.
## What
* Change FixAvailability of `Q000` `Q002` to `Sometimes`
* Changed both rules such that docstrings/inline strings that cannot be
fixed are still reported as bad quotes via diagnostics, but no fix is
provided
## Test Plan
* For `Q000`: Add docstrings in different scopes that (partially) would
have been autofixed wrongly
* For `Q002`: Add inline strings that (partially) would have been
autofixed wrongly
Closes https://github.com/astral-sh/ruff/issues/6785
## Summary
The upstream category check here
fd26b29986/crates/ruff_linter/src/upstream_categories.rs (L54-L65)
was not working because the code is actually "E0001" not "PLE0001", I
changed it so it will detect the upstream category correctly.
I also sorted the upstream categories alphabetically, so that the
document generation will be deterministic.
## Test Plan
I compared the diff before and after the change.
Fixes#10426
## Summary
Fix rule B030 giving a false positive with Tuple operations like `+`.
[Playground](https://play.ruff.rs/17b086bc-cc43-40a7-b5bf-76d7d5fce78a)
```python
try:
...
except (ValueError,TypeError) + (EOFError,ArithmeticError):
...
```
## Reviewer notes
This is a little more convoluted than I was expecting -- because we can
have valid nested Tuples with operations done on them, the flattening
logic has become a bit more complex.
Shall I guard this behind --preview?
## Test Plan
Unit tested.
## Summary
Implement `singledispatchmethod-function` from pylint, part of #970.
This is essentially a copy paste of #8934 for `@singledispatchmethod`
decorator.
## Test Plan
Text fixture added.
## Summary
Short-circuit implementation mentioned in #10403.
I implemented this by extending C400:
- Made `UnnecessaryGeneratorList` have information of whether the the
short-circuiting occurred (to put diagnostic)
- Add additional check for whether in `unnecessary_generator_list`
function.
Please give me suggestions if you think this isn't the best way to
handle this :)
## Test Plan
Extended `C400.py` a little, and written the cases where:
- Code could be converted to one single conversion to `list` e.g.
`list(x for x in range(3))` -> `list(range(3))`
- Code couldn't be converted to one single conversion to `list` e.g.
`list(2 * x for x in range(3))` -> `[2 * x for x in range(3)]`
- `list` function is not built-in, and should not modify the code in any
way.
## Summary
Trailing ellipses in objects defined in `typing.TYPE_CHECKING` might be
meaningful (it might be declaring a stub). Thus, we should skip the
`unnecessary-placeholder` (`PIE970`) rule in such contexts.
Closes#10358.
## Test Plan
`cargo nextest run`
## Summary
Given `del X`, we'll typically add a `BindingKind::Deletion` to `X` to
shadow the current binding. However, if the deletion is inside of a
conditional operation, we _won't_, as in:
```python
def f():
global X
if X > 0:
del X
```
We will, however, track it as a reference to the binding. This PR adds
the expression context to those resolved references, so that we can
detect that the `X` in `global X` was "assigned to".
Closes https://github.com/astral-sh/ruff/issues/10397.
## Summary
The previous documentation sounded as if typing a mutable default as a
`ClassVar` were optional. However, it is not, as not doing so causes a
`ValueError`. The snippet below was tested in Python's interactive
shell:
```
>>> from dataclasses import dataclass
>>> @dataclass
... class A:
... mutable_default: list[int] = []
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.11/dataclasses.py", line 1230, in dataclass
return wrap(cls)
^^^^^^^^^
File "/usr/lib/python3.11/dataclasses.py", line 1220, in wrap
return _process_class(cls, init, repr, eq, order, unsafe_hash,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/dataclasses.py", line 958, in _process_class
cls_fields.append(_get_field(cls, name, type, kw_only))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/dataclasses.py", line 815, in _get_field
raise ValueError(f'mutable default {type(f.default)} for field '
ValueError: mutable default <class 'list'> for field mutable_default is not allowed: use default_factory
>>>
```
This behavior is also documented in Python's docs, see
[here](https://docs.python.org/3/library/dataclasses.html#mutable-default-values):
> [...] the
[dataclass()](https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass)
decorator will raise a
[ValueError](https://docs.python.org/3/library/exceptions.html#ValueError)
if it detects an unhashable default parameter. The assumption is that if
a value is unhashable, it is mutable. This is a partial solution, but it
does protect against many common errors.
And
[here](https://docs.python.org/3/library/dataclasses.html#class-variables)
it is documented why it works if it is typed as a `ClassVar`:
> One of the few places where
[dataclass()](https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass)
actually inspects the type of a field is to determine if a field is a
class variable as defined in [PEP
526](https://peps.python.org/pep-0526/). It does this by checking if the
type of the field is typing.ClassVar. If a field is a ClassVar, it is
excluded from consideration as a field and is ignored by the dataclass
mechanisms. Such ClassVar pseudo-fields are not returned by the
module-level
[fields()](https://docs.python.org/3/library/dataclasses.html#dataclasses.fields)
function.
In this PR I have changed the documentation to make it a little bit
clearer that not using `ClassVar` makes the code invalid.
## Summary
Ignoring all lines until the first logical line does not match the
behavior from pycodestyle. This PR therefore removes the `if
state.is_not_first_logical_line` skipping the line check before the
first logical line, and applies it only to `E302`.
For example, in the snippet below a rule violation should be detected on
the second comment and on the import.
```python
# first comment
# second comment
import foo
```
Fixes#10374
## Test Plan
Add test cases, update the snapshots and verify the ecosystem check output
## Summary
This PR updates the `StringLike::FString` variant to use `ExprFString`
instead of `FStringLiteralElement`.
For context, the reason it used `FStringLiteralElement` is that the node
is actually the string part of an f-string ("foo" in `f"foo{x}"`). But,
this is inconsistent with other variants where the captured value is the
_entire_ string.
This is also problematic w.r.t. implicitly concatenated strings. Any
rules which work with `StringLike::FString` doesn't account for the
string part in an implicitly concatenated f-strings. For example, we
don't flag confusable character in the first part of `"𝐁ad" f"𝐁ad
string"`, but only the second part
(https://play.ruff.rs/16071c4c-a1dd-4920-b56f-e2ce2f69c843).
### Update `PYI053`
_This is included in this PR because otherwise it requires a temporary
workaround to be compatible with the old logic._
This PR also updates the `PYI053` (`string-or-bytes-too-long`) rule for
f-string to consider _all_ the visible characters in a f-string,
including the ones which are implicitly concatenated. This is consistent
with implicitly concatenated strings and bytes.
For example,
```python
def foo(
# We count all the characters here
arg1: str = '51 character ' 'stringgggggggggggggggggggggggggggggggg',
# But not here because of the `{x}` replacement field which _breaks_ them up into two chunks
arg2: str = f'51 character {x} stringgggggggggggggggggggggggggggggggggggggggggggg',
) -> None: ...
```
This PR fixes it to consider all _visible_ characters inside an f-string
which includes expressions as well.
fixes: #10310fixes: #10307
## Test Plan
Add new test cases and update the snapshots.
## Review
To facilitate the review process, the change have been split into two
commits: one which has the code change while the other has the test
cases and updated snapshots.
## Summary
Fixes#10367.
While the server is still in an unstable state, requiring a `--preview`
flag would be a good way to indicate this to end users.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Adds a successful check message after no errors were found
Implements #8553
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Ran a check on a test file with `cargo run -p ruff_cli -- check test.py
--no-cache` and outputted as expected.
Ran the same check with `cargo run -p ruff_cli -- check test.py
--no-cache --silent` and the command was gone as expected.
<!-- How was it tested? -->
---------
Co-authored-by: Zanie Blue <contact@zanie.dev>
Re-implementation of https://github.com/astral-sh/ruff/pull/5845 but
instead of deprecating the option I toggle the default. Now users can
_opt-in_ via the setting which will give them an unsafe fix to remove
the import. Otherwise, we raise violations but do not offer a fix. The
setting is a bit of a misnomer in either case, maybe we'll want to
remove it still someday.
As discussed there, I think the safe fix should be to import it as an
alias. I'm not sure. We need support for offering multiple fixes for
ideal behavior though? I think we should remove the fix entirely and
consider it separately.
Closes https://github.com/astral-sh/ruff/issues/5697
Supersedes https://github.com/astral-sh/ruff/pull/5845
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR adds methods on `FString` to iterate over the two different kind
of elements it can have - literals and expressions. This is similar to
the methods we have on `ExprFString`.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Fix "TRIO115 false positive with with sleep(var) where var starts as 0"
#9935 based on the discussion in the issue.
## Test Plan
Issue code added to fixture
## Summary
I used `codespell` and `gramma` to identify mispellings and grammar
errors throughout the codebase and fixed them. I tried not to make any
controversial changes, but feel free to revert as you see fit.
## Summary
We had a report of a test failure on a specific architecture, and
looking into it, I think the test assumes that the hash keys are
iterated in a specific order. This PR thus adds a variant to our
settings display macro specifically for maps and sets. Like `CacheKey`,
it sorts the keys when printing.
Closes https://github.com/astral-sh/ruff/issues/10359.
## Summary
Fixes#10351
It seems the bug was caused by this section of code
b669306c87/crates/ruff_python_index/src/indexer.rs (L55-L58)
It's true that newline tokens cannot be immediately followed by line
continuations, but only outside parentheses. e.g. the exception
```
(
1
\
+ 2)
```
But why was this check put there in the first place? Is it guarding
against something else?
## Test Plan
New test was added to indexer
## Summary
When negating an expression like `a or b`, we need to wrap it in
parentheses, e.g., `not (a or b)` instead of `not a or b`, due to
operator precedence.
Closes https://github.com/astral-sh/ruff/issues/10335.
## Test Plan
`cargo test`
This PR fixes the following false positive in a `.pyi` stub file:
```py
x: int
y = x # F821 currently emitted here, but shouldn't be in a stub file
```
In a `.py` file, this is invalid regardless of whether `from __future__ import annotations` is enabled or not. In a `.pyi` stub file, however, it's always valid, as an annotation counts as a binding in a stub file even if no value is assigned to the variable.
I also added more test coverage for `.pyi` stub files in various edge cases where ruff's behaviour is currently correct, but where `.pyi` stub files do slightly different things to `.py` files.
## Summary
Fixes#10295.
`E225` (`Missing whitespace around operator`) and `E275` (`Missing
whitespace after keyword`) try to add a white space even when the next
character is a `)` (which is a syntax error in most cases, the
exceptions already being handled). This causes `E202` (`Whitespace
before close bracket`) to try to remove the added whitespace, resulting
in an infinite loop when `E225`/`E275` re-add it.
This PR adds an exception in `E225` and `E275` to not trigger in case
the next token is a `)`. It is a bit simplistic, but it solves the
example given in the issue without introducing a change in behavior
(according to the fixtures).
## Test Plan
`cargo test` and the `ruff-ecosystem` check were used to check that the
PR's changes do not have side-effects.
A new fixture was added to check that running the 3 rules on the example
given in the issue does not cause ruff to fail to converge.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR introduces the `ruff_server` crate and a new `ruff server`
command. `ruff_server` is a re-implementation of
[`ruff-lsp`](https://github.com/astral-sh/ruff-lsp), written entirely in
Rust. It brings significant performance improvements, much tighter
integration with Ruff, a foundation for supporting entirely new language
server features, and more!
This PR is an early version of `ruff_lsp` that we're calling the
**pre-release** version. Anyone is more than welcome to use it and
submit bug reports for any issues they encounter - we'll have some
documentation on how to set it up with a few common editors, and we'll
also provide a pre-release VSCode extension for those interested.
This pre-release version supports:
- **Diagnostics for `.py` files**
- **Quick fixes**
- **Full-file formatting**
- **Range formatting**
- **Multiple workspace folders**
- **Automatic linter/formatter configuration** - taken from any
`pyproject.toml` files in the workspace.
Many thanks to @MichaReiser for his [proof-of-concept
work](https://github.com/astral-sh/ruff/pull/7262), which was important
groundwork for making this PR possible.
## Architectural Decisions
I've made an executive choice to go with `lsp-server` as a base
framework for the LSP, in favor of `tower-lsp`. There were several
reasons for this:
1. I would like to avoid `async` in our implementation. LSPs are mostly
computationally bound rather than I/O bound, and `async` adds a lot of
complexity to the API, while also making harder to reason about
execution order. This leads into the second reason, which is...
2. Any handlers that mutate state should be blocking and run in the
event loop, and the state should be lock-free. This is the approach that
`rust-analyzer` uses (also with the `lsp-server`/`lsp-types` crates as a
framework), and it gives us assurances about data mutation and execution
order. `tower-lsp` doesn't support this, which has caused some
[issues](https://github.com/ebkalderon/tower-lsp/issues/284) around data
races and out-of-order handler execution.
3. In general, I think it makes sense to have tight control over
scheduling and the specifics of our implementation, in exchange for a
slightly higher up-front cost of writing it ourselves. We'll be able to
fine-tune it to our needs and support future LSP features without
depending on an upstream maintainer.
## Test Plan
The pre-release of `ruff_server` will have snapshot tests for common
document editing scenarios. An expanded test suite is on the roadmap for
future version of `ruff_server`.
## Summary
Fix#10282
This PR updates the Python grammar to include the `*` character in
`*args` `**kwargs` in the range of the `Parameter`
```
def f(*args, **kwargs): pass
# ~~~~ ~~~~~~ <-- range before the PR
# ^^^^^ ^^^^^^^^ <-- range after
```
The invalid syntax `def f(*, **kwargs): ...` is also now correctly
reported.
## Test Plan
Test cases were added to `function.rs`.
## Summary
This PR changes how we format `with` statements with a single with item
for Python 3.8 or older. This change is not compatible with Black.
This is how we format a single-item with statement today
```python
def run(data_path, model_uri):
with pyspark.sql.SparkSession.builder.config(
key="spark.python.worker.reuse", value=True
).config(key="spark.ui.enabled", value=False).master(
"local-cluster[2, 1, 1024]"
).getOrCreate():
# ignore spark log output
spark.sparkContext.setLogLevel("OFF")
print(score_model(spark, data_path, model_uri))
```
This is different than how we would format the same expression if it is
inside any other clause header (`while`, `if`, ...):
```python
def run(data_path, model_uri):
while (
pyspark.sql.SparkSession.builder.config(
key="spark.python.worker.reuse", value=True
)
.config(key="spark.ui.enabled", value=False)
.master("local-cluster[2, 1, 1024]")
.getOrCreate()
):
# ignore spark log output
spark.sparkContext.setLogLevel("OFF")
print(score_model(spark, data_path, model_uri))
```
Which seems inconsistent to me.
This PR changes the formatting of the single-item with Python 3.8 or
older to match that of other clause headers.
```python
def run(data_path, model_uri):
with (
pyspark.sql.SparkSession.builder.config(
key="spark.python.worker.reuse", value=True
)
.config(key="spark.ui.enabled", value=False)
.master("local-cluster[2, 1, 1024]")
.getOrCreate()
):
# ignore spark log output
spark.sparkContext.setLogLevel("OFF")
print(score_model(spark, data_path, model_uri))
```
According to our versioning policy, this style change is gated behind a
preview flag.
## Test Plan
See added tests.
Added
## Summary
Fixes https://github.com/astral-sh/ruff/issues/10267
The issue with the current formatting is that the formatter flips
between the `SingleParenthesizedContextManager` and
`ParenthesizeIfExpands` or `SingleWithTarget` because the layouts use
incompatible formatting ( `SingleParenthesizedContextManager`:
`maybe_parenthesize_expression(context)` vs `ParenthesizeIfExpands`:
`parenthesize_if_expands(item)`, `SingleWithTarget`:
`optional_parentheses(item)`.
The fix is to ensure that the layouts between which the formatter flips
when adding or removing parentheses are the same. I do this by
introducing a new `SingleWithoutTarget` layout that uses the same
formatting as `SingleParenthesizedContextManager` if it has no target
and prefer `SingleWithoutTarget` over using `ParenthesizeIfExpands` or
`SingleWithTarget`.
## Formatting change
The downside is that we now use `maybe_parenthesize_expression` over
`parenthesize_if_expands` for expressions where
`can_omit_optional_parentheses` returns `false`. This can lead to stable
formatting changes. I only found one formatting change in our ecosystem
check and, unfortunately, this is necessary to fix the instability (and
instability fixes are okay to have as part of minor changes according to
our versioning policy)
The benefit of the change is that `with` items with a single context
manager and without a target are now formatted identically to how the
same expression would be formatted in other clause headers.
## Test Plan
I ran the ecosystem check locally
## Summary
This PR refactors the with item formatting to use more explicit layouts
to make it easier to understand the different formatting cases.
The benefit of the explicit layout is that it makes it easier to reasons
about layout transition between format runs. For example, today it's
possible that `SingleWithTarget` or `ParenthesizeIfExpands` add
parentheses around the with items for `with aaaaaaaaaa + bbbbbbbbbbbb:
pass`, resulting in `with (aaaaaaaaaa + bbbbbbbbbbbb): pass`. The
problem with this is that the next formatting pass uses the
`SingleParenthesizedContextExpression` layout that uses
`maybe_parenthesize_expression` which is different from
`parenthesize_if_expands(&expr)` or `optional_parentheses(&expr)`.
## Test Plan
`cargo test`
I ran the ecosystem checks locally and there are no changes.
This PR modifies our AST so that nodes for string literals, bytes literals and f-strings all retain the following information:
- The quoting style used (double or single quotes)
- Whether the string is triple-quoted or not
- Whether the string is raw or not
This PR is a followup to #10256. Like with that PR, this PR does not, in itself, fix any bugs. However, it means that we will have the necessary information to preserve quoting style and rawness of strings in the `ExprGenerator` in a followup PR, which will allow us to provide a fix for https://github.com/astral-sh/ruff/issues/7799.
The information is recorded on the AST nodes using a bitflag field on each node, similarly to how we recorded the information on `Tok::String`, `Tok::FStringStart` and `Tok::FStringMiddle` tokens in #10298. Rather than reusing the bitflag I used for the tokens, however, I decided to create a custom bitflag for each AST node.
Using different bitflags for each node allows us to make invalid states unrepresentable: it is valid to set a `u` prefix on a string literal, but not on a bytes literal or an f-string. It also allows us to have better debug representations for each AST node modified in this PR.
## Summary
Fixes the handling end of line comments that belong to `**kwargs` when
the `**kwargs` come after a slash.
The issue was that we missed to include the `**kwargs` start position
when determining the start of the next node coming after the `/`.
Fixes https://github.com/astral-sh/ruff/issues/10281
## Test Plan
Added test
## Summary
Changes the generic recommendation to replace
```python
if foo == True: ...
```
with `if cond:` to `if foo:`.
Still uses a generic message for compound comparisons as a specific
message starts to become confusing. For example,
```python
if foo == True != False: ...
```
produces two recommendations, one of which would recommend `if True:`,
which is confusing.
Resolves [recommendation in a previous
PR](https://github.com/astral-sh/ruff/pull/8613/files#r1514915070).
## Test Plan
`cargo nextest run`
## Summary
The code later in this file that checks for slices relies on the stack
of brackets to determine the position. I'm not sure why format strings
were being excluded from this, but the tests still pass with these match
guards removed.
Closes#10278
## Test Plan
~Still needs a test.~ Test case added for this example.
## Summary
This is a follow-up to https://github.com/astral-sh/ruff/pull/10238 to
offer fixes for the f-string rule regardless of the line length of the
resulting fix. To quote Alex in the linked PR:
> Yes, from the user's perspective I'd rather have a fix that may lead
to line length issues than have to fix them myself :-) Cleaning up line
lengths is easier than changing from `"".format()` to `f""`
I agree with this position, which is that if we're going to offer a
diagnostic, we should really be offering the user the ability to fix it
-- otherwise, we're just inconveniencing them.
## Summary
Given a format string like `"{x} {x}".format(x=foo())`, we should avoid
converting to an f-string, since doing so would require repeating the
function call (`f"{foo()} {foo()}"`), which could introduce side
effects.
Closes https://github.com/astral-sh/ruff/issues/10258.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/10235
This PR changes `UP032` to flag all `"".format` calls that can
technically be rewritten to an f-string, even if rewritting it to an
fstring, at least automatically, exceeds the line length (or increases
the amount by which it goes over the line length).
I looked at the Git history to understand whether the check prevents
some false positives (reported by an issue), but i haven't found a
compelling reason to limit the rule to only flag format calls that stay
in the line length limit:
* https://github.com/astral-sh/ruff/pull/7818 Changed the heuristic to
determine if the fix fits to address
https://github.com/astral-sh/ruff/discussions/7810
* https://github.com/astral-sh/ruff/pull/1905 first version of the rule
I did take a look at pyupgrade and couldn't find a similar check, at
least not in the rule code (maybe it's checked somewhere else?)
https://github.com/asottile/pyupgrade/blob/main/pyupgrade/_plugins/fstrings.py
## Breaking Change?
This could be seen as a breaking change according to ruff's [versioning
policy](https://docs.astral.sh/ruff/versioning/):
> The behavior of a stable rule is changed
* The scope of a stable rule is significantly increased
* The intent of the rule changes
* Does not include bug fixes that follow the original intent of the rule
It does increase the scope of the rule, but it is in the original intent
of the rule (so it's not).
## Test Plan
See changed test output
## Summary
When you try to remove an internal representation leaking into another
type and end up rewriting a simple version of `smallvec`.
The goal of this PR is to replace the `Box<[&'a str]>` with
`Box<QualifiedName>` to avoid that the internal `QualifiedName`
representation leaks (and it gives us a nicer API too). However, doing
this when `QualifiedName` uses `SmallVec` internally gives us all sort
of funny lifetime errors. I was lost but @BurntSushi came to rescue me.
He figured out that `smallvec` has a variance problem which is already
tracked in https://github.com/servo/rust-smallvec/issues/146
To fix the variants problem, I could use the smallvec-2-alpha-4 or
implement our own smallvec. I went with implementing our own small vec
for this specific problem. It obviously isn't as sophisticated as
smallvec (only uses safe code), e.g. it doesn't perform any size
optimizations, but it does its job.
Other changes:
* Removed `Imported::qualified_name` (the version that returns a
`String`). This can be replaced by calling `ToString` on the qualified
name.
* Renamed `Imported::call_path` to `qualified_name` and changed its
return type to `&QualifiedName`.
* Renamed `QualifiedName::imported` to `user_defined` which is the more
common term when talking about builtins vs the rest/user defined
functions.
## Test plan
`cargo test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/10039
The [recommendation for typing stub
files](https://typing.readthedocs.io/en/latest/source/stubs.html#blank-lines)
is to use **one** blank line to group related definitions and
otherwise omit blank lines.
The newly added blank line rules (`E3*`) didn't account for typing stub
files and enforced two empty lines at the top level and one empty line
otherwise, making it impossible to group related definitions.
This PR implements the `E3*` rules to:
* Not enforce blank lines. The use of blank lines in typing definitions
is entirely up to the user.
* Allow at most one empty line, including between top level statements.
## Test Plan
Added unit tests (It may look odd that many snapshots are empty but the
point is that the rule should no longer emit diagnostics)
## Summary
This PR changes the `E3*` rules to respect the `isort`
`lines-after-imports` and `lines-between-types` settings. Specifically,
the following rules required changing
* `TooManyBlannkLines` : Respects both settings.
* `BlankLinesTopLevel`: Respects `lines-after-imports`. Doesn't need to
respect `lines-between-types` because it only applies to classes and
functions
The downside of this approach is that `isort` and the blank line rules
emit a diagnostic when there are too many blank lines. The fixes aren't
identical, the blank line is less opinionated, but blank lines accepts
the fix of `isort`.
<details>
<summary>Outdated approach</summary>
Fixes
https://github.com/astral-sh/ruff/issues/10077#issuecomment-1961266981
This PR changes the blank line rules to not enforce the number of blank
lines after imports (top-level) if isort is enabled and leave it to
isort to enforce the right number of lines (depends on the
`isort.lines-after-imports` and `isort.lines-between-types` settings).
The reason to give `isort` precedence over the blank line rules is that
they are configurable. Users that always want to blank lines after
imports can use `isort.lines-after-imports=2` to enforce that
(specifically for imports).
This PR does not fix the incompatibility with the formatter in pyi files
that only uses 0 to 1 blank lines. I'll address this separately.
</details>
## Review
The first commit is a small refactor that simplified implementing the
fix (and makes it easier to reason about what's mutable and what's not).
## Test Plan
I added a new test and verified that it fails with an error that the fix
never converges. I verified the snapshot output after implementing the
fix.
---------
Co-authored-by: Hoël Bagard <34478245+hoel-bagard@users.noreply.github.com>
## Summary
When users provide configurations via `--config`, we use `shellexpand`
to ensure that we expand signifiers like `~` and environment variables.
In https://github.com/astral-sh/ruff/pull/9599, we modified `--config`
to accept either a path or an arbitrary setting. However, the detection
(to determine whether the value is a path or a setting) was lacking the
`shellexpand` behavior -- it was downstream. So we were always treating
paths like `~/ruff.toml` as values, not paths.
Closes https://github.com/astral-sh/ruff-vscode/issues/413.
The expression types in our AST are called `ExprYield`, `ExprAwait`,
`ExprStringLiteral` etc, except `ExprNamedExpr`, `ExprIfExpr` and
`ExprGenratorExpr`. This seems to align with [Python AST's
naming](https://docs.python.org/3/library/ast.html) but feels
inconsistent and excessive.
This PR removes the `Expr` postfix from `ExprNamedExpr`, `ExprIfExpr`,
and `ExprGeneratorExpr`.
## Summary
Charlie can probably explain this better than I but it turns out,
`CallPath` is used for two different things:
* To represent unqualified names like `version` where `version` can be a
local variable or imported (e.g. `from sys import version` where the
full qualified name is `sys.version`)
* To represent resolved, full qualified names
This PR splits `CallPath` into two types to make this destinction clear.
> Note: I haven't renamed all `call_path` variables to `qualified_name`
or `unqualified_name`. I can do that if that's welcomed but I first want
to get feedback on the approach and naming overall.
## Test Plan
`cargo test`
## Summary
This PR fixes for `invalid-first-argument` rules.
The fixes rename the first argument of methods and class methods to the
valid one. References to this argument are also renamed.
Fixes are skipped when another argument is named as the valid first
argument.
The fix is marked as unsafe due
The functions for the `N804` and `N805` rules are now merged, as they
only differ by the name of the valid first argument.
The rules were moved from the AST iteration to the deferred scopes to be
in the function scope while creating the fix.
## Test Plan
`cargo test`
## Summary
Allows `required-version` to be set with a version specifier, like
`>=0.3.1`.
If a single version is provided, falls back to assuming `==0.3.1`, for
backwards compatibility.
Closes https://github.com/astral-sh/ruff/issues/10192.
## Summary
This PR removes the unneeded lifetime `'b` from many of our `Visitor`
implementations.
The lifetime is unneeded because it is only constraint by `'a`, so we
can use `'a` directly.
## Test Plan
`cargo build`
## Summary
This PR changes the `CallPath` type alias to a newtype wrapper.
A newtype wrapper allows us to limit the API and to experiment with
alternative ways to implement matching on `CallPath`s.
## Test Plan
`cargo test`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Removes the unnecessary `exc` variable in `TRY300`'s docs example.
## Test Plan
```
python scripts/generate_mkdocs.py; mkdocs serve -f mkdocs.public.yml
```
## Summary
Fixes#10174 by allowing match cases to be enclosing nodes for
suppression comments. `else/elif` clauses are now also allowed to be
enclosing nodes.
## Test Plan
I've added the offending code from the original issue to the `RUF028`
snapshot test, and I've also expanded it to test the allowed `else/elif`
clause.
## Summary
This fixes https://github.com/astral-sh/ruff/issues/7868.
Support isort's `default-section` feature which allows any imports that
match sections that are not in `section-order` to be mapped to a
specifically named section.
https://pycqa.github.io/isort/docs/configuration/options.html#default-section
This has a few implications:
- It is no longer required that all known sections are defined in
`section-order`.
- This is technically a bw-incompat change because currently if folks
define custom groups, and do not define a `section-order`, the code used
to add all known sections to `section-order` while emitting warnings.
**However, when this happened, users would be seeing warnings so I do
not think it should count as a bw-incompat change.**
## Test Plan
- Added a new test.
- Did not break any existing tests.
Finally, I ran the following config against Pyramid's complex codebase
that was previously using isort and this change worked there.
### pyramid's previous isort config
5f7e286b06/pyproject.toml (L22-L37)
```toml
[tool.isort]
profile = "black"
multi_line_output = 3
src_paths = ["src", "tests"]
skip_glob = ["docs/*"]
include_trailing_comma = true
force_grid_wrap = false
combine_as_imports = true
line_length = 79
force_sort_within_sections = true
no_lines_before = "THIRDPARTY"
sections = "FUTURE,THIRDPARTY,FIRSTPARTY,LOCALFOLDER"
default_section = "THIRDPARTY"
known_first_party = "pyramid"
```
### tested with ruff isort config
```toml
[tool.ruff.lint.isort]
case-sensitive = true
combine-as-imports = true
force-sort-within-sections = true
section-order = [
"future",
"third-party",
"first-party",
"local-folder",
]
default-section = "third-party"
known-first-party = [
"pyramid",
]
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
Fixes#6611
## Summary
This lint rule spots comments that are _intended_ to suppress or enable
the formatter, but will be ignored by the Ruff formatter.
We borrow some functions the formatter uses for determining comment
placement / putting them in context within an AST.
The analysis function uses an AST visitor to visit each comment and
attach it to the AST. It then uses that context to check:
1. Is this comment in an expression?
2. Does this comment have bad placement? (e.g. a `# fmt: skip` above a
function instead of at the end of a line)
3. Is this comment redundant?
4. Does this comment actually suppress any code?
5. Does this comment have ambiguous placement? (e.g. a `# fmt: off`
above an `else:` block)
If any of these are true, a violation is thrown. The reported reason
depends on the order of the above check-list: in other words, a `# fmt:
skip` comment on its own line within a list expression will be reported
as being in an expression, since that reason takes priority.
The lint suggests removing the comment as an unsafe fix, regardless of
the reason.
## Test Plan
A snapshot test has been created.
## Summary
Adapts the fix for rule B006 to no longer modify the body of function
stubs, while retaining the change in method signature.
## Test Plan
The existing tests for B006 were adapted to reflect this change in
behavior.
## Relevant issue
https://github.com/astral-sh/ruff/issues/10083
## Summary
The `lxml` library has been modified to address known vulnerabilities
and unsafe defaults. As such, the `defusedxml`
library is no longer necessary, `defusedxml` has deprecated its `lxml`
module.
Closes https://github.com/astral-sh/ruff/issues/10030.
## Summary
This is a not-unpopular directory name, and it's led to tons of issues
and user confusion (most recently:
https://github.com/astral-sh/ruff-pre-commit/issues/69). I've wanted to
remove it for a long time, but we need to do so as part of a minor
release.
## Summary
Currently, rule `RUF015` is not able to detect the usage of
`list(iterable).pop(0)` falling under the category of an _unnecessary
iterable allocation for accessing the first element_. This PR wants to
change that. See the underlying issue for more details.
* Provide extension to detect `list(iterable).pop(0)`, but not
`list(iterable).pop(i)` where i > 1
* Update corresponding doc
## Test Plan
* `RUF015.py` and the corresponding snap file were extended such that
their correspond to the new behaviour
Closes https://github.com/astral-sh/ruff/issues/9190
---
PS: I've only been working on this ticket as I haven't seen any activity
from issue assignee @rmad17, neither in this repo nor in a fork. I hope
I interpreted his inactivity correctly. Didn't mean to steal his chance.
Since I stumbled across the underlying problem myself, I wanted to offer
a solution as soon as possible.
## Summary
It is a convention to use the `_()` alias for `gettext()`. We want to
avoid
statement expressions and assignments related to aliases of the gettext
API.
See https://docs.python.org/3/library/gettext.html for details. When one
uses `_() to mark a string for translation, the tools look for these
markers
and replace the original string with its translated counterpart. If the
string contains variable placeholders or formatting, it can complicate
the
translation process, lead to errors or incorrect translations.
## Test Plan
* Test file `RUF027_1.py` was extended such that the test reproduces the
false-positive
Closes https://github.com/astral-sh/ruff/issues/10023.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
The original implementation of this applied the runtime-required context
to definitions _within_ the function, but not the signature itself. (We
had test coverage; the snapshot was just correctly showing the wrong
outcome.)
Closes https://github.com/astral-sh/ruff/issues/10089.
## Summary
Update PLR1714 to ignore `sys.platform` and `sys.version` checks.
I'm not sure if these checks or if we need to add more. Please advise.
Fixes#10017
## Test Plan
Added a new test case and ran `cargo nextest run`
## Summary
Allows, e.g.:
```python
import os
os.environ["WORLD_SIZE"] = "1"
os.putenv("CUDA_VISIBLE_DEVICES", "4")
import torch
```
For now, this is only allowed in preview.
Closes https://github.com/astral-sh/ruff/issues/10059
## Summary
Closes#10031
- Detect commented out `case` statements. Playground repro:
https://play.ruff.rs/5a305aa9-6e5c-4fa4-999a-8fc427ab9a23
- Add more support for one-line commented out code.
## Test Plan
Unit tested and tested with
```sh
cargo run -p ruff -- check crates/ruff_linter/resources/test/fixtures/eradicate/ERA001.py --no-cache --preview --select ERA001
```
TODO:
- [x] `cargo insta test`
## Summary
Part of #7595
This PR moves the `RUF001` and `RUF002` rules to the AST checker. This
removes the use of docstring detection from these rules.
## Test Plan
As this is just a refactor, make sure existing test cases pass.
## Summary
Fixes#9895
The cause for this panic came from an offset error in the code. When
analyzing a hypothetical f-string, we attempt to re-parse it as an
f-string, and use the AST data to determine, among other things, whether
the format specifiers are correct. To determine the 'correctness' of a
format specifier, we actually have to re-parse the format specifier, and
this is where the issue lies. To get the source text for the specifier,
we were taking a slice from the original file source text... even though
the AST data for the specifier belongs to the standalone parsed f-string
expression, meaning that the ranges are going to be way off. In a file
with Unicode, this can cause panics if the slice is inside a char
boundary.
To fix this, we now slice from the temporary source we created earlier
to parse the literal as an f-string.
## Test Plan
The RUF027 snapshot test was amended to include a string with format
specifiers which we _should_ be calling out. This is to ensure we do
slice format specifiers from the source text correctly.
## Summary
_This is preview only feature and is available using the `--preview`
command-line flag._
With the implementation of [PEP 701] in Python 3.12, f-strings can now
be broken into multiple lines, can contain comments, and can re-use the
same quote character. Currently, no other Python formatter formats the
f-strings so there's some discussion which needs to happen in defining
the style used for f-string formatting. Relevant discussion:
https://github.com/astral-sh/ruff/discussions/9785
The goal for this PR is to add minimal support for f-string formatting.
This would be to format expression within the replacement field without
introducing any major style changes.
### Newlines
The heuristics for adding newline is similar to that of
[Prettier](https://prettier.io/docs/en/next/rationale.html#template-literals)
where the formatter would only split an expression in the replacement
field across multiple lines if there was already a line break within the
replacement field.
In other words, the formatter would not add any newlines unless they
were already present i.e., they were added by the user. This makes
breaking any expression inside an f-string optional and in control of
the user. For example,
```python
# We wouldn't break this
aaaaaaaaaaa = f"asaaaaaaaaaaaaaaaa { aaaaaaaaaaaa + bbbbbbbbbbbb + ccccccccccccccc } cccccccccc"
# But, we would break the following as there's already a newline
aaaaaaaaaaa = f"asaaaaaaaaaaaaaaaa {
aaaaaaaaaaaa + bbbbbbbbbbbb + ccccccccccccccc } cccccccccc"
```
If there are comments in any of the replacement field of the f-string,
then it will always be a multi-line f-string in which case the formatter
would prefer to break expressions i.e., introduce newlines. For example,
```python
x = f"{ # comment
a }"
```
### Quotes
The logic for formatting quotes remains unchanged. The existing logic is
used to determine the necessary quote char and is used accordingly.
Now, if the expression inside an f-string is itself a string like, then
we need to make sure to preserve the existing quote and not change it to
the preferred quote unless it's 3.12. For example,
```python
f"outer {'inner'} outer"
# For pre 3.12, preserve the single quote
f"outer {'inner'} outer"
# While for 3.12 and later, the quotes can be changed
f"outer {"inner"} outer"
```
But, for triple-quoted strings, we can re-use the same quote char unless
the inner string is itself a triple-quoted string.
```python
f"""outer {"inner"} outer""" # valid
f"""outer {'''inner'''} outer""" # preserve the single quote char for the inner string
```
### Debug expressions
If debug expressions are present in the replacement field of a f-string,
then the whitespace needs to be preserved as they will be rendered as it
is (for example, `f"{ x = }"`. If there are any nested f-strings, then
the whitespace in them needs to be preserved as well which means that
we'll stop formatting the f-string as soon as we encounter a debug
expression.
```python
f"outer { x = !s :.3f}"
# ^^
# We can remove these whitespaces
```
Now, the whitespace doesn't need to be preserved around conversion spec
and format specifiers, so we'll format them as usual but we won't be
formatting any nested f-string within the format specifier.
### Miscellaneous
- The
[`hug_parens_with_braces_and_square_brackets`](https://github.com/astral-sh/ruff/issues/8279)
preview style isn't implemented w.r.t. the f-string curly braces.
- The
[indentation](https://github.com/astral-sh/ruff/discussions/9785#discussioncomment-8470590)
is always relative to the f-string containing statement
## Test Plan
* Add new test cases
* Review existing snapshot changes
* Review the ecosystem changes
[PEP 701]: https://peps.python.org/pep-0701/
## Summary
Ignore `async for` loops when checking the SIM113 rule.
Closes#9995
## Test Plan
A new test case was added to SIM113.py with an async for loop.
## Summary
This PR is a small refactor to extract out the logic for normalizing
string in the formatter from the `StringPart` struct. It also separates
the quote selection into a separate method on the new
`StringNormalizer`. Both of these will help in the f-string formatting
to use `StringPart` and `choose_quotes` irrespective of normalization.
The reason for having separate quote selection and normalization step is
so that the f-string formatting can perform quote selection on its own.
Unlike string and byte literals, the f-string formatting would require
that the normalization happens only for the literal elements of it i.e.,
the "foo" and "bar" in `f"foo {x + y} bar"`. This will automatically be
handled by the already separate `normalize_string` function.
Another use-case in the f-string formatting is to extract out the
relevant information from the `StringPart` like quotes and prefix which
is to be passed as context while formatting each element of an f-string.
## Test Plan
Ensure that clippy is happy and all tests pass.
## Summary
This PR introduces a new semantic model flag `DOCSTRING` which suggests
that the model is currently in a module / class / function docstring.
This is the first step in eliminating the docstring detection state
machine which is prone to bugs as stated in #7595.
## Test Plan
~TODO: Is there a way to add a test case for this?~
I tested this using the following code snippet and adding a print
statement in the `string_like` analyzer to print if we're currently in a
docstring or not.
<details><summary>Test code snippet:</summary>
<p>
```python
"Docstring" ", still a docstring"
"Not a docstring"
def foo():
"Docstring"
"Not a docstring"
if foo:
"Not a docstring"
pass
class Foo:
"Docstring"
"Not a docstring"
foo: int
"Unofficial variable docstring"
def method():
"Docstring"
"Not a docstring"
pass
def bar():
"Not a docstring".strip()
def baz():
_something_else = 1
"""Not a docstring"""
```
</p>
</details>
## Summary
Implement [implicit readlines
(FURB129)](https://github.com/dosisod/refurb/blob/master/refurb/checks/iterable/implicit_readlines.py)
lint.
## Notes
I need a help/an opinion about suggested implementations.
This implementation differs from the original one from `refurb` in the
following way. This implementation checks syntactically the call of the
method with the name `readlines()` inside `for` {loop|generator
expression}. The implementation from refurb also
[checks](https://github.com/dosisod/refurb/blob/master/refurb/checks/iterable/implicit_readlines.py#L43)
that callee is a variable with a type `io.TextIOWrapper` or
`io.BufferedReader`.
- I do not see a simple way to implement the same logic.
- The best I can have is something like
```rust
checker.semantic().binding(checker.semantic().resolve_name(attr_expr.value.as_name_expr()?)?).statement(checker.semantic())
```
and analyze cases. But this will be not about types, but about guessing
the type by assignment (or with) expression.
- Also this logic has several false negatives, when the callee is not a
variable, but the result of function call (e.g. `open(...)`).
- On the other side, maybe it is good to lint this on other things,
where this suggestion is not safe, and push the developers to change
their interfaces to be less surprising, comparing with the standard
library.
- Anyway while the current implementation has false-positives (I
mentioned some of them in the test) I marked the fixes to be unsafe.
## Summary
Accept 0.0 and 1.0 as common magic values. This is in line with the
pylint behaviour, and I think makes sense conceptually.
## Test Plan
Test cases were added to
`crates/ruff_linter/resources/test/fixtures/pylint/magic_value_comparison.py`
## Summary
I was surprised to learn that we treat `x` in `[_ for x in y]` as an
"assignment" binding kind, rather than a dedicated comprehension
variable.
The docs previously mentioned an irrelevant config option, but were
missing a link to the relevant `ignore-init-module-imports` config
option which _is_ actually used.
Additionally, this commit adds a link to the documentation to explain
the conventions around a module interface which includes using a
redundant import alias to preserve an unused import.
(noticed this while filing #9962)
## Summary
This PR renames the semantic model flag `MODULE_DOCSTRING` to
`MODULE_DOCSTRING_BOUNDARY`. The main reason is for readability and for
the new semantic model flag `DOCSTRING` which tracks that the model is
in a module / class / function docstring.
I got confused earlier with the name until I looked at the use case and
it seems that the `_BOUNDARY` prefix is more appropriate for the
use-case and is consistent with other flags.
## Summary
This PR fixes the `DebugText` implementation to use the expression range
instead of the parenthesized range.
Taking the following code snippet as an example:
```python
x = 1
print(f"{ ( x ) = }")
```
The output of running it would be:
```
( x ) = 1
```
Notice that the whitespace between the parentheses and the expression is
preserved as is.
Currently, we don't preserve this information in the AST which defeats
the purpose of `DebugText` as the main purpose of the struct is to
preserve whitespaces _around_ the expression.
This is also problematic when generating the code from the AST node as
then the generator has no information about the parentheses the
whitespaces between them and the expression which would lead to the
removal of the parentheses in the generated code.
I noticed this while working on the f-string formatting where the debug
text would be used to preserve the text surrounding the expression in
the presence of debug expression. The parentheses were being dropped
then which made me realize that the problem is instead in the parser.
## Test Plan
1. Add a test case for the parser
2. Add a test case for the generator
## Summary
This PR ensures that if a list `x` is modified within a `for` loop, we
avoid flagging `list(x)` as unnecessary. Previously, we only detected
calls to exactly `.append`, and they couldn't be nested within other
statements.
Closes https://github.com/astral-sh/ruff/issues/9925.
## Summary
If these are defined within class scopes, they're actually attributes of
the class, and can be accessed through the class itself.
(We preserve our existing behavior for `.pyi` files.)
Closes https://github.com/astral-sh/ruff/issues/9948.
Fixes#8368
Fixes https://github.com/astral-sh/ruff/issues/9186
## Summary
Arbitrary TOML strings can be provided via the command-line to override
configuration options in `pyproject.toml` or `ruff.toml`. As an example:
to run over typeshed and respect typeshed's `pyproject.toml`, but
override a specific isort setting and enable an additional pep8-naming
setting:
```
cargo run -- check ../typeshed --no-cache --config ../typeshed/pyproject.toml --config "lint.isort.combine-as-imports=false" --config "lint.extend-select=['N801']"
```
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Zanie Blue <contact@zanie.dev>
## Summary
Currently these rules apply the heuristic that if the original sequence
doesn't have a newline in between the final sequence item and the
closing parenthesis, the autofix won't add one for you. The feedback
from @ThiefMaster, however, was that this was producing slightly unusual
formatting -- things like this:
```py
__all__ = [
"b", "c",
"a", "d"]
```
were being autofixed to this:
```py
__all__ = [
"a",
"b",
"c",
"d"]
```
When, if it was _going_ to be exploded anyway, they'd prefer something
like this (with the closing parenthesis on its own line, and a trailing comma added):
```py
__all__ = [
"a",
"b",
"c",
"d",
]
```
I'm still pretty skeptical that we'll be able to please everybody here
with the formatting choices we make; _but_, on the other hand, this
_specific_ change is pretty easy to make.
## Test Plan
`cargo test`. I also ran the autofixes for RUF022 and RUF023 on CPython
to check how they looked; they looked fine to me.
## Summary
If a generic appears multiple times on the right-hand side, we should
only include it once on the left-hand side when rewriting.
Closes https://github.com/astral-sh/ruff/issues/9904.
## Summary
This review contains a fix for
[D405](https://docs.astral.sh/ruff/rules/capitalize-section-name/)
(capitalize-section-name)
The problem is that Ruff considers the sub-section header as a normal
section if it has the same name as some section name. For instance, a
function/method has an argument named "parameters". This only applies if
you use Numpy style docstring.
See: [ISSUE](https://github.com/astral-sh/ruff/issues/9806)
The following will not raise D405 after the fix:
```python
def some_function(parameters: list[str]):
"""A function with a parameters parameter
Parameters
----------
parameters:
A list of string parameters
"""
...
```
## Test Plan
```bash
cargo test
```
---------
Co-authored-by: Mikko Leppänen <mikko.leppanen@vaisala.com>
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR reduces the size of `Expr` from 80 to 64 bytes, by reducing the
sizes of...
- `ExprCall` from 72 to 56 bytes, by using boxed slices for `Arguments`.
- `ExprCompare` from 64 to 48 bytes, by using boxed slices for its
various vectors.
In testing, the parser gets a bit faster, and the linter benchmarks
improve quite a bit.
## Summary
Corrects mentions of `Path.is_link` to `Path.is_symlink` (the former
doesn't exist).
## Test Plan
```sh
python scripts/generate_mkdocs.py && mkdocs serve -f mkdocs.public.yml
```
Fixes#9857.
## Summary
Statements like `logging.info("Today it is: {day}")` will no longer be
ignored by RUF027. As before, statements like `"Today it is:
{day}".format(day="Tuesday")` will continue to be ignored.
## Test Plan
The snapshot tests were expanded to include new cases. Additionally, the
snapshot tests have been split in two to separate positive cases from
negative cases.
## Summary
Django's `mark_safe` can also be used as a decorator, so we should
detect usages of `@mark_safe` for the purpose of the relevant Bandit
rule.
Closes https://github.com/astral-sh/ruff/issues/9780.
## Summary
Given:
```python
"""Make a summary line.
Note:
----
Per the code comment the next two lines are blank. "// The first blank line is the line containing the closing
triple quotes, so we need at least two."
"""
```
It turns out we excluded the line ending in `"""`, because it's empty
(unlike for functions, where it consists of the indent). This PR changes
the `following_lines` iterator to always include the trailing newline,
which gives us correct and consistent handling between function and
module-level docstrings.
Closes https://github.com/astral-sh/ruff/issues/9877.
#2977 added the `allow-dict-calls-with-keyword-arguments` configuration
option for the `unnecessary-collection-call (C408)` rule, but it did not
update the rule description.
## Summary
This PR adds the `AnyNode` and `AnyNodeRef` implementation for
`FStringFormatSpec` node which will be required in the f-string
formatting.
The main usage for this is so that we can pass in the node directly to
`suppressed_node` in case debug expression is used to format is as
verbatim text.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
`max-positional-args` defaults to `max-args` if it's not specified and
the default to `max-args` is 5, so saying that the default is 3 is
definitely wrong. Ideally, we wouldn't specify a default at all for this
config option, but I don't think that's possible?
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
Not sure.
## Summary
When we fall through to parsing, the comment-detection rule is a
significant portion of lint time. This PR adds an additional fast
heuristic whereby we abort if a comment contains two consecutive name
tokens (via the zero-allocation lexer). For the `ctypeslib.py`, which
has a few cases that are now caught by this, it's a 2.5x speedup for the
rule (and a 20% speedup for token-based rules).
These are for descriptors which affects the behavior of the object _as a
property_; I do not think they should be called directly but there is no
alternative when working with the object directly.
Closes https://github.com/astral-sh/ruff/issues/9789
## Summary
These run over nearly every identifier. It's rare to override them, so
when not provided, we can just use a match against the hardcoded default
set.
It turns out that for ASCII identifiers, this is nearly 2x faster:
```
Parser/before time: [15.388 ns 15.395 ns 15.406 ns]
Parser/after time: [8.3786 ns 8.5821 ns 8.7715 ns]
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#8151
This PR implements a new rule, `RUF027`.
## What it does
Checks for strings that contain f-string syntax but are not f-strings.
### Why is this bad?
An f-string missing an `f` at the beginning won't format anything, and
instead treat the interpolation syntax as literal.
### Example
```python
name = "Sarah"
dayofweek = "Tuesday"
msg = "Hello {name}! It is {dayofweek} today!"
```
It should instead be:
```python
name = "Sarah"
dayofweek = "Tuesday"
msg = f"Hello {name}! It is {dayofweek} today!"
```
## Heuristics
Since there are many possible string literals which contain syntax
similar to f-strings yet are not intended to be,
this lint will disqualify any literal that satisfies any of the
following conditions:
1. The string literal is a standalone expression. For example, a
docstring.
2. The literal is part of a function call with keyword arguments that
match at least one variable (for example: `format("Message: {value}",
value = "Hello World")`)
3. The literal (or a parent expression of the literal) has a direct
method call on it (for example: `"{value}".format(...)`)
4. The string has no `{...}` expression sections, or uses invalid
f-string syntax.
5. The string references variables that are not in scope, or it doesn't
capture variables at all.
6. Any format specifiers in the potential f-string are invalid.
## Test Plan
I created a new test file, `RUF027.py`, which is both an example of what
the lint should catch and a way to test edge cases that may trigger
false positives.
## Summary
It turns out we saw a panic in cases when dedenting blocks like the `def
wrapper` here:
```python
def instrument_url(f: UrlFuncT) -> UrlFuncT:
# TODO: Type this with ParamSpec to preserve the function signature.
if not INSTRUMENTING: # nocoverage -- option is always enabled; should we remove?
return f
else:
def wrapper(
self: "ZulipTestCase", url: str, info: object = {}, **kwargs: Union[bool, str]
) -> HttpResponseBase:
```
Since we relied on the first line to determine the indentation, instead
of the first non-empty line.
## Test Plan
`cargo test`
## Summary
This is a simple idea to avoid unnecessary work in the linter,
especially for rules that run on all name and/or all attribute nodes.
Imagine a rule like the NumPy deprecation check. If the user never
imported `numpy`, we should be able to skip that rule entirely --
whereas today, we do a `resolve_call_path` check on _every_ name in the
file. It turns out that there's basically a finite set of modules that
we care about, so we now track imports on those modules as explicit
flags on the semantic model. In rules that can _only_ ever trigger if
those modules were imported, we add a dedicated and extremely cheap
check to the top of the rule.
We could consider generalizing this to all modules, but I would expect
that not to be much faster than `resolve_call_path`, which is just a
hash map lookup on `TextSize` anyway.
It would also be nice to make this declarative, such that rules could
declare the modules they care about, the analyzers could call the rules
as appropriate. But, I don't think such a design should block merging
this.
## Summary
Often, when fixing, we need to dedent a block of code (e.g., if we
remove an `if` and dedent its body). Today, we use LibCST to parse and
adjust the indentation, which is really expensive -- but this is only
really necessary if the block contains a multiline string, since naively
adjusting the indentation for such a string can change the whitespace
_within_ the string.
This PR uses a simple dedent implementation for cases in which the block
doesn't intersect with a multi-line string (or an f-string, since we
don't support tracking multi-line strings for f-strings right now).
We could improve this even further by using the ranges to guide the
dedent function, such that we don't apply the dedent if the line starts
within a multiline string. But that would also need to take f-strings
into account, which is a little tricky.
## Test Plan
`cargo test`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
When I was looking at the v0.2.0 release, this method showed up in a
CodSpeed regression (we were calling it more), so I decided to quickly
look at speeding it up. @BurntSushi suggested using Aho-Corasick, and it
looks like it's about 7 or 8x faster:
```text
Parser/AhoCorasick time: [8.5646 ns 8.5914 ns 8.6191 ns]
Parser/Iterator time: [64.992 ns 65.124 ns 65.271 ns]
```
## Test Plan
`cargo test`
I noticed that the comment doesn't match the behavior:
- zip function is not used anymore
- parameters are not scanned in reverse
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
No need
Signed-off-by: Mikael Arguedas <mikael.arguedas@gmail.com>
## Summary
Adds an additional warning macro (we should consolidate these later)
that shows a warning once based on the content of the warning itself.
This is less efficient than `warn_user_once!` and `warn_user_by_id!`,
but this is so expensive that it doesn't matter at all.
Applies this macro to the various warnings for the v0.2.0 release, and
also includes the filename in said warnings, so the FastAPI case is now:
```text
warning: The top-level linter settings are deprecated in favour of their counterparts in the `lint` section. Please update the following options in /Users/crmarsh/workspace/fastapi/pyproject.toml:
- 'ignore' -> 'lint.ignore'
- 'select' -> 'lint.select'
- 'isort' -> 'lint.isort'
- 'pyupgrade' -> 'lint.pyupgrade'
- 'per-file-ignores' -> 'lint.per-file-ignores'
```
---------
Co-authored-by: Zanie <contact@zanie.dev>
## Summary
This was causing build failures for #9599. We were referencing the
command line overrides instead of the merged configuration data, hence
the issue.
## Test Plan
A snapshot test was added.
Follow-up to #9754 and #9689. Alternative to #9714.
Marks `TRY200` as removed and redirects to `B904` instead of marking as
deprecated and suggesting `B904` instead.
Extends https://github.com/astral-sh/ruff/pull/9752 adding internal test
rules for redirection
Fixes a bug where we did not see warnings for exact codes that are
redirected (just prefixes)
Cherry-picked from https://github.com/astral-sh/ruff/pull/9714 which is
being abandoned for now because we need to invest more into our
redirection infrastructure before it is feasible.
Fixes a bug in the implementation where we improperly included
deprecated rules in `RuleSelector.rules()` when preview is on. Includes
some clean-up of error messages and the implementation.
# Conflicts:
# crates/ruff/tests/integration_test.rs
## Summary
This rule was added to `flake8-type-checking` as `TC010`. We're about to
stabilize it, so we might as well use the correct code.
See: https://github.com/astral-sh/ruff/issues/9573.
## Summary
This PR stabilizes the preview rules from:
- `flake8-trio` (6 rules)
- `flake8-quotes` (1 rule)
- `pyupgrade` (1 rule)
- `flake8-pyi` (1 rule)
- `flake8-simplify` (2 rules)
- `flake8-bandit` (9 rules; 14 remain in preview)
- `flake8-type-checking` (1 rule)
- `numpy` (1 rule)
- `ruff` (4 rules, one elevated from nursery; 6 remain in preview as
they were added within the last 30 days)
- `flake8-logging` (4 rules)
I see these are largely uncontroversial.
Adds a new `Deprecated` rule group in addition to `Stable` and
`Preview`.
Deprecated rules:
- Warn on explicit selection without preview
- Error on explicit selection with preview
- Are excluded when selected by prefix with preview
Deprecates `TRY200`, `ANN101`, and `ANN102` as a proof of concept. We
can consider deprecating them separately.
Extends #9682 to error if the nursery selector is used or nursery rules
are selected without preview.
Part of #7992 — we will remove this in 0.3.0 instead so we can provide
nice errors in 0.2.0.
# Conflicts:
# crates/ruff/tests/integration_test.rs
# crates/ruff_workspace/src/configuration.rs
Fixes#7350
## Summary
* `--show-source` and `--no-show-source` are now deprecated.
* `output-format` supports two new variants, `full` and `concise`.
`text` is now a deprecated variant, and any use of it is treated as the
default serialization format.
* `--output-format` now default to `concise`
* In preview mode, `--output-format` defaults to `full`
* `--show-source` will still set `--output-format` to `full` if the
output format is not otherwise specified.
* likewise, `--no-show-source` can override an output format that was
set in a file-based configuration, though it will also be overridden by
`--output-format`
## Test Plan
A lot of tests were updated to use `--output-format=full`. Additional
tests were added to ensure the correct deprecation warnings appeared,
and that deprecated options behaved as intended.
# Conflicts:
# crates/ruff/tests/integration_test.rs
## Summary
Un-gates the behavior to allow `sys.path` modifications between imports,
which removed a bunch of false positives in the ecosystem CI at the
time.
## Summary
At present, our versioning policy forbids the addition of safe fixes to
stable rules outside of a minor release, so we've accumulated a bunch of
new fixes that are behind `--preview`, and can be ungated in v0.2.0.
To find these, I just grepped for `preview.is_enabled()` and identified
all such cases. I then audited the `preview_rules` test fixtures and
removed any tests that existed only to test this autofix behavior.
# Conflicts:
# crates/ruff_linter/src/rules/flake8_simplify/snapshots/ruff_linter__rules__flake8_simplify__tests__SIM114_SIM114.py.snap
# crates/ruff_linter/src/rules/flake8_simplify/snapshots/ruff_linter__rules__flake8_simplify__tests__preview__SIM114_SIM114.py.snap
## Summary
This rule was added to flake8-bugbear. In general, we tend to prefer
redirecting to prominent plugins when our own rules are reimplemented
(since more projects have `B` activated than `RUF`).
## Test Plan
`cargo test`
# Conflicts:
# crates/ruff_linter/src/rules/ruff/rules/mod.rs
Updated implementation of https://github.com/astral-sh/ruff/pull/7369
which was left out in the cold.
This was motivated again following changes in #9691 and #9689 where we
could not test the changes without actually deprecating or removing
rules.
---
Follow-up to discussion in https://github.com/astral-sh/ruff/pull/7210
Moves integration tests from using rules that are transitively in
nursery / preview groups to dedicated test rules that only exist during
development. These rules always raise violations (they do not require
specific file behavior). The rules are not available in production or in
the documentation.
Uses features instead of `cfg(test)` for cross-crate support per
https://github.com/rust-lang/cargo/issues/8379
## Summary
Just like #6537 and #6538 but for the `default` second parameter to
`getenv()`.
Also rename "BAD" to "BAR" in the tests, since those strings shouldn't
trigger the rule.
## Test Plan
Added passing and failing examples to `invalid_envvar_default.py`.
## Summary
This PR implements the `blank_line_after_nested_stub_class` preview
style in the formatter.
The logic is divided into 3 parts:
1. In between preceding and following nodes at top level and nested
suite
2. When there's a trailing comment after the class
3. When there is no following node from (1) which is the case when it's
the last or the only node in a suite
We handle (3) with `FormatLeadingAlternateBranchComments`.
## Test Plan
- Add new test cases and update existing snapshots
- Checked the `typeshed` diff
fixes: #8891
## Summary
This review contains a fix for
[ASYNC101](https://docs.astral.sh/ruff/rules/open-sleep-or-subprocess-in-async-function/)
(open-sleep-or-subprocess-in-async-function)
The problem is that ruff does not take open calls from pathlib.Path into
account in async functions. Path.open() call is still a blocking call.
In addition, PTH123 suggests to use pathlib.Path instead of os.open. So
this might create an additional confusion.
See: https://github.com/astral-sh/ruff/issues/6892
## Test Plan
```bash
cargo test
```
## Summary
Tweaks PLR2004 to show the literal source text, rather than the constant
value.
I noticed this when I had a hexadecimal constant, and the linter turned
it into base-10.
Now, if you have `0x300`, it will show `0x300` instead of `768`.
Also, added backticks around the constant in the output message.
## Test Plan
`cargo test`
## Summary
Given:
```python
from dataclasses import InitVar, dataclass
@dataclass
class C:
i: int
j: int = None
database: InitVar[DatabaseType] = None
def __post_init__(self, database):
if self.j is None and database is not None:
self.j = database.lookup('j')
c = C(10, database=my_database)
```
We should avoid marking `InitVar` as typing-only, since it _is_ required
by the dataclass at runtime.
Note that by default, we _already_ don't flag this, since the
`@dataclass` member is needed at runtime too -- so it's only a problem
with `strict` mode.
Closes https://github.com/astral-sh/ruff/issues/9666.
Changes our warning for combined use of `--preview` and `--select
NURSERY` to a hard error.
This should go out _before_ #9680 where we will ban use of `NURSERY`
outside of preview as well (see #9683).
Part of https://github.com/astral-sh/ruff/issues/7992
## Summary
Per https://github.com/astral-sh/ruff/issues/9570:
> `dtype` are a bit of a strange beast, but definitely best thought of
as instances, not classes, and they are meant to be comparable not just
to their own class, but also to the corresponding scalar types (e.g.,
`x.dtype == np.float32`) and strings (e.g., `x.dtype == ['i1,i4']`;
basically, `__eq__` always tries to do `dtype(other)`.
This PR thus allows comparisons to `dtype` in preview.
Closes https://github.com/astral-sh/ruff/issues/9570.
## Test Plan
`cargo test`
## Summary
This review contains a fix for
[RET504](https://docs.astral.sh/ruff/rules/unnecessary-assign/)
(unnecessary-assign)
The problem is that Ruff suggests combining a return statement inside
contextlib.suppress. Even though it is an unsafe fix it might lead to an
invalid code that is not equivalent to the original one.
See: https://github.com/astral-sh/ruff/issues/5909
## Test Plan
```bash
cargo test
```
## Summary
Given a statement like `colors = 6`, we currently treat the cell as an
automagic (since `colors` is an automagic) -- i.e., we assume it's
equivalent to `%colors = 6`. This PR adds some additional detection
whereby if the statement is an _assignment_, we avoid treating it as
such. I audited the list of automagics, and I believe this is safe for
all of them.
Closes https://github.com/astral-sh/ruff/issues/8526.
Closes https://github.com/astral-sh/ruff/issues/9648.
## Test Plan
`cargo test`
## Summary
This review contains a fix for
[PIE810](https://docs.astral.sh/ruff/rules/multiple-starts-ends-with/)
(multiple-starts-ends-with)
The problem is that ruff suggests combining multiple startswith/endswith
calls into a single call even though there might be a call with tuple of
strs. This leads to calling startswith/endswith with tuple of tuple of
strs which is incorrect and violates startswith/endswith conctract and
results in runtime failure.
However the following will be valid and fixed correctly =>
```python
x = ("hello", "world")
y = "h"
z = "w"
msg = "hello world"
if msg.startswith(x) or msg.startswith(y) or msg.startswith(z) :
sys.exit(1)
```
```
ruff --fix --select PIE810 --unsafe-fixes
```
=>
```python
if msg.startswith(x) or msg.startswith((y,z)):
sys.exit(1)
```
See: https://github.com/astral-sh/ruff/issues/8906
## Test Plan
```bash
cargo test
```
## Summary
This rule was just incorrect, it didn't match the examples in the docs.
(It's a very rarely-used rule since it's not included in any of the
conventions.)
Closes https://github.com/astral-sh/ruff/issues/9452.
## Summary
Add a rule for defaultdict(default_factory=callable). Instead suggest
using defaultdict(callable).
See: https://github.com/astral-sh/ruff/issues/9509
If a user tries to bind a "non-callable" to default_factory, the rule
ignores it. Another option would be to warn that it's probably not what
you want. Because Python allows the following:
```python
from collections import defaultdict
defaultdict(default_factory=1)
```
this raises after you actually try to use it:
```python
dd = defaultdict(default_factory=1)
dd[1]
```
=>
```bash
KeyError: 1
```
Instead using callable directly in the constructor it will raise (not
being a callable):
```python
from collections import defaultdict
defaultdict(1)
```
=>
```bash
TypeError: first argument must be callable or None
```
## Test Plan
```bash
cargo test
```
## Summary
When we are analyzing the implicit return rule this change add an
additional check to verify if the call expression has been annotated
with NoReturn type from typing module.
See: https://github.com/astral-sh/ruff/issues/5474
## Test Plan
```bash
cargo test
```
Previously, without the 'wrap_help' feature enabled, Clap would not do
any auto-wrapping of help text. For help text with long lines, this
tends to lead to non-ideal formatting. It can be especially difficult to
read when the width of the terminal is smaller.
This commit enables 'wrap_help', which will automatically cause Clap to
query the terminal size and wrap according to that. Or, if the terminal
size cannot be determined, it will default to a maximum line width of
100.
Ref https://github.com/astral-sh/ruff/pull/9599#discussion_r1464992692
## Summary
If you paste in the TOML for our default configuration (from the docs),
it's rejected by our JSON Schema:

It seems like the issue is with:
```toml
# Set the line length limit used when formatting code snippets in
# docstrings.
#
# This only has an effect when the `docstring-code-format` setting is
# enabled.
docstring-code-line-length = "dynamic"
```
Specifically, since that value uses a custom Serde implementation, I
guess Schemars bails out? This PR adds a custom representation to allow
`"dynamic"` (but no other strings):

This seems like it should work but I don't have a great way to test it.
Closes https://github.com/astral-sh/ruff/issues/9630.
## Summary
Checks for unnecessary `dict` comprehension when creating a new
dictionary from iterable. Suggest to replace with
`dict.fromkeys(iterable)`
See: https://github.com/astral-sh/ruff/issues/9592
## Test Plan
```bash
cargo test
```
## Summary
This PR introduces a new rule to sort `__slots__` and `__match_args__`
according to a [natural sort](https://en.wikipedia.org/wiki/Natural_sort_order), as was
requested in https://github.com/astral-sh/ruff/issues/1198#issuecomment-1881418365.
The implementation here generalises some of the machinery introduced in
3aae16f1bd
so that different kinds of sorts can be applied to lists of string
literals. (We use an "isort-style" sort for `__all__`, but that isn't
really appropriate for `__slots__` and `__match_args__`, where nearly
all items will be snake_case.) Several sections of code have been moved
from `sort_dunder_all.rs` to a new module, `sorting_helpers.rs`, which
`sort_dunder_all.rs` and `sort_dunder_slots.rs` both make use of.
`__match_args__` is very similar to `__all__`, in that it can only be a
tuple or a list. `__slots__` differs from the other two, however, in
that it can be any iterable of strings. If slots is a dictionary, the
values are used by the builtin `help()` function as per-attribute
docstrings that show up in the output of `help()`. (There's no
particular use-case for making `__slots__` a set, but it's perfectly
legal at runtime, so there's no reason for us not to handle it in this
rule.)
Note that we don't do an autofix for multiline `__slots__` if `__slots__` is a dictionary: that's out of scope. Everything else, we can nearly always fix, however.
## Test Plan
`cargo test` / `cargo insta review`.
I also ran this rule on CPython, and the diff looked pretty good
---
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Implement rule `mutable-fromkeys-value` (`RUF023`).
Autofixes
```python
dict.fromkeys(foo, [])
```
to
```python
{key: [] for key in foo}
```
The fix is marked as unsafe as it changes runtime behaviour. It also
uses `key` as the comprehension variable, which may not always be
desired.
Closes#4613.
## Test Plan
`cargo test`
## Summary
When determining whether _any_ settings have namespace packages, we need
to consider the global settings (as would be provided via `--config`).
This was a subtle fallout of a refactor.
Closes https://github.com/astral-sh/ruff/issues/9579.
## Test Plan
Tested locally by compiling Ruff and running against this
[namespace-test](https://github.com/gokay05/namespace-test) repo.
## Summary
This PR detects whether PLR0917 is being applied to a method or class
method, and if so, it ignores the first argument for the purposes of
counting the number of positional arguments.
## Test Plan
New tests have been added to the corresponding fixture.
Closes#9552.
## Summary
Long ago, we had a single `ruff` crate. We started to break that up, and
at some point, we wanted to separate the CLI from the core library. So
we created `ruff_cli`, which created a `ruff` binary. Later, the `ruff`
crate was renamed to `ruff_linter` and further broken up into additional
crates.
(This is all from memory -- I didn't bother to look through the history
to ensure that this is 100% correct :))
Now that `ruff` no longer exists, this PR renames `ruff_cli` to `ruff`.
The primary benefit is that the binary target and the crate name are now
the same, which helps with downstream tooling like `cargo-dist`, and
also removes some complexity from the crate and `Cargo.toml` itself.
## Test Plan
- Ran `rm -rf target/release`.
- Ran `cargo build --release`.
- Verified that `./target/release/ruff` was created.
## Summary
#5920 with a fix for the erroneous slice in `module_name`. Fixes#9547.
## Test Plan
Added `import bbb.ccc._ddd as eee` to the test fixture to ensure it no
longer panics.
`cargo test`
## Summary
This implements the rule proposed in #1198 (though it doesn't close the
issue, as there are some open questions about configuration that might
merit some further discussion).
## Test Plan
`cargo test` / `cargo insta review`. I also ran this PR branch on the CPython
codebase with `--fix --select=RUF022 --preview `, and the results looked
pretty good to me.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Andrew Gallant <andrew@astral.sh>
## Summary
add autofix for `deprecated_log_warn` (`PGH002`)
## Test Plan
`cargo test`
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Right now, if you run with `explicit-preview-rules`, and use something
like `select = ["RUF017"]`, we won't actually enable fixing for that
rule, because `fixable = ["ALL"]` (the default) won't include `RUF017`
due to the `explicit-preview-rules`.
The framing in this PR is that `explicit-preview-rules` should only
affect the enablement selectors, whereas the fixable selectors should
just include all possible matching rules. I think this will lead to the
most intuitive behavior.
Closes https://github.com/astral-sh/ruff/issues/9282. (An alternative to
https://github.com/astral-sh/ruff/pull/9284.)
## Summary
This PR is a more holistic fix for
https://github.com/astral-sh/ruff/issues/9534 and
https://github.com/astral-sh/ruff/issues/9159.
When we visit the AST, we track nodes that we need to visit _later_
(deferred nodes). For example, when visiting a function, we defer the
function body, since we don't want to visit the body until we've visited
the rest of the statements in the containing scope.
However, deferred nodes can themselves contain deferred nodes... For
example, a function body can contain a lambda (which contains a deferred
body). And then there are rarer cases, like a lambda inside of a type
annotation.
The aforementioned issues were fixed by reordering the deferral visits
to catch common cases. But even with those fixes, we still fail on cases
like:
```python
from __future__ import annotations
import re
from typing import cast
cast(lambda: re.match, 1)
```
Since we don't expect lambdas to appear inside of type definitions.
This PR modifies the `Checker` to keep visiting until all the deferred
stacks are empty. We _already_ do this for any one kind of deferred
node; now, we do it for _all_ of them at a level above.
## Summary
This is effectively the same problem as
https://github.com/astral-sh/ruff/pull/9175. And this just papers over
it again, though I'm gonna try a more holistic fix in a follow-up PR.
The _real_ fix here is that we need to continue to visit deferred items
until they're exhausted since, e.g., we still get this case wrong
(flagging `re` as unused):
```python
import re
cast(lambda: re.match, 1)
```
Closes https://github.com/astral-sh/ruff/issues/9534.
## Summary
I found that `cargo benchmark lexer` didn't work as expected:
```shell
❯ cargo benchmark lexer
Finished bench [optimized] target(s) in 0.08s
Running benches/formatter.rs (target/release/deps/formatter-4e1d9bf9d3ba529d)
Running benches/linter.rs (target/release/deps/linter-e449086ddfd8ad8c)
```
Turns out that `cargo bench -p ruff_benchmark` is now recommended over
`cargo benchmark`, so updating the docs to reflect that.
## Summary
Closes#9508 .
Add `__prepare__` method to dunder method list in
`is_known_dunder_method`.
## Test Plan
1. add "__prepare__" method to `Apple` class in
crates/ruff_linter/resources/test/fixtures/pylint/bad_dunder_method_name.py.
2. run `cargo test`
Implements SIM113 from #998
Added tests
Limitations
- No fix yet
- Only flag cases where index variable immediately precede `for` loop
@charliermarsh please review and let me know any improvements
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
In the `logical_lines`'s `expand_indent` , respect the
`LinterSettings::tab_size` setting instead of hardcoding the size of
tabs to 8.
Also see [this
conversation](https://github.com/astral-sh/ruff/pull/9266#discussion_r1447102212)
## Test Plan
Tested by running `cargo test`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#8334.
`Display` has been implemented for `ruff_workspace::Settings`, which
gives a much nicer and more readable output to `--show-settings`.
Internally, a `display_settings` utility macro has been implemented to
reduce the boilerplate of the display code.
### Work to be done
- [x] A lot of formatting for `Vec<_>` and `HashSet<_>` types have been
stubbed out, using `Debug` as a fallback. There should be a way to add
generic formatting support for these types as a modifier in
`display_settings`.
- [x] Several complex types were also stubbed out and need proper
`Display` implementations rather than falling back on `Debug`.
- [x] An open question needs to be answered: how important is it that
the output be valid TOML? Some types in settings, such as a hash-map
from a glob pattern to a multi-variant enum, will be hard to rework into
valid _and_ readable TOML.
- [x] Tests need to be implemented.
## Test Plan
Tests consist of a snapshot test for the default `--show-settings`
output and a doctest for `display_settings!`.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fix the message for `__aenter__ ` in PLC2801 (introduced in
https://github.com/astral-sh/ruff/pull/9166)
There is no `aenter` builtin in Python, so the current message is
misleading.
I take the message from original lint
https://github.com/pylint-dev/pylint/blob/main/pylint/constants.py#L211
P.S. I think here should be more accurate synchronization with original
lint (e.g. the current implementation will not lint `__enter__` on my
first sight), but it is out-of-scope of this change.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
I noticed that there should be a missing period added to some of the new
error messages for Unnecessary dunder call:
```
sandpit\test.py:6:16: PLC2801 Unnecessary dunder call to `__getattribute__`. Access attribute directly or use getattr built-in function..
```
## Test Plan
Static analysis of the implementation, as this has no existing test
cases.
## Summary
We haven't found time to flip this on, so feels like it's best to remove
it for now -- can always restore from source when we get back to it.
## Summary
Closes#9319, implements the [`SIM911` rule from
`flake8-simplify`](https://github.com/MartinThoma/flake8-simplify/pull/183).
#### Note
I wasn't sure whether or not to include
```rs
if checker.settings.preview.is_disabled() {
return;
}
```
at the beginning of the function with violation logic if the rule's
already declared as part of `RuleGroup::Preview`.
I've seen both variants, so I'd appreciate some feedback on that :)
## Summary
This PR attempts to improve `builtin-attribute-shadowing` (`A003`), a
rule which has been repeatedly criticized, but _does_ have value (just
not in the current form).
Historically, this rule would flag cases like:
```python
class Class:
id: int
```
This led to an increasing number of exceptions and special-cases to the
rule over time to try and improve it's specificity (e.g., ignore
`TypedDict`, ignore `@override`).
The crux of the issue is that given the above, referencing `id` will
never resolve to `Class.id`, so the shadowing is actually fine. There's
one exception, however:
```python
class Class:
id: int
def do_thing() -> id:
pass
```
Here, `id` actually resolves to the `id` attribute on the class, not the
`id` builtin.
So this PR completely reworks the rule around this _much_ more targeted
case, which will almost always be a mistake: when you reference a class
member from within the class, and that member shadows a builtin.
Closes https://github.com/astral-sh/ruff/issues/6524.
Closes https://github.com/astral-sh/ruff/issues/7806.
## Summary
Sort of a random PR to make the coupling between `pyproject_config` and
`resolver` more explicit by passing it to the `Resolver`, rather than
threading it through to each individual method.
Saves 2% on Airflow:
```shell
❯ hyperfine --warmup 20 -i "./target/release/main format ../airflow" "./target/release/ruff format ../airflow"
Benchmark 1: ./target/release/main format ../airflow
Time (mean ± σ): 72.7 ms ± 0.4 ms [User: 48.7 ms, System: 75.5 ms]
Range (min … max): 72.0 ms … 73.7 ms 40 runs
Benchmark 2: ./target/release/ruff format ../airflow
Time (mean ± σ): 71.4 ms ± 0.6 ms [User: 46.2 ms, System: 76.2 ms]
Range (min … max): 70.3 ms … 73.8 ms 41 runs
Summary
'./target/release/ruff format ../airflow' ran
1.02 ± 0.01 times faster than './target/release/main format ../airflow'
```
Fixes#8721
## Summary
This implements the rule proposed in #8721, as RUF021. `and` always
binds more tightly than `or` when chaining the two together.
(This should definitely be autofixable, but I'm leaving that to a
followup PR for now.)
## Test Plan
`cargo test` / `cargo insta review`
## Summary
This PR enables Ruff to remove redefined imports, as in:
```python
import os
import os
print(os)
```
Previously, Ruff would flag `F811` on the second `import os`, but
couldn't fix it.
For now, this fix is marked as safe, but only available in preview.
Closes https://github.com/astral-sh/ruff/issues/3477.
## Summary
On `main`, we flag redefinitions in cases like:
```python
import os
x = 1
if x > 0:
import os
```
That is, we consider these to be in the "same branch", since they're not
in disjoint branches. This matches Flake8's behavior, but it seems to
lead to false positives.
## Summary
Given a docstring like:
```python
def func(x: int, args: tuple[int]):
"""Toggle the gizmo.
Args:
x: Some argument.
args: Some other arguments.
"""
```
We were considering the `args:` descriptor to be an indented docstring
section header (since `Args:`) is a valid header name. This led to very
confusing diagnostics.
This PR makes the parsing a bit more lax in this case, such that if we
see a nested header that's more deeply indented than the preceding
header, and the preceding section allows sub-items (like `Args:`), we
avoid treating the nested item as a section header.
Closes https://github.com/astral-sh/ruff/issues/9426.
## Summary
After we apply fixes, the source code might be transformed. And yet,
we're using the _unmodified_ source code to compute locations in some
cases (e.g., for displaying parse errors, or Jupyter Notebook cells).
This can lead to subtle errors in reporting, or even panics. This PR
modifies the linter to use the _transformed_ source code for such
computations.
Closes https://github.com/astral-sh/ruff/issues/9407.
I just fixed this false negative in flake8-pyi
(https://github.com/PyCQA/flake8-pyi/pull/460), and then realised ruff
has the exact same bug! Luckily it's a very easy fix.
(The bug is that unused protocols go undetected if they're generic.)
## Summary
This is similar to https://github.com/astral-sh/ruff/pull/8876, but more
limited in scope:
1. It only applies to `# fmt: skip` (like Black). Like `# isort: on`, `#
fmt: on` needs to be on its own line (still).
2. It only delimits on `#`, so you can do `# fmt: skip # noqa`, but not
`# fmt: skip - some other content` or `# fmt: skip; noqa`.
If we want to support the `;`-delimited version, we should revisit
later, since we don't support that in the linter (so `# fmt: skip; noqa`
wouldn't register a `noqa`).
Closes https://github.com/astral-sh/ruff/issues/8892.
When formatting notebooks, we populate the `id` field for cells that do
not have one. Previously, we generated a UUID v4 which resulted in
non-deterministic formatting. Here, we generate the UUID from a seeded
random number generator instead of using true randomness. For example,
here are the first five ids it would generate:
```
7fb27b94-1602-401d-9154-2211134fc71a
acae54e3-7e7d-407b-bb7b-55eff062a284
9a63283c-baf0-4dbc-ab1f-6479b197f3a8
8dd0d809-2fe7-4a7c-9628-1538738b07e2
72eea511-9410-473a-a328-ad9291626812
```
We also add a check that an id is not present in another cell to prevent
accidental introduction of duplicate ids.
The specification is lax, and we could just use incrementing integers
e.g. `0`, `1`, ... but I have a minor preference for retaining the UUID
format. Some discussion
[here](https://github.com/astral-sh/ruff/pull/9359#discussion_r1439607121)
— I'm happy to go either way though.
Discovered via #9293
## Summary
Ensures that any lint rules that include line locations render them as
relative to the cell (and include the cell number) when inside a Jupyter
notebook.
Closes https://github.com/astral-sh/ruff/issues/6672.
## Test Plan
`cargo test`
## Summary
Given:
```python
F"{"ڤ
```
We try to locate the "unclosed left brace" error by subtracting the
quote size from the lexer offset -- so we subtract 1 from the end of the
source, which puts us in the middle of a Unicode character. I don't
think we should try to adjust the offset in this way, since there can be
content _after_ the quote. For example, with the advent of PEP 701, this
string could reasonably be fixed as:
```python
F"{"ڤ"}"
````
Closes https://github.com/astral-sh/ruff/issues/9379.
## Summary
This PR adds an autofix for the newly added PYI058 rule (added in
#9313). ~~The PR's current implementation is that the fix is only
available if the fully qualified name of `Generator` or `AsyncGenerator`
is being used:~~
- ~~`-> typing.Generator` is converted to `-> typing.Iterator`;~~
- ~~`-> collections.abc.AsyncGenerator[str, Any]` is converted to `->
collections.abc.AsyncIterator[str]`;~~
- ~~but `-> Generator` is _not_ converted to `-> Iterator`. (It would
require more work to figure out if `Iterator` was already imported or
not. And if it wasn't, where should we import it from? `typing`,
`typing_extensions`, or `collections.abc`? It seems much more
complicated.)~~
The fix is marked as always safe for `__iter__` or `__aiter__` methods
in `.pyi` files, but unsafe for all such methods in `.py` files that
have more than one statement in the method body.
This felt slightly fiddly to accomplish, but I couldn't _see_ any
utilities in
https://github.com/astral-sh/ruff/tree/main/crates/ruff_linter/src/fix
that would have made it simpler to implement. Lmk if I'm missing
something, though -- my first time implementing an autofix! :)
## Test Plan
`cargo test` / `cargo insta review`.
## Summary
We had an early `continue` in this loop, and we weren't setting
`comparator = next;` when continuing... This PR removes the early
continue altogether for clarity.
Closes https://github.com/astral-sh/ruff/issues/9374.
## Test Plan
`cargo test`
## Summary
Changes message from `"Relative imports are banned"` to `"Prefer
absolute imports over relative imports from parent modules"`.
Closes#9363.
## Test Plan
`cargo test`
## Summary
This PR modifies our `Cargo.toml` files to use workspace dependencies
for _all_ dependencies, rather than the status quo of sporadically
trying to use workspace dependencies for those dependencies that are
used across multiple crates. I find the current situation more confusing
and harder to manage, since we have a mix of workspace and crate-local
dependencies, whereas this setup consistently uses the same approach for
all dependencies.
## Summary
The `ureq` dev-dependency in the ruff_cli workspace member is unused.
There are no code references to `ureq` in that crate.
## Test Plan
ruff and its tests continues to compile with the dependency removed. :)
The "wsl" crate was last touched in 2019, whereas the "is-wsl" crate was
last updated in 2023. Additionally, it is unclear whether the "wsl"
crate supports both WSL1 and WSL2 (which was announced in 2019), whereas
the "is-wsl" crate explicitly supports both WSL1 and WSL2.
The required code changes are minimal, since both crates provide only a
`is_wsl() -> bool` function.
paramiko `set_missing_host_key_policy` has mandatory positional arg.
The [current
documentation](https://docs.astral.sh/ruff/rules/ssh-no-host-key-verification/#example)
leads to non-running code
```
>>> from paramiko import client
>>> ssh_client = client.SSHClient()
>>> ssh_client.set_missing_host_key_policy()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: SSHClient.set_missing_host_key_policy() missing 1 required positional argument: 'policy'
```
This PR modifies the documentation to set the policy to the [default
`RejectPolicy`](https://docs.paramiko.org/en/latest/api/client.html#paramiko.client.SSHClient.set_missing_host_key_policy)
Signed-off-by: Mikael Arguedas <mikael.arguedas@gmail.com>
## Summary
Remove the period from a couple short messages, for consistency with all
other short messages.
All other short rule messages lack such a period, except for long
messages made of multiple sentences.
## Test Plan
Tests modified accordingly.
Not sure if this would qualify as a breaking change because user-visible
messages are modified.
## Summary
This PR implements Y058 from flake8-pyi -- this is a new flake8-pyi rule
that was released as part of `flake8-pyi 23.11.0`. I've followed the
Python implementation as closely as possible (see
858c0918a8),
except that for the Ruff version, the rule also applies to `.py` files
as well as for `.pyi` files. (For `.py` files, we only emit the
diagnostic in very specific situations, however, as there's a much
higher likelihood of emitting false positives when applying this rule to
a `.py` file.)
## Test Plan
`cargo test`/`cargo insta review`
## Summary
Historically, we encoded this list by extracting the `__all__`. I went
to update it, but... is there really any value in it? Seems easier to
just treat `typing_extensions` as an alias for `typing`.
Closes https://github.com/astral-sh/ruff/issues/9334.
## Summary
We stopped releasing this a while ago and no longer advertise it
anywhere. IMO, we should remove it so that we stop paying the cost of
maintaining it. If we want to revive it, we can always do so from Git.
## Summary
This is a non-behavior-changing refactor to follow-up
https://github.com/astral-sh/ruff/pull/9321 by modifying
`DisplayParseError` to use owned data and make it useable as a
standalone error type (rather than using references and implementing
`Display`). I don't feel very strongly either way. I thought it was
awkward that the `FormatCommandError` had two branches in the display
path, and wanted to represent the `Parse` vs. other cases as a separate
enum, so here we are.
## Summary
The logic that detects continuations assumed that tokens themselves
cannot span multiple lines. However, strings _can_ -- even single-quoted
strings.
Closes https://github.com/astral-sh/ruff/issues/9323.
## Summary
I always found it odd that we had to pass this in, since it's really
higher-level context for the error. The awkwardness is further evidenced
by the fact that we pass in fake values everywhere (even outside of
tests). The source path isn't actually used to display the error; it's
only accessed elsewhere to _re-display_ the error in certain cases. This
PR modifies to instead pass the path directly in those cases.
## Summary
This PR modifies the semantics of `runtime-evaluated-decorators` to
respect decorators on both classes _and_ functions. Historically, this
only respected classes, since the common use-case is (e.g.)
`pydantic.BaseModel` -- but functions are equally valid.
Closes https://github.com/astral-sh/ruff/issues/9312.
## Test Plan
`cargo test`
## Summary
This helps a bit with (but does not close) the issues described in
https://github.com/astral-sh/ruff/issues/9311. E.g., now, we at least
see: `error: Failed to format main.py: source contains syntax errors:
invalid syntax. Got unexpected token '=' at byte offset 20`.
## Summary
Given:
```python
from somewhere import get_cfg
def lookup_cfg(cfg_description):
cfg = get_cfg(cfg_description)
if cfg is not None:
return cfg
raise AttributeError(f"No cfg found matching {cfg_description}")
```
We were analyzing the method from last-to-first statement. So we saw the
`raise`, then assumed the method _always_ raised. In reality, though, it
_might_ return. This PR improves the branch analysis to respect these
mixed cases.
Closes https://github.com/astral-sh/ruff/issues/9269.
Closes https://github.com/astral-sh/ruff/issues/9304.
## Summary
Remove `:` for PLR0917 to make all PLR09XX message look the same
```
PLR0904 Too many public methods (21 > 20)
PLR0911 Too many return statements (16 > 6)
PLR0912 Too many branches (13 > 12)
PLR0913 Too many arguments in function definition (10 > 5)
PLR0915 Too many statements (118 > 50)
PLR0917 Too many positional arguments: (15/5)
```
## Test Plan
<!-- How was it tested? -->
---------
Signed-off-by: Mikael Arguedas <mikael.arguedas@gmail.com>
## Summary
Part of #970.
This adds Pylint's [R0244
empty_comment](https://pylint.pycqa.org/en/latest/user_guide/messages/refactor/empty-comment.html)
lint as well as an always-safe fix.
## Test Plan
The included snapshot verifies the following:
- A line containing only a non-empty comment is not changed
- A line containing leading whitespace before a non-empty comment is not
changed
- A line containing only an empty comment has its content deleted
- A line containing only leading whitespace before an empty comment has
its content deleted
- A line containing only leading and trailing whitespace on an empty
comment has its content deleted
- A line containing trailing whitespace after a non-empty comment is not
changed
- A line containing only a single newline character (i.e. a blank line)
is not changed
- A line containing code followed by a non-empty comment is not changed
- A line containing code followed by an empty comment has its content
deleted after the last non-whitespace character
- Lines containing code and no comments are not changed
- Empty comment lines within block comments are ignored
- Empty comments within triple-quoted sections are ignored
## Comparison to Pylint
Running Ruff and Pylint 3.0.3 with Python 3.12.0 against the
`empty_comment.py` file added in this PR, we see the following:
* Identical behavior:
* empty_comment.py:3:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:4:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:5:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:18:0: R2044: Line with empty comment (empty-comment)
* Differing behavior:
* Pylint doesn't ignore empty comments in block comments commonly used
for visual spacing; I decided these were fine in this implementation
since many projects use these and likely do not want them removed.
* empty_comment.py:28:0: R2044: Line with empty comment (empty-comment)
* Pylint detects "empty comments" within the triple-quoted section at
the bottom of the file, which is arguably a bug in the Pylint
implementation since these are not truly comments. These are ignored by
this implementation.
* empty_comment.py:37:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:38:0: R2044: Line with empty comment (empty-comment)
* empty_comment.py:39:0: R2044: Line with empty comment (empty-comment)
## Summary
If a rule ends with a trailing placeholder (like "Use {target}"), that
gets interpreted as an HTML attribute adding, `target="target"` to the
node. This PR escapes such cases. In reality, they're rare, since we
almost always wrap placeholders in backticks, which avoids this problem
-- but in some cases, they are in fact correct to be un-backticked.
Closes https://github.com/astral-sh/ruff/issues/9288.
## Test Plan
<img width="673" alt="Screen Shot 2023-12-28 at 9 33 40 AM"
src="https://github.com/astral-sh/ruff/assets/1309177/14aaa168-c802-4258-b82d-217a85b42ebf">
## Summary
Hey there 👋 thanks for this great project!
On python code looking like the following
```
import yaml
from yaml.loader import SafeLoader
with MY_FILE_PATH.open("r") as my_file:
my_data = yaml.load(my_file, Loader=SafeLoader)
```
ruff reports this error:
```
S506 Probable use of unsafe loader `SafeLoader` with `yaml.load`. Allows instantiation of arbitrary objects. Consider `yaml.safe_load`.
```
This PR is an attempt to support SafeLoader being imported for either
`yaml` or `yaml.loader`
Disclaimer:
I am not familiar with Rust so this is likely not the better way of
doing it. Interested in hearing how to adapt this PR to provide similar
behavior in a better way
## Test Plan
The S506.py file was updated accordingly to cover the use cases and test
were confirmed to pass with this change.
## Summary
If `RUF100` is ignored via `per-file-ignores`, we need to avoid raising
it. `RUF100` has special "self-ignore" logic, since the rule itself
deals with `# noqa` directives. This PR wires up `per-file-ignores` to
that "self-ignore" logic.
Closes https://github.com/astral-sh/ruff/issues/9297.
We should avoid adding `-> None` to stubs in `.pyi` files, along with a
few other cases. (We already ignore abstract methods.)
Closes https://github.com/astral-sh/ruff/issues/9270.
## Summary
This PR adds some helper structs to the linter paths to enable passing
in the pre-computed tokens and parsed source code during benchmarking,
to remove lexing and parsing from the overall linter benchmark
measurement. We already remove parsing for the formatter, and we have
separate benchmarks for the lexer and the parser, so this should make it
much easier to measure linter performance changes.
## Summary
Adds a rule to detect unions that include `typing.NoReturn` or
`typing.Never`. In such cases, the use of the bottom type is redundant.
Closes https://github.com/astral-sh/ruff/issues/9113.
## Test Plan
`cargo test`
## Summary
fixes#6956
details in issue
Following an advice in
https://github.com/astral-sh/ruff/issues/6956#issuecomment-1817672585,
this change separates expressions to 3 levels of "constant likelihood":
* literals, empty dict and tuples... (definitely constant, level 2)
* CONSTANT_CASE vars (probably constant, 1)
* all other expressions (0)
a comparison is marked yoda if the level is strictly higher on its left
hand side
following
https://github.com/astral-sh/ruff/issues/6956#issuecomment-1697107822
marking compound expressions of literals (e.g. `60 * 60` ) as constants
this change current behaviour on
`SomeClass().settings.SOME_CONSTANT_VALUE > (60 * 60)` in the fixture
from error to ok
## Summary
Given a function like:
```python
def func(x: int):
if not x:
raise ValueError
else:
raise TypeError
```
We now correctly use `NoReturn` as the return type, rather than `None`.
Closes https://github.com/astral-sh/ruff/issues/9201.
## Summary
Part of #8771. flake8-pyi will emit a Y018 error for unused TypeVars,
ParamSpecs or TypeVarTuples; Ruff currently only emits PYI018 for unused
TypeVars.
This is my first "proper" Ruff PR -- let me know if there's a better way
of doing this! Not sure if the repeated calls to `match_typing_expr()`
are ideal.
## Test Plan
I manually updated the fixtures to add some unused ParamSpecs and
TypeVarTuples, and then updated the snapshots using `cargo insta
review`. All tests then passed when run using `cargo test`.
Bumps [wasm-bindgen-test](https://github.com/rustwasm/wasm-bindgen) from
0.3.38 to 0.3.39.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/rustwasm/wasm-bindgen/commits">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
New messages for "format" mode.
Fixes#9132
## Test Plan
<!-- How was it tested? -->
I ran the tests specified in `CONTRIBUTING.md`
```bash
cargo run -p ruff_cli -- check /path/to/some_files.py --no-cache
cargo run -p ruff_cli -- format --check /path/to/some_files.py --no-cache
cargo clippy --workspace --all-targets --all-features -- -D warnings
RUFF_UPDATE_SCHEMA=1 cargo test
pre-commit run --all-files --show-diff-on-failure
```
**Note:** In case no files are detected, either correctly formatted,
changed, or unchanged, it does not display a message. Wouldn't it be
better to show some message in this case?
## Summary
Given `Callable[[Callable[_P, _R]], Callable[_P, _R]]` from the
originating issue, when quoting `Callable`, we quoted the inner
`[Callable[_P, _R]]`, and then created a separate edit for the outer
`Callable`. Since there's an extra level of nesting in the subscript,
the edit for `[Callable[_P, _R]]` correctly did _not_ expand to the
entire expression. However, in this case, we should discard the inner
edit, since the expression is getting quoted by the outer edit anyway.
Closes https://github.com/astral-sh/ruff/issues/9162.
## Summary
A common mistake is to add quotes around one member in an `X | Y`-style
type union, as in:
```python
contract_versions_list: list[ContractVersion] | 'QuerySet[ContractVersion]' | None = None
```
However, doing so will lead to a runtime error if the annotation is
runtime-evaluated. This PR lints against such patterns.
Closes https://github.com/astral-sh/ruff/issues/9139.
## Summary
Fix dropped union expressions for piped non-types in `PYI055` autofix
If you had `type[int] | type[str] | str`, it would have dropped the
`str`, which breaks the type!
Closes#9156
## Test Plan
`cargo test`
Fix#9080
Example, where `[]` is a 2 byte non-breaking space:
```
def f():
""" Docstring header
^^^^ Real indentation is 4 chars
docstring body, over-indented
^^^^^^ Over-indentation is 6 - 4 = 2 chars due to this line
[] [] docstring body 2, further indented
^^^^^ We take these 4 chars/5 bytes to match the docstring ...
^^^ ... and these 2 chars/3 bytes to remove the `over_indented_size` ...
^^ ... but preserve this real indent
```
The example below used to panic because we tried to split at 2 bytes in
the 4-bytes character `转`.
```python
def sample_func(xx):
"""
转置 (transpose)
"""
return xx.T
```
Fixes#9145
Fixes https://github.com/astral-sh/ruff-vscode/issues/362
The second commit is a small test refactoring.
This sets `lto = "thin"` instead of using "fat" LTO, and sets
`codegen-units = 16`. These are the defaults for Cargo's `release`
profile, and I think it may give us faster iteration times, especially
when benchmarking. The point of this PR is to see what kind of impact
this has on benchmarks. It is expected that benchmarks may regress to
some extent.
I did some quick ad hoc experiments to quantify this change in compile
times. Namely, I ran:
cargo build --profile release -p ruff_cli
Then I ran
touch crates/ruff_python_formatter/src/expression/string/docstring.rs
(because that's where i've been working lately) and re-ran
cargo build --profile release -p ruff_cli
This last command is what I timed, since it reflects how much time one
has to wait between making a change and getting a compiled artifact.
Here are my results:
* With status quo `release` profile, build takes 77s
* with `release` but `lto = "thin"`, build takes 41s
* with `release`, but `lto = false`, build takes 19s
* with `release`, but `lto = false` **and** `codegen-units = 16`, build
takes 7s
* with `release`, but `lto = "thin"` **and** `codegen-units = 16`, build
takes 16s (i believe this is the default `release` configuration)
This PR represents the last option. It's not the fastest to compile, but
it's nearly a whole minute faster! The idea is that with `codegen-units
= 16`, we still make use of parallelism, but keep _some_ level of LTO on
to try and re-gain what we lose by increasing the number of codegen
units.
## Summary
Add new test cases for `with_item` and `match` sequence that demonstrate how long headers break.
Removes one use of `optional_parentheses` in a position where it is know that the parentheses always need to be added.
## Test Plan
cargo test
## Summary
Add some more documentation to `can_omit_optional_parentheses` because it is realy hard to understand.
Restrict the `Attribute` and `None` `OperatorPrecedence` branches to ensure they only get applyied to the intended nodes.
## Test Plan
Ecosystem check reports no differences. The compatibility index remains unchanged.
Given:
```python
x: DataFrame[
int
] = 1
```
We currently wrap the annotation in single quotes, which leads to a
syntax error:
```python
x: "DataFrame[
int
]" = 1
```
There are a few options for what to suggest for users here... Use triple
quotes:
```python
x: """DataFrame[
int
]""" = 1
```
Or, use an implicit string concatenation (which may require
parentheses):
```python
x: ("DataFrame["
"int"
"]") = 1
```
The solution I settled on here is to use the `Generator`, which
effectively means we write it out on a single line, like:
```python
x: "DataFrame[int]" = 1
```
It's kind of the "least opinionated" solution, but it does mean we'll
expand to a very long line in some cases.
Closes https://github.com/astral-sh/ruff/issues/9136.
This PR splits the string formatting code in the formatter to be handled
by the respective nodes.
Previously, the string formatting was done through a single
`FormatString` interface. Now, the nodes themselves are responsible for
formatting.
The following changes were made:
1. Remove `StringLayout::ImplicitStringConcatenationInBinaryLike` and
inline the call to `FormatStringContinuation`. After the refactor, the
binary like formatting would delegate to `FormatString` which would then
delegate to `FormatStringContinuation`. This removes the intermediary
steps.
2. Add formatter implementation for `FStringPart` which delegates it to
the respective string literal or f-string node.
3. Add `ExprStringLiteralKind` which is either `String` or `Docstring`.
If it's a docstring variant, then the string expression would not be
implicitly concatenated. This is guaranteed by the
`DocstringStmt::try_from_expression` constructor.
4. Add `StringLiteralKind` which is either a `String`, `Docstring` or
`InImplicitlyConcatenatedFString`. The last variant is for when the
string literal is implicitly concatenated with an f-string (`"foo" f"bar
{x}"`).
5. Remove `FormatString`.
6. Extract the f-string quote detection as a standalone function which
is public to the crate. This is used to detect the quote to be used for
an f-string at the expression level (`ExprFString` or
`FormatStringContinuation`).
### Formatter ecosystem result
**This PR**
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75804 | 1799 | 1648 |
| django | 0.99984 | 2772 | 34 |
| home-assistant | 0.99955 | 10596 | 214 |
| poetry | 0.99905 | 321 | 15 |
| transformers | 0.99967 | 2657 | 324 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99980 | 3669 | 18 |
| warehouse | 0.99976 | 654 | 14 |
| zulip | 0.99958 | 1459 | 36 |
**main**
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75804 | 1799 | 1648 |
| django | 0.99984 | 2772 | 34 |
| home-assistant | 0.99955 | 10596 | 214 |
| poetry | 0.99905 | 321 | 15 |
| transformers | 0.99967 | 2657 | 324 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99980 | 3669 | 18 |
| warehouse | 0.99976 | 654 | 14 |
| zulip | 0.99958 | 1459 | 36 |
This fixes a bug where the current indent level was not calculated
correctly for doctests. Namely, it didn't account for the extra indent
level (in terms of ASCII spaces) used by by the PS1 (`>>> `) and PS2
(`... `) prompts. As a result, lines could extend up to 4 spaces beyond
the configured line length limit.
We fix that by passing the `CodeExampleKind` to the `format` routine
instead of just the code itself. In this way, `format` can query whether
there will be any extra indent added _after_ formatting the code and
take that into account for its line length setting.
We add a few regression tests, taken directly from @stinodego's
examples.
Fixes#9126
This PR does the plumbing to make a new formatting option,
`docstring-code-format`, available in the configuration for end users.
It is disabled by default (opt-in). It is opt-in at least initially to
reflect a conservative posture. The intent is to make it opt-out at some
point in the future.
This was split out from #8811 in order to make #8811 easier to merge.
Namely, once this is merged, docstring code snippet formatting will
become available to end users. (See comments below for how we arrived at
the name.)
Closes#7146
## Test Plan
Other than the standard test suite, I ran the formatter over the CPython
and polars projects to ensure both that the result looked sensible and
that tests still passed. At time of writing, one issue that currently
appears is that reformatting code snippets trips the long line lint:
https://github.com/BurntSushi/polars/actions/runs/7006619426/job/19058868021
This PR adds a `as_slice` method to all the string nodes which returns
all the parts of the nodes as a slice. This will be useful in the next
PR to split the string formatting to use this method to extract the
_single node_ or _implicitly concanated nodes_.
## Summary
Adds support for sarif v2.1.0 output to cli, usable via the
output-format paramter.
`ruff . --output-format=sarif`
Includes a few changes I wasn't sure of, namely:
* Adds a few derives for Clone & Copy, which I think could be removed
with a little extra work as well.
## Test Plan
I built and ran this against several large open source projects and
verified that the output sarif was valid, using [Microsoft's SARIF
validator tool](https://sarifweb.azurewebsites.net/Validation)
I've also attached an output of the sarif generated by this version of
ruff on the main branch of django at commit: b287af5dc9
[django_main_b287af5dc9_sarif.json](https://github.com/astral-sh/ruff/files/13626222/django_main_b287af5dc9_sarif.json)
Note: this needs to be regenerated with the latest changes and
confirmed.
## Open Points
[ ] Convert to just using all Rules all the time
[ ] Fix the issue with getting the file URI when compiling for web
assembly
## Summary
This allows us to fix usages like:
```python
from pandas import DataFrame
def baz() -> DataFrame:
...
```
By quoting the `DataFrame` in `-> DataFrame`. Without quotes, moving
`from pandas import DataFrame` into an `if TYPE_CHECKING:` block will
fail at runtime, since Python tries to evaluate the annotation to add it
to the function's `__annotations__`.
Unfortunately, this does require us to split our "annotation kind" flags
into three categories, rather than two:
- `typing-only`: The annotation is only evaluated at type-checking-time.
- `runtime-evaluated`: Python will evaluate the annotation at runtime
(like above) -- but we're willing to quote it.
- `runtime-required`: Python will evaluate the annotation at runtime
(like above), and some library (like Pydantic) needs it to be available
at runtime, so we _can't_ quote it.
This functionality is gated behind a setting
(`flake8-type-checking.quote-annotations`).
Closes https://github.com/astral-sh/ruff/issues/5559.
## Summary
Adds `find_assigned_value` a function which gets the `&Expr` assigned to
a given `id` if one exists in the semantic model.
Open TODOs:
- [ ] Handle `binding.kind.is_unpacked_assignment()`: I am bit confused
by this one. The snippet from its documentation does not appear to be
counted as an unpacked assignment and the only ones I could find for
which that was true were invalid Python like:
```python
x, y = 1
```
- [ ] How to handle AugAssign. Can we combine statements like:
```python
(a, b) = [(1, 2, 3), (4,)]
a += (6, 7)
```
to get the full value for a? Code currently just returns `None` for
these assign types
- [ ] Multi target assigns
```python
m_c = (m_d, m_e) = (0, 0)
trio.sleep(m_c) # OK
trio.sleep(m_d) # TRIO115
trio.sleep(m_e) # TRIO115
```
## Test Plan
Used the function in two rules:
- `TRIO115`
- `PERF101`
Expanded both their fixtures for explicit multi target check
## Summary
A fairly common pattern which triggers F841 is unused variables from
tuple assignments, e.g.:
user, created = User.objects.get_or_create(...)
^ F841: Local variable `created` is assigned to but never used
This error is currently not auto-fixable.
This PR adds support for fixing the error automatically by renaming the
unused variable to have a leading underscore (i.e. `_created`) **iff**
the `dummy-variable-rgx` setting would match it.
I considered using `renamers::Renamer` here, but because by the nature
of the error there should be no references to it, that seemed like
overkill. Also note that the fix might break by shadowing the new name
if it is already used elsewhere in the scope. I left it as is because
1. the renamed variable matches the "unused" regex, so it should
hopefully not already be used,
2. the fix is marked as unsafe so it should be reviewed manually
anyways, and
3. I'm not actually sure how to check the scope for the new variable
name 😅
## Summary
This PR changes the internal `docstring-code-line-width` setting to
additionally accept a string value `dynamic`. When `dynamic` is set, the
line width is dynamically adjusted when reformatting code snippets in
docstrings based on the indent level of the docstring. The result is
that the reformatted lines from the code snippet should not exceed the
"global" line width configuration for the surrounding source.
This PR does not change the default behavior, although I suspect the
default should probably be `dynamic`.
## Test Plan
I added a new configuration to the existing docstring code tests and
also added a new set of tests dedicated to the new `dynamic` mode.
Hides hints about unsafe fixes when they are disabled e.g. with
`--no-unsafe-fixes` or `unsafe-fixes = false`. By default, unsafe fix
hints are still displayed. This seems like a nice way to remove the nag
for users who have chosen not to apply unsafe fixes.
Inspired by comment at
https://github.com/astral-sh/ruff/issues/9063#issuecomment-1850289675
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Check floating-point numbers similarly to integers in FURB163. For
example, both `math.log(x, 10)` and `math.log(x, 10.0)` should be
changed to `math.log10(x)`.
## Test Plan
<!-- How was it tested? -->
Added couple of test cases.
## Summary
E274 currently flags any keyword at the start of a line indented with
tabs. This turns out to be due to a bug in `Whitespace::trailing` that
never considers any whitespace containing a tab as indentation.
## Test Plan
Added a simple test case.
This PR allows `matplotlib.use` calls to intersperse imports without
triggering `E402`. This is a pragmatic choice as it's common to require
`matplotlib.use` calls prior to importing from within `matplotlib`
itself.
Closes https://github.com/astral-sh/ruff/issues/9091.
## Summary
This does the light plumbing necessary to add a new internal option that
permits setting the line width of code examples in docstrings. The plan
is to add the corresponding user facing knob in #8854.
Note that this effectively removes the `same-as-global` configuration
style discussed [in this
comment](https://github.com/astral-sh/ruff/issues/8855#issuecomment-1847230440).
It replaces it with the `{integer}` configuration style only.
There are a lot of commits here, but they are each tiny to make review
easier because of the changes to snapshots.
## Test Plan
I added a new docstring test configuration that sets
`docstring-code-line-width = 60` and examined the differences.
Bumps
[serde-wasm-bindgen](https://github.com/RReverser/serde-wasm-bindgen)
from 0.6.1 to 0.6.3.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="e65f027ed7"><code>e65f027</code></a>
chore: Release</li>
<li><a
href="0cf8879399"><code>0cf8879</code></a>
Fix find-replace typo in docs</li>
<li><a
href="ff83666343"><code>ff83666</code></a>
Fix doc annotation</li>
<li><a
href="014e415d41"><code>014e415</code></a>
chore: Release</li>
<li><a
href="34aab01dcb"><code>34aab01</code></a>
Use Wasm target for docs.rs</li>
<li><a
href="455d55645f"><code>455d556</code></a>
More consistent docs + hide internal fields</li>
<li><a
href="ce7669e1d1"><code>ce7669e</code></a>
Use field indices for struct deserialization</li>
<li><a
href="a7e4c5b5aa"><code>a7e4c5b</code></a>
Bump deps</li>
<li><a
href="b4b4965c63"><code>b4b4965</code></a>
Don't use --profiling for benchmarks</li>
<li><a
href="3dfe7271ba"><code>3dfe727</code></a>
Speed up integer decoding</li>
<li>Additional commits viewable in <a
href="https://github.com/RReverser/serde-wasm-bindgen/compare/v0.6.1...v0.6.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
## Summary
In https://github.com/astral-sh/ruff/pull/8921, we changed our parameter
formatting behavior to add a trailing comma whenever a single-argument
function breaks. This introduced a deviation in the case that a function
contains a single argument, but _also_ includes a positional-only or
keyword-only separator.
Closes https://github.com/astral-sh/ruff/issues/9074.
## Summary
Fixes#8863 : Detect asyncio-dangling-task (RUF006) when discarding
return value
## Test Plan
added new two testcases, changed result of an old one that was made more
specific
## Summary
Fix a couple typos:
- I'm certain about `It's is` → `It is`.
- Not sure about `is it's` → `if it's` because I don't understand the
sentence.
## Test Plan
No tests.
## Summary
This PR updates the logic for `is_magic_cell` to include certain cell
magics. These cell magics would contain Python code following the line
defining the command. The code could define a variable which can then be
referenced in other cells. Currently, we would ignore the cell
completely leading to undefined-name violation.
As discussed in
https://github.com/astral-sh/ruff/issues/8354#issuecomment-1832221009
## Test Plan
Add new test case to validate this scenario.
(This is not possible to actually use until
https://github.com/astral-sh/ruff/pull/8854 is merged.)
This commit slots in support for formatting Markdown fenced code
blocks[1]. With the refactoring done for reStructuredText previously,
this ended up being pretty easy to add. Markdown code blocks are also
quite a bit easier to parse and recognize correctly.
One point of contention in #8860 is whether to assume that unlabeled
Markdown code fences are Python or not by default. In this PR, we make
such an assumption. This follows what `rustdoc` does. The mitigation
here is that if an unlabeled code block isn't Python, then it probably
won't parse as Python. And we'll end up skipping it. So in the vast
majority of cases, the worst thing that can happen is a little bit of
wasted work.
Closes#8860
[1]: https://spec.commonmark.org/0.30/#fenced-code-blocks
## Summary
It's common to interleave a `sys.path` modification between imports at
the top of a file. This is a frequent cause of `# noqa: E402` false
positives, as seen in the ecosystem checks. This PR modifies E402 to
omit such modifications when determining the "import boundary".
(We could consider linting against `sys.path` modifications, but that
should be a separate rule.)
Closes: https://github.com/astral-sh/ruff/issues/5557.
## Summary
This PR introduces a new `StringLike` enum which is a narrow type to
indicate string-like nodes. These includes the string literals, bytes
literals, and the literal parts of f-strings.
The main motivation behind this is to avoid repetition of rule calling
in the AST checker. We add a new `analyze::string_like` function which
takes in the enum and calls all the respective rule functions which
expects atleast 2 of the variants of this enum.
I'm open to discarding this if others think it's not that useful at this
stage as currently only 3 rules require these nodes.
As suggested
[here](https://github.com/astral-sh/ruff/pull/8835#discussion_r1414746934)
and
[here](https://github.com/astral-sh/ruff/pull/8835#discussion_r1414750204).
## Test Plan
`cargo test`
Rebase of #6365 authored by @davidszotten.
## Summary
This PR updates the AST structure for an f-string elements.
The main **motivation** behind this change is to have a dedicated node
for the string part of an f-string. Previously, the existing
`ExprStringLiteral` node was used for this purpose which isn't exactly
correct. The `ExprStringLiteral` node should include the quotes as well
in the range but the f-string literal element doesn't include the quote
as it's a specific part within an f-string. For example,
```python
f"foo {x}"
# ^^^^
# This is the literal part of an f-string
```
The introduction of `FStringElement` enum is helpful which represent
either the literal part or the expression part of an f-string.
### Rule Updates
This means that there'll be two nodes representing a string depending on
the context. One for a normal string literal while the other is a string
literal within an f-string. The AST checker is updated to accommodate
this change. The rules which work on string literal are updated to check
on the literal part of f-string as well.
#### Notes
1. The `Expr::is_literal_expr` method would check for
`ExprStringLiteral` and return true if so. But now that we don't
represent the literal part of an f-string using that node, this improves
the method's behavior and confines to the actual expression. We do have
the `FStringElement::is_literal` method.
2. We avoid checking if we're in a f-string context before adding to
`string_type_definitions` because the f-string literal is now a
dedicated node and not part of `Expr`.
3. Annotations cannot use f-string so we avoid changing any rules which
work on annotation and checks for `ExprStringLiteral`.
## Test Plan
- All references of `Expr::StringLiteral` were checked to see if any of
the rules require updating to account for the f-string literal element
node.
- New test cases are added for rules which check against the literal
part of an f-string.
- Check the ecosystem results and ensure it remains unchanged.
## Performance
There's a performance penalty in the parser. The reason for this remains
unknown as it seems that the generated assembly code is now different
for the `__reduce154` function. The reduce function body is just popping
the `ParenthesizedExpr` on top of the stack and pushing it with the new
location.
- The size of `FStringElement` enum is the same as `Expr` which is what
it replaces in `FString::format_spec`
- The size of `FStringExpressionElement` is the same as
`ExprFormattedValue` which is what it replaces
I tried reducing the `Expr` enum from 80 bytes to 72 bytes but it hardly
resulted in any performance gain. The difference can be seen here:
- Original profile: https://share.firefox.dev/3Taa7ES
- Profile after boxing some node fields:
https://share.firefox.dev/3GsNXpD
### Backtracking
I tried backtracking the changes to see if any of the isolated change
produced this regression. The problem here is that the overall change is
so small that there's only a single checkpoint where I can backtrack and
that checkpoint results in the same regression. This checkpoint is to
revert using `Expr` to the `FString::format_spec` field. After this
point, the change would revert back to the original implementation.
## Review process
The review process is similar to #7927. The first set of commits update
the node structure, parser, and related AST files. Then, further commits
update the linter and formatter part to account for the AST change.
---------
Co-authored-by: David Szotten <davidszotten@gmail.com>
## Summary
Occasionally, valid code needs to use `argparse._SubParsersAction` in a
type annotation. This isn't great, but it's indicative of the fact that
public interfaces can return private types. If you accessed that private
type via a private interface, then we should be flagging the call site,
rather than the annotation.
Closes https://github.com/astral-sh/ruff/issues/9013.
## Summary
This PR updates the `ANN201`, `ANN202`, `ANN205`, and `ANN206` rules to
not create a fix for the return type when it's an abstract method and
the function body is empty i.e., it only contains either a pass
statement, docstring or an ellipsis literal.
fixes: #9004
## Test Plan
Add the following test cases:
- Abstract method with pass statement
- Abstract method with docstring
- Abstract method with ellipsis literal
- Abstract method with possible return type
(This is not possible to actually use until
https://github.com/astral-sh/ruff/pull/8854 is merged.)
ruff_python_formatter: add reStructuredText docstring formatting support
This commit makes use of the refactoring done in prior commits to slot
in reStructuredText support. Essentially, we add a new type of code
example and look for *both* literal blocks and code block directives.
Literal blocks are treated as Python by default because it seems to be a
[common
practice](https://github.com/adamchainz/blacken-docs/issues/195).
That is, literal blocks like this:
```
def example():
"""
Here's an example::
foo( 1 )
All done.
"""
pass
```
Will get reformatted. And code blocks (via reStructuredText directives)
will also get reformatted:
```
def example():
"""
Here's an example:
.. code-block:: python
foo( 1 )
All done.
"""
pass
```
When looking for a code block, it is possible for it to become invalid.
In which case, we back out of looking for a code example and print the
lines out as they are. As with doctest formatting, if reformatting the
code would result in invalid Python or if the code collected from the
block is invalid, then formatting is also skipped.
A number of tests have been added to check both the formatting and
resetting behavior. Mixed indentation is also tested a fair bit, since
one of my initial attempts at dealing with mixed indentation ended up
not working.
I recommend working through this PR commit-by-commit. There is in
particular a somewhat gnarly refactoring before reST support is added.
Closes#8859
This PR renames the semantic model flag `LITERAL` to `TYPING_LITERAL` to
better reflect its purpose. The main motivation behind this change is to
avoid any confusion with the "literal" terminology used in the AST for
literal nodes like string, bytes, numbers, etc.
## Summary
We should avoid inlining the ellipsis in:
```python
def h():
...
# bye
```
Just as we omit the ellipsis in:
```python
def h():
# bye
...
```
Closes https://github.com/astral-sh/ruff/issues/8905.
## Summary
If a string has a Unicode prefix, we can't add the `r` prefix on top of
that -- we need to remove and replace it. (The Unicode prefix is
redundant anyway in Python 3.)
Closes https://github.com/astral-sh/ruff/issues/8967.
## Summary
Check PEP 695 type alias definitions for `snake-case-type-alias`
(`PYI042`) and `t-suffixed-type-alias` (`PYI043`)
Related to #8771.
## Test Plan
`cargo test`
## Summary
For `t-suffixed-type-alias` to trigger, the type alias needs to be
marked as such using the `typing.TypeAlias` annotation and the name of
the alias must be marked as private using a leading underscore. The
documentation example was of an unannotated type alias that was not
marked as private, which was misleading.
## Test Plan
The current example doesn't trigger the rule; the example in this merge
request does.
In the source of working on #8859, I made a number of smallish refactors
to how code snippet formatting works. Most or all of these were
motivated by writing in support for reStructuredText blocks. They have
some fundamentally different requirements than doctests, and there are a
lot more ways for reStructuredText blocks to become invalid.
(Commit-by-commit review is recommended as the commit messages provide
further context on each change. I split this off from ongoing work to
make review more manageable.)
## Summary
- Adds `add_argument` similar to existing `remove_argument` utility to
safely add arguments to functions.
- Adds autofix for `PLW1514` as per specs requested in
https://github.com/astral-sh/ruff/issues/8883 as a test
## Test Plan
Checks on existing fixtures as well as additional test and fixture for
Python 3.9 and lower fix
## Issue Link
Closes: https://github.com/astral-sh/ruff/issues/8883
## Summary
Adds detection for branches without a `return` or `raise`, so that we
can properly `Optional` the return types. I'd like to remove this and
replace it with our code graph analysis from the `unreachable.rs` rule,
but it at least fixes the worst offenders.
Closes#8942.
## Summary
Triggers `no-return-argument-annotation-in-stub` (`PYI050`) for vararg
and kwarg `NoReturn` type annotations.
Related to #8771.
## Test Plan
`cargo test`
## Summary
When a function uses `@functools.singledispatch`, we need to treat the
first argument of any implementations as runtime-required.
Closes https://github.com/astral-sh/ruff/issues/6849.
## Summary
This PR fixes the bug where the autofix for `TRIO115` was taking the
entire arguments range for the fix which included the parenthesis as
well. This means that the fix would remove the arguments and the
parenthesis. The fix is to use the correct range.
fixes: #8713
## Test Plan
Update existing snapshots :)
## Summary
Part 2 of implementing the reverted autofix for `PYI030`
Also handles `typing.Union` and `typing_extensions.Literal` etc, uses
the first subscript name it finds for each offensive line.
## Test Plan
<!-- How was it tested? -->
`cargo test` and manually
---------
Co-authored-by: Zanie Blue <contact@zanie.dev>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Our `SoftKeywordTokenizer` only respected soft keywords in compound
statement positions -- for example, at the start of a logical line:
```python
type X = int
```
However, type aliases can also appear in simple statement positions,
like:
```python
class Class: type X = int
```
(Note that `match` and `case` are _not_ valid keywords in such
positions.)
This PR upgrades the tokenizer to track both kinds of valid positions.
Closes https://github.com/astral-sh/ruff/issues/8900.
Closes https://github.com/astral-sh/ruff/issues/8899.
## Test Plan
`cargo test`
## Summary
These rewrites are only (potentially) unsafe on Python versions that
predate their introduction into the standard library and grammar, so it
seems correct to mark them as safe on those later versions.
## Summary
Allows assignments of the form, e.g., `Attachment =
apps.get_model("zerver", "Attachment")`, for better compatibility with
Django.
Closes https://github.com/astral-sh/ruff/issues/7675.
## Test Plan
`cargo test`
## Summary
Given `with (a := b): pass`, we truncate the `WithItem` range by one on
both sides such that the parentheses are part of the statement, rather
than the item. However, for `with (a := b) as x: pass`, we want to avoid
this trick.
Closes https://github.com/astral-sh/ruff/issues/8913.
## Summary
This PR updates the `E402` rule to work at cell level for Jupyter
notebooks. This is enabled only in preview to gather feedback.
The implementation basically resets the import boundary flag on the
semantic model when we encounter the first statement in a cell.
Another potential solution is to introduce `E403` rule that is
specifically for notebooks that works at cell level while `E402` will be
disabled for notebooks.
## Test Plan
Add a notebook with imports in multiple cells and verify that the rule
works as expected.
resolves: #8669
## Summary
Given `Union[Dict, None]` (in our internal representation), we were
filtering out `Dict` since we treat it as un-representable (i.e., we
can't convert it to an expression), returning just `None` as the type
annotation. We should require that all members of the union are
representable.
Closes https://github.com/astral-sh/ruff/issues/8879.
## Summary
This PR fixes the bug in the lexer where the `Mode::Ipython` wasn't
being considered when initializing the soft keyword transformer which
wraps the lexer. This means that if the source code starts with either
`match` or `type` keyword, then the keywords were being considered as
name tokens instead. For example,
```python
match foo:
case bar:
pass
```
This would transform the `match` keyword into an identifier if the mode
is `Ipython`.
The fix is to reverse the condition in the soft keyword initializer so
that any new modes are by default considered as the lexer being at start
of line.
## Test Plan
Add a new test case for `Mode::Ipython` and verify the snapshot.
fixes: #8870
This PR removes several uses of `unsafe`. I generally limited myself to
low hanging fruit that I could see. There are still a few remaining uses
of `unsafe` that looked a bit more difficult to remove (if possible at
all). But this gets rid of a good chunk of them.
I put each `unsafe` removal into its own commit with a justification for
why I did it. So I would encourage reviewing this PR commit-by-commit.
That way, we can legislate them independently. It's no problem to drop a
commit if we feel the `unsafe` should stay in that case.
## Summary
Closes#1567.
Add both `length-sort` and `length-sort-straight` settings for isort.
Here are a few notable points:
- The length is determined using the
[`unicode_width`](https://crates.io/crates/unicode-width) crate, i.e. we
are talking about displayed length (this is explicitly mentioned in the
description of the setting)
- The dots are taken into account in the length to be compatible with
the original isort
- I had to reorder a few fields of the module key struct for it all to
make sense (notably the `force_to_top` field is now the first one)
## Test Plan
I added tests for the following cases:
- Basic tests for length-sort with ASCII characters only
- Tests with non-ASCII characters
- Tests with relative imports
- Tests for length-sort-straight
This turns `string` into a parent module with a `docstring` sub-module.
I arranged things this way because there are parts of the `string`
module that the `docstring` module wants to know about (such as a
`NormalizedString`). The alternative I think would be to make
`docstring` a sibling module and expose more of `string`'s internals.
I think I overall like this change because it gives docstring handling a
bit more room to breath. It has grown quite a bit with the addition of
code snippet formatting.
[This was suggested by
@charliermarsh.](https://github.com/astral-sh/ruff/pull/8811#discussion_r1401169531)
## Summary
This PR adds opt-in support for formatting doctests in docstrings. This
reflects initial support and it is intended to add support for Markdown
and reStructuredText Python code blocks in the future. But I believe
this PR lays the groundwork, and future additions for Markdown and reST
should be less costly to add.
It's strongly recommended to review this PR commit-by-commit. The last
few commits in particular implement the bulk of the work here and
represent the denser portions.
Some things worth mentioning:
* The formatter is itself not perfect, and it is possible for it to
produce invalid Python code. Because of this, reformatted code snippets
are checked for Python validity. If they aren't valid, then we
(unfortunately silently) bail on formatting that code snippet.
* There are a couple places where it would be nice to at least warn the
user that doctest formatting failed, but it wasn't clear to me what the
best way to do that is.
* I haven't yet run this in anger on a real world code base. I think
that should happen before merging.
Closes#7146
## Test Plan
* [x] Pass the local test suite.
* [x] Scrutinize ecosystem changes.
* [x] Run this formatter on extant code and scrutinize the results.
(e.g., CPython, numpy.)
A follow-up to auto-generate the `FormatNodeRule` implementation for the
string part nodes. This is just a dummy implementation that is
unreachable because it's handled by the parent nodes.
## Summary
This PR is a follow-up to the AST refactor which does the following:
- Remove `Deref` implementation on `StringLiteralValue` and use explicit
`as_str` calls instead. The `Deref` implementation would implicitly
perform allocations in case of implicitly concatenated strings. This is
to make sure the allocation is explicit.
- Now, certain methods can be implemented to do zero allocations which
have been implemented in this PR. They are:
- `is_empty`
- `len`
- `chars`
- Custom `PartialEq` implementation to compare each character
## Test Plan
Run the linter test suite and make sure all tests pass.
## Summary
This PR updates the string nodes (`ExprStringLiteral`,
`ExprBytesLiteral`, and `ExprFString`) to account for implicit string
concatenation.
### Motivation
In Python, implicit string concatenation are joined while parsing
because the interpreter doesn't require the information for each part.
While that's feasible for an interpreter, it falls short for a static
analysis tool where having such information is more useful. Currently,
various parts of the code uses the lexer to get the individual string
parts.
One of the main challenge this solves is that of string formatting.
Currently, the formatter relies on the lexer to get the individual
string parts, and formats them including the comments accordingly. But,
with PEP 701, f-string can also contain comments. Without this change,
it becomes very difficult to add support for f-string formatting.
### Implementation
The initial proposal was made in this discussion:
https://github.com/astral-sh/ruff/discussions/6183#discussioncomment-6591993.
There were various AST designs which were explored for this task which
are available in the linked internal document[^1].
The selected variant was the one where the nodes were kept as it is
except that the `implicit_concatenated` field was removed and instead a
new struct was added to the `Expr*` struct. This would be a private
struct would contain the actual implementation of how the AST is
designed for both single and implicitly concatenated strings.
This implementation is achieved through an enum with two variants:
`Single` and `Concatenated` to avoid allocating a vector even for single
strings. There are various public methods available on the value struct
to query certain information regarding the node.
The nodes are structured in the following way:
```
ExprStringLiteral - "foo" "bar"
|- StringLiteral - "foo"
|- StringLiteral - "bar"
ExprBytesLiteral - b"foo" b"bar"
|- BytesLiteral - b"foo"
|- BytesLiteral - b"bar"
ExprFString - "foo" f"bar {x}"
|- FStringPart::Literal - "foo"
|- FStringPart::FString - f"bar {x}"
|- StringLiteral - "bar "
|- FormattedValue - "x"
```
[^1]: Internal document:
https://www.notion.so/astral-sh/Implicit-String-Concatenation-e036345dc48943f89e416c087bf6f6d9?pvs=4
#### Visitor
The way the nodes are structured is that the entire string, including
all the parts that are implicitly concatenation, is a single node
containing individual nodes for the parts. The previous section has a
representation of that tree for all the string nodes. This means that
new visitor methods are added to visit the individual parts of string,
bytes, and f-strings for `Visitor`, `PreorderVisitor`, and
`Transformer`.
## Test Plan
- `cargo insta test --workspace --all-features --unreferenced reject`
- Verify that the ecosystem results are unchanged
## Summary
This PR updates the `E703` rule to avoid flagging any semicolons if
they're present after the last expression in a notebook cell. These are
intended to hide the cell output.
Part of #8669
## Test Plan
Add test notebook and update the snapshots.
## Summary
This PR updates `B015` and `B018` to ignore last top-level expressions
in each cell of a Jupyter Notebook.
Part of #8669
## Test Plan
Add test cases for both rules and update the snapshots.
## Summary
This refactors the `ruff_cli` integration tests to create a new
`RuffCheck` struct -- this holds options to configure the "common case"
flags that we want to pass to Ruff (e.g. `--no-cache`, `--isolated`,
etc). This helps reduce the boilerplate and (IMO) makes it more obvious
what the core logic of each test is by keeping only the "interesting"
parameters.
## Test Plan
`cargo test`
closes#8732
I noticed that the reference to the setting in the rule docs doesn't
work, but there seem to be something wrong with pylint settings in
general in the docs - the "For related settings, see ...." is also
missing there.
# Summary
This setting behaves similarly to the ``from_first`` setting in isort
upstream, and sorts "from X import Y" type imports before straight
imports.
Like the other PR I added, happy to refactor if this is better in
another form.
Fixes#8662
# Test plan
I've added a unit test, and ran this on a large codebase that relies on
this setting in isort to verify it doesn't have unexpected side effects.
Closes https://github.com/astral-sh/ruff/issues/7347Closes#3970 via use of `include`
We could update examples in our documentation, but I worry since we do
not have versioned documentation users on older versions would be
confused. Instead, I'll open an issue to track updating use of `ruff
check .` in the documentation sometime in the future.
Semantically it makes sense to put certain contextmanagers into separate
with statements. Currently asyncio.timeout and its relatives in anyio
and trio are exempt from SIM117.
Closes https://github.com/astral-sh/ruff/issues/8606
## Summary
Exempt asyncio.timeout and related functions from SIM117 (Collapse with
statements where possible).
See https://github.com/astral-sh/ruff/issues/8606 for more.
## Test Plan
Extended the insta tests.
## Summary
Fixes#8750. `import __main__` is now considered a first-party import,
and is grouped accordingly by the linter and formatter.
## Test Plan
Added a test based off code supplied in the linked issue.
## Summary
In 2.0, Pydantic has moved the `BaseSettings` class to a separate
package called `pydantic-settings`
(https://docs.pydantic.dev/2.4/migration/#basesettings-has-moved-to-pydantic-settings),
which results in a false positive on `RUF012` (`mutable-class-default`).
A simple fix for that would be adding `pydantic_settings.BaseSettings`
base to the `has_default_copy_semantics` helper, which I've done in this
PR.
Related issue: #5308
## Test Plan
`cargo test`
Bumps [js-sys](https://github.com/rustwasm/wasm-bindgen) from 0.3.64 to
0.3.65.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/rustwasm/wasm-bindgen/commits">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
## Summary
It turns out that some type checkers rely on the presence of ellipses in
`Protocol` interfaces and abstract methods, in order to differentiate
between default implementations and stubs. This PR modifies the preview
behavior of `PIE790` to avoid flagging "unnecessary" ellipses in such
cases.
Closes https://github.com/astral-sh/ruff/issues/8756.
## Test Plan
`cargo test`
If you define a subclass of `pydantic.BaseModel`, and then a subclass of
_that_ class in the same file, we'll now correctly treat it as
runtime-evaluated.
Closes https://github.com/astral-sh/ruff/issues/7893.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Adds the Pylint rule E1132 to check for repeated keyword arguments in a
function call.
## Test Plan
Tested via the included unit tests and manual spot checking.
## Summary
Ensures that we can catch cases like:
```python
ages = {"Tom": 23, "Maria": 23, "Dog": 11}
age = ages.get("Cat", None)
```
Previously, the rule was somewhat useless, as it only checked for
literal accesses.
Closes https://github.com/astral-sh/ruff/issues/8760.
Fix an instability where await was followed by a breaking fluent style
expression:
```python
test_data = await (
Stream.from_async(async_data)
.flat_map_async()
.map()
.filter_async(is_valid_data)
.to_list()
)
```
Note that this technically a minor style change (see ecosystem check)
Closes https://github.com/astral-sh/ruff/issues/8695
We track the smallest offset seen for overindented lines then only
reduce the indentation of the lines that far to preserve indentation in
other lines. This rule's behavior now matches our formatter, which is
nice.
We may want to gate this with preview.
## Summary
When running ruff in verbose mode with `-v`, the first debug logs show
where the config settings are taken from. For example:
```
❯ ruff check ./some_file.py -v
[2023-11-17][00:16:25][ruff_cli::resolve][DEBUG] Using pyproject.toml (parent) at /Users/vince/demo/ruff.toml
```
This threw me off for a second because I knew I had no python project
there, and therefore no `pyproject.toml` file. Then I realised it was
actually reading a `ruff.toml` file (obvious when you read the whole
print I suppose) and that the pyproject.toml is a hardcoded string in
the debug log.
I think it would be nice to tweak the wording slightly so it is clear
that the settings don't neccessarily have to come from a
`pyproject.toml` file.
We ended up with a syntax error here via `from trio import
lowlevel.checkpoint`. The new solution avoids that error, but does miss
cases like:
```py
from trio.lowlevel import Timer
```
Where it could insert `from trio.lowlevel import Timer, checkpoint`.
Instead, it'll add `from trio import lowlevel`.
See:
https://github.com/astral-sh/ruff/issues/8402#issuecomment-1810838129
Update to [Rust
1.74](https://blog.rust-lang.org/2023/11/16/Rust-1.74.0.html) and use
the new clippy lints table.
The update itself introduced a new clippy lint about superfluous hashes
in raw strings, which got removed.
I moved our lint config from `rustflags` to the newly stabilized
[workspace.lints](https://doc.rust-lang.org/stable/cargo/reference/workspaces.html#the-lints-table).
One consequence is that we have to `unsafe_code = "warn"` instead of
"forbid" because the latter now actually bans unsafe code:
```
error[E0453]: allow(unsafe_code) incompatible with previous forbid
--> crates/ruff_source_file/src/newlines.rs:62:17
|
62 | #[allow(unsafe_code)]
| ^^^^^^^^^^^ overruled by previous forbid
|
= note: `forbid` lint level was set on command line
```
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
I think it's reasonable to avoid raising `INP001` for scripts, and
shebangs are one sufficient way to detect scripts.
Closes https://github.com/astral-sh/ruff/issues/8690.
I checked for ipython-specific builtins on python 3.11 using
```python
import json
from subprocess import check_output
builtins_python = json.loads(check_output(["python3", "-c" "import json; print(json.dumps(dir(__builtins__)))"]))
builtins_ipython = json.loads(check_output(["ipython3", "-c" "import json; print(json.dumps(dir(__builtins__)))"]))
print(sorted(set(builtins_ipython) - set(builtins_python)))
```
and updated the relevant constant and match. The list changes from
`display`
to
`__IPYTHON__`, `display`, `get_ipython`.
Followup to #8707
## Summary
This exists to power a test, but it ends up affecting the behavior of
all files in the directory. Namely, it means that these files _aren't_
excluded when you format or lint them directly, since in that case, Ruff
will fall back to looking at the `pyproject.toml` in
`crates/ruff_linter/resources/test/fixtures`, which _doesn't_ exclude
these files, unlike our top-level `pyproject.toml`.
## Summary
We already support inserting imports for `I002` -- this PR just adds the
same fix for `FA102`, which is explicitly about `from __future__ import
annotations`.
Closes https://github.com/astral-sh/ruff/issues/8682.
## Summary
It seems like the range of an `ExprStringLiteral` can be somewhat
unreliable when the string is part of an implicit concatenation with an
f-string. Using the tokens themselves is more reliable.
Closes#8680.
Closes https://github.com/astral-sh/ruff/issues/7784.
## Summary
`display` is a special-cased builtin in IPython. This PR adds it to the
builtin namespace when analyzing IPython notebooks.
Closes https://github.com/astral-sh/ruff/issues/8702.
## Summary
This adds an autofix for PIE800 (unnecessary spread) -- whenever we see
a `**{...}` inside another dictionary literal, just delete the `**{` and
`}` to inline the key-value pairs. So `{"a": "b", **{"c": "d"}}` becomes
just `{"a": "b", "c": "d"}`.
I have enabled this just for preview mode.
## Test Plan
Updated the preview snapshot test.
## Summary
Implements
[FURB136](https://github.com/dosisod/refurb/blob/master/docs/checks.md#furb136-use-min-max)
that checks for `if` expressions that can be replaced with `min()` or
`max()` calls. See issue #1348 for more information.
This implementation diverges from Refurb's original implementation by
retaining the order of equal values. For example, Refurb suggest that
the following expressions:
```python
highest_score1 = score1 if score1 > score2 else score2
highest_score2 = score1 if score1 >= score2 else score2
```
should be to rewritten as:
```python
highest_score1 = max(score1, score2)
highest_score2 = max(score1, score2)
```
whereas this implementation provides more correct alternatives:
```python
highest_score1 = max(score2, score1)
highest_score2 = max(score1, score2)
```
## Test Plan
Unit test checks all eight possibilities.
Testing the compatibility with the future stable black style, i realized
the `ruff_python_formatter` dev main was lacking the
`--skip-magic-trailing-comma` option. This does not affect `ruff
format`.
Usage:
```shell
cargo run --bin ruff_python_formatter -p ruff_python_formatter -- --skip-magic-trailing-comma --emit stdout scratch.py
```
## Summary
This adds a ``no-sections`` option for isort in the linter, similar to
the ``no_sections`` option that exists in upstream isort
(https://pycqa.github.io/isort/docs/configuration/options.html#no-sections)
This option puts all imports except for ``__future__`` into the same
section, and is mostly used by monorepos.
I've taken a bit of a leap in assuming that ruff wants to support the
exact same option; more than happy to refactor if you'd prefer a
different way of setting this up.
Fixes#8653
## Test Plan
I've added a test and have run it on a large Python codebase that uses
isort with --no-sections. The option is disabled by default.
While fixing #8661 I noticed that the code structure for sorting imports
could be simplified.
## Summary
- Move the logic for `force_sort_within_sections` from `isort/mod.rs` to
`isort/ordering.rs` => now there is just one line in `isort/mod.rs`:
`let imports = order_imports(import_block, settings);` which yields the
sorted imports
- Change the function signature of `order_imports` to directly return a
`Vec<EitherImport<'a>>` => no need for `OrderedImportBlock`
I think this is a bit of an improvement because the code is simpler and
there should be a bit of a speedup when setting
`force-sort-within-sections` to true. Indeed, when it's set to true
we're now directly ordering all the imports, whereas before we would
first order the straight imports, then the from imports, combine them
and finally sort the combination a second time (this is probably not
noticeable in practice though).
## Test Plan
No tests added, this is a simple refactor.
For the `PLW0129` rule, the f-string case shouldn't match against bytes
literal as f-strings cannot contain them. F-strings are made up of
either string literals or formatted expressions.
## Summary
This PR adds (unsafe) fixes to the flake8-annotations rules that enforce
missing return types, offering to automatically insert type annotations
for functions with literal return values. The logic is smart enough to
generate simplified unions (e.g., `float` instead of `int | float`) and
deal with implicit returns (`return` without a value).
Closes https://github.com/astral-sh/ruff/issues/1640 (though we could
open a separate issue for referring parameter types).
Closes https://github.com/astral-sh/ruff/issues/8213.
## Test Plan
`cargo test`
Fixes#8661
## Summary
Imports like `from x import y` don't have an "asname" for the module, so
they were placed before imports like `import x as w` since `None` <
`Some(s)` for any string s.
The fix is to first sort by `first_alias`, since it's `None` for `import
x as w`, and then by `asname`.
## Test Plan
I included the example from the issue to avoid future regressions.
When using the autofixer for `Q000` it does not remove the backslashes
from quotes that no longer need escaping.
This new rule checks for such backslashes (regardless whether they come
from the autofixer or not) and can remove them.
fixes#8617
## Summary
This PR extends `unnecessary-pass` (`PIE790`) to flag unnecessary
ellipsis expressions in addition to `pass` statements. A `pass` is
equivalent to a standalone `...`, so it feels correct to me that a
single rule should cover both cases.
When we look to v0.2.0, we should also consider deprecating `PYI013`,
which flags ellipses only for classes.
Closes https://github.com/astral-sh/ruff/issues/8602.
## Summary
PIE807 will rewrite `lambda: []` to `list` -- AFAICT though, the same
rationale also applies to dicts, so I've modified the code to also
rewrite `lambda: {}` to `dict`.
Two things I'm not sure about:
* Should this go to a new rule? This no longer actually matches the
behavior of flake8-pie, and while I think thematically it makes sense to
be part of the same rule, we could make it a standalone rule (but if so,
where should I put it and what error code should I use)?
* If we want a single rule, are there backwards compatibility concerns
with the rule name change (from `reimplemented_list_builtin` to
`reimplemented_container_builtin`?
## Test Plan
Added snapshot tests of the functionality.
## Summary
This PR implements validation in the formatter tests to ensure that we
don't modify the AST during formatting. Black has similar logic.
In implementing this, I learned that Black actually _does_ modify the
AST, and their test infrastructure normalizes the AST to wipe away those
differences. Specifically, Black changes the indentation of docstrings,
which _does_ modify the AST; and it also inserts parentheses in `del`
statements, which changes the AST too.
Ruff also does both these things, so we _also_ implement the same
normalization using a new visitor that allows for modifying the AST.
Closes https://github.com/astral-sh/ruff/issues/8184.
## Test Plan
`cargo test`
## Summary
This PR makes `whitespace-before-punctuation` (`E203`) compatible with
the formatter by relaxing the rule a bit, as compared to the pycodestyle
implementation. It's also more consistent with PEP 8, which says:
> However, in a slice the colon acts like a binary operator, and should
have equal amounts on either side (treating it as the operator with the
lowest priority).
Closes https://github.com/astral-sh/ruff/issues/7259.
Closes https://github.com/astral-sh/ruff/issues/8642.
## Test Plan
`cargo test`
It seems as though using `include!(...)` to avoid the source code copy
breaks rust-analzer. Namely, it treats the included file as unlinked,
and so any part of analysis (e.g., goto-definition) that needs that file
to reason about the code ends up failing.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
Previously, this rule used the range of the `self` annotation, but it's
a lot more natural to use the range of the function name (since it also
means the `# noqa` is associated with the method rather than its first
argument).
Closes https://github.com/astral-sh/ruff/issues/8635.
## Summary
- Close#7487
In the spirit of `flake8-boolean-trap`, any positional argument that can
accept a boolean should raise `FBT001`.
Raise `FBT001` for all annotations that accept booleans (e.g.
`Optional[bool]`, `Union[int, bool]`).
## Test Plan
Add a fixture, with an annotation using `|`, `Optional`, and `Union`,
and containing a boolean.
## Summary
Removes unnecessary commentary from the PD901 message. This does make it
different from pandas-vet, but it improves consistency with the rest of
messages.
Current Message:
> `df` is a bad variable name. Be kinder to your future self.
New Message
> `df` is a bad variable name.
## Test Plan
The relevant snapshot has been updated with the new message.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
I got an error from RUF001 and wanted to override it. How to do that was
not quite obvious. In the process I have tried to improve the
documentation for the rule and it's siblings.
## Summary
Adds an extra check to F632 to check for any `is` comparisons to a
mutable initialisers.
Implements #8589 .
Example:
```Python
named_var = {}
if named_var is {}: # F632 (fix)
pass
```
The if condition will always evaluate to False because it checks on
identity and it's impossible to take the same identity as a hard coded
list/set/dict initializer.
## Test Plan
Multiple test cases were added to ensure the rule works + doesn't flag
false positives + the fix works correctly.
## Summary
This fixes#2606 by moving where we apply the convention ignores --
instead of applying that at the very end, e track, we now track which
rules have been specifically enabled (via `Specificity::Rule`). If they
have, then we do *not* apply the docstring overrides at the end.
## Test Plan
Added unit tests to `ruff_workspace` and an integration test to
`ruff_cli`
## Summary
This PR updates the formatter to preserve trailing semicolon for Jupyter
Notebooks.
The motivation behind the change is that semicolons in notebooks are
typically used to hide the output, for example when plotting. This is
highlighted in the linked issue.
The conditions required as to when the trailing semicolon should be
preserved are:
1. It should be a top-level statement which is last in the module.
2. For statement, it can be either assignment, annotated assignment, or
augmented assignment. Here, the target should only be a single
identifier i.e., multiple assignments or tuple unpacking isn't
considered.
3. For expression, it can be any.
## Test Plan
Add a new integration test in `ruff_cli`. The test notebook basically
acts as a document as to which trailing semicolons are to be preserved.
fixes: #8254
Previously, this lint had its alias detection logic a little
backwards. That is, for Python 3.11+, it would *only* detect
asyncio.TimeoutError as an alias, but it should have also detected
socket.timeout as an alias. And in Python <3.11, it would falsely
detect asyncio.TimeoutError as an alias where it should have only
detected socket.timeout as an alias.
We fix it so that both asyncio.TimeoutError and socket.timeout are
detected as aliases in Python 3.11+, and only socket.timeout is
detected as an alias in Python 3.10.
Fixes#8565
## Test Plan
I tested this by updating the existing snapshot test which had
erroneously
asserted that socket.timeout should not be replaced with TimeoutError in
Python
3.11+. I also added a new regression test that targets Python 3.10 and
ensures
that the suggestion to replace asyncio.TimeoutError with TimeoutError
does not
occur.
## Summary
This fixes the bug where the `flake8-commas` rules weren't taking the
new f-string tokens into account.
## Test Plan
Add new test cases around f-strings for all of `flake8-commas`'s rules.
fixes: #8556
## Summary
When you run Ruff via stdin, and pass `format` or `check --fix`, we
typically write the changed or unchanged contents to stdout. It turns
out we forgot to do this when the file is _excluded_, so if you run
`ruff format /path/to/excluded/file.py`, we don't write _anything_ to
`stdout`. This led to a bug in the LSP whereby we deleted file contents
for third-party files.
The right thing to do here is write back the unchanged contents, as it
should always be safe to write the output of stdout back to a file.
## Summary
An assignment can be _both_ (e.g.) a loop variable _and_ assigned via
unpacking. In other words, unpacking is a quality of an assignment, not
a _kind_.
## Summary
This brings ruff's behavior in line with what `pep8-naming` already does
and thus closes#8397.
I had initially implemented this to look at the last segment of a dotted
path only when the entry in the `*-decorators` setting started with a
`.`, but in the end I thought it's better to remain consistent w/
`pep8-naming` and doing a match against the last segment of the
decorator name in any case.
If you prefer to diverge from this in favor of less ambiguity in the
configuration let me know and I'll change it so you would need to put
e.g. `.expression` in the `classmethod-decorators` list.
## Test Plan
Tested against the file in the issue linked below, plus the new testcase
added in this PR.
~Improves detection of types imported from `typing_extensions`. Removes
the hard-coded list of supported types in `typing_extensions`; instead
assuming all types could be imported from `typing`, `_typeshed`, or
`typing_extensions`.~
~The typing extensions package appears to re-export types even if they
do not need modification.~
Adds detection of `if typing_extensions.TYPE_CHECKING` blocks. Avoids
inserting a new `if TYPE_CHECKING` block and `from typing import
TYPE_CHECKING` if `typing_extensions.TYPE_CHECKING` is used (closes
https://github.com/astral-sh/ruff/issues/8427)
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR fixes the bug where the generated fix for `EM*` rules would
replace a
triple-quoted (f-)string with a single-quoted (f-)string. This changes
the
semantic of the string in case it contains a single-quoted string
literal. This
is especially evident with f-strings where the expression could contain
another
string within it. For example,
```python
f"""normal {"another"} normal"""
```
## Test Plan
Add test case for triple-quoted string and update the snapshots.
fixes: #6988fixes: #7736
This ensures the python label is used for all python code blocks for
consistency.
## Test Plan
Visual inspection of all changes via git client ensuring no other
changes were made in error.
## Summary
This PR addresses the incompatibility with `jupyterlab-lsp` +
`python-lsp-ruff` arising from the inference of source type from file
extension, raised in #6847.
In particular it follows the suggestion in
https://github.com/astral-sh/ruff/issues/6847#issuecomment-1765724679 to
specify a mapping from file extension to source type.
The source types are
- python
- pyi
- ipynb
Usage:
```sh
ruff check --no-cache --stdin-filename Untitled.ipynb --extension ipynb:python
```
Unlike the original suggestion, `:` instead of `=` is used to associate
file extensions to language since that is what is used with
`--per-file-ignores` which is an existing option that accepts a mapping.
## Test Plan
2 tests added to `integration_test.rs` to ensure the override works as
expected
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Prior to this change `extend_unsafe_fixes` took precedence over
`extend_safe_fixes` selectors, so any conflicts were resolved in favour
of `extend_unsafe_fixes`. Thanks to that ruff were conservatively
assuming that if configs conlict the fix corresponding to selected rule
will be treated as unsafe.
After this change we take into account Specificity of the selectors. For
conflicts between selectors of the same Specificity we will treat the
corresponding fixes as unsafe. But if the conflicting selectors are of
different specificity the more specific one will win.
## Test Plan
Tests were added for the `FixSafetyTable` struct. The
`check_extend_unsafe_fixes_conflict_with_extend_safe_fixes_by_specificity`
integration test was added to test conflicting rules of different
specificity.
Fixes#8404
---------
Co-authored-by: Zanie <contact@zanie.dev>
These names are only ever displayed internally right now and we could be
clearer in our test snapshots.
The diff is kind of scary because all of the tests fixtures are updated.
## Summary
Being able to set `--no-cache` without touching the command line makes
comparing formatter speed with e.g. Hyperfine a lot easier; Black allows
one to set `BLACK_CACHE_DIR=/dev/null`, but setting
`RUFF_CACHE_DIR=/dev/null` has Ruff choke:
```
error: Failed to initialize cache at /dev/null: Not a directory (os error 20)
error: Failed to initialize cache at /dev/null: Not a directory (os error 20)
warning: Failed to open cache file '/dev/null/0.1.4/18160934645386409287': Not a directory (os error 20)
```
Alternately, we could make a `/dev/null` (or `nul` on Windows) cache
directory imply `--no-cache`?
## Test Plan
None yet.
## Summary
This commit adds some additional error checking to the parser such that
assignments that are invalid syntax are rejected. This covers the
obvious cases like `5 = 3` and some not so obvious cases like `x + y =
42`.
This does add an additional recursive call to the parser for the cases
handling assignments. I had initially been concerned about doing this,
but `set_context` is already doing recursion during assignments, so I
didn't feel as though this was changing any fundamental performance
characteristics of the parser. (Also, in practice, I would expect any
such recursion here to be quite shallow since the recursion is done on
the target of an assignment. Such things are rarely nested much in
practice.)
Fixes#6895
## Test Plan
I've added unit tests covering every case that is detected as invalid on
an `Expr`.
## Summary
Fixes bug in `TRIO115` where it would not `return` for values that were
not a `NumberLiteral` so
```python
x = "bla"
trio.sleep(x)
```
would set off a false positive
## Test Plan
Added test case to fixture
## Summary
Given `key in obj.keys()`, `obj` _could_ be a dictionary, or it could be
another type that defines
a `.keys()` method. In the latter case, removing the `.keys()` attribute
could lead to a runtime error.
Previously, we marked all `SIM118` fixes as unsafe for this reason;
however, in preview, we now mark them as safe if we can
infer that the expression is a dictionary.
## Test Plan
Added a preview fixture.
## Summary
We have this pattern in a bunch of places, where we find the _only_
binding to a name (and return `None`) if it's bound multiple times. This
PR DRYs it up into a method on `SemanticModel`.
## Summary
If you want to create an edit with dynamic applicability, you have to
branch and repeat the edit entirely between the two branches. If you
further need the edit itself to be dynamic (e.g., perhaps you have a
single edit in one case, vs. multiple in another), you suddenly have
four branches. This PR just adds an alternate constructor that takes
applicability as an argument, as an escape hatch.
## Summary
Implement
[`no-is-type-none`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/no_is_type_none.py)
as `type-none-comparison` (`FURB169`).
Auto-fixes comparisons that use `type` to compare the type of an object
to `type(None)` to a `None` identity check. For example,
```python
type(foo) is type(None)
```
becomes
```python
foo is None
```
Related to #1348.
## Test Plan
`cargo test`
## Summary
Black and Ruff's preview styles now collapse statements like:
```python
from contextlib import nullcontext
ctx = nullcontext()
with ctx: ...
```
Historically, we made an exception here for classes
(https://github.com/astral-sh/ruff/pull/2837). This PR extends it to
other statement kinds for consistency with the formatter.
Closes https://github.com/astral-sh/ruff/issues/8496.
## Summary
Adds `TRIO105` from the [flake8-trio
plugin](https://github.com/Zac-HD/flake8-trio). The `MethodName` logic
mirrors that of `TRIO100` to stay consistent within the plugin.
It is at 95% parity with the exception of upstream also checking for a
slightly more complex scenario where a call to `start()` on a
`trio.Nursery` context should also be immediately awaited. Upstream
plugin appears to just check for anything named `nursery` judging from
[the relevant issue](https://github.com/Zac-HD/flake8-trio/issues/56).
Unsure if we want to do so something similar or, alternatively, if there
is some capability in ruff to check for calls made on this context some
other way
## Test Plan
Added a new fixture, based on [the one from upstream
plugin](https://github.com/Zac-HD/flake8-trio/blob/main/tests/eval_files/trio105.py)
## Issue link
Refers: https://github.com/astral-sh/ruff/issues/8451
## Summary
This PR fixes a bug in our formatter where a multiline lambda expression
statement was formatted over multiple lines without adding parentheses.
The PR "fixes" the problem by not splitting the lambda parameters if it
is not parenthesized
## Test Plan
Added test
## Summary
Adds `memoryview` to the list of typeclasses that `fn is_type()` uses
for type comparison checks so that it raises a violation if `is`, `is
not` or `isinstance()` are not used.
## Test Plan
Added examples to existing fixture
## Issue Link
Closes: https://github.com/astral-sh/ruff/issues/8483
This is the one refactor in the NumPy 2.0 upgrade rule that isn't
compatible with earlier versions of NumPy, so I'm marking it as unsafe
and adding a dedicated message.
## Summary
Currently, `UP032` applied to raw strings results in format strings with
the prefix 'fr'. This gets changed to 'rf' by Ruff format (or Black). In
order to avoid that, this PR uses the prefix 'rf' to begin with.
## Test Plan
Updated the expectation on an existing test.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Hi! Currently NumPy Python API is undergoing a cleanup process that will
be delivered in NumPy 2.0 (release is planned for the end of the year).
Most changes are rather simple (renaming, removing or moving a member of
the main namespace to a new place), and they could be flagged/fixed by
an additional ruff rule for numpy (e.g. changing occurrences of
`np.float_` to `np.float64`).
Would you accept such rule?
I named it `NPY201` in the existing group, so people will receive a
heads-up for changes arriving in 2.0 before actually migrating to it.
~~This is still a draft PR.~~ I'm not an expert in rust so if any part
of code can be done better please share!
NumPy 2.0 migration guide:
https://numpy.org/devdocs/numpy_2_0_migration_guide.html
NEP 52: https://numpy.org/neps/nep-0052-python-api-cleanup.html
NumPy cleanup tracking issue:
https://github.com/numpy/numpy/issues/23999
## Test Plan
A unit test is provided that checks all rule's fix cases.
## Summary
LangChain is attempting to use Ruff over their Jupyter notebooks
(https://github.com/langchain-ai/langchain/pull/12677/files), but
running into a bunch of syntax errors, the majority of which come from
our inability to recognize automagic.
If you run this in a cell:
```jupyter
pip install requests
```
Jupyter will automatically treat that as:
```jupyter
%pip install requests
```
We need to ignore cells that use these automagics, since the parser
doesn't understand them. (I guess we could support it in the parser, but
that seems much harder?). The good news is that AFAICT Jupyter doesn't
let you mix automagics with code, so by skipping these cells, we don't
miss out on analyzing any Python code.
## Test Plan
1. `cargo test`
2. Ran over LangChain and verified that there are no more errors
relating to `pip install` automagics.
## Summary
This PR removes the `unicode` flag from the string literal in
`ComparableExpr`. This flag isn't required as all strings are unicode in
Python 3 so `"foo" == u"foo"`.
## Summary
We typically avoid enforcing exclusions if a file was passed to Ruff
directly on the CLI. However, we also allow `--force-exclude`, which
ignores excluded files _even_ if they're passed to Ruff directly. This
is really important for pre-commit, which always passes changed files --
we need to exclude files passed by pre-commit if they're in the
`exclude` lists.
Turns out the new `lint.exclude` and `format.exclude` settings weren't
respecting `--force-exclude`.
Closes https://github.com/astral-sh/ruff/issues/8391.
## Summary
By using `set`, we were setting the bracket flag to `false` if another
operator was visited.
Closes https://github.com/astral-sh/ruff/issues/8379.
## Test Plan
`cargo test`
## Summary
This PR adds a new `LiteralExpressionRef` which wraps all of the literal
expression nodes in a single enum. This allows for a narrow type when
working exclusively with a literal node. Additionally, it also
implements a `Expr::as_literal_expr` method to return the new enum if
the expression is indeed a literal one.
A few rules have been updated to account for the new enum:
1. `redundant_literal_union`
2. `if_else_block_instead_of_dict_lookup`
3. `magic_value_comparison`
To account for the change in (2), a new `ComparableLiteral` has been
added which can be constructed from the new enum
(`ComparableLiteral::from(<LiteralExpressionRef>)`).
### Open Questions
1. The new `ComparableLiteral` can be exclusively used via the
`LiteralExpressionRef` enum. Should we remove all of the literal
variants from `ComparableExpr` and instead have a single
`ComparableExpr::Literal(ComparableLiteral)` variant instead?
## Test Plan
`cargo test`
## Summary
We were considering the `{` within an f-string to be a left brace, which
caused the "space-after-colon" rule to trigger incorrectly.
Closes https://github.com/astral-sh/ruff/issues/8299.
## Summary
Uses `warn_user_once!` instead of `warn!` to ensure that every warning
is shown exactly once, regardless of whether there are duplicates in the
list, or warnings that are raised by multiple configuration files.
Closes#8271.
## Summary
If the value of `shell` wasn't literally `True`, we now show a message
describing it as truthy, rather than the (misleading) `shell=True`
literal in the diagnostic.
Closes https://github.com/astral-sh/ruff/issues/8310.
**Summary** Previously, own line comment following after a docstring
followed by newline(s) before the first content statement were treated
as trailing on the docstring and we didn't insert a newline after the
docstring as black would.
Before:
```python
class ModuleBrowser:
"""Browse module classes and functions in IDLE."""
# This class is also the base class for pathbrowser.PathBrowser.
def __init__(self, master, path, *, _htest=False, _utest=False):
pass
```
After:
```python
class ModuleBrowser:
"""Browse module classes and functions in IDLE."""
# This class is also the base class for pathbrowser.PathBrowser.
def __init__(self, master, path, *, _htest=False, _utest=False):
pass
```
I'm not entirely happy about hijacking
`handle_own_line_comment_between_statements`, but i don't know a better
spot to put it.
Fixes#7948
**Test Plan** Fixtures
We previously incorrectly treated byte strings in docstring position as
docstrings because black does so
(https://github.com/astral-sh/ruff/pull/8283#discussion_r1375682931,
https://github.com/psf/black/issues/4002), even CPython doesn't
recognize them:
```console
$ python3.12
Python 3.12.0 (main, Oct 6 2023, 17:57:44) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> def f():
... b""" a"""
...
>>> print(str(f.__doc__))
None
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR adds `Default` for the following literal nodes:
* `StringLiteral`
* `BytesLiteral`
* `BooleanLiteral`
* `NoneLiteral`
* `EllipsisLiteral`
The implementation creates the zero value of the respective literal
nodes in terms of the Python language.
## Test Plan
`cargo test`
## Summary
This PR inlines the formatting logic for `ExprNumberLiteral` and removes
the need of having dedicated `Format*` struct for each number type.
## Test Plan
`cargo test`
## Summary
This PR splits the `Constant` enum as individual literal nodes. It
introduces the following new nodes for each variant:
* `ExprStringLiteral`
* `ExprBytesLiteral`
* `ExprNumberLiteral`
* `ExprBooleanLiteral`
* `ExprNoneLiteral`
* `ExprEllipsisLiteral`
The main motivation behind this refactor is to introduce the new AST
node for implicit string concatenation in the coming PR. The elements of
that node will be either a string literal, bytes literal or a f-string
which can be implemented using an enum. This means that a string or
bytes literal cannot be represented by `Constant::Str` /
`Constant::Bytes` which creates an inconsistency.
This PR avoids that inconsistency by splitting the constant nodes into
it's own literal nodes, literal being the more appropriate naming
convention from a static analysis tool perspective.
This also makes working with literals in the linter and formatter much
more ergonomic like, for example, if one would want to check if this is
a string literal, it can be done easily using
`Expr::is_string_literal_expr` or matching against `Expr::StringLiteral`
as oppose to matching against the `ExprConstant` and enum `Constant`. A
few AST helper methods can be simplified as well which will be done in a
follow-up PR.
This introduces a new `Expr::is_literal_expr` method which is the same
as `Expr::is_constant_expr`. There are also intermediary changes related
to implicit string concatenation which are quiet less. This is done so
as to avoid having a huge PR which this already is.
## Test Plan
1. Verify and update all of the existing snapshots (parser, visitor)
2. Verify that the ecosystem check output remains **unchanged** for both
the linter and formatter
### Formatter ecosystem check
#### `main`
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75803 | 1799 | 1647 |
| django | 0.99983 | 2772 | 34 |
| home-assistant | 0.99953 | 10596 | 186 |
| poetry | 0.99891 | 317 | 17 |
| transformers | 0.99966 | 2657 | 330 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99978 | 3669 | 20 |
| warehouse | 0.99977 | 654 | 13 |
| zulip | 0.99970 | 1459 | 22 |
#### `dhruv/constant-to-literal`
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75803 | 1799 | 1647 |
| django | 0.99983 | 2772 | 34 |
| home-assistant | 0.99953 | 10596 | 186 |
| poetry | 0.99891 | 317 | 17 |
| transformers | 0.99966 | 2657 | 330 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99978 | 3669 | 20 |
| warehouse | 0.99977 | 654 | 13 |
| zulip | 0.99970 | 1459 | 22 |
## Summary
This PR adds a new `Singleton` enum for the `PatternMatchSingleton`
node.
Earlier the node was using the `Constant` enum but the value for this
pattern can only be either `None`, `True` or `False`. With the coming PR
to remove the `Constant`, this node required a new type to fill in.
This also has the benefit of narrowing the type down to only the
possible values for the node as evident by the removal of `unreachable`.
## Test Plan
Update the AST snapshots and run `cargo test`.
## Summary
Refactor for isort implementation. Closes#7738.
I introduced a `NatOrdString` and a `NatOrdStr` type to have a naturally
ordered `String` and `&str`, and I pretty much went back to the original
implementation based on `module_key`, `member_key` and
`sorted_by_cached_key` from itertools. I tried my best to avoid
unnecessary allocations but it may have been clumsy in some places, so
feedback is appreciated! I also renamed the `Prefix` enum to
`MemberType` (and made some related adjustments) because I think this
fits more what it is, and it's closer to the wording found in the isort
documentation.
I think the result is nicer to work with, and it should make
implementing #1567 and the like easier :)
Of course, I am very much open to any and all remarks on what I did!
## Test Plan
I didn't add any test, I am relying on the existing tests since this is
just a refactor.
## Summary
Implements pylint C0415 (import-outside-toplevel) — imports should be at
the top level of a file.
The great debate I had on this implementation is whether "top-level" is
one word or two (`toplevel` or `top_level`). I opted for 2 because that
seemed to be how it is used in the codebase but the rule string itself
uses one-word "toplevel." 🤷 I'd be happy to change it as desired.
I suppose this could be auto-fixed by moving the import to the
top-level, but it seems likely that the author's intent was to actually
import this dynamically, so I view the main point of this rule is to
force some sort of explanation, and auto-fixing might be annoying.
For reference, this is what "pylint" reports:
```
> pylint crates/ruff/resources/test/fixtures/pylint/import_outside_top_level.py
************* Module import_outside_top_level
...
crates/ruff/resources/test/fixtures/pylint/import_outside_top_level.py:4:4: C0415: Import outside toplevel (string) (import-outside-toplevel)
```
ruff would now report:
```
import_outside_top_level.py:4:5: PLC0415 `import` should be used only at the top level of a file
|
3 | def import_outside_top_level():
4 | import string # [import-outside-toplevel]
| ^^^^^^^^^^^^^ PLC0415
|
```
Contributes to https://github.com/astral-sh/ruff/issues/970.
## Test Plan
Snapshot test.
## Summary
If a file has no diagnostics, then we can read and write that
information from and to the cache, even if the fix mode is `--fix` or
`--diff`. (Typically, we can't read or write such results from or to the
cache, because `--fix` and `--diff` have side effects that take place
during diagnostic analysis (writing to disk or outputting the diff).)
This greatly improves performance when running `--fix` on a codebase in
the common case (few diagnostics).
Closes#8311.
Closes https://github.com/astral-sh/ruff/issues/8315.
## Summary
This makes use of memchr and other methods to parse the strings
(hopefully) faster. It might also be worth converting the
`parse_fstring_middle` helper to use similar techniques, but I did not
implement it in this PR.
## Test Plan
This was tested using the existing tests and passed all of them.
## Summary
Implement
[`no-isinstance-type-none`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/no_isinstance_type_none.py)
as `isinstance-type-none` (`FURB168`).
Auto-fixes calls to `isinstance` to check if an object is `None` to a
`None` identity check. For example,
```python
isinstance(foo, type(None))
```
becomes
```python
foo is None
```
Related to #1348.
## Test Plan
`cargo test`
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Remove wrong note on `tool.ruff.format` `exclude` option from
documentation which is referencing `extend-exclude` even if it's not
relevant for the formatter options (`exclude` is additive). See #8301
## Test Plan
N/A (Docs change)
## Summary
Add missing "is":
```diff
- The 🧪 emoji indicates that a rule in "preview".
+ The 🧪 emoji indicates that a rule is in "preview".
```
## Test Plan
N/A
## Summary
Since `--format` was changed to `--output-format` for `check`, it feels
like it makes sense for the same to work for the auxiliary commands.
This
* adds the same deprecation warning that used to be a thing in #7514
(and un-became a thing in #7984)
Fixes#7990.
## Test Plan
* `cargo run --bin=ruff -- rule --all --output-format=json` works
* `cargo run --bin=ruff -- rule --format=json` works with warnings
Change
```python
"""Test docstring"""
a = 1
```
to
```python
"""Test docstring"""
a = 1
```
in preview style, but don't touch the docstring otherwise.
Do we want to ask black to also format the content of module level
docstrings? Seems inconsistent to me that we change function and class
docstring indentation/contents but not module docstrings.
Fixes https://github.com/astral-sh/ruff/issues/7995
## Summary
This PR removes the `debug_assertion` in the `Indexer` to allow
unterminated f-strings. This is mainly a fix in the development build
which now matches the release build.
The fix is simple: remove the `debug_assertion` which means that the
there could be `FStringStart` and possibly `FStringMiddle` tokens
without a corresponding f-string range in the `Indexer`. This means that
the code requesting for the f-string index need to account for the
`None` case, making the code safer.
This also updates the code which queries the `FStringRanges` to account
for the `None` case. This will happen when the `FStringStart` /
`FStringMiddle` tokens are present but the `FStringEnd` token isn't
which means that the `Indexer` won't contain the range for that
f-string.
## Test Plan
`cargo test`
Taking the following code as an example:
```python
f"{123}
```
This only emits a `FStringStart` token, but no `FStringMiddle` or
`FStringEnd` tokens.
And,
```python
f"\.png${
```
This emits a `FStringStart` and `FStringMiddle` token, but no
`FStringEnd` token.
fixes: #8065
## Summary
Explain the meaning of the icon for screen readers (and mouse over).
Hide "inactive" (low opacity) icons from screen readers.
Remove opacity: 1 styling, it's the default opacity.
Without this change a screen reader will just read "Hammer and spanner
test tube" for the last column in each row.
## Summary
Based on [this
feedback](https://github.com/astral-sh/ruff/issues/8185#issuecomment-1780092525).
Avoid warning about `force-wrap-aliases` and `split-on-trailing-comma`
if `force-single-line` is true (which creates a dedicated import for
each imported member).
## Test Plan
Ran `ruff format . --no-cache` and verified that the warning show up
when `force-single-line=false` and aren't shown when
`force-single-line=true`
## Summary
This PR fixes the `W605` rule implementation to provide the quickfix
message as
per the fix provided.
## Test Plan
Update snapshots.
fixes: #8155
## Summary
Avoid warning about incompatible rules except if their configuration
directly conflicts with the formatter. This should reduce the noise and
potentially the need for https://github.com/astral-sh/ruff/issues/8175
and https://github.com/astral-sh/ruff/issues/8185
I also extended the rule and option documentation to mention any
potential formatter incompatibilities or whether they're redundant when
using the formatter.
* `LineTooLong`: This is a use case we explicitly want to support. Don't
warn about it
* `TabIndentation`, `IndentWithSpaces`: Only warn if
`indent-style="tab"`
* `IndentationWithInvalidMultiple`,
`IndentationWithInvalidMultipleComment`: Only warn if `indent-width !=
4`
* `OverIndented`: Don't warn, but mention that the rule is redundant
* `BadQuotesInlineString`: Warn if quote setting is different from
`format.quote-style`
* `BadQuotesMultilineString`, `BadQuotesDocstring`: Warn if `quote !=
"double"`
## Test Plan
I added a new integration test for the default configuration with `ALL`.
`ruff format` now only shows two incompatible rules, which feels more
reasonable.
## Summary
This rule is now unsafe if we can't verify that the `obj` in `raise
obj()` is a class or builtin. (If we verify that it's a function, we
don't raise at all, as before.)
See the documentation change for motivation behind the unsafe edit.
Closes https://github.com/astral-sh/ruff/issues/8228.
**Summary** Prepare for the black preview style becoming the black
stable style at the end of the year.
This adds a new test file to compare stable and preview on some relevant
preview options in black, and makes `format_dev` understand the black
preview flag. I've added poetry as a project that uses preview.
I've implemented one specific deviation (collapsing of stub
implementation in non-stub files) which showed up in poetry for testing.
This also improves poetry compatibility from 0.99891 to 0.99919.
Fixes#7440
New compatibility stats:
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75803 | 1799 | 1647 |
| django | 0.99983 | 2772 | 35 |
| home-assistant | 0.99953 | 10596 | 189 |
| poetry | 0.99919 | 317 | 12 |
| transformers | 0.99963 | 2657 | 332 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99978 | 3669 | 20 |
| warehouse | 0.99969 | 654 | 15 |
| zulip | 0.99970 | 1459 | 22 |
## Summary
This PR refactors the formatter diff code to reuse the
`SourceKind::diff` logic. This has the benefit that the Notebook diff
now includes the cell numbers which was not present before.
## Test Plan
Update the snapshots and verified the cell numbers.
## Summary
Given:
```python
# comment
class A:
def foo(self):
pass
```
We need to insert an additional newline between `# comment` and `class
A`. We were missing this handling for the case in which `# comment` is a
leading comment on `class A`, as opposed to a trailing comment of some
preceding statement.
In practice, I think this only applies to the specific case in which a
class or function is the first statement in a module, and there's a
single empty line between a leading comment and that class or function.
If there are no empty lines, then the comment "sticks" to the
definition; if there are two or more, then `leading_comments` will
truncate appropriately. If the class or function is nested, then we only
need one empty line anyway.
Closes https://github.com/astral-sh/ruff/issues/8215.
## Test Plan
No change in similarity.
Before:
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75803 | 1799 | 1647 |
| django | 0.99983 | 2772 | 34 |
| home-assistant | 0.99953 | 10596 | 186 |
| poetry | 0.99891 | 317 | 17 |
| transformers | 0.99966 | 2657 | 330 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99978 | 3669 | 20 |
| warehouse | 0.99977 | 654 | 13 |
| zulip | 0.99970 | 1459 | 22 |
After:
| project | similarity index | total files | changed files |
|----------------|------------------:|------------------:|------------------:|
| cpython | 0.75803 | 1799 | 1648 |
| django | 0.99983 | 2772 | 34 |
| home-assistant | 0.99953 | 10596 | 186 |
| poetry | 0.99891 | 317 | 17 |
| transformers | 0.99966 | 2657 | 330 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99978 | 3669 | 20 |
| warehouse | 0.99977 | 654 | 13 |
| zulip | 0.99970 | 1459 | 22 |
## Summary
This PR removes the `todo!()` around `IpyEscapeCommand` in the
formatter.
The `NeedsParentheses` trait needs to be implemented which always return
`Never`. The reason being that if an escape command is parenthesized,
then that's not parsed as an escape command. IOW, the parentheses
shouldn't be present around an escape command.
In the similar way, the `CanSkipOptionalParenthesesVisitor` will skip
this node.
## Test Plan
Updated the `unformatted.ipynb` fixture with new cells containing
IPython escape commands and the corresponding snapshot was verified.
Also, tested it out in a few open source repositories containing
notebooks (`openai/openai-cookbook`, `huggingface/notebooks`).
#### New cells in `unformatted.ipynb`
**Cell 2**
```markdown
A markdown cell
```
**Cell 3**
```python
def some_function(foo, bar):
pass
%matplotlib inline
```
**Cell 4**
```python
foo = %pwd
def some_function(foo,bar,):
foo = %pwd
print(foo
)
```
fixes: #8204
## Summary
This PR fixes the bug where if a Notebook contained IPython syntax, then
the format command would fail. This was because the correct mode was not
being used while parsing through the formatter code path.
## Test Plan
This PR isn't the only requirement for Notebook formatting to start
working with IPython escape commands. The following PR in the stack is
required as well.
## Summary
Python 3.12 added the `__buffer__()`/`__release_buffer_()` special
methods, which are incorrectly flagged as invalid dunder methods by
`PLW3201`.
## Test Plan
Added definitions to the test suite, and confirmed they failed without
the fix and are ignored after the fix was done.
## Summary
Related to https://github.com/astral-sh/ruff/issues/8135.
If we're not printing a `--diff`, or a summary of `--check` changes, we
can avoid sorting the list of results. Further, when sorting, we only
need to sort a small subset of the entries, in the common case (i.e., in
general, it's much more likely that a file is formatted than not).
## Test Plan
Local benchmarks suggest a 5-10% speedup on the cached behavior:
```
❯ hyperfine --warmup 3 "./target/release/ruff format ../airflow" "./target/release/sort format ../airflow"
Benchmark 1: ./target/release/ruff format ../airflow
Time (mean ± σ): 70.3 ms ± 5.2 ms [User: 52.1 ms, System: 59.0 ms]
Range (min … max): 68.3 ms … 101.7 ms 42 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet PC without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Benchmark 2: ./target/release/sort format ../airflow
Time (mean ± σ): 66.0 ms ± 1.4 ms [User: 48.3 ms, System: 58.4 ms]
Range (min … max): 64.7 ms … 71.8 ms 44 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet PC without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Summary
'./target/release/sort format ../airflow' ran
1.07 ± 0.08 times faster than './target/release/ruff format ../airflow'
```
## Summary
This PR renames the `tab-size` configuration option to `indent-width` to
express that the formatter uses the option to determine the indentation
width AND as tab width.
I first preferred naming the option `tab-width` but then decided to go
with `indent-width` because:
* It aligns with the `indent-style` option
* It would allow us to write a lint rule that asserts that each
indentation uses `indent-width` spaces.
Closes#7643
## Test Plan
Added integration test
## Summary
This PR introduces a new `pycodestyl.max-line-length` option that allows overriding the global `line-length` option for `E501` only.
This is useful when using the formatter and `E501` together, where the formatter uses a lower limit and `E501` is only used to catch extra-long lines.
Closes#7644
## Considerations
~~Our fix infrastructure asserts in some places that the fix doesn't exceed the configured `line-width`. With this change, the question is whether it should use the `pycodestyle.max-line-width` or `line-width` option to make that decision.
I opted for the global `line-width` for now, considering that it should be the lower limit. However, this constraint isn't enforced and users not using the formatter may only specify `pycodestyle.max-line-width` because they're unaware of the global option (and it solves their need).~~
~~I'm interested to hear your thoughts on whether we should use `pycodestyle.max-line-width` or `line-width` to decide on whether to emit a fix or not.~~
Edit: The linter users `pycodestyle.max-line-width`. The `line-width` option has been removed from the `LinterSettings`
## Test Plan
Added integration test. Built the documentation and verified that the links are correct.
## Summary
First time contribute to `ruff`, so If there are low-level errors,
please forgive me. 🙇
Introduce auto fix for `E275`, this partially address #8121.
## Test Plan
Already coverd.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Close#8123
## Test Plan
<!-- How was it tested? -->
New test cases
---------
Signed-off-by: harupy <hkawamura0130@gmail.com>
## Summary
This was just a bug in the parser ranges, probably since it was
initially implemented. Given `match n % 3, n % 5: ...`, the "subject"
(i.e., the tuple of two binary operators) was using the entire range of
the `match` statement.
Closes https://github.com/astral-sh/ruff/issues/8091.
## Test Plan
`cargo test`
## Summary
This PR updates our E721 implementation and semantics to match the
updated `pycodestyle` logic, which I think is an improvement.
Specifically, we now allow `type(obj) is int` for exact type
comparisons, which were previously impossible. So now, we're largely
just linting against code like `type(obj) == int`.
This change is gated to preview mode.
Closes https://github.com/astral-sh/ruff/issues/7904.
## Test Plan
Updated the test fixture and ensured parity with latest Flake8.
## Summary
This PR updates our documentation for the upcoming formatter release.
Broadly, the documentation is now structured as follows:
- Overview
- Tutorial
- Installing Ruff
- The Ruff Linter
- Overview
- `ruff check`
- Rule selection
- Error suppression
- Exit codes
- The Ruff Formatter
- Overview
- `ruff format`
- Philosophy
- Configuration
- Format suppression
- Exit codes
- Black compatibility
- Known deviations
- Configuring Ruff
- pyproject.toml
- File discovery
- Configuration discovery
- CLI
- Shell autocompletion
- Preview
- Rules
- Settings
- Integrations
- `pre-commit`
- VS Code
- LSP
- PyCharm
- GitHub Actions
- FAQ
- Contributing
The major changes include:
- Removing the "Usage" section from the docs, and instead folding that
information into "Integrations" and the new Linter and Formatter
sections.
- Breaking up "Configuration" into "Configuring Ruff" (for generic
configuration), and new Linter- and Formatter-specific sections.
- Updating all example configurations to use `[tool.ruff.lint]` and
`[tool.ruff.format]`.
My suggestion is to pull and build the docs locally, and review by
reading them in the browser rather than trying to parse all the code
changes.
Closes https://github.com/astral-sh/ruff/issues/7235.
Closes https://github.com/astral-sh/ruff/issues/7647.
Adds a new `ruff version` sub-command which displays long version
information in the style of `cargo` and `rustc`. We include the number
of commits since the last release tag if its a development build, in the
style of Python's versioneer.
```
❯ ruff version
ruff 0.1.0+14 (947940e91 2023-10-18)
```
```
❯ ruff version --output-format json
{
"version": "0.1.0",
"commit_info": {
"short_commit_hash": "947940e91",
"commit_hash": "947940e91269f20f6b3f8f8c7c63f8e914680e80",
"commit_date": "2023-10-18",
"last_tag": "v0.1.0",
"commits_since_last_tag": 14
}
}%
```
```
❯ cargo version
cargo 1.72.1 (103a7ff2e 2023-08-15)
```
## Test plan
I've tested this manually locally, but want to at least add unit tests
for the message formatting. We'd also want to check the next release to
ensure the information is correct.
I checked build behavior with a detached head and branches.
## Future work
We could include rustc and cargo versions from the build, the current
Python version, and other diagnostic information for bug reports.
The `--version` and `-V` output is unchanged. However, we could update
it to display the long ruff version without the rust and cargo versions
(this is what cargo does). We'll need to be careful to ensure this does
not break downstream packages which parse our version string.
```
❯ ruff --version
ruff 0.1.0
```
The LSP should be updated to use `ruff version --output-format json`
instead of parsing `ruff --version`.
This is my first PR and I'm new at rust, so feel free to ask me to
rewrite everything if needed ;)
The rule must be called after deferred lambas have been visited because
of the last check (whether the lambda parameters are used in the body of
the function that's being called). I didn't know where to do it, so I
did what I could to be able to work on the rule itself:
- added a `ruff_linter::checkers::ast::analyze::lambda` module
- build a vec of visited lambdas in `visit_deferred_lambdas`
- call `analyze::lambda` on the vec after they all have been visited
Building that vec of visited lambdas was necessary so that bindings
could be properly resolved in the case of nested lambdas.
Note that there is an open issue in pylint for some false positives, do
we need to fix that before merging the rule?
https://github.com/pylint-dev/pylint/issues/8192
Also, I did not provide any fixes (yet), maybe we want do avoid merging
new rules without fixes?
## Summary
Checks for lambdas whose body is a function call on the same arguments
as the lambda itself.
### Bad
```python
df.apply(lambda x: str(x))
```
### Good
```python
df.apply(str)
```
## Test Plan
Added unit test and snapshot.
Manually compared pylint and ruff output on pylint's test cases.
## References
- [pylint
documentation](https://pylint.readthedocs.io/en/latest/user_guide/messages/warning/unnecessary-lambda.html)
- [pylint
implementation](https://github.com/pylint-dev/pylint/blob/main/pylint/checkers/base/basic_checker.py#L521-L587)
- https://github.com/astral-sh/ruff/issues/970
## Summary
The lint checks for number of arguments in a function *definition*, but
the message says “function *call*”
## Test Plan
See what breaks and change the tests
Given `print(*a_list_with_elements, sep="\n")`, we can't remove the
separator (unlike in `print(a, sep="\n")`), since we don't know how many
arguments were provided.
Closes https://github.com/astral-sh/ruff/issues/8078.
- Add changelog entry for 0.1.1
- Bump version to 0.1.1
- Require preview for fix added in #7967
- Allow duplicate headings in changelog (markdownlint setting)
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes https://github.com/astral-sh/ruff/issues/7448
Fixes https://github.com/astral-sh/ruff/issues/7892
I've removed automatic dangling comment formatting, we're doing manual
dangling comment formatting everywhere anyway (the
assert-all-comments-formatted ensures this) and dangling comments would
break the formatting there.
## Test Plan
New test file.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Split out of #8044: In preview style, ellipsis are also collapsed in
non-stub files. This should only affect function/class contexts since
for other statements stub are generally not used. I've updated our tests
to use `pass` instead to reflect this, which makes tracking the preview
style changes much easier.
## Summary
Given an expression like `[x for (x) in y]`, we weren't skipping over
parentheses when searching for the `in` between `(x)` and `y`.
Closes https://github.com/astral-sh/ruff/issues/8053.
## Summary
In #6157 a warning was introduced when users use `ruff: noqa`
suppression in-line instead of at the file-level. I had this trigger
today after forgetting about it, and the warning is an excellent
improvement.
I knew immediately what the issue was because I raised it previously,
but on reading the warning I'm not sure it would be so obvious to all
users. This PR extends the error with a short sentence explaining that
line-level suppression should omit the `ruff:` prefix.
## Test Plan
Not sure it's necessary for such a trivial change :)
**Summary** `ruff format --diff` is similar to `ruff format --check`,
but we don't only error with the list of file that would be formatted,
but also show a diff between the unformatted input and the formatted
output.
```console
$ ruff format --diff scratch.py scratch.pyi scratch.ipynb
warning: `ruff format` is not yet stable, and subject to change in future versions.
--- scratch.ipynb
+++ scratch.ipynb
@@ -1,3 +1,4 @@
import numpy
-maths = (numpy.arange(100)**2).sum()
-stats= numpy.asarray([1,2,3,4]).median()
+
+maths = (numpy.arange(100) ** 2).sum()
+stats = numpy.asarray([1, 2, 3, 4]).median()
--- scratch.py
+++ scratch.py
@@ -1,3 +1,3 @@
x = 1
-y=2
+y = 2
z = 3
2 files would be reformatted, 1 file left unchanged
```
With `--diff`, the summary message gets printed to stderr to allow e.g.
`ruff format --diff . > format.patch`.
At the moment, jupyter notebooks are formatted as code diffs, while
everything else is a real diff that could be applied. This means that
the diffs containing jupyter notebooks are not real diffs and can't be
applied. We could change this to json diffs, but they are hard to read.
We could also split the diff option into a human diff option, where we
deviate from the machine readable diff constraints, and a proper machine
readable, appliable diff output that you can pipe into other tools.
To make the tests work, the results (and errors, if any) are sorted
before printing them. Previously, the print order was random, i.e. two
identical runs could have different output.
Open question: Should this go into the markdown docs? Or will this be
subsumed by the integration of the formatter into `ruff check`?
**Test plan** Fixtures for the change and no change cases, including a
jupyter notebook and for file input and stdin.
Fixes#7231
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
**Summary** Insert a newline after nested function and class
definitions, unless there is a trailing own line comment.
We need to e.g. format
```python
if platform.system() == "Linux":
if sys.version > (3, 10):
def f():
print("old")
else:
def f():
print("new")
f()
```
as
```python
if platform.system() == "Linux":
if sys.version > (3, 10):
def f():
print("old")
else:
def f():
print("new")
f()
```
even though `f()` is directly preceded by an if statement, not a
function or class definition. See the comments and fixtures for trailing
own line comment handling.
**Test Plan** I checked that the new content of `newlines.py` matches
black's formatting.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
When linting, we store a map from file path to fixes, which we then use
to show a fix summary in the printer.
In the printer, we assume that if the map is non-empty, then we have at
least one fix. But this isn't enforced by the fix struct, since you can
have an entry from (file path) to (empty fix table). In practice, this
only bites us when linting from `stdin`, since when linting across
multiple files, we have an `AddAssign` on `Diagnostics` that avoids
adding empty entries to the map. When linting from `stdin`, we create
the map directly, and so it _is_ possible to have a non-empty map that
doesn't contain any fixes, leading to a panic.
This PR introduces a dedicated struct to make these constraints part of
the formal interface.
Closes https://github.com/astral-sh/ruff/issues/8027.
## Test Plan
`cargo test` (notice two failures are removed)
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
In https://github.com/astral-sh/ruff/pull/7968, I introduced a
regression whereby we started to treat imports used _only_ in type
annotation bounds (with `__future__` annotations) as unused.
The root of the issue is that I started using `visit_annotation` for
these bounds. So we'd queue up the bound in the list of deferred type
parameters, then when visiting, we'd further queue it up in the list of
deferred type annotations... Which we'd then never visit, since deferred
type annotations are visited _before_ deferred type parameters.
Anyway, the better solution here is to use a dedicated flag for these,
since they have slightly different behavior than type annotations.
I've also fixed what I _think_ is a bug whereby we previously failed to
resolve `Callable` in:
```python
type RecordCallback[R: Record] = Callable[[R], None]
from collections.abc import Callable
```
IIUC, the values in type aliases should be evaluated lazily, like type
parameters.
Closes https://github.com/astral-sh/ruff/issues/8017.
## Test Plan
`cargo test`
## Summary
Rule B005 of flake8-bugbear docs has a typo in one of the examples that
leads to a confusion in the correctness of `.strip()` method

```python
# Wrong output (used in docs)
"text.txt".strip(".txt") # "ex"
# Correct output
"text.txt".strip(".txt") # "e"
```
## Summary
Fix a typo in the docs for quote style.
> a = "a string without any quotes"
> b = "It's monday morning"
> Ruff will change a to use single quotes when using quote-style =
"single". However, a will be unchanged, as converting to single quotes
would require the inner ' to be escaped, which leads to less readable
code: 'It\'s monday morning'.
It should read "However, **b** will be unchanged".
## Test Plan
N/A.
## Summary
### What it does
This rule triggers an error when a bare raise statement is not in an
except or finally block.
### Why is this bad?
If raise statement is not in an except or finally block, there is no
active exception to
re-raise, so it will fail with a `RuntimeError` exception.
### Example
```python
def validate_positive(x):
if x <= 0:
raise
```
Use instead:
```python
def validate_positive(x):
if x <= 0:
raise ValueError(f"{x} is not positive")
```
## Test Plan
Added unit test and snapshot.
Manually compared ruff and pylint outputs on pylint's tests.
## References
- [pylint
documentation](https://pylint.pycqa.org/en/stable/user_guide/messages/error/misplaced-bare-raise.html)
- [pylint
implementation](https://github.com/pylint-dev/pylint/blob/main/pylint/checkers/exceptions.py#L339)
See the provided breaking changes note for details.
Removes support for the deprecated `--format`option in the `ruff check`
CLI, `format` inference as `output-format` in the configuration file,
and the `RUFF_FORMAT` environment variable.
The error message for use of `format` in the configuration file could be
better, but would require some awkward serde wrappers and it seems hard
to present the correct schema to the user still.
## Summary
Given `type RecordOrThings = Record | int | str`, the right-hand side
won't be evaluated at runtime. Same goes for `Record` in `type
RecordCallback[R: Record] = Callable[[R], None]`. This PR modifies the
visitation logic to treat them as typing-only.
Closes https://github.com/astral-sh/ruff/issues/7966.
## Summary
Unlike other filepath-based settings, the `cache-dir` wasn't being
resolved relative to the project root, when specified as an absolute
path.
Closes https://github.com/astral-sh/ruff/issues/7958.
## Summary
This PR adds a new `cell` field to the JSON output format which
indicates the Notebook cell this diagnostic (and fix) belongs to. It
also updates the location for the diagnostic and fixes as per the
`NotebookIndex`. It will be used in the VSCode extension to display the
diagnostic in the correct cell.
The diagnostic and edit start and end source locations are translated
for the notebook as per the `NotebookIndex`. The end source location for
an edit needs some special handling.
### Edit end location
To understand this, the following context is required:
1. Visible lines in Jupyter Notebook vs JSON array strings: The newline
is part of the string in the JSON format. This means that if there are 3
visible lines in a cell where the last line is empty then the JSON would
contain 2 strings in the source array, both ending with a newline:
**JSON format:**
```json
[
"# first line\n",
"# second line\n",
]
```
**Notebook view:**
```python
1 # first line
2 # second line
3
```
2. If an edit needs to remove an entire line including the newline, then
the end location would be the start of the next row.
To remove a statement in the following code:
```python
import os
```
The edit would be:
```
start: row 1, col 1
end: row 2, col 1
```
Now, here's where the problem lies. The notebook index doesn't have any
information for row 2 because it doesn't exists in the actual notebook.
The newline was added by Ruff to concatenate the source code and it's
removed before writing back. But, the edit is computed looking at that
newline.
This means that while translating the end location for an edit belong to
a Notebook, we need to check if both the start and end location belongs
to the same cell. If not, then the end location should be the first
character of the next row and if so, translate that back to the last
character of the previous row. Taking the above example, the translated
location for Notebook would be:
```
start: row 1, col 1
end: row 1, col 10
```
## Test Plan
Add test cases for notebook output in the JSON format and update
existing snapshots.
## Summary
This PR refactors the `NotebookIndex` struct to use `OneIndexed` to make
the
intent of the code clearer.
## Test Plan
Update the existing test case and run `cargo test` to verify the change.
- [x] Verify `--diff` output
- [x] Verify the diagnostics output
- [x] Verify `--show-source` output
**Summary** Handle comment before the default values of function
parameters correctly by inserting a line break instead of space after
the equals sign where required.
```python
def f(
a = # parameter trailing comment; needs line break
1,
b =
# default leading comment; needs line break
2,
c = ( # the default leading can only be end-of-line with parentheses; no line break
3
),
d = (
# own line leading comment with parentheses; no line break
4
)
)
```
Fixes#7603
**Test Plan** Added the different cases and one more complex case as
fixtures.
## Summary
This PR fixes the bug where the rule `E251` was being triggered on a equal token
inside a f-string which was used in the context of debug expressions.
For example, the following was being flagged before the fix:
```python
print(f"{foo = }")
```
But, now it is not. This leads to false negatives such as:
```python
print(f"{foo(a = 1)}")
```
One solution would be to know if the opened parentheses was inside a f-string or
not. If it was then we can continue flagging until it's closed. If not, then we
should not flag it.
## Test Plan
Add new test cases and check that they don't raise any false positives.
fixes: #7882
## Summary
`foo(**{})` was an overlooked edge case for `PIE804` which introduced a
crash within the Fix, introduced in #7884.
I've made it so that `foo(**{})` turns into `foo()` when applied with
`--fix`, but is that desired/expected? 🤔 Should we just ignore instead?
## Test Plan
`cargo test`
Closes https://github.com/astral-sh/ruff/issues/7572
Drops formatting specific rules from the default rule set as they
conflict with formatters in general (and in particular, conflict with
our formatter). Most of these rules are in preview, but the removal of
`line-too-long` and `mixed-spaces-and-tabs` is a change to the stable
rule set.
## Example
The following no longer raises `E501`
```
echo "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx = 1" | ruff check -
```
## Summary
Throughout the codebase, we have this pattern:
```rust
let mut diagnostic = ...
if checker.patch(Rule::UnusedVariable) {
// Do the fix.
}
diagnostics.push(diagnostic)
```
This was helpful when we computed fixes lazily; however, we now compute
fixes eagerly, and this is _only_ used to ensure that we don't generate
fixes for rules marked as unfixable.
We often forget to add this, and it leads to bugs in enforcing
`--unfixable`.
This PR instead removes all of these checks, moving the responsibility
of enforcing `--unfixable` up to `check_path`. This is similar to how
@zanieb handled the `--extend-unsafe` logic: we post-process the
diagnostics to remove any fixes that should be ignored.
## Summary
Add autofix for `PLR1714` using tuples.
If added complexity is desired, we can lean into the `set` part by doing
some kind of builtin check on all of the comparator elements for
starters, since we otherwise don't know if something's hashable.
## Test Plan
`cargo test`, and manually.
**Summary** Remove spaces from import statements such as
```python
import tqdm . tqdm
from tqdm . auto import tqdm
```
See also #7760 for a better solution.
**Test Plan** New fixtures
**Summary** Quoting of f-strings can change if they are triple quoted
and only contain single quotes inside.
Fixes#6841
**Test Plan** New fixtures
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
closes https://github.com/astral-sh/ruff/issues/7912
## Test Plan
<!-- How was it tested? -->
Adds two configuration-file only settings `extend-safe-fixes` and
`extend-unsafe-fixes` which can be used to promote and demote the
applicability of fixes for rules.
Fixes with `Never` applicability cannot be promoted.
## Summary
Given:
```python
baz: Annotated[
str,
[qux for qux in foo],
]
```
We treat `baz` as `BindingKind::Annotation`, to ensure that references
to `baz` are marked as unbound. However, we were _also_ treating `qux`
as `BindingKind::Annotation`, which meant that the load in the
comprehension _also_ errored.
Closes https://github.com/astral-sh/ruff/issues/7879.
## Summary
This PR upgrades some rules from "sometimes" to "always" fixes, now that
we're getting ready to ship support in the CLI. The focus here was on
identifying rules for which the diagnostic itself is high-confidence,
and the fix itself is too (assuming that the diagnostic is correct).
This is _unlike_ rules that _may_ be a false positive, like those that
(e.g.) assume an object is a dictionary when you call `.values()` on it.
Specifically, I upgraded:
- A bunch of rules that only apply to `.pyi` files.
- Rules that rewrite deprecated imports or aliases.
- Some other misc. rules, like: `empty-print-string`, `unused-noqa`,
`getattr-with-constant`.
Open to feedback on any of these.
## Summary
Adds autofix to `PYI030`
Closes#7854.
Unsure if the cloning method I chose is the best solution here, feel
free to suggest alternatives!
## Test Plan
`cargo test` as well as manually
## Summary
Restores functionality of #7875 but in the correct place. Closes#7877.
~~I couldn't figure out how to get cargo fmt to work, so hopefully
that's run in CI.~~ Nevermind, figured it out.
## Test Plan
Can see output of json.
## Summary
This PR fixes a bug to disallow f-strings in match pattern literal.
```
literal_pattern ::= signed_number
| signed_number "+" NUMBER
| signed_number "-" NUMBER
| strings
| "None"
| "True"
| "False"
| signed_number: NUMBER | "-" NUMBER
```
Source:
https://docs.python.org/3/reference/compound_stmts.html#grammar-token-python-grammar-literal_pattern
Also,
```console
$ python /tmp/t.py
File "/tmp/t.py", line 4
case "hello " f"{name}":
^^^^^^^^^^^^^^^^^^
SyntaxError: patterns may only match literals and attribute lookups
```
## Test Plan
Update existing test case and accordingly the snapshots. Also, add a new
test case to verify that the parser does raise an error.
## Summary
Fixes#7853.
The old and new source files were reversed in the call to
`TextDiff::from_lines`, so the diff output of the CLI was also reversed.
## Test Plan
Two snapshots were updated in the process, so any reversal should be
caught :)
Closes https://github.com/astral-sh/ruff/issues/7491
Users found it confusing that warnings were displayed when ignoring a
preview rule (which has no effect without `--preview`). While we could
retain the warning with different messaging, I've opted to remove it for
now. With this pull request, we will only warn on `--select` and
`--extend-select` but not `--fixable`, `--unfixable`, `--ignore`, or
`--extend-fixable`.
## Summary
Resolves https://github.com/astral-sh/ruff/issues/7618.
The list of builtin iterator is not exhaustive.
## Test Plan
`cargo test`
``` python
a = [1, 2]
examples = [
enumerate(a),
filter(lambda x: x, a),
map(int, a),
reversed(a),
zip(a),
iter(a),
]
for example in examples:
print(next(example))
```
## Summary
Implement
[`no-single-item-in`](https://github.com/dosisod/refurb/blob/master/refurb/checks/iterable/no_single_item_in.py)
as `single-item-membership-test` (`FURB171`).
Uses the helper function `generate_comparison` from the `pycodestyle`
implementations; this function should probably be moved, but I am not
sure where at the moment.
Update: moved it to `ruff_python_ast::helpers`.
Related to #1348.
## Test Plan
`cargo test`
I noticed that `tracing::instrument` wasn't available with only the
`"std"` feature enabled when trying to run `cargo doc -p
ruff_formatter`.
I could be misunderstanding something, but I couldn't even run the tests
for the crate.
```
ruff on ruff-formatter-tracing [$] is 📦 v0.0.292 via 🦀 v1.72.0
❯ cargo test -p ruff_formatter
Compiling ruff_formatter v0.0.0 (/Users/chrispryer/github/ruff/crates/ruff_formatter)
error[E0433]: failed to resolve: could not find `instrument` in `tracing`
--> crates/ruff_formatter/src/printer/mod.rs:57:16
|
57 | #[tracing::instrument(name = "Printer::print", skip_all)]
| ^^^^^^^^^^ could not find `instrument` in `tracing`
|
note: found an item that was configured out
--> /Users/chrispryer/.cargo/registry/src/index.crates.io-6f17d22bba15001f/tracing-0.1.37/src/lib.rs:959:29
|
959 | pub use tracing_attributes::instrument;
| ^^^^^^^^^^
= note: the item is gated behind the `attributes` feature
For more information about this error, try `rustc --explain E0433`.
error: could not compile `ruff_formatter` (lib) due to previous error
warning: build failed, waiting for other jobs to finish...
error: could not compile `ruff_formatter` (lib test) due to previous error
```
Maybe the idea is to keep this crate minimal, but I figured I'd at least
point this out.
## Summary
Document the performance effects of `itertools.starmap`, including that
it is actually slower than comprehensions in Python 3.12.
Closes#7771.
## Test Plan
`python scripts/check_docs_formatted.py`
After working with the previous change in
https://github.com/astral-sh/ruff/pull/7821 I found the names a bit
unclear and their relationship with the user-facing API muddied. Since
the applicability is exposed to the user directly in our JSON output, I
think it's important that these names align with our configuration
options. I've replaced `Manual` or `Never` with `Display` which captures
our intent for these fixes (only for display). Here, we create room for
future levels, such as `HasPlaceholders`, which wouldn't fit into the
`Always`/`Sometimes`/`Never` levels.
Unlike https://github.com/astral-sh/ruff/pull/7819, this retains the
flat enum structure which is easier to work with.
Previously we just omitted diagnostic summaries when using `--fix` or
`--diff` with a stdin file. Now, we still write the summaries to stderr
instead of the main writer (which is generally stdout but could be
changed by `--output-file`).
Rebase of https://github.com/astral-sh/ruff/pull/5119 authored by
@evanrittenhouse with additional refinements.
## Changes
- Adds `--unsafe-fixes` / `--no-unsafe-fixes` flags to `ruff check`
- Violations with unsafe fixes are not shown as fixable unless opted-in
- Fix applicability is respected now
- `Applicability::Never` fixes are no longer applied
- `Applicability::Sometimes` fixes require opt-in
- `Applicability::Always` fixes are unchanged
- Hints for availability of `--unsafe-fixes` added to `ruff check`
output
## Examples
Check hints at hidden unsafe fixes
```
❯ ruff check example.py --no-cache --select F601,W292
example.py:1:14: F601 Dictionary key literal `'a'` repeated
example.py:2:15: W292 [*] No newline at end of file
Found 2 errors.
[*] 1 fixable with the `--fix` option (1 hidden fix can be enabled with the `--unsafe-fixes` option).
```
We could add an indicator for which violations have hidden fixes in the
future.
Check treats unsafe fixes as applicable with opt-in
```
❯ ruff check example.py --no-cache --select F601,W292 --unsafe-fixes
example.py:1:14: F601 [*] Dictionary key literal `'a'` repeated
example.py:2:15: W292 [*] No newline at end of file
Found 2 errors.
[*] 2 fixable with the --fix option.
```
Also can be enabled in the config file
```
❯ cat ruff.toml
unsafe-fixes = true
```
And opted-out per invocation
```
❯ ruff check example.py --no-cache --select F601,W292 --no-unsafe-fixes
example.py:1:14: F601 Dictionary key literal `'a'` repeated
example.py:2:15: W292 [*] No newline at end of file
Found 2 errors.
[*] 1 fixable with the `--fix` option (1 hidden fix can be enabled with the `--unsafe-fixes` option).
```
Diff does not include unsafe fixes
```
❯ ruff check example.py --no-cache --select F601,W292 --diff
--- example.py
+++ example.py
@@ -1,2 +1,2 @@
x = {'a': 1, 'a': 1}
-print(('foo'))
+print(('foo'))
\ No newline at end of file
Would fix 1 error.
```
Unless there is opt-in
```
❯ ruff check example.py --no-cache --select F601,W292 --diff --unsafe-fixes
--- example.py
+++ example.py
@@ -1,2 +1,2 @@
-x = {'a': 1}
-print(('foo'))
+x = {'a': 1, 'a': 1}
+print(('foo'))
\ No newline at end of file
Would fix 2 errors.
```
https://github.com/astral-sh/ruff/pull/7790 will improve the diff
messages following this pull request
Similarly, `--fix` and `--fix-only` require the `--unsafe-fixes` flag to
apply unsafe fixes.
## Related
Replaces #5119
Closes https://github.com/astral-sh/ruff/issues/4185
Closes https://github.com/astral-sh/ruff/issues/7214
Closes https://github.com/astral-sh/ruff/issues/4845
Closes https://github.com/astral-sh/ruff/issues/3863
Addresses https://github.com/astral-sh/ruff/issues/6835
Addresses https://github.com/astral-sh/ruff/issues/7019
Needs follow-up https://github.com/astral-sh/ruff/issues/6962
Needs follow-up https://github.com/astral-sh/ruff/issues/4845
Needs follow-up https://github.com/astral-sh/ruff/issues/7436
Needs follow-up https://github.com/astral-sh/ruff/issues/7025
Needs follow-up https://github.com/astral-sh/ruff/issues/6434
Follow-up #7790
Follow-up https://github.com/astral-sh/ruff/pull/7792
---------
Co-authored-by: Evan Rittenhouse <evanrittenhouse@gmail.com>
## Summary
This PR updates the parser definition to use the precise location when reporting
an invalid f-string conversion flag error.
Taking the following example code:
```python
f"{foo!x}"
```
On earlier version,
```
Error: f-string: invalid conversion character at byte offset 6
```
Now,
```
Error: f-string: invalid conversion character at byte offset 7
```
This becomes more useful when there's whitespace between `!` and the flag value
although that is not valid but we can't detect that now.
## Test Plan
As mentioned above.
## Summary
This PR resolves an issue raised in
https://github.com/astral-sh/ruff/discussions/7810, whereby we don't fix
an f-string that exceeds the line length _even if_ the resultant code is
_shorter_ than the current code.
As part of this change, I've also refactored and extracted some common
logic we use around "ensuring a fix isn't breaking the line length
rules".
## Test Plan
`cargo test`
## Summary
The implementation here differs from the non-`stdin` version -- this is
now more consistent.
## Test Plan
```
❯ cat Untitled.ipynb | cargo run -p ruff_cli -- check --stdin-filename Untitled.ipynb --diff -n
Finished dev [unoptimized + debuginfo] target(s) in 0.11s
Running `target/debug/ruff check --stdin-filename Untitled.ipynb --diff -n`
--- Untitled.ipynb:cell 2
+++ Untitled.ipynb:cell 2
@@ -1 +0,0 @@
-import os
--- Untitled.ipynb:cell 4
+++ Untitled.ipynb:cell 4
@@ -1 +0,0 @@
-import sys
```
## Summary
This PR fixes the bug where the formatter would panic if a class/function with
decorators had a suppression comment.
The fix is to use to correct start location to find the `async`/`def`/`class`
keyword when decorators are present which is the end of the last
decorator.
## Test Plan
Add test cases for the fix and update the snapshots.
- Only trigger for immediately adjacent isinstance() calls with the same
target
- Preserve order of or conditions
Two existing tests changed:
- One was incorrectly reordering the or conditions, and is now correct.
- Another was combining two non-adjacent isinstance() calls. It's safe
enough in that example,
but this isn't safe to do in general, and it feels low-value to come up
with a heuristic for
when it is safe, so it seems better to not combine the calls in that
case.
Fixes https://github.com/astral-sh/ruff/issues/7797
## Summary
We now list each changed file when running with `--check`.
Closes https://github.com/astral-sh/ruff/issues/7782.
## Test Plan
```
❯ cargo run -p ruff_cli -- format foo.py --check
Compiling ruff_cli v0.0.292 (/Users/crmarsh/workspace/ruff/crates/ruff_cli)
rgo + Finished dev [unoptimized + debuginfo] target(s) in 1.41s
Running `target/debug/ruff format foo.py --check`
warning: `ruff format` is a work-in-progress, subject to change at any time, and intended only for experimentation.
Would reformat: foo.py
1 file would be reformatted
```
## Summary
Check that the sequence type is a list, set, dict, or tuple before
recommending replacing the `enumerate(...)` call with `range(len(...))`.
Document behaviour so users are aware of the type inference limitation
leading to false negatives.
Closes#7656.
## Summary
This PR fixes a bug in the lexer for f-string format spec where it would
consider the `{{` (double curly braces) as an escape pattern.
This is not the case as evident by the
[PEP](https://peps.python.org/pep-0701/#how-to-produce-these-new-tokens)
as well but I missed the part:
> [..]
> * **If in “format specifier mode” (see step 3), an opening brace ({)
or a closing brace (}).**
> * If not in “format specifier mode” (see step 3), an opening brace ({)
or a closing brace (}) that is not immediately followed by another
opening/closing brace.
## Test Plan
Add a test case to verify the fix and update the snapshot.
fixes: #7778
## Summary
Two of the three listed examples were wrong: one was semantically
incorrect, another was _correct_ but not actually within the scope of
the rule.
Good motivation for us to start linting documentation examples :)
Closes https://github.com/astral-sh/ruff/issues/7773.
## Summary
We'll revert back to the crates.io release once it's up-to-date, but
better to get this out now that Python 3.12 is released.
## Test Plan
`cargo test`
## Summary
This PR enables `ruff format` to format Jupyter notebooks.
Most of the work is contained in a new `format_source` method that
formats a generic `SourceKind`, then returns `Some(transformed)` if the
source required formatting, or `None` otherwise.
Closes https://github.com/astral-sh/ruff/issues/7598.
## Test Plan
Ran `cat foo.py | cargo run -p ruff_cli -- format --stdin-filename
Untitled.ipynb`; verified that the console showed a reasonable error:
```console
warning: Failed to read notebook Untitled.ipynb: Expected a Jupyter Notebook, which must be internally stored as JSON, but this file isn't valid JSON: EOF while parsing a value at line 1 column 0
```
Ran `cat Untitled.ipynb | cargo run -p ruff_cli -- format
--stdin-filename Untitled.ipynb`; verified that the JSON output
contained formatted source code.
## Summary
When writing back notebooks via `stdout`, we need to write back the
entire JSON content, not _just_ the fixed source code. Otherwise,
writing the output _back_ to the file will yield an invalid notebook.
Closes https://github.com/astral-sh/ruff/issues/7747
## Test Plan
`cargo test`
## Summary
It turns out that _some_ identifiers can contain newlines --
specifically, dot-delimited import identifiers, like:
```python
import foo\
.bar
```
At present, we print all identifiers verbatim, which causes us to retain
the `\` in the formatted output. This also leads to violating some debug
assertions (see the linked issue, though that's a symptom of this
formatting failure).
This PR adds detection for import identifiers that contain newlines, and
formats them via `text` (slow) rather than `source_code_slice` (fast) in
those cases.
Closes https://github.com/astral-sh/ruff/issues/7734.
## Test Plan
`cargo test`
## Summary
There's no way for users to fix this warning if they're intentionally
using an "invalid" PEP 593 annotation, as is the case in CPython. This
is a symptom of having warnings that aren't themselves diagnostics. If
we want this to be user-facing, we should add a diagnostic for it!
## Test Plan
Ran `cargo run -p ruff_cli -- check foo.py -n` on:
```python
from typing import Annotated
Annotated[int]
```
## Summary
If we have, e.g.:
```python
sum((
factor.dims for factor in bases
), [])
```
We generate three edits: two insertions (for the `operator` and
`functools` imports), and then one replacement (for the `sum` call
itself). We need to ensure that the insertions come before the
replacement; otherwise, the edits will appear overlapping and
out-of-order.
Closes https://github.com/astral-sh/ruff/issues/7718.
## Summary
This PR fixes a bug where if a Windows newline (`\r\n`) character was
escaped, then only the `\r` was consumed and not `\n` leading to an
unterminated string error.
## Test Plan
Add new test cases to check the newline escapes.
fixes: #7632
## Summary
This PR fixes the bug where the value of a string node type includes the
escaped mac/windows newline character.
Note that the token value still includes them, it's only removed when
parsing the string content.
## Test Plan
Add new test cases for the string node type to check that the escapes
aren't being included in the string value.
fixes: #7723
## Summary
This PR modifies the `line-too-long` and `doc-line-too-long` rules to
ignore lines that are too long due to the presence of a pragma comment
(e.g., `# type: ignore` or `# noqa`). That is, if a line only exceeds
the limit due to the pragma comment, it will no longer be flagged as
"too long". This behavior mirrors that of the formatter, thus ensuring
that we don't flag lines under E501 that the formatter would otherwise
avoid wrapping.
As a concrete example, given a line length of 88, the following would
_no longer_ be considered an E501 violation:
```python
# The string literal is 88 characters, including quotes.
"shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:sh" # type: ignore
```
This, however, would:
```python
# The string literal is 89 characters, including quotes.
"shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:shape:sha" # type: ignore
```
In addition to mirroring the formatter, this also means that adding a
pragma comment (like `# noqa`) won't _cause_ additional violations to
appear (namely, E501). It's very common for users to add a `# type:
ignore` or similar to a line, only to find that they then have to add a
suppression comment _after_ it that was required before, as in `# type:
ignore # noqa: E501`.
Closes https://github.com/astral-sh/ruff/issues/7471.
## Test Plan
`cargo test`
## Summary
This PR fixes the bug where the `NotebookIndex` was not being computed
when
using stdin as the input source.
## Test Plan
On `main`, the diagnostic output won't include the cell number when
using stdin
while it'll be included after this fix.
### `main`
```console
$ cat ~/playground/ruff/notebooks/test.ipynb | cargo run --bin ruff -- check --isolated --no-cache - --stdin-filename ~/playground/ruff/notebooks/test.ipynb
/Users/dhruv/playground/ruff/notebooks/test.ipynb:2:8: F401 [*] `math` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:7:8: F811 Redefinition of unused `random` from line 1
/Users/dhruv/playground/ruff/notebooks/test.ipynb:8:8: F401 [*] `pprint` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:12:4: F632 [*] Use `==` to compare constant literals
/Users/dhruv/playground/ruff/notebooks/test.ipynb:13:38: F632 [*] Use `==` to compare constant literals
Found 5 errors.
[*] 4 potentially fixable with the --fix option.
```
### `dhruv/notebook-index-stdin`
```console
$ cat ~/playground/ruff/notebooks/test.ipynb | cargo run --bin ruff -- check --isolated --no-cache - --stdin-filename ~/playground/ruff/notebooks/test.ipynb
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 3:2:8: F401 [*] `math` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5:1:8: F811 Redefinition of unused `random` from line 1
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5:2:8: F401 [*] `pprint` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6:2:4: F632 [*] Use `==` to compare constant literals
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6:3:38: F632 [*] Use `==` to compare constant literals
Found 5 errors.
[*] 4 potentially fixable with the --fix option.
```
## Summary
This PR implements a variety of optimizations to improve performance of
the Eradicate rule, which always shows up in all-rules benchmarks and
bothers me. (These improvements are not hugely important, but it was
kind of a fun Friday thing to spent a bit of time on.)
The improvements include:
- Doing cheaper work first (checking for some explicit substrings
upfront).
- Using `aho-corasick` to speed an exact substring search.
- Merging multiple regular expressions using a `RegexSet`.
- Removing some unnecessary `\s*` and other pieces from the regular
expressions (since we already trim strings before matching on them).
## Test Plan
I benchmarked this function in a standalone crate using a variety of
cases. Criterion reports that this version is up to 80% faster, and
almost every case is at least 50% faster:
```
Eradicate/Detection/# Warn if we are installing over top of an existing installation. This can
time: [101.84 ns 102.32 ns 102.82 ns]
change: [-77.166% -77.062% -76.943%] (p = 0.00 < 0.05)
Performance has improved.
Found 3 outliers among 100 measurements (3.00%)
3 (3.00%) high mild
Eradicate/Detection/#from foo import eradicate
time: [74.872 ns 75.096 ns 75.314 ns]
change: [-84.180% -84.131% -84.079%] (p = 0.00 < 0.05)
Performance has improved.
Found 1 outliers among 100 measurements (1.00%)
1 (1.00%) high mild
Eradicate/Detection/# encoding: utf8
time: [46.522 ns 46.862 ns 47.237 ns]
change: [-29.408% -28.918% -28.471%] (p = 0.00 < 0.05)
Performance has improved.
Found 7 outliers among 100 measurements (7.00%)
6 (6.00%) high mild
1 (1.00%) high severe
Eradicate/Detection/# Issue #999
time: [16.942 ns 16.994 ns 17.058 ns]
change: [-57.243% -57.064% -56.815%] (p = 0.00 < 0.05)
Performance has improved.
Found 3 outliers among 100 measurements (3.00%)
2 (2.00%) high mild
1 (1.00%) high severe
Eradicate/Detection/# type: ignore
time: [43.074 ns 43.163 ns 43.262 ns]
change: [-17.614% -17.390% -17.152%] (p = 0.00 < 0.05)
Performance has improved.
Found 5 outliers among 100 measurements (5.00%)
3 (3.00%) high mild
2 (2.00%) high severe
Eradicate/Detection/# user_content_type, _ = TimelineEvent.objects.using(db_alias).get_or_create(
time: [209.40 ns 209.81 ns 210.23 ns]
change: [-32.806% -32.630% -32.470%] (p = 0.00 < 0.05)
Performance has improved.
Eradicate/Detection/# this is = to that :(
time: [72.659 ns 73.068 ns 73.473 ns]
change: [-68.884% -68.775% -68.655%] (p = 0.00 < 0.05)
Performance has improved.
Found 9 outliers among 100 measurements (9.00%)
7 (7.00%) high mild
2 (2.00%) high severe
Eradicate/Detection/#except Exception:
time: [92.063 ns 92.366 ns 92.691 ns]
change: [-64.204% -64.052% -63.909%] (p = 0.00 < 0.05)
Performance has improved.
Found 4 outliers among 100 measurements (4.00%)
2 (2.00%) high mild
2 (2.00%) high severe
Eradicate/Detection/#print(1)
time: [68.359 ns 68.537 ns 68.725 ns]
change: [-72.424% -72.356% -72.278%] (p = 0.00 < 0.05)
Performance has improved.
Found 2 outliers among 100 measurements (2.00%)
1 (1.00%) low mild
1 (1.00%) high mild
Eradicate/Detection/#'key': 1 + 1,
time: [79.604 ns 79.865 ns 80.135 ns]
change: [-69.787% -69.667% -69.549%] (p = 0.00 < 0.05)
Performance has improved.
```
## Summary
The parser now uses the raw source code as global context and slices
into it to parse debug text. It turns out we were always passing in the
_old_ source code, so when code was fixed, we were making invalid
accesses. This PR modifies the call to use the _fixed_ source code,
which will always be consistent with the tokens.
Closes https://github.com/astral-sh/ruff/issues/7711.
## Test Plan
`cargo test`
## Summary
This wasn't necessary in the past, since we _only_ applied this rule to
bodies that contained two statements, one of which was a `pass`. Now
that it applies to any `pass` in a block with multiple statements, we
can run into situations in which we remove both passes, and so need to
apply the fixes in isolation.
See:
https://github.com/astral-sh/ruff/issues/7455#issuecomment-1741107573.
## Summary
The markdown documentation was present, but in the wrong place, so was
not displaying on the website. I moved it and added some references.
Related to #2646.
## Test Plan
`python scripts/check_docs_formatted.py`
Previously attempted to repair these tests at
https://github.com/astral-sh/ruff/pull/6992 but I don't think we should
prioritize that and instead I would like to remove this dead code.
## Summary
Extend `unnecessary-pass` (`PIE790`) to trigger on all unnecessary
`pass` statements by checking for `pass` statements in any class or
function body with more than one statement.
Closes#7600.
## Test Plan
`cargo test`
Part of #1646.
## Summary
Implement `S505`
([`weak_cryptographic_key`](https://bandit.readthedocs.io/en/latest/plugins/b505_weak_cryptographic_key.html))
rule from `bandit`.
For this rule, `bandit` [reports the issue
with](https://github.com/PyCQA/bandit/blob/1.7.5/bandit/plugins/weak_cryptographic_key.py#L47-L56):
- medium severity for DSA/RSA < 2048 bits and EC < 224 bits
- high severity for DSA/RSA < 1024 bits and EC < 160 bits
Since Ruff does not handle severities for `bandit`-related rules, we
could either report the issue if we have lower values than medium
severity, or lower values than high one. Two reasons led me to choose
the first option:
- a medium severity issue is still a security issue we would want to
report to the user, who can then decide to either handle the issue or
ignore it
- `bandit` [maps the EC key algorithms to their respective key lengths
in
bits](https://github.com/PyCQA/bandit/blob/1.7.5/bandit/plugins/weak_cryptographic_key.py#L112-L133),
but there is no value below 160 bits, so technically `bandit` would
never report medium severity issues for EC keys, only high ones
Another consideration is that as shared just above, for EC key
algorithms, `bandit` has a mapping to map the algorithms to their
respective key lengths. In the implementation in Ruff, I rather went
with an explicit list of EC algorithms known to be vulnerable (which
would thus be reported) rather than implementing a mapping to retrieve
the associated key length and comparing it with the minimum value.
## Test Plan
Snapshot tests from
https://github.com/PyCQA/bandit/blob/1.7.5/examples/weak_cryptographic_key_sizes.py.
## Summary
Extend the `task-tags` checking logic to ignore TODO tags (with or
without parentheses). For example,
```python
# TODO(tjkuson): Rewrite in Rust
```
is no longer flagged as commented-out code.
Closes#7031.
I also updated the documentation to inform users that the rule is prone
to false positives like this!
EDIT: Accidentally linked to the wrong issue when first opening this PR,
now corrected.
## Test Plan
`cargo test`
## Summary
When lexing a number like `0x995DC9BBDF1939FA` that exceeds our small
number representation, we were only storing the portion after the base
(in this case, `995DC9BBDF1939FA`). When using that representation in
code generation, this could lead to invalid syntax, since
`995DC9BBDF1939FA)` on its own is not a valid integer.
This PR modifies the code to store the full span, including the radix
prefix.
See:
https://github.com/astral-sh/ruff/issues/7455#issuecomment-1739802958.
## Test Plan
`cargo test`
Closes#7434
Replaces the `PREVIEW` selector (removed in #7389) with a configuration
option `explicit-preview-rules` which requires selectors to use exact
rule codes for all preview rules. This allows users to enable preview
without opting into all preview rules at once.
## Test plan
Unit tests
## Summary
At present, `quote-style` is used universally. However, [PEP
8](https://peps.python.org/pep-0008/) and [PEP
257](https://peps.python.org/pep-0257/) suggest that while either single
or double quotes are acceptable in general (as long as they're
consistent), docstrings and triple-quoted strings should always use
double quotes. In our research, the vast majority of Ruff users that
enable the `flake8-quotes` rules only enable them for inline strings
(i.e., non-triple-quoted strings).
Additionally, many Black forks (like Blue and Pyink) use double quotes
for docstrings and triple-quoted strings.
Our decision for now is to always prefer double quotes for triple-quoted
strings (which should include docstrings). Based on feedback, we may
consider adding additional options (e.g., a `"preserve"` mode, to avoid
changing quotes; or a `"multiline-quote-style"` to override this).
Closes https://github.com/astral-sh/ruff/issues/7615.
## Test Plan
`cargo test`
## Summary
Extends the pragma comment detection in the formatter to support
case-insensitive `noqa` (as supposed by Ruff), plus a variety of other
pragmas (`isort:`, `nosec`, etc.).
Also extracts the detection out into the trivia crate so that we can
reuse it in the linter (see:
https://github.com/astral-sh/ruff/issues/7471).
## Test Plan
`cargo test`
## Summary
No-op refactor, but we can evaluate early if the first part of
`preserve_parentheses || has_comments` is `true`, and thus avoid looking
up the node comments.
## Test Plan
`cargo test`
## Summary
The formatting for tuple patterns is now intended to match that of `for`
loops:
- Always parenthesize single-element tuples.
- Don't break on the trailing comma in single-element tuples.
- For other tuples, preserve the parentheses, and insert if-breaks.
Closes https://github.com/astral-sh/ruff/issues/7681.
## Test Plan
`cargo test`
## Summary
`PGH002`, which checks for use of deprecated `logging.warn` calls, did
not check for calls made on the attribute `warn` yet. Since
https://github.com/astral-sh/ruff/pull/7521 we check both cases for
similar rules wherever possible. To be consistent this PR expands PGH002
to do the same.
## Test Plan
Expanded existing fixtures with `logger.warn()` calls
## Issue links
Fixes final inconsistency mentioned in
https://github.com/astral-sh/ruff/issues/7502
## Summary
As we bind the `ast::ExprCall` in the big `match expr` in
`expression.rs`
```rust
Expr::Call(
call @ ast::ExprCall {
...
```
There is no need for additional `let/if let` checks on `ExprCall` in
downstream rules. Found a few older rules which still did this while
working on something else. This PR removes the redundant check from
these rules.
## Test Plan
`cargo test`
## Summary
It's common practice to name derive macros the same as the trait that they implement (`Debug`, `Display`, `Eq`, `Serialize`, ...).
This PR renames the `ConfigurationOptions` derive macro to `OptionsMetadata` to match the trait name.
## Test Plan
`cargo build`
## Summary
This PR adds a new `lint` section to the configuration that groups all linter-specific settings. The existing top-level configurations continue to work without any warning because the `lint.*` settings are experimental.
The configuration merges the top level and `lint.*` settings where the settings in `lint` have higher precedence (override the top-level settings). The reasoning behind this is that the settings in `lint.` are more specific and more specific settings should override less specific settings.
I decided against showing the new `lint.*` options on our website because it would make the page extremely long (it's technically easy to do, just attribute `lint` with `[option_group`]). We may want to explore adding an `alias` field to the `option` attribute and show the alias on the website along with its regular name.
## Test Plan
* I added new integration tests
* I verified that the generated `options.md` is identical
* Verified the default settings in the playground
## Summary
This PR adds support for named expressions when analyzing `__all__`
assignments, as per https://github.com/astral-sh/ruff/issues/7672. It
also loosens the enforcement around assignments like: `__all__ =
list(some_other_expression)`. We shouldn't flag these as invalid, even
though we can't analyze the members, since we _know_ they evaluate to a
`list`.
Closes https://github.com/astral-sh/ruff/issues/7672.
## Test Plan
`cargo test`
## Summary
Fixes#7616 by ensuring that
[B006](https://docs.astral.sh/ruff/rules/mutable-argument-default/#mutable-argument-default-b006)
fixes are inserted after module imports.
I have created a new test file, `B006_5.py`. This is mainly because I
have been working on this on and off, and the merge conflicts were
easier to handle in a separate file. If needed, I can move it into
another file.
## Test Plan
`cargo test`
## Summary
Expands several rules to also check for `Expr::Name` values. As they
would previously not consider:
```python
from logging import error
error("foo")
```
as potential violations
```python
import logging
logging.error("foo")
```
as potential violations leading to inconsistent behaviour.
The rules impacted are:
- `BLE001`
- `TRY400`
- `TRY401`
- `PLE1205`
- `PLE1206`
- `LOG007`
- `G001`-`G004`
- `G101`
- `G201`
- `G202`
## Test Plan
Fixtures for all impacted rules expanded.
## Issue Link
Refers: https://github.com/astral-sh/ruff/issues/7502
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
The note about rules being in preview was not being displayed for legacy
nursery rules.
Adds a link to the new preview documentation as well.
## Test Plan
<!-- How was it tested? -->
Built locally and checked a nursery rule e.g.
http://127.0.0.1:8000/ruff/rules/no-indented-block-comment/
## Summary
Pass around a `Settings` struct instead of individual members to
simplify function signatures and to make it easier to add new settings.
This PR was suggested in [this
comment](https://github.com/astral-sh/ruff/issues/1567#issuecomment-1734182803).
## Note on the choices
I chose which functions to modify based on which seem most likely to use
new settings, but suggestions on my choices are welcome!
## Summary
This PR fixes the bug where the cell indices displayed in the `--diff` output
and the ones in the normal output were different. This was due to the fact that
the `--diff` output was using the `enumerate` function to iterate over
the cells which starts at 0.
## Test Plan
Ran the following command with and without the `--diff` flag:
```console
cargo run --bin ruff -- check --no-cache --isolated ~/playground/ruff/notebooks/test.ipynb
```
### `main`
<details><summary>Diagnostics output:</summary>
<p>
```console
$ cargo run --bin ruff -- check --no-cache --isolated ~/playground/ruff/notebooks/test.ipynb
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 3:2:8: F401 [*] `math` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5:1:8: F811 Redefinition of unused `random` from line 1
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5:2:8: F401 [*] `pprint` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6:2:4: F632 [*] Use `==` to compare constant literals
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6:3:38: F632 [*] Use `==` to compare constant literals
Found 5 errors.
[*] 4 potentially fixable with the --fix option.
```
</p>
</details>
<details><summary>Diff output:</summary>
<p>
```console
$ cargo run --bin ruff -- check --no-cache --isolated ~/playground/ruff/notebooks/test.ipynb --diff
--- /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 2
+++ /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 2
@@ -1,2 +1 @@
-import random
-import math
+import random
--- /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 4
+++ /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 4
@@ -1,4 +1,3 @@
import random
-import pprint
random.randint(10, 20)
--- /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5
+++ /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5
@@ -1,3 +1,3 @@
foo = 1
-if foo is 2:
- raise ValueError(f"Invalid foo: {foo is 1}")
+if foo == 2:
+ raise ValueError(f"Invalid foo: {foo == 1}")
Would fix 4 errors.
```
</p>
</details>
### `dhruv/consistent-cell-indices`
<details><summary>Diagnostic output:</summary>
<p>
```console
$ cargo run --bin ruff -- check --no-cache --isolated ~/playground/ruff/notebooks/test.ipynb
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 3:2:8: F401 [*] `math` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5:1:8: F811 Redefinition of unused `random` from line 1
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5:2:8: F401 [*] `pprint` imported but unused
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6:2:4: F632 [*] Use `==` to compare constant literals
/Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6:3:38: F632 [*] Use `==` to compare constant literals
Found 5 errors.
[*] 4 potentially fixable with the --fix option.
```
</p>
</details>
<details><summary>Diff output:</summary>
<p>
```console
$ cargo run --bin ruff -- check --no-cache --isolated ~/playground/ruff/notebooks/test.ipynb --diff
--- /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 3
+++ /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 3
@@ -1,2 +1 @@
-import random
-import math
+import random
--- /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5
+++ /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 5
@@ -1,4 +1,3 @@
import random
-import pprint
random.randint(10, 20)
--- /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6
+++ /Users/dhruv/playground/ruff/notebooks/test.ipynb:cell 6
@@ -1,3 +1,3 @@
foo = 1
-if foo is 2:
- raise ValueError(f"Invalid foo: {foo is 1}")
+if foo == 2:
+ raise ValueError(f"Invalid foo: {foo == 1}")
Would fix 4 errors.
```
</p>
</details>
fixes: #6673
I got confused and refactored a bit, now the naming should be more
consistent. This is the basis for the range formatting work.
Chages:
* `format_module` -> `format_module_source` (format a string)
* `format_node` -> `format_module_ast` (format a program parsed into an
AST)
* Added `parse_ok_tokens` that takes `Token` instead of `Result<Token>`
* Call the source code `source` consistently
* Added a `tokens_and_ranges` helper
* `python_ast` -> `module` (because that's the type)
**Summary** Check that `closefd` and `opener` aren't being used with
`builtin.open()` before suggesting `Path.open()` because pathlib doesn't
support these arguments.
Closes#7620
**Test Plan** New cases in the fixture.
## Summary
This is a follow-up to #7469 that attempts to achieve similar gains, but
without introducing malachite. Instead, this PR removes the `BigInt`
type altogether, instead opting for a simple enum that allows us to
store small integers directly and only allocate for values greater than
`i64`:
```rust
/// A Python integer literal. Represents both small (fits in an `i64`) and large integers.
#[derive(Clone, PartialEq, Eq, Hash)]
pub struct Int(Number);
#[derive(Debug, Clone, PartialEq, Eq, Hash)]
pub enum Number {
/// A "small" number that can be represented as an `i64`.
Small(i64),
/// A "large" number that cannot be represented as an `i64`.
Big(Box<str>),
}
impl std::fmt::Display for Number {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
Number::Small(value) => write!(f, "{value}"),
Number::Big(value) => write!(f, "{value}"),
}
}
}
```
We typically don't care about numbers greater than `isize` -- our only
uses are comparisons against small constants (like `1`, `2`, `3`, etc.),
so there's no real loss of information, except in one or two rules where
we're now a little more conservative (with the worst-case being that we
don't flag, e.g., an `itertools.pairwise` that uses an extremely large
value for the slice start constant). For simplicity, a few diagnostics
now show a dedicated message when they see integers that are out of the
supported range (e.g., `outdated-version-block`).
An additional benefit here is that we get to remove a few dependencies,
especially `num-bigint`.
## Test Plan
`cargo test`
## Summary
This is whitespace as per `is_python_whitespace`, and right now it tends
to lead to panics in the formatter. Seems reasonable to treat it as
whitespace in the `SimpleTokenizer` too.
Closes .https://github.com/astral-sh/ruff/issues/7624.
## Summary
Given:
```python
if True:
if True:
pass
else:
pass
# a
# b
# c
else:
pass
```
We want to preserve the newline after the `# c` (before the `else`).
However, the `last_node` ends at the `pass`, and the comments are
trailing comments on the `pass`, not trailing comments on the
`last_node` (the `if`). As such, when counting the trailing newlines on
the outer `if`, we abort as soon as we see the comment (`# a`).
This PR changes the logic to skip _all_ comments (even those with
newlines between them). This is safe as we know that there are no
"leading" comments on the `else`, so there's no risk of skipping those
accidentally.
Closes https://github.com/astral-sh/ruff/issues/7602.
## Test Plan
No change in compatibility.
Before:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1631 |
| django | 0.99983 | 2760 | 36 |
| transformers | 0.99963 | 2587 | 319 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99979 | 3496 | 22 |
| warehouse | 0.99967 | 648 | 15 |
| zulip | 0.99972 | 1437 | 21 |
After:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1631 |
| django | 0.99983 | 2760 | 36 |
| transformers | 0.99963 | 2587 | 319 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99983 | 3496 | 18 |
| warehouse | 0.99967 | 648 | 15 |
| zulip | 0.99972 | 1437 | 21 |
## Summary
This PR fixes the autofix behavior for `PT022` to create an additional
edit for the return type if it's present. The edit will update the
return type from `Generator[T, ...]` to `T`. As per the [official
documentation](https://docs.python.org/3/library/typing.html?highlight=typing%20generator#typing.Generator),
the first position is the yield type, so we can ignore other positions.
```python
typing.Generator[YieldType, SendType, ReturnType]
```
## Test Plan
Add new test cases, `cargo test` and review the snapshots.
fixes: #7610
## Summary
Implement
[`simplify-print`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/print.py)
as `print-empty-string` (`FURB105`).
Extends the original rule in that it also checks for multiple empty
string positional arguments with an empty string separator.
Related to #1348.
## Test Plan
`cargo test`
Similar to tuples, a generator _can_ be parenthesized or
unparenthesized. Only search for bracketed comments if it contains its
own parentheses.
Closes https://github.com/astral-sh/ruff/issues/7623.
## Summary
Given:
```python
if True:
if True:
if True:
pass
#a
#b
#c
else:
pass
```
When determining the placement of the various comments, we compute the
indentation depth of each comment, and then compare it to the depth of
the previous statement. It turns out this can lead to reordering
comments, e.g., above, `#b` is assigned as a trailing comment of `pass`,
and so gets reordered above `#a`.
This PR modifies the logic such that when we compute the indentation
depth of `#b`, we limit it to at most the indentation depth of `#a`. In
other words, when analyzing comments at the end of branches, we don't
let successive comments go any _deeper_ than their preceding comments.
Closes https://github.com/astral-sh/ruff/issues/7602.
## Test Plan
`cargo test`
No change in similarity.
Before:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1631 |
| django | 0.99983 | 2760 | 36 |
| transformers | 0.99963 | 2587 | 319 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99979 | 3496 | 22 |
| warehouse | 0.99967 | 648 | 15 |
| zulip | 0.99972 | 1437 | 21 |
After:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1631 |
| django | 0.99983 | 2760 | 36 |
| transformers | 0.99963 | 2587 | 319 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99979 | 3496 | 22 |
| warehouse | 0.99967 | 648 | 15 |
| zulip | 0.99972 | 1437 | 21 |
## Summary
Given:
```python
# -*- coding: utf-8 -*-
import random
# Defaults for arguments are defined here
# args.threshold = None;
logger = logging.getLogger("FastProject")
```
We want to count the number of newlines after `import random`, to ensure
that there's _at least one_, but up to two.
Previously, we used the end range of the statement (then skipped
trivia); instead, we need to use the end of the _last comment_. This is
similar to #7556.
Closes https://github.com/astral-sh/ruff/issues/7604.
## Summary
B005 only flags `.strip()` calls for which the argument includes
duplicate characters. This is consistent with bugbear, but isn't
explained in the documentation.
## Summary
Currently, this happens
```sh
$ echo "print()" | ruff format -
#Notice that nothing went to stdout
```
Which does not match `ruff check --fix - ` behavior and deletes my code
every time I format it (more or less 5 times per minute 😄).
I just checked that my example works as the change was very
straightforward.
It is apparently possible to add files to the git index, even if they
are part of the gitignore (see e.g.
https://stackoverflow.com/questions/45400361/why-is-gitignore-not-ignoring-my-files,
even though it's strange that the gitignore entries existed before the
files were added, i wouldn't know how to get them added in that case). I
ran
```
git rm -r --cached .
```
then change the gitignore not actually ignore those files with the
exception of
`crates/ruff_cli/resources/test/fixtures/cache_mutable/source.py`, which
is actually a generated file.
## Summary
This is only used for the `level` field in relative imports (e.g., `from
..foo import bar`). It seems unnecessary to use a wrapper here, so this
PR changes to a `u32` directly.
## Summary
When we format the trailing comments on a clause body, we check if there
are any newlines after the last statement; if not, we insert one.
This logic didn't take into account that the last statement could itself
have trailing comments, as in:
```python
if True:
pass
# comment
else:
pass
```
We were thus inserting a newline after the comment, like:
```python
if True:
pass
# comment
else:
pass
```
In the context of function definitions, this led to an instability,
since we insert a newline _after_ a function, which would in turn lead
to the bug above appearing in the second formatting pass.
Closes https://github.com/astral-sh/ruff/issues/7465.
## Test Plan
`cargo test`
Small improvement in `transformers`, but no regressions.
Before:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1631 |
| django | 0.99983 | 2760 | 36 |
| transformers | 0.99956 | 2587 | 404 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99983 | 3496 | 18 |
| warehouse | 0.99967 | 648 | 15 |
| zulip | 0.99972 | 1437 | 21 |
After:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1631 |
| django | 0.99983 | 2760 | 36 |
| **transformers** | **0.99957** | **2587** | **402** |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99983 | 3496 | 18 |
| warehouse | 0.99967 | 648 | 15 |
| zulip | 0.99972 | 1437 | 21 |
## Summary
If a function has no parameters (and no comments within the parameters'
`()`), we're supposed to wrap the return annotation _whenever_ it
breaks. However, our `empty_parameters` test didn't properly account for
the case in which the parameters include a newline (but no other
content), like:
```python
def get_dashboards_hierarchy(
) -> Dict[Type['BaseDashboard'], List[Type['BaseDashboard']]]:
"""Get hierarchy of dashboards classes.
Returns:
Dict of dashboards classes.
"""
dashboards_hierarchy = {}
```
This PR fixes that detection. Instead of lexing, it now checks if the
parameters itself is empty (or if it contains comments).
Closes https://github.com/astral-sh/ruff/issues/7457.
## Summary
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR moves the `ResolverSettings` and `Settings` struct to `ruff_workspace`. `LinterSettings` remains in `ruff_linter` because it gets passed to lint rules, the `Checker` etc.
## Test Plan
`cargo test`
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR extracts the linter-specific settings into a new `LinterSettings` struct and adds it as a `linter` field to the `Settings` struct. This is in preparation for moving `Settings` from `ruff_linter` to `ruff_workspace`
## Test Plan
`cargo test`
## Stack Summary
This stack splits `Settings` into `FormatterSettings` and `LinterSettings` and moves it into `ruff_workspace`. This change is necessary to add the `FormatterSettings` to `Settings` without adding `ruff_python_formatter` as a dependency to `ruff_linter` (and the linter should not contain the formatter settings).
A quick overview of our settings struct at play:
* `Options`: 1:1 representation of the options in the `pyproject.toml` or `ruff.toml`. Used for deserialization.
* `Configuration`: Resolved `Options`, potentially merged from multiple configurations (when using `extend`). The representation is very close if not identical to the `Options`.
* `Settings`: The resolved configuration that uses a data format optimized for reading. Optional fields are initialized with their default values. Initialized by `Configuration::into_settings` .
The goal of this stack is to split `Settings` into tool-specific resolved `Settings` that are independent of each other. This comes at the advantage that the individual crates don't need to know anything about the other tools. The downside is that information gets duplicated between `Settings`. Right now the duplication is minimal (`line-length`, `tab-width`) but we may need to come up with a solution if more expensive data needs sharing.
This stack focuses on `Settings`. Splitting `Configuration` into some smaller structs is something I'll follow up on later.
## PR Summary
This PR extracts a `ResolverSettings` struct that holds all the resolver-relevant fields (uninteresting for the `Formatter` or `Linter`). This will allow us to move the `ResolverSettings` out of `ruff_linter` further up in the stack.
## Test Plan
`cargo test`
(I'll to more extensive testing at the top of this stack)
## Summary
This PR fixes the way NoQA range is inserted to the `NoqaMapping`.
Previously, the way the mapping insertion logic worked was as follows:
1. If the range which is to be inserted _touched_ the previous range, meaning
that the end of the previous range was the same as the start of the new
range, then the new range was added in addition to the previous range.
2. Else, if the new range intersected the previous range, then the previous
range was replaced with the new _intersection_ of the two ranges.
The problem with this logic is that it does not work for the following case:
```python
assert foo, \
"""multi-line
string"""
```
Now, the comments cannot be added to the same line which ends with a continuation
character. So, the `NoQA` directive has to be added to the next line. But, the
next line is also a triple-quoted string, so the `NoQA` directive for that line
needs to be added to the next line. This creates a **union** pattern instead of an
**intersection** pattern.
But, only union doesn't suffice because (1) means that for the edge case where
the range touch only at the end, the union won't take place.
### Solution
1. Replace '<=' with '<' to have a _strict_ insertion case
2. Use union instead of intersection
## Test Plan
Add a new test case. Run the test suite to ensure that nothing is broken.
### Integration
1. Make a `test.py` file with the following contents:
```python
assert foo, \
"""multi-line
string"""
```
2. Run the following command:
```console
$ cargo run --bin ruff -- check --isolated --no-cache --select=F821 test.py
/Users/dhruv/playground/ruff/fstring.py:1:8: F821 Undefined name `foo`
Found 1 error.
```
3. Use `--add-noqa`:
```console
$ cargo run --bin ruff -- check --isolated --no-cache --select=F821 --add-noqa test.py
Added 1 noqa directive.
```
4. Check that the NoQA directive was added in the correct position:
```python
assert foo, \
"""multi-line
string""" # noqa: F821
```
5. Run the `check` command to ensure that the NoQA directive is respected:
```console
$ cargo run --bin ruff -- check --isolated --no-cache --select=F821 test.py
```
fixes: #7530
## Summary
Implement
[`no-ignored-enumerate-items`](https://github.com/dosisod/refurb/blob/master/refurb/checks/builtin/no_ignored_enumerate.py)
as `unnecessary-enumerate` (`FURB148`).
The auto-fix considers if a `start` argument is passed to the
`enumerate()` function. If only the index is used, then the suggested
fix is to pass the `start` value to the `range()` function. So,
```python
for i, _ in enumerate(xs, 1):
...
```
becomes
```python
for i in range(1, len(xs)):
...
```
If the index is ignored and only the value is ignored, and if a start
value greater than zero is passed to `enumerate()`, the rule doesn't
produce a suggestion. I couldn't find a unanimously accepted best way to
iterate over a collection whilst skipping the first n elements. The rule
still triggers, however.
Related to #1348.
## Test Plan
`cargo test`
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
**Summary** Instead of emitting a bogus token per char, we now only emit
on single last bogus token. This leads to much more concise output.
**Test Plan** Updated fixtures
Closes#5497
Needs MkDocs 1.5 to be released.
- [x] https://github.com/mkdocs/mkdocs/milestone/15
## Summary
Uses MkDocs' `not_in_nav` config to hide spam about files in
`docs/rules/` not being in nav.
Close#7479
The `@override` was already implemented
## Test Plan
Tested the code in the issue. After removing all the noqa's, only one
occurrence of `BadName()` raised a violation.
Added a fixture
## Summary
This PR implements a new rule for `flake8-logging` plugin that checks
for uses of `logging.exception()` with `exc_info` set to `False` or a
falsy value. It suggests using `logging.error` in these cases instead.
I am unsure about the name. Open to suggestions there, went with the
most explicit name I could think of in the meantime.
Refer https://github.com/astral-sh/ruff/issues/7248
## Test Plan
Added a new fixture cases and ran `cargo test`
## Summary
This PR updates the `W191` (`tab-indentation`) rule from a line-based to
a token-based rule.
Earlier, the rule used the `triple_quoted_string_ranges` from the
indexer to skip over any lines _inside_ a triple-quoted string. This was the only
use of the ranges. These ranges were extracted through the tokens, so instead
we can directly use the newline tokens to perform the check.
This would also mean that we can remove the `triple_quoted_string_ranges` from
the indexer but I'll hold that off until we have a better idea on #7326
but I don't think it would be a problem to remove it.
This will also fix#7379 once PEP 701 changes are merged.
## Test Plan
`cargo test`
## Summary
This PR implements a new rule for `flake8-logging` plugin that checks
for
`logging.getLogger` calls with either `__file__` or `__cached__` as the
first
argument and generates a suggested fix to use `__name__` instead.
Refer: #7248
## Test Plan
Add test cases and `cargo test`
## Summary
The tokenizer was split into a forward and a backwards tokenizer. The
backwards tokenizer uses the same names as the forwards ones (e.g.
`next_token`). The backwards tokenizer gets the comment ranges that we
already built to skip comments.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
We're planning to move the documentation from
[https://beta.ruff.rs/docs](https://beta.ruff.rs/docs) to
[https://docs.astral.sh/ruff](https://docs.astral.sh/ruff), for a few
reasons:
1. We want to remove the `beta` from the domain, as Ruff is no longer
considered beta software.
2. We want to migrate to a structure that could accommodate multiple
future tools living under one domain.
The docs are actually already live at
[https://docs.astral.sh/ruff](https://docs.astral.sh/ruff), but later
today, I'll add a permanent redirect from the previous to the new
domain. **All existing links will continue to work, now and in
perpetuity.**
This PR contains the code changes necessary for the updated
documentation. As part of this effort, I moved the playground and
documentation from my personal Cloudflare account to our team Cloudflare
account (hence the new `--project-name` references). After merging, I'll
also update the secrets on this repo.
## Summary
Given a trailing operator comment in a unary expression, like:
```python
if (
not # comment
a):
...
```
We were attaching these to the operand (`a`), but formatting them in the
unary operator via special handling. Parents shouldn't format the
comments of their children, so this instead attaches them as dangling
comments on the unary expression. (No intended change in formatting.)
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Adds the maximum of 320 for the line-length setting to the JSON schema
for better integration with IDEs.
Related https://github.com/astral-sh/ruff/pull/6873
## Test Plan
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
The previous reference was “CWE-78: Improper Neutralization of Special
Elements used in an OS Command ('OS Command Injection')”, which
describes another issue. The new reference is “CWE-426: Untrusted Search
Path”, which describes exactly the problem that this rule should warn
about.
## Test Plan
The change was not tested, as it only changes two numbers in the
documentation.
## Summary
Adds `LOG009` from
[flake8-logging](https://github.com/adamchainz/flake8-logging). Also
adds the boilerplate for a new plugin
Checks for usages of undocumented `logging.WARN` constant and suggests
replacement with `logging.WARNING`.
## Test Plan
`cargo test` with fresh fixture
## Issue links
Refers: https://github.com/astral-sh/ruff/issues/7248
## Summary
Extends UP040 to support moving type variables with
bounds/constraints/variance that are used in type aliases to use PEP-695
syntax.
Part of #4617.
## Test Plan
The existing tests added by #6314 already cover the relevant cases.
Rules like D209 and D205 are only intended to apply to multi-line
docstrings. If a docstring is single-quoted, but extends via a
continuation, it should be excluded (it'll be flagged by another rule
anyway). Closes https://github.com/astral-sh/ruff/issues/7058.
## Summary
At some point, we removed these so that they wouldn't be autocompleted
for users, since we wanted to discourage usage of `ALL`. But given that
they're valid values, I think that was a bad idea -- it leads to an even
more confusing experience whereby JSON Schema validators tell you that
you have an error, when you don't.
Closes https://github.com/astral-sh/ruff/issues/7261.
The rule selector is not useful because `--select PREVIEW` only targets
Ruff developers and `--ignore PREVIEW` has no effect due to its low
specificity. We may restore it later if useful.
`ComparableExpr` includes the `ExprContext` field on an expression, so,
e.g., the two tuples in `(a, b) = (a, b)` won't be considered equal.
Similarly, the tuples in `[(a, b) for (a, b) in c]` _also_ wouldn't be
considered equal. I find this behavior surprising, since
`ComparableExpr` is intended to allow you to compare two ASTs, but
`ExprContext` is really encoding information about the broader context
for the expression.
Bumps [shlex](https://github.com/comex/rust-shlex) from 1.1.0 to 1.2.0.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/comex/rust-shlex/blob/master/CHANGELOG.md">shlex's
changelog</a>.</em></p>
<blockquote>
<h1>1.2.0</h1>
<ul>
<li>Adds <code>bytes</code> module to support operating directly on byte
strings.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/comex/rust-shlex/commits">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Given a statement like:
```python
result = (
f(111111111111111111111111111111111111111111111111111111111111111111111111111111111)
+ 1
)()
```
When we go to parenthesize the target of the assignment, we use
`maybe_parenthesize_expression` with `Parenthesize::IfBreaks`. This then
checks if the call on the right-hand side needs to be parenthesized, the
implementation of which looks like:
```rust
impl NeedsParentheses for ExprCall {
fn needs_parentheses(
&self,
_parent: AnyNodeRef,
context: &PyFormatContext,
) -> OptionalParentheses {
if CallChainLayout::from_expression(self.into(), context.source())
== CallChainLayout::Fluent
{
OptionalParentheses::Multiline
} else if context.comments().has_dangling(self) {
OptionalParentheses::Always
} else {
self.func.needs_parentheses(self.into(), context)
}
}
}
```
Checking for `self.func.needs_parentheses(self.into(), context)` is
problematic, since, as in the example above, `self.func` may _already_
be parenthesized -- in which case, we _don't_ want to parenthesize the
entire expression. If we do, we end up with this non-ideal formatting:
```python
result = (
(
f(
111111111111111111111111111111111111111111111111111111111111111111111111111111111
)
+ 1
)()
)
```
This PR modifies the `NeedsParentheses` implementations for call chain
expressions to return `Never` if the inner expression has its own
parentheses, in which case, the formatting implementations for those
expressions will preserve them anyway.
Closes https://github.com/astral-sh/ruff/issues/7370.
## Test Plan
Zulip improves a bit, everything else is unchanged.
Before:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1632 |
| django | 0.99981 | 2760 | 40 |
| transformers | 0.99944 | 2587 | 413 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99983 | 3496 | 18 |
| warehouse | 0.99834 | 648 | 20 |
| zulip | 0.99956 | 1437 | 23 |
After:
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1632 |
| django | 0.99981 | 2760 | 40 |
| transformers | 0.99944 | 2587 | 413 |
| twine | 1.00000 | 33 | 0 |
| typeshed | 0.99983 | 3496 | 18 |
| warehouse | 0.99834 | 648 | 20 |
| **zulip** | **0.99962** | **1437** | **22** |
## Summary
When fixing `reversed(sorted(x, reverse=False))`, we rewrite as
`sorted(x, reverse=True)`. However, if the `reverse` argument isn't
`True` or `False`, we leave it as-is, which is incorrect.
Now, given `reversed(sorted(x, reverse=y))`, we rewrite as `sorted(x,
reverse=not y)`.
## Summary
Adds warnings for cases where:
- A selector does not include any rules because preview is disabled
- A nursery rule is selected without the preview flag
## Test plan
Add integration tests
Moves the new rule from nursery to preview for the upcoming release.
Adds new test coverage for selection of a single preview rule and fixes
a bug where preview rules were incorrectly selectable with exact codes.
## Summary
This PR bumps the pyproject-toml crate to 0.7.0. The only difference is that it now depends on indexmap 2. I reviewed the indexmap 2 changes and they don't seem relevant to us.
I used this opportunity to remove the default features from `serde_with` which removes our indexmap 1 dependency (and some other unused dependencies)
## Test Plan
`cargo test`
## Motivation
The `ast::Arguments` for call argument are split into positional
arguments (args) and keywords arguments (keywords). We currently assume
that call consists of first args and then keywords, which is generally
the case, but not always:
```python
f(*args, a=2, *args2, **kwargs)
class A(*args, a=2, *args2, **kwargs):
pass
```
The consequence is accidentally reordering arguments
(https://github.com/astral-sh/ruff/pull/7268).
## Summary
`Arguments::args_and_keywords` returns an iterator of an `ArgOrKeyword`
enum that yields args and keywords in the correct order. I've fixed the
obvious `args` and `keywords` usages, but there might be some cases with
wrong assumptions remaining.
## Test Plan
The generator got new test cases, otherwise the stacked PR
(https://github.com/astral-sh/ruff/pull/7268) which uncovered this.
## Summary
This PR updates the `FileCache` to include an optional `NotebookIndex`
to support caching for Jupyter Notebooks.
We only require the index to compute the diagnostics and thus we don't
really need to store the entire `Notebook` on the `Diagnostics` struct.
This means we only need the index to be stored in the cache to
reconstruct the `Diagnostics`.
## Test Plan
Update an existing test case to run over the fixtures under
`ruff_notebook` crate where there are multiple Jupyter Notebook.
Locally, the following commands were run in order:
1. Remove the cache: `rm -rf .ruff_cache`
2. Run without cache: `cargo run --bin ruff -- check --isolated
crates/ruff_notebook/resources/test/fixtures/jupyter/unused_variable.ipynb
--no-cache`
3. Run with cache: `cargo run --bin ruff -- check --isolated
crates/ruff_notebook/resources/test/fixtures/jupyter/unused_variable.ipynb`
4. Check whether the `.ruff_cache` directory was created or not
5. Run with cache again and verify: `cargo run --bin ruff -- check
--isolated
crates/ruff_notebook/resources/test/fixtures/jupyter/unused_variable.ipynb`
## Benchmarks
https://github.com/astral-sh/ruff/pull/6863#issuecomment-1715675186fixes: #6671
## Summary
Closes#6958.
If a method has the `override` decorator, there is nothing you can do
about incorrect dunder methods, so they should be ignored.
## Test Plan
Overridden incorrect dunder method was added to the tests to verify ruff
doesn't catch it when evaluating the file. Snapshot changes are all just
line number changes
## Summary
This PR updates the lexer test snapshots to include the range value as
well. This is mainly a mechanical refactor.
### Motivation
The main motivation is so that we can verify that the ranges are valid
and do not overlap.
## Test Plan
`cargo test`
## Summary
This PR updates the remaining lexer test cases to use the snapshots.
This is mainly a mechanical refactor.
## Motivation
The main motivation is so that when we add the token range values to the
test case output, it's easier to update the test cases.
The reason they were not using the snapshots before was because of the usage of
`test_case` macro. The macros is mainly used for different EOL test cases. If we
just generate the snapshots directly, then the snapshot name would be suffixed
with `-1`, `-2`, etc. as the test function is still the same. So, we'll create
the snapshot ourselves with the platform name for the respective EOL
test cases.
## Test Plan
`cargo test`
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Extends work in #7046 (some relevant discussion there)
Changes:
- All nursery rules are now referred to as preview rules
- Documentation for the nursery is updated to describe preview
- Adds a "PREVIEW" selector for preview rules
- This is primarily to allow `--preview --ignore PREVIEW --extend-select
FOO001,BAR200`
- Using `--preview` enables preview rules that match selectors
Notable decisions:
- Preview rules are not selectable by their rule code without enabling
preview
- Retains the "NURSERY" selector for backwards compatibility
- Nursery rules are selectable by their rule code for backwards
compatiblity
Additional work:
- Selection of preview rules without the "--preview" flag should display
a warning
- Use of deprecated nursery selection behavior should display a warning
- Nursery selection should be removed after some time
## Test Plan
<!-- How was it tested? -->
Manual confirmation (i.e. we don't have an preview rules yet just
nursery rules so I added a preview rule for manual testing)
New unit tests
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Another statement on the same line as the docstring would previous make
the D204 (newline after docstring) fix fail:
```python
class StatementOnSameLineAsDocstring:
"After this docstring there's another statement on the same line separated by a semicolon." ;priorities=1
def sort_services(self):
pass
```
The fix handles this case manually:
```python
class StatementOnSameLineAsDocstring:
"After this docstring there's another statement on the same line separated by a semicolon."
priorities=1
def sort_services(self):
pass
```
Fixes#7088
## Test Plan
Added a new `D` test case
## Summary
Fix all but one empty line differences with the black preview style in
typeshed. The remaining differences are breaking with type comments and
trailing commas in function definitions.
I compared the empty line differences with the preview mode of black
since stable has some oddities that would have been hard to replicate
(https://github.com/psf/black/issues/3861). Additionally, it assumes the
style proposed in https://github.com/psf/black/issues/3862.
An edge case that also surfaced with typeshed are newline before
trailing module comments.
**main**
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1632 |
| django | 0.99966 | 2760 | 58 |
| transformers | 0.99930 | 2587 | 447 |
| twine | 1.00000 | 33 | 0 |
| **typeshed** | 0.99978 | 3496 | **2173** |
| warehouse | 0.99825 | 648 | 22 |
| zulip | 0.99950 | 1437 | 27 |
**PR**
| project | similarity index | total files | changed files |
|--------------|------------------:|------------------:|------------------:|
| cpython | 0.76083 | 1789 | 1632 |
| django | 0.99966 | 2760 | 58 |
| transformers | 0.99930 | 2587 | 447 |
| twine | 1.00000 | 33 | 0 |
| **typeshed** | 0.99983 | 3496 | **18** |
| warehouse | 0.99825 | 648 | 22 |
| zulip | 0.99950 | 1437 | 27 |
Closes#6723
## Test Plan
The main driver was the typeshed diff. I added new test cases for all
kinds of possible empty line combinations in stub files, test cases for
newlines before trailing module comments.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR adds the `--preview` and `--no-preview` options to the `format` command (hidden) and passes it through to the formatte.
## Test Plan
I added the `dbg(f.options().preview())` statement in `FormatNodeRule::fmt` and verified that the option gets correctly passed to the formatter.
Show header for formatter comment decoration info
**Summary** Show a header in the formatter comment decoration debug
output that shows which node is preceding/following/enclosing
(https://github.com/astral-sh/ruff/pull/6813#issuecomment-1708119550). I
kept this intentionally condensed to make it easy to use this is a small
sidebar without vertical scrolling.
```console
$ cargo run --bin ruff_python_formatter -- --emit stdout --print-comments scratch.py
# Comment decoration: Range, Preceding, Following, Enclosing, Comment
17..20, Some((ParameterWithDefault, 6..10)), None, (Parameters, 5..22), "# a"
44..47, Some((StmtExpr, 28..39)), Some((StmtExpr, 52..60)), (StmtFunctionDef, 0..60), "# b"
77..80, None, None, (ExprList, 71..82), "# c"
{
Node {
kind: ParameterWithDefault,
range: 6..10,
source: `x=[]`,
}: {
...
```
**Test Plan** It's debug output.
**Summary** The comment visitor used to rebuild the locator for every
comment. Instead, we now keep the locator on the builder. Follow-up to
#6813.
**Test Plan** No formatting changes.
## Summary
Add a configuration option to extend the list of names that can be
accessed without triggering SLF001.
Fixes issue #7018
## Test Plan
Manually tested by creating a python file (`test.py`):
```python
def foo(obj):
obj._meta
```
and a `ruff.toml` file:
```toml
select = ["SLF"]
[flake8-self]
extend-ignore-names = ["_meta"]
```
Then running `cargo run -p ruff_cli -- check test.py --no-cache` (once
with the `extend-ignore-names` line comment out) to see if the
configuration option works.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR updates the revision of `LibCST` dependency to 9c263aa897
inorder to fix https://github.com/astral-sh/ruff/issues/4899
## Test Plan
The test case including the carriage return (`\r`) character was added for
`F504` and then `cargo test`.
fixes: #4899
If a user has `import collections, functools, operator`, and we try to
import from `functools` and `operator`, we end up adding two identical
synthetic edits to preserve that import statement. We need to dedupe
them.
Closes https://github.com/astral-sh/ruff/issues/7059.
## Summary
This PR moves `ruff/jupyter` into its own `ruff_notebook` crate. Beyond
the move itself, there were a few challenges:
1. `ruff_notebook` relies on the source map abstraction. I've moved the
source map into `ruff_diagnostics`, since it doesn't have any
dependencies on its own and is used alongside diagnostics.
2. `ruff_notebook` has a couple tests for end-to-end linting and
autofixing. I had to leave these tests in `ruff` itself.
3. We had code in `ruff/jupyter` that relied on Python lexing, in order
to provide a more targeted error message in the event that a user saves
a `.py` file with a `.ipynb` extension. I removed this in order to avoid
a dependency on the parser, it felt like it wasn't worth retaining just
for that dependency.
## Test Plan
`cargo test`
## Summary
I think the fallthrough here for some branches is a little confusing.
Now each branch either runs a command that returns `Result<ExitStatus>`,
or runs a command that returns `Result<()>` and then explicitly returns
`Ok(ExitStatus::SUCCESS)`.
## Summary
This PR refactors the error-handling cases around Jupyter notebooks to
use errors rather than `Box<Diagnostics>`, which creates some oddities
in the downstream handling. So, instead of formatting errors as
diagnostics _eagerly_ (in the notebook methods), we now return errors
and convert those errors to diagnostics at the last possible moment (in
`diagnostics.rs`). This is more ergonomic, as errors can be composed and
reported-on in different ways, whereas diagnostics require a `Printer`,
etc.
See, e.g.,
https://github.com/astral-sh/ruff/pull/7013#discussion_r1311136301.
## Test Plan
Ran `cargo run` over a Python file labeled with a `.ipynb` suffix, and
saw:
```
foo.ipynb:1:1: E999 SyntaxError: Expected a Jupyter Notebook, which must be internally stored as JSON, but found a Python source file: expected value at line 1 column 1
```
## Summary
This PR modifies our between-statement comment handling such that
comments that are not separated by a statement by any newlines continue
to be treated as leading comments on the statement, but comments that
_are_ separated are instead formatted as trailing comments on the
preceding statement.
See, e.g., the originating snippet:
```python
DEFAULT_TEMPLATE = "flatpages/default.html"
# This view is called from FlatpageFallbackMiddleware.process_response
# when a 404 is raised, which often means CsrfViewMiddleware.process_view
# has not been called even if CsrfViewMiddleware is installed. So we need
# to use @csrf_protect, in case the template needs {% csrf_token %}.
# However, we can't just wrap this view; if no matching flatpage exists,
# or a redirect is required for authentication, the 404 needs to be returned
# without any CSRF checks. Therefore, we only
# CSRF protect the internal implementation.
def flatpage(request, url):
pass
```
Here, we need to ensure that the `def flatpage` is precede by two empty
lines. However, we want those two empty lines to be enforced from the
_end_ of the comment block, _unless_ the comments are directly atop the
`def flatpage`.
I played with this a bit, and I think the simplest conceptual model and
implementation is to instead treat those as trailing comments on the
preceding node. The main difficulty with this approach is that, in order
to be fully compatible with Black, we'd sometimes need to insert
newlines _between_ the preceding node and its trailing comments. See,
e.g.:
```python
def func():
...
# comment
x = 1
```
In this case, we'd need to insert two blank lines between `def func():
...` and `# comment`, but `# comment` is trailing comment on `def
func(): ...`. So, we'd need to take this case into account in the
various nodes that _require_ newlines after them: functions, classes,
and imports. After some discussion, we've opted _not_ to support this,
and just treat these as trailing comments -- so we won't insert newlines
there. This means our handling is still identical to Black's on
Black-formatted code, but avoids moving such trailing comments on
unformatted code.
I dislike that the empty handling is so complex, and that it's split
between so many different nodes, but this is really tricky. Continuing
to treat these as leading comments is very difficult too, since we'd
need to do similar tricks for the leading comment handling in those
nodes, and influencing leading comments is even harder, since they're
all formatted _before_ the node itself.
Closes https://github.com/astral-sh/ruff/issues/6761.
## Test Plan
`cargo test`
Surprisingly, it doesn't change the similarity at all (apart from a
0.00001 change in CPython), but I manually confirmed that it did fix the
originating issue in Django.
Before:
| project | similarity index |
|--------------|------------------|
| cpython | 0.76082 |
| django | 0.99921 |
| transformers | 0.99854 |
| twine | 0.99982 |
| typeshed | 0.99953 |
| warehouse | 0.99648 |
| zulip | 0.99928 |
After:
| project | similarity index |
|--------------|------------------|
| cpython | 0.76081 |
| django | 0.99921 |
| transformers | 0.99854 |
| twine | 0.99982 |
| typeshed | 0.99953 |
| warehouse | 0.99648 |
| zulip | 0.99928 |
## Summary
This PR modifies a few of our rules related to which statements (and how
many) are allowed in function bodies within `.pyi` files, to improve
compatibility with flake8-pyi and improve the interplay dynamics between
them. Each change fixes a deviation from flake8-pyi:
- We now always trigger the multi-statement rule (PYI048) regardless of
whether one of the statements is a docstring.
- We no longer trigger the `...` rule (PYI010) if the single statement
is a docstring or a `pass` (since those are covered by other rules).
- We no longer trigger the `...` rule (PYI010) if the function body
contains multiple statements (since that's covered by PYI048).
Closes https://github.com/astral-sh/ruff/issues/7021.
## Test Plan
`cargo test`
## Summary
This PR attempts to address a problem in the parser related to the
range's of `WithItem` nodes in certain contexts -- specifically,
`WithItem` nodes in parentheses that do not have an `as` token after
them.
For example,
[here](https://play.ruff.rs/71be2d0b-2a04-4c7e-9082-e72bff152679):
```python
with (a, b):
pass
```
The range of the `WithItem` `a` is set to the range of `(a, b)`, as is
the range of the `WithItem` `b`. In other words, when we have this kind
of sequence, we use the range of the entire parenthesized context,
rather than the ranges of the items themselves.
Note that this also applies to cases
[like](https://play.ruff.rs/c551e8e9-c3db-4b74-8cc6-7c4e3bf3713a):
```python
with (a, b, c as d):
pass
```
You can see the issue in the parser here:
```rust
#[inline]
WithItemsNoAs: Vec<ast::WithItem> = {
<location:@L> <all:OneOrMore<Test<"all">>> <end_location:@R> => {
all.into_iter().map(|context_expr| ast::WithItem { context_expr, optional_vars: None, range: (location..end_location).into() }).collect()
},
}
```
Fixing this issue is... very tricky. The naive approach is to use the
range of the `context_expr` as the range for the `WithItem`, but that
range will be incorrect when the `context_expr` is itself parenthesized.
For example, _that_ solution would fail here, since the range of the
first `WithItem` would be that of `a`, rather than `(a)`:
```python
with ((a), b):
pass
```
The `with` parsing in general is highly precarious due to ambiguities in
the grammar. Changing it in _any_ way seems to lead to an ambiguous
grammar that LALRPOP fails to translate. Consensus seems to be that we
don't really understand _why_ the current grammar works (i.e., _how_ it
avoids these ambiguities as-is).
The solution implemented here is to avoid changing the grammar itself,
and instead change the shape of the nodes returned by various rules in
the grammar. Specifically, everywhere that we return `Expr`, we instead
return `ParenthesizedExpr`, which includes a parenthesized range and the
underlying `Expr` itself. (If an `Expr` isn't parenthesized, the ranges
will be equivalent.) In `WithItemsNoAs`, we can then use the
parenthesized range as the range for the `WithItem`.
Per discussion at https://github.com/astral-sh/ruff/discussions/6998
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Adds a `--preview` and `--no-preview` option to the CLI for `ruff check`
and corresponding settings. The CLI options are hidden for now.
Available in the settings as `preview = true` or `preview = false`.
Does not include environment variable configuration, although we may add
it in the future.
## Test Plan
<!-- How was it tested? -->
`cargo build`
Future work will build on this setting, such as toggling the mode during
a test.
## Summary
This PR adds comment handling for comments between the `=` and the
`value` for keywords, as in the following cases:
```python
func(
x # dangling
= # dangling
# dangling
1,
** # dangling
y
)
```
(Comments after the `**` were already handled in some cases, but I've
unified the handling with the `=` handling.)
Note that, previously, comments between the `**` and its value were
rendered as trailing comments on the value (so they'd appear after `y`).
This struck me as odd since it effectively re-ordered the comment with
respect to its closest AST node (the value). I've made them leading
comments, though I don't know that that's a significant improvement. I
could also imagine us leaving them where they are.
## Summary
Attempt at a small improvement to two `perflint` rules using the new
type inference capabilities to only flag `PERF401` and `PERF402` for
values we infer to be lists. This makes the rule more conservative, as
it only flags values that we _know_ to be lists, but it's overall a
desirable change, as it favors false negatives over false positives for
a "nice-to-have" rule.
Closes https://github.com/astral-sh/ruff/issues/6995.
## Test Plan
Add non-list value cases and make sure all old cases are still caught.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Rewriting the `if`-comparison to focus on the meaning of rule ` assert
S101`.
Fixes#6984
## Test Plan
<!-- How was it tested? -->
---------
Co-authored-by: Zanie Blue <contact@zanie.dev>
## Summary
Ensures that we use the same error types and messages. Also renames
those struct to `FormatCommand*` for consistency, and removes the
`FormatCommandResult::Skipped` variant in favor of skipping in the
iterator directly.
## Summary
Returns an exit code of 1 if any files would be reformatted:
```
ruff on charlie/format-check:main [$?⇡] is 📦 v0.0.286 via 🐍 v3.11.2 via 🦀 v1.72.0
❯ cargo run -p ruff_cli -- format foo.py --check
Compiling ruff_cli v0.0.286 (/Users/crmarsh/workspace/ruff/crates/ruff_cli)
Finished dev [unoptimized + debuginfo] target(s) in 1.69s
Running `target/debug/ruff format foo.py --check`
warning: `ruff format` is a work-in-progress, subject to change at any time, and intended only for experimentation.
1 file would be reformatted
ruff on charlie/format-check:main [$?⇡] is 📦 v0.0.286 via 🐍 v3.11.2 via 🦀 v1.72.0 took 2s
❯ echo $?
1
```
Closes#6966.
## Summary
This is similar to `commands::check` vs. `commands::check_stdin`, and
gets the logic out of the parent file (`lib.rs`). It also ensures that
we avoid formatting files that should be excluded when `--force-exclude`
is provided.
## Summary
This PR adds a new helper method on the `Cursor` called `eat_char2`
which is similar to `eat_char` but accepts 2 characters instead of 1. It'll
`bump` the cursor twice if both characters are found on lookahead.
## Test Plan
`cargo test`
- Use `Option` instead of `Result` everywhere.
- Use `field` instead of `property` (to match the nomenclature of
`NamedTuple` and `TypedDict`).
- Put the violation function at the top of the file, rather than the
bottom.
## Summary
The `typename` argument to `NamedTuple` and `TypedDict` is a required
positional argument. We assumed as much, but panicked if it was provided
as a keyword argument or otherwise omitted. This PR handles the case
gracefully.
Closes https://github.com/astral-sh/ruff/issues/6953.
## Summary
As a small quality-of-life improvement, the locator can now slice like
`locator.slice(stmt)` instead of requiring
`locator.slice(stmt.range())`.
## Test Plan
`cargo test`
## Summary
This PR adds a higher-level enum (`SourceType`) around `PySourceType` to
allow us to use the same detection path to handle TOML files. Right now,
we have ad hoc `is_pyproject_toml` checks littered around, and some
codepaths are omitting that logic altogether (like `add_noqa`). Instead,
we should always be required to check the source type and handle TOML
files as appropriate.
This PR will also help with our pre-commit capabilities. If we add
`toml` to pre-commit (to support `pyproject.toml`), pre-commit will
start to pass _other_ files to Ruff (along with `poetry.lock` and
`Pipfile` -- see
[identify](b59996304f/identify/extensions.py (L355))).
By detecting those files and handling those cases, we avoid attempting
to parse them as Python files, which would lead to pre-commit errors.
(We tried to add `toml` to pre-commit here
(https://github.com/astral-sh/ruff-pre-commit/pull/44), but had to
revert here (https://github.com/astral-sh/ruff-pre-commit/pull/45) as it
led to the pre-commit hook attempting to parse `poetry.lock` files as
Python files.)
## Summary
This PR fixes a bug which sends the lexer into infinite loop for an invalid input.
The code in question is `[1` where the nesting is never finished. This means
that the lexer will keep emitting the `Err` token forever.
## Test Plan
Add a test case which collects all the tokens from the lexer. This just
makes sure that it doesn't go into infinite loop.
## Summary
Just making the formatter CLI more consistent with the linter -- e.g.,
we now use stdin on invocations like `cat foo.py | cargo run -p ruff_cli
-- format -- --stdin-filename=foo.py`, instead of _only_ relying on the
`-` file (and use the same helper as the linter to facilitate this).
**Summary** Add recursive formatting based on `ruff check` file
discovery for `ruff format`, as a prototype for the formatter alpha.
This allows e.g. `format ../projects/django/`. It's still lacking
support for any settings except line length.
Note just like the existing `ruff format` this will become part of the
production build, i.e. you'll be able to use it - hidden by default and
with a prominent warning - with `ruff format .` after the next release.
Error handling works in my manual tests (the colors do also work):
```
$ target/debug/ruff format scripts/
warning: `ruff format` is a work-in-progress, subject to change at any time, and intended for internal use only.
```
(the above changes `add_rule.py` where we have the wrong bin op
breaking)
```
$ target/debug/ruff format ../projects/django/
warning: `ruff format` is a work-in-progress, subject to change at any time, and intended for internal use only.
Failed to format /home/konsti/projects/django/tests/test_runner_apps/tagged/tests_syntax_error.py: source contains syntax errors: ParseError { error: UnrecognizedToken(Name { name: "syntax_error" }, None), offset: 131, source_path: "<filename>" }
```
```
$ target/debug/ruff format a
warning: `ruff format` is a work-in-progress, subject to change at any time, and intended for internal use only.
Failed to read /home/konsti/ruff/a/d.py: Permission denied (os error 13)
```
**Test Plan** Missing! I'm not sure if it's worth building tests at this
stage or how they should look like.
## Summary
The motivation here is that this enables us to implement `Ranged` in
crates that don't depend on `ruff_python_ast`.
Largely a mechanical refactor with a lot of regex, Clippy help, and
manual fixups.
## Test Plan
`cargo test`
## Summary
The range of the usage from `Globals` should be the range of the
identifier, not the range of the full `global pandas` statement.
Closes https://github.com/astral-sh/ruff/issues/6914.
## Summary
This PR introduces two new AST nodes to improve the representation of
`PatternMatchClass`. As a reminder, `PatternMatchClass` looks like this:
```python
case Point2D(0, 0, x=1, y=2):
...
```
Historically, this was represented as a vector of patterns (for the `0,
0` portion) and parallel vectors of keyword names (for `x` and `y`) and
values (for `1` and `2`). This introduces a bunch of challenges for the
formatter, but importantly, it's also really different from how we
represent similar nodes, like arguments (`func(0, 0, x=1, y=2)`) or
parameters (`def func(x, y)`).
So, firstly, we now use a single node (`PatternArguments`) for the
entire parenthesized region, making it much more consistent with our
other nodes. So, above, `PatternArguments` would be `(0, 0, x=1, y=2)`.
Secondly, we now have a `PatternKeyword` node for `x=1` and `y=2`. This
is much more similar to the how `Keyword` is represented within
`Arguments` for call expressions.
Closes https://github.com/astral-sh/ruff/issues/6866.
Closes https://github.com/astral-sh/ruff/issues/6880.
Closes#6767
Replaces https://github.com/astral-sh/ruff/pull/6773 (this cherry-picks
some parts from there)
Alternative to the approach introduced in #6616 which added support for
placeholders in format specifications while retaining parsing of other
format specification parts.
The idea is that if there are placeholders in a format specification we
will not attempt to glean semantic meaning from the other parts of the
format specification we'll just extract all of the placeholders ignoring
other characters. The dynamic content of placeholders can drastically
change the meaning of the format specification in ways unknowable by
static analysis. This change prevents false analysis and will ensure
safety if we build other rules on top of this at the cost of missing
detection of some bad specifications.
Minor note: I've use "replacements" and "placeholders" interchangeably
but am trying to go with "placeholder" as I think it's a better term for
the static analysis concept here
Closes https://github.com/astral-sh/ruff/issues/6821
ERA100 was not raising on commented parts of dictionaries if it included
another comment (such as a noqa clause). In cases where this comment was
a noqa clause, RUF100 to be emitted since the noqa would have no effect.
Here, we update ERA100 to raise even when there are trailing comments.
This resolves the linked issue _and_ increases the scope of ERA100. We
could narrow the regular expression to only apply to noqa comments if we
do not want to expand ERA100 however I think this change is within the
spirit of the rule.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Adds support for `PatternMatchMapping` -- i.e., cases like:
```python
match foo:
case {"a": 1, "b": 2, **rest}:
pass
```
Unfortunately, this node has _three_ kinds of dangling comments:
```python
{ # "open parenthesis comment"
key: pattern,
** # end-of-line "double star comment"
# own-line "double star comment"
rest # end-of-line "after rest comment"
# own-line "after rest comment"
}
```
Some of the complexity comes from the fact that in `**rest`, `rest` is
an _identifier_, not a node, so we have to handle comments _after_ it as
dangling on the enclosing node, rather than trailing on `**rest`. (We
could change the AST to use `PatternMatchAs` there, which would be more
permissive than the grammar but not totally crazy -- `PatternMatchAs` is
used elsewhere to mean "a single identifier".)
Closes https://github.com/astral-sh/ruff/issues/6644.
## Test Plan
`cargo test`
## Summary
This PR ensures that if an expression has an own-line leading comment
_before_ its open parentheses, we render it as such.
For example, given:
```python
[ # foo
# bar
( # baz
1
)
]
```
On `main`, we format as:
```python
[ # foo
(
# bar
# baz
1
)
]
```
As of this PR, we format as:
```python
[ # foo
# bar
( # baz
1
)
]
```
## Test Plan
`cargo test`
## Summary
This PR ensures that we handle bracketed comments on sequences, like `#
comment` here:
```python
match x:
case [ # comment
1, 2
]:
pass
```
The handling is very similar to other, similar nodes, except that we do
need some special logic to determine whether the sequence is
parenthesized, similar to our logic for tuples.
## Test Plan
`cargo test`
## Summary
This PR modifies our formatting of comments around the `.` in an
attribute. Specifically, the goal here is to avoid _reordering_
comments, and the net effect is that we generally leave comments
where-they-are when dealing with comments between around the dot (which
you can also think of as comments between attributes).
All comments around the dot are now treated as dangling and formatted
manually, with the exception of end-of-line or parenthesized comments on
the value, like those marked as trailing here, which remain trailing:
```python
(
(
a # trailing end-of-line
# trailing own-line
) # dangling before dot end-of-line
.b # trailing end-of-line
)
```
Closes https://github.com/astral-sh/ruff/issues/6823.
## Test Plan
`cargo test`
Before:
| project | similarity index |
|--------------|------------------|
| cpython | 0.76050 |
| django | 0.99820 |
| transformers | 0.99800 |
| twine | 0.99876 |
| typeshed | 0.99953 |
| warehouse | 0.99615 |
| zulip | 0.99729 |
After:
| project | similarity index |
|--------------|------------------|
| cpython | 0.76050 |
| django | 0.99820 |
| transformers | 0.99800 |
| twine | 0.99876 |
| typeshed | 0.99953 |
| warehouse | 0.99615 |
| zulip | 0.99729 |
## Summary
This PR fixes the duplicate-parenthesis problem that's visible in the
tests from https://github.com/astral-sh/ruff/pull/6799. The issue is
that we might have parentheses around the entire match-case pattern,
like in `(1)` here:
```python
match foo:
case (1):
y = 0
```
In this case, the inner expression (`1`) will _think_ it's
parenthesized, but we'll _also_ detect the parentheses at the case level
-- so they get rendered by the case, then again by the expression.
Instead, if we detect parentheses at the case level, we can force-off
the parentheses for the pattern using a design similar to the way we
handle parentheses on expressions.
Closes https://github.com/astral-sh/ruff/issues/6753.
## Test Plan
`cargo test`
## Summary
Our first-party import detection uses a heuristic that doesn't exist in
isort: if an import appears to be from within the same package as the
containing file, we mark it as first-party. For example, if you have a
directory `./foo/__init__.py`, and you import `from foo import bar` in
`./foo/baz.py`, we'll mark that as first-party. (See:
https://github.com/astral-sh/ruff/pull/1266.)
This is often unnecessary, and arguably should be removed (though it
does have some important use-cases that are otherwise unserved -- I
believe Dagster uses it to ensure that all packages mark imports from
within the same package as first-party, but not imports _across_
different first-party packages)... but it does exist, and it does help
in cases in which the `src` field is not properly configured.
This PR adds an option to turn off this behavior:
```toml
[tool.ruff.isort]
detect-same-package = false
```
This is being introduced to help codebases migrating over from isort
that may want more consistent behavior with their current sorting.
## Test Plan
`cargo test`
Extends #6781
Part of https://github.com/astral-sh/ruff/issues/3762
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Allows calls in argument defaults if the argument is annotated as an
immutable type to avoid false positives.
## Test Plan
<!-- How was it tested? -->
Snapshots
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fix#6834
## Test Plan
<!-- How was it tested? -->
Need tests?
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
The docs were out of date, and the new version incorporates some
feedback.
I tried to keep the language concise and the information ordered by how
early you need it, so people can get the relevant information quickly
before jumping into the code.
I did some minor format_dev changes for consistency in the docs.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Closes https://github.com/astral-sh/ruff/issues/6788 by special casing
integer literals with attribute access — either retaining parenthesis
for literals with values (e.g. `int(7).denominator` to
`(7).denominator)` or leaving calls without values (e.g.
`int().denominator`) unchanged.
## Summary
Another drive-by change to remove unnecessary custom lexing. We just
need to know the parenthesized range, so we can use...
`parenthesized_range`. I've also updated `parenthesized_range` to
support nested parentheses.
## Test Plan
`cargo test`
## Summary
This is effectively #6608, but with additional tests.
We aren't properly handling parenthesized patterns, but that needs to be
dealt with separately as it's somewhat involved.
Closes#6555
## Summary
Follows up on
https://github.com/astral-sh/ruff/pull/6652#discussion_r1300871033 with
some modifications to the `PatternMatchAs` comment handling.
Specifically, any comments between the `as` and the end are now
formatted as dangling, and we now insert some newlines in the
appropriate places.
## Test Plan
`cargo test`
## Summary
Ensures that we retain the open-parenthesis comment in cases like:
```python
match pattern_comments:
case ( # leading
only_leading
):
...
```
Previously, this was treated as a leading comment on `only_leading`.
## Test Plan
`cargo test`
## Summary
This PR fixes the bug where the decorator parentheses weren't being considered
when computing the autofix for `ANN204`. The existing logic would only look
for balanced parentheses and not multiple pairs of parentheses.
The solution is to remove the logic to generate the autofix and use the
`Parameters` end range directly which includes the parentheses as well.
## Test Plan
Add test case for `ANN204` with decorator being called
fixes: #6790
## Summary
Given:
```python
def end_of_file():
if False:
return 1
x = 2 \
```
Then when searching for the end of the `x = 2` statement, we'd reach a
panic as we'd hit the last line (`\\`) and abort, since the universal
iterator doesn't return trailing newlines. Instead, we should just use
the end of the file as the fallback.
Closes https://github.com/astral-sh/ruff/issues/6787.
## Test Plan
`cargo test`
## Summary
Avoid `C417` for `lambda` with default and variadic parameters.
## Test Plan
`cargo test` and checking if it generates any autofix errors as test
cases
for `lambda` with default parameters already exists.
fixes: #6715
## Summary
This PR updates the lexer tests to use the snapshot testing framework.
It also
makes the following changes:
* Remove the use of macros in the lexer tests
* Use `test_case` for EOL tests
## Test Plan
```
cargo test --package ruff_python_parser --lib --all-features -- lexer::tests --no-capture
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR adds a utility for transforming expressions via LibCST that
automatically wraps the expression in parentheses, applies a
user-provided transformation, then strips the parentheses from the
generated code. LibCST can't parse arbitrary expression ranges, since
some expressions may require parenthesization in order to be parsed
properly. For example:
```python
option = (
'{name}={value}'
.format(nam=name, value=value)
)
```
In this case, the expression range is:
```python
'{name}={value}'
.format(nam=name, value=value)
```
Which isn't valid on its own. So, instead, we add "fake" parentheses
around the expression.
We were already doing this in a few places, so this is mostly
formalizing and DRYing up that pattern.
Closes https://github.com/astral-sh/ruff/issues/6720.
## Summary
For imports, we enforce that there's _at least_ one empty line after an
import (assuming the next statement is _not_ an import), but allow up to
two at the module level.
Closes https://github.com/astral-sh/ruff/issues/6760.
## Test Plan
`cargo test`
## Summary
The isolation group for unused imports was relying on
`checker.semantic().current_statement()`, which isn't valid for that
rule, since it runs over the _scope_, not the statement. Instead, we
need to lookup the isolation group based on the `NodeId` of the
statement.
Our tests didn't catch this, because we mostly have cases that look like
this:
```python
if TYPE_CHECKING:
import shelve
import importlib
```
In this case, the two fixes to remove the two unused imports are
considered overlapping (since we delete the _full_ line, and the two
_full_ lines touch, and we consider exactly-adjacent fixes to be
overlapping), and so they don't run in a single pass due to the
non-overlapping-fixes requirement. That is: the isolation groups aren't
required for this case. They are, however, required for cases like:
```python
if TYPE_CHECKING:
import shelve
import importlib
```
...where the fixes don't overlap.
Closes https://github.com/astral-sh/ruff/issues/6758.
## Test Plan
`cargo test`
`IOError` is special, it is not actually a lint but an error before
linting. I'm not entirely sure how to document it since it does not
match the general lint rule pattern (`Checks that the file can be read
in its entirety.` is imho worse).
I added the in my experience two most common reasons for io errors on
unix systems and linked two tutorials on how to fix them.
See https://github.com/astral-sh/ruff/issues/2646
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
I noticed this in the ecosystem CI check from
https://github.com/astral-sh/ruff/pull/6742. If we include source code
directly in a diagnostic, we need to be careful to avoid rendering
multi-line diagnostics or even excessively long diagnostics.
## Test Plan
`cargo test`
## Summary
This PR is a follow-up to the suggestion in
https://github.com/astral-sh/ruff/pull/6345#discussion_r1285470953 to
use a single stack to store all statements and expressions, rather than
using separate vectors for each, which gives us something closer to a
full-fidelity chain. (We can then generalize this concept to include all
other AST nodes too.)
This is in part made possible by the removal of the hash map from
`&Stmt` to `StatementId` (#6694), which makes it much cheaper to store
these using a single interface (since doing so no longer introduces the
requirement that we hash all expressions).
I'll follow-up with some profiling, but a few notes on how the data
requirements have changed:
- We now store a `BranchId` for every expression, not just every
statement, so that's an extra `u32`.
- We now store a single `NodeId` on every snapshot, rather than separate
`StatementId` and `ExpressionId` IDs, so that's one fewer `u32` for each
snapshot.
- We're probably doing a few more lookups in general, since any calls to
`current_statement()` etc. now have to iterate up the node hierarchy
until they identify the first statement.
## Test Plan
`cargo test`
## Summary
Avoid attempting to rewrite `import matplotlib.pyplot` as `import
matplotlib.pyplot as plt`. We can't support these right now, since we
don't track references at the attribute level (like
`matplotlib.pyplot`).
Closes https://github.com/astral-sh/ruff/issues/6719.
## Summary
Given:
```python
from sys import *
exit(0)
```
We can't add `exit` to `from sys import *`, so we should just ignore it.
Ideally, we'd just resolve `exit` in the first place (since it's
imported from `from sys import *`), but as long as we don't support
wildcard imports, this is more consistent.
Closes https://github.com/astral-sh/ruff/issues/6718.
## Test Plan
`cargo test`
Avoid the nesting in a macro by using the new `WithNodeLevel` to
`PyFormatter` deref. No changes otherwise.
I wanted to follow this up with quickly fixing the typeshed empty line
rules but they turned out a lot more complex than i had anticipated.
**Summary** A common pattern in the code used to be
```rust
if statements.len() != 1 {
return;
}
use_single_entry(statements[0])?;
```
which can be better expressed as
```rust
let [statement] = statements else {
return;
};
use_single_entry(statements)?;
```
Direct indexing can cause panics if you don't manually take care of
checking the length, while matching (such as if-let or let-else) can
never panic.
This isn't a complete refactor, i've just removed some of the obvious
cases. I've specifically looked for `.len() != 1` and fixed those.
**Test Plan** No functional changes
## Summary
We're using LibCST to ensure that we return the full parenthesized range
of an expression, for display purposes. We can just use
`parenthesized_range` which is more efficient and removes one LibCST
dependency.
## Test Plan
`cargo test`
This _probably_ never matters given the set of rules we support and in
fact I'm having trouble thinking of a test-case for it, but it's
definitely incorrect _not_ to pass on the `BranchId` here.
## Summary
We have a few rules that rely on detecting whether two statements are in
different branches -- for example, different arms of an `if`-`else`.
Historically, the way this was implemented is that, given two statement
IDs, we'd find the common parent (by traversing upwards via our
`Statements` abstraction); then identify branches "manually" by matching
the parents against `try`, `if`, and `match`, and returning iterators
over the arms; then check if there's an arm for which one of the
statements is a child, and the other is not.
This has a few drawbacks:
1. First, the code is generally a bit hard to follow (Konsti mentioned
this too when working on the `ElifElseClause` refactor).
2. Second, this is the only place in the codebase where we need to go
from `&Stmt` to `StatementID` -- _everywhere_ else, we only need to go
in the _other_ direction. Supporting these lookups means we need to
maintain a mapping from `&Stmt` to `StatementID` that includes every
`&Stmt` in the program. (We _also_ end up maintaining a `depth` level
for every statement.) I'd like to get rid of these requirements to
improve efficiency, reduce complexity, and enable us to treat AST modes
more generically in the future. (When I looked at adding the `&Expr` to
our existing statement-tracking infrastructure, maintaining a hash map
with all the statements noticeably hurt performance.)
The solution implemented here instead makes branches a first-class
concept in the semantic model. Like with `Statements`, we now have a
`Branches` abstraction, where each branch points to its optional parent.
When we store statements, we store the `BranchID` alongside each
statement. When we need to detect whether two statements are in the same
branch, we just realize each statement's branch path and compare the
two. (Assuming that the two statements are in the same scope, then
they're on the same branch IFF one branch path is a subset of the other,
starting from the top.) We then add some calls to the visitor to push
and pop branches in the appropriate places, for `if`, `try`, and `match`
statements.
Note that a branch is not 1:1 with a statement; instead, each branch is
closer to a suite, but not _every_ suite is a branch. For example, each
arm in an `if`-`elif`-`else` is a branch, but the `else` in a `for` loop
is not considered a branch.
In addition to being much simpler, this should also be more efficient,
since we've shed the entire `&Stmt` hash map, plus the `depth` that we
track on `StatementWithParent` in favor of a single `Option<BranchID>`
on `StatementWithParent` plus a single vector for all branches. The
lookups should be faster too, since instead of doing a bunch of jumps
around with the hash map + repeated recursive calls to find the common
parents, we instead just do a few simple lookups in the `Branches`
vector to realize and compare the branch paths.
## Test Plan
`cargo test` -- we have a lot of coverage for this, which we inherited
from PyFlakes
## Summary
This is much simpler and avoids (1) multiple passes over the entire
function body, (2) requiring the rule to do its own binding tracking (we
can just use the semantic model), and (3) a usage of `StatementKey`.
In general, where we can, we should try to remove these kinds of custom
visitors that track name references, and instead rely on the semantic
model.
## Test Plan
`cargo test`
## Summary
If a lambda doesn't contain any parameters, or any parameter _tokens_
(like `*`), we can use `None` for the parameters. This feels like a
better representation to me, since, e.g., what should the `TextRange` be
for a non-existent set of parameters? It also allows us to remove
several sites where we check if the `Parameters` is empty by seeing if
it contains any arguments, so semantically, we're already trying to
detect and model around this elsewhere.
Changing this also fixes a number of issues with dangling comments in
parameter-less lambdas, since those comments are now automatically
marked as dangling on the lambda. (As-is, we were also doing something
not-great whereby the lambda was responsible for formatting dangling
comments on the parameters, which has been removed.)
Closes https://github.com/astral-sh/ruff/issues/6646.
Closes https://github.com/astral-sh/ruff/issues/6647.
## Test Plan
`cargo test`
## Summary
In working on https://github.com/astral-sh/ruff/pull/6628, I noticed
that we clone the source code contents, potentially multiple times,
prior to linting. The issue is that `SourceKind::Python` takes a
`String`, so we first have to provide it with a `String`. In the stdin
case, that means cloning. However, on top of this, we then have to clone
`source_kind.contents()` because `SourceKind` gets mutated. So for
stdin, we end up cloning twice. For non-stdin, we end up cloning once,
but unnecessarily (since the _contents_ don't get mutated, only the
kind).
This PR removes the `String` from `source_kind`, instead requiring that
we parse it out elsewhere. It reduces the number of clones down to 1 for
Jupyter Notebooks, and zero otherwise.
## Summary
The motivating code here was:
```python
with test as (
# test
foo):
pass
```
Which we were formatting as:
```python
with test as
# test
(foo):
pass
```
`with` statements are oddly difficult. This PR makes a bunch of subtle
modifications and adds a more extensive test suite. For example, we now
only preserve parentheses if there's more than one `WithItem` _or_ a
trailing comma; before, we always preserved.
Our formatting is_not_ the same as Black, but here's a diff of our
formatted code vs. Black's for the `with.py` test suite. The primary
difference is that we tend to break parentheses when they contain
comments rather than move them to the end of the life (this is a
consistent difference that we make across the codebase):
```diff
diff --git a/crates/ruff_python_formatter/foo.py b/crates/ruff_python_formatter/foo.py
index 85e761080..31625c876 100644
--- a/crates/ruff_python_formatter/foo.py
+++ b/crates/ruff_python_formatter/foo.py
@@ -1,6 +1,4 @@
-with (
- aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
-), aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa:
+with aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa, aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa:
...
# trailing
@@ -16,28 +14,33 @@ with (
# trailing
-with a, b: # a # comma # c # colon
+with (
+ a, # a # comma
+ b, # c
+): # colon
...
with (
- a as # a # as
- # own line
- b, # b # comma
+ a as ( # a # as
+ # own line
+ b
+ ), # b # comma
c, # c
): # colon
... # body
# body trailing own
-with (
- a as # a # as
+with a as ( # a # as
# own line
- bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb # b
-):
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
+): # b
pass
-with (a,): # magic trailing comma
+with (
+ a,
+): # magic trailing comma
...
@@ -47,6 +50,7 @@ with a: # should remove brackets
with aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb as c:
...
+
with (
# leading comment
a
@@ -74,8 +78,7 @@ with (
with (
a # trailing same line comment
# trailing own line comment
- as b
-):
+) as b:
...
with (
@@ -87,7 +90,9 @@ with (
with (
a
# trailing own line comment
-) as b: # trailing as same line comment # trailing b same line comment
+) as ( # trailing as same line comment
+ b
+): # trailing b same line comment
...
with (
@@ -124,18 +129,24 @@ with ( # comment
...
with ( # outer comment
- CtxManager1() as example1, # inner comment
+ ( # inner comment
+ CtxManager1()
+ ) as example1,
CtxManager2() as example2,
CtxManager3() as example3,
):
...
-with CtxManager() as example: # outer comment
+with ( # outer comment
+ CtxManager()
+) as example:
...
with ( # outer comment
CtxManager()
-) as example, CtxManager2() as example2: # inner comment
+) as example, ( # inner comment
+ CtxManager2()
+) as example2:
...
with ( # outer comment
@@ -145,7 +156,9 @@ with ( # outer comment
...
with ( # outer comment
- (CtxManager1()), # inner comment
+ ( # inner comment
+ CtxManager1()
+ ),
CtxManager2(),
) as example:
...
@@ -179,7 +192,9 @@ with (
):
pass
-with a as (b): # foo
+with a as ( # foo
+ b
+):
pass
with f(
@@ -209,17 +224,13 @@ with f(
) as b, c as d:
pass
-with (
- aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
-) as b:
+with aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb as b:
pass
with aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb as b:
pass
-with (
- aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
-) as b, c as d:
+with aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb as b, c as d:
pass
with (
@@ -230,6 +241,8 @@ with (
pass
with (
- aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
-) as b, c as d:
+ aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ + bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb as b,
+ c as d,
+):
pass
```
Closes https://github.com/astral-sh/ruff/issues/6600.
## Test Plan
Before:
| project | similarity index |
|--------------|------------------|
| cpython | 0.75473 |
| django | 0.99804 |
| transformers | 0.99618 |
| twine | 0.99876 |
| typeshed | 0.74292 |
| warehouse | 0.99601 |
| zulip | 0.99727 |
After:
| project | similarity index |
|--------------|------------------|
| cpython | 0.75473 |
| django | 0.99804 |
| transformers | 0.99618 |
| twine | 0.99876 |
| typeshed | 0.74292 |
| warehouse | 0.99601 |
| zulip | 0.99727 |
`cargo test`
## Summary
Attaches comments around the `:=` operator in a named expression as
dangling, and formats them manually in the `named_expr.rs` formatter.
Closes https://github.com/astral-sh/ruff/issues/5695.
## Test Plan
`cargo test`
## Summary
This PR exposes our `is_expression_parenthesized` logic such that we can
use it to expand expressions when autofixing to include their
parenthesized ranges.
This solution has a few drawbacks: (1) we need to compute parenthesized
ranges in more places, which also relies on backwards lexing; and (2) we
need to make use of this in any relevant fixes.
However, I still think it's worth pursuing. On (1), the implementation
is very contained, so IMO we can easily swap this out for a more
performant solution in the future if needed. On (2), this improves
correctness and fixes some bad syntax errors detected by fuzzing, which
means it has value even if it's not as robust as an _actual_
`ParenthesizedExpression` node in the AST itself.
Closes https://github.com/astral-sh/ruff/issues/4925.
## Test Plan
`cargo test` with new cases that previously failed the fuzzer.
## Summary
I noticed some inconsistencies around uses of `.range.start()`, structs
that have a `TextRange` field but don't implement `Ranged`, etc.
## Test Plan
`cargo test`
## Summary
Given:
```python
if (
x
:=
( # 4
y # 5
) # 6
):
pass
```
It turns out the parser ended the range of the `NamedExpr` at the end of
`y`, rather than the end of the parenthesis that encloses `y`. This just
seems like a bug -- the range should be from the start of the name on
the left, to the end of the parenthesized node on the right.
## Test Plan
`cargo test`
Closes https://github.com/astral-sh/ruff/issues/6442
Python string formatting like `"hello {place}".format(place="world")`
supports format specifications for replaced content such as `"hello
{place:>10}".format(place="world")` which will align the text to the
right in a container filled up to ten characters.
Ruff parses formatted strings into `FormatPart`s each of which is either
a `Field` (content in `{...}`) or a `Literal` (the normal content).
Fields are parsed into name and format specifier sections (we'll ignore
conversion specifiers for now).
There are a myriad of specifiers that can be used in a `FormatSpec`.
Unfortunately for linters, the specifier values can be dynamically set.
For example, `"hello {place:{align}{width}}".format(place="world",
align=">", width=10)` and `"hello {place:{fmt}}".format(place="world",
fmt=">10")` will yield the same string as before but variables can be
used to determine the formatting. In this case, when parsing the format
specifier we can't know what _kind_ of specifier is being used as their
meaning is determined by both position and value.
Ruff does not support nested replacements and our current data model
does not support the concept. Here the data model is updated to support
this concept, although linting of specifications with replacements will
be inherently limited. We could split format specifications into two
types, one without any replacements that we can perform lints with and
one with replacements that we cannot inspect. However, it seems
excessive to drop all parsing of format specifiers due to the presence
of a replacement. Instead, I've opted to parse replacements eagerly and
ignore their possible effect on other format specifiers. This will allow
us to retain a simple interface for `FormatSpec` and most syntax checks.
We may need to add some handling to relax errors if a replacement was
seen previously.
It's worth noting that the nested replacement _can_ also include a
format specification although it may fail at runtime if you produce an
invalid outer format specification. For example, `"hello
{place:{fmt:<2}}".format(place="world", fmt=">10")` is valid so we need
to represent each nested replacement as a full `FormatPart`.
## Test plan
Adding unit tests for `FormatSpec` parsing and snapshots for PLE1300
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Support glob patterns for `raises_require_match_for` and
`raises_require_match_for`. Resolve#6473
## Test Plan
New tests + existing tests
## Summary
No behavior changes, but these need some refactoring to support
https://github.com/astral-sh/ruff/pull/6575 (namely, they need to take
the `ast::ExprCompare` or similar node instead of the attribute fields),
and I don't want to muddy that PR.
## Test Plan
`cargo test`
## Summary
Ensures we avoid cases like:
```python
x.values = 1
```
Since Pandas doesn't even expose a setter for that. We also avoid cases
like:
```python
print(self.values)
```
Since it's overwhelming likely to be a false positive.
Closes https://github.com/astral-sh/ruff/issues/6630.
## Test Plan
`cargo test`
## Summary
When running Ruff from stdin, we were always falling back to the default
source type, even if the user specified a path (as is the case when
running from the LSP). This PR wires up the source type inference, which
means we now get the expected result when checking `.pyi` and `.ipynb`
files.
Closes#6627.
## Test Plan
Verified that `cat
crates/ruff/resources/test/fixtures/jupyter/valid.ipynb | cargo run -p
ruff_cli -- --force-exclude --no-cache --no-fix --isolated --select ALL
--stdin-filename foo.ipynb -` yielded the expected results (and differs
from the errors you get if you omit the filename).
Verified that `cat foo.pyi | cargo run -p ruff_cli -- --force-exclude
--no-cache --no-fix --format json --isolated --select TCH
--stdin-filename path/to/foo.pyi -` yielded no errors.
In https://github.com/astral-sh/ruff/pull/6616 we are adding support for
nested replacements in format specifiers which makes actually formatting
strings infeasible without a great deal of complexity. Since we're not
using these functions (they just exist for runtime use in RustPython),
we can just remove them.
## Summary
Closes https://github.com/astral-sh/ruff/issues/6384, although I think
the issue was fixed already on main, for the most part.
The linked issue is around formatting expressions like:
```python
def test():
(
yield
#comment 1
* # comment 2
# comment 3
test # comment 4
)
```
On main, prior to this PR, we now format like:
```python
def test():
(
yield (
# comment 1
# comment 2
# comment 3
*test
) # comment 4
)
```
Which strikes me as reasonable. (We can't test this, since it's a syntax
error after for our parser, despite being a syntax error in both cases
from CPython's perspective.)
Meanwhile, Black does:
```python
def test():
(
yield
# comment 1
* # comment 2
# comment 3
test # comment 4
)
```
So our formatting differs in that we move comments between the star and
the expression above the star.
As of this PR, we also support formatting this input, which is valid:
```python
def test():
(
yield
#comment 1
* # comment 2
# comment 3
test, # comment 4
1
)
```
Like:
```python
def test():
(
yield (
# comment 1
(
# comment 2
# comment 3
*test, # comment 4
1,
)
)
)
```
There were two fixes here: (1) marking starred comments as dangling and
formatting them properly; and (2) supporting parenthesized comments for
tuples that don't contain their own parentheses, as is often the case
for yielded tuples (previously, we hit a debug assert).
Note that this diff
## Test Plan
cargo test
## Summary
Allows for proper lexing of tokens like `->`.
The main challenge is to ensure that our forward and backwards
representations are the same for cases like `===`. Specifically, we want
that to lex as `==` followed by `=` regardless of whether it's a
forwards or backwards lex. To do so, we identify the range of the
sequential characters (the full span of `===`), lex it forwards, then
return the last token.
## Test Plan
`cargo test`
## Summary
This PR adds support for parenthesized comments. A parenthesized comment
is a comment that appears within a parenthesis, but not within the range
of the expression enclosed by the parenthesis. For example, the comment
here is a parenthesized comment:
```python
if (
# comment
True
):
...
```
The parentheses enclose the `True`, but the range of `True` doesn’t
include the `# comment`.
There are at least two problems associated with parenthesized comments:
(1) associating the comment with the correct (i.e., enclosed) node; and
(2) formatting the comment correctly, once it has been associated with
the enclosed node.
The solution proposed here for (1) is to search for parentheses between
preceding and following node, and use open and close parentheses to
break ties, rather than always assigning to the preceding node.
For (2), we handle these special parenthesized comments in `FormatExpr`.
The biggest risk with this approach is that we forget some codepath that
force-disables parenthesization (by passing in `Parentheses::Never`).
I've audited all usages of that enum and added additional handling +
test coverage for such cases.
Closes https://github.com/astral-sh/ruff/issues/6390.
## Test Plan
`cargo test` with new cases.
Before:
| project | similarity index |
|--------------|------------------|
| build | 0.75623 |
| cpython | 0.75472 |
| django | 0.99804 |
| transformers | 0.99618 |
| typeshed | 0.74233 |
| warehouse | 0.99601 |
| zulip | 0.99727 |
After:
| project | similarity index |
|--------------|------------------|
| build | 0.75623 |
| cpython | 0.75472 |
| django | 0.99804 |
| transformers | 0.99618 |
| typeshed | 0.74237 |
| warehouse | 0.99601 |
| zulip | 0.99727 |
## Summary
Unlike other statements, Black always adds a trailing comma if an
import-from statement breaks with a single import member. I believe this
is for compatibility with isort -- see
09f5ee3a19,
https://github.com/psf/black/issues/127, or
66648c528a/src/black/linegen.py (L1452)
for the current version.
## Test Plan
`cargo test`, notice that a big chunk of the compatibility suite is
removed.
Before:
| project | similarity index |
|--------------|------------------|
| cpython | 0.75472 |
| django | 0.99804 |
| transformers | 0.99618 |
| twine | 0.99876 |
| typeshed | 0.74233 |
| warehouse | 0.99601 |
| zulip | 0.99727 |
After:
| project | similarity index |
|--------------|------------------|
| cpython | 0.75472 |
| django | 0.99804 |
| transformers | 0.99618 |
| twine | 0.99876 |
| typeshed | 0.74260 |
| warehouse | 0.99601 |
| zulip | 0.99727 |
## Summary
Instead, we set an `is_star` flag on `Stmt::Try`. This is similar to the
pattern we've migrated towards for `Stmt::For` (removing
`Stmt::AsyncFor`) and friends. While these are significant differences
for an interpreter, we tend to handle these cases identically or nearly
identically.
## Test Plan
`cargo test`
## Summary
This PR adds handling for comments on open parentheses in parenthesized
context managers. For example, given:
```python
with ( # comment
CtxManager1() as example1,
CtxManager2() as example2,
CtxManager3() as example3,
):
...
```
We want to preserve that formatting. (Black does the same.) On `main`,
we format as:
```python
with (
# comment
CtxManager1() as example1,
CtxManager2() as example2,
CtxManager3() as example3,
):
...
```
It's very similar to how `StmtImportFrom` is handled.
Note that this case _isn't_ covered by the "parenthesized comment"
proposal, since this is a common on the statement that would typically
be attached to the first `WithItem`, and the `WithItem` _itself_ can
have parenthesized comments, like:
```python
with ( # comment
(
CtxManager1() # comment
) as example1,
CtxManager2() as example2,
CtxManager3() as example3,
):
...
```
## Test Plan
`cargo test`
Confirmed no change in similarity score.
## Summary
For #6485, I need to be able to use the `SimpleTokenizer` to lex the
space between any two adjacent expressions (i.e., the space between a
preceding and following node). This requires that we support a wider
range of keywords (like `and`, to connect the pieces of `x and y`), and
some additional single-character tokens (like `-` and `>`, to support
`->`). Note that the `SimpleTokenizer` does not support multi-character
tokens, so the `->` in a function signature is lexed as a `-` followed
by a `>` -- but this is fine for our purposes.
## Summary
In https://github.com/astral-sh/ruff/pull/6512, we added a flag to the
AST to mark implicitly-concatenated string expressions. This PR makes
use of that flag to remove the `is_implicit_concatenation` method.
## Test Plan
`cargo test`
## Summary
The bracketed-end-of-line comment rule is meant to assign comments like
this as "immediately following the bracket":
```python
f( # comment
1
)
```
However, the logic was such that we treated this equivalently:
```python
f(
( # comment
1
)
)
```
This PR modifies the placement logic to ensure that we only skip the
opening bracket, and not any nested brackets. The above is now formatted
as:
```python
f(
(
# comment
1
)
)
```
(But will be corrected once we handle parenthesized comments properly.)
## Test Plan
`cargo test`
Confirmed no change in similarity score.
## Summary
Per the discussion in
https://github.com/astral-sh/ruff/discussions/6183, this PR adds an
`implicit_concatenated` flag to the string and bytes constant variants.
It's not actually _used_ anywhere as of this PR, but it is covered by
the tests.
Specifically, we now use a struct for the string and bytes cases, along
with the `Expr::FString` node. That struct holds the value, plus the
flag:
```rust
#[derive(Clone, Debug, PartialEq, is_macro::Is)]
pub enum Constant {
Str(StringConstant),
Bytes(BytesConstant),
...
}
#[derive(Clone, Debug, PartialEq, Eq)]
pub struct StringConstant {
/// The string value as resolved by the parser (i.e., without quotes, or escape sequences, or
/// implicit concatenations).
pub value: String,
/// Whether the string contains multiple string tokens that were implicitly concatenated.
pub implicit_concatenated: bool,
}
impl Deref for StringConstant {
type Target = str;
fn deref(&self) -> &Self::Target {
self.value.as_str()
}
}
#[derive(Clone, Debug, PartialEq, Eq)]
pub struct BytesConstant {
/// The bytes value as resolved by the parser (i.e., without quotes, or escape sequences, or
/// implicit concatenations).
pub value: Vec<u8>,
/// Whether the string contains multiple string tokens that were implicitly concatenated.
pub implicit_concatenated: bool,
}
impl Deref for BytesConstant {
type Target = [u8];
fn deref(&self) -> &Self::Target {
self.value.as_slice()
}
}
```
## Test Plan
`cargo test`
**Summary** Implement docstring formatting
**Test Plan** Matches black's `docstring.py` fixture exactly, added some
new cases for what is hard to debug with black and with what black
doesn't cover.
similarity index:
main:
zulip: 0.99702
django: 0.99784
warehouse: 0.99585
build: 0.75623
transformers: 0.99469
cpython: 0.75989
typeshed: 0.74853
this branch:
zulip: 0.99702
django: 0.99784
warehouse: 0.99585
build: 0.75623
transformers: 0.99464
cpython: 0.75517
typeshed: 0.74853
The regression in transformers is actually an improvement in a file they
don't format with black (they run `black examples tests src utils
setup.py conftest.py`, the difference is in hubconf.py). cpython doesn't
use black.
Closes#6196
## Summary
This method is almost never what you actually want, because it doesn't
respect Python's scoping semantics. For example, if you call this within
a class method, it will return class attributes, whereas Python actually
_skips_ symbols in classes unless the load occurs within the class
itself. I also want to move away from these kinds of dynamic lookups and
more towards `resolve_name`, which performs a lookup based on the stored
`BindingId` at the time of symbol resolution, and will make it much
easier for us to separate model building from linting in the near
future.
## Test Plan
`cargo test`
## Summary
Fixes some TODOs introduced in
https://github.com/astral-sh/ruff/pull/6538. In short, given an
expression like `1 if x > 0 else "Hello, world!"`, we now return a union
type that says the expression can resolve to either an `int` or a `str`.
The system remains very limited, it only works for obvious primitive
types, and there's no attempt to do inference on any more complex
variables. (If any expression yields `Unknown` or `TypeError`, we
propagate that result throughout and abort on the client's end.)
## Summary
When adding an import, such as when fixing `I002`, ruff doesn't skip
whitespace between comments, but isort does. See this issue for more
detail: https://github.com/astral-sh/ruff/issues/6504
This change would fix that by skipping whitespace between comments in
`Insertion.start_of_file()`.
## Test Plan
I added a new test, `comments_and_newlines`, to verify this behavior. I
also ran `cargo test` and no existing tests broke. That being said, this
is technically a breaking change, as it's possible that someone was
relying on the previous behavior.
## Summary
Generalizes the abstractions for name matching introduced in
https://github.com/astral-sh/ruff/pull/6378 and applies them to the
existing `banned_api` rule, such that both rules have a uniform API and
implementation.
## Test Plan
`cargo test`
## Summary
Noticed in https://github.com/astral-sh/ruff/pull/6378. Given `import h;
import i`, we don't consider `import i` to be a "top-level" import for
E402 purposes, which is wrong. Similarly, we _do_ consider `import k` to
be a "top-level" import in:
```python
if __name__ == "__main__":
import j; \
import k
```
Using the semantic detection, rather than relying on newline position,
fixes both cases.
## Test Plan
`cargo test`
## Summary
Add a new rule `TID253` (`banned-module-level-imports`), to ban a
user-specified list of imports from appearing at module level. This rule
doesn't exist in `flake8-tidy-imports`, so it's unique to Ruff. The
implementation is pretty similar to `TID251`.
Briefly discussed
[here](https://github.com/astral-sh/ruff/discussions/6370).
## Test Plan
Added a new test case, checking that inline imports are allowed and that
non-inline imports from the banned list are disallowed.
## Summary
This PR modifies our logic for wrapping return type annotations.
Previously, we _always_ wrapped the annotation in parentheses if it
expanded; however, Black only exhibits this behavior when the function
parameters is empty (i.e., it doesn't and can't break). In other cases,
it uses the normal parenthesization rules, allowing nodes to bring their
own parentheses.
For example, given:
```python
def xxxxxxxxxxxxxxxxxxxxxxxxxxxx() -> Set[
"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
]:
...
def xxxxxxxxxxxxxxxxxxxxxxxxxxxx(x) -> Set[
"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
]:
...
```
Black will format as:
```python
def xxxxxxxxxxxxxxxxxxxxxxxxxxxx() -> (
Set[
"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
]
):
...
def xxxxxxxxxxxxxxxxxxxxxxxxxxxx(
x,
) -> Set[
"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
]:
...
```
Whereas, prior to this PR, Ruff would format as:
```python
def xxxxxxxxxxxxxxxxxxxxxxxxxxxx() -> (
Set[
"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
]
):
...
def xxxxxxxxxxxxxxxxxxxxxxxxxxxx(
x,
) -> (
Set[
"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
]
):
...
```
Closes https://github.com/astral-sh/ruff/issues/6431.
## Test Plan
Before:
- `zulip`: 0.99702
- `django`: 0.99784
- `warehouse`: 0.99585
- `build`: 0.75623
- `transformers`: 0.99470
- `cpython`: 0.75988
- `typeshed`: 0.74853
After:
- `zulip`: 0.99724
- `django`: 0.99791
- `warehouse`: 0.99586
- `build`: 0.75623
- `transformers`: 0.99474
- `cpython`: 0.75956
- `typeshed`: 0.74857
## Summary
This PR fixes some misformattings around optional parentheses for
expressions.
I first noticed that we were misformatting this:
```python
return (
unicodedata.normalize("NFKC", s1).casefold()
== unicodedata.normalize("NFKC", s2).casefold()
)
```
The above is stable Black formatting, but we were doing:
```python
return unicodedata.normalize("NFKC", s1).casefold() == unicodedata.normalize(
"NFKC", s2
).casefold()
```
Above, the "last" expression is a function call, so our
`can_omit_optional_parentheses` was returning `true`...
However, it turns out that Black treats function calls differently
depending on whether or not they have arguments -- presumedly because
they'll never split empty parentheses, and so they're functionally
non-useful. On further investigation, I believe this applies to all
parenthesized expressions. If Black can't split on the parentheses, it
doesn't leverage them when removing optional parentheses.
## Test Plan
Nice increase in similarity scores.
Before:
- `zulip`: 0.99702
- `django`: 0.99784
- `warehouse`: 0.99585
- `build`: 0.75623
- `transformers`: 0.99470
- `cpython`: 0.75989
- `typeshed`: 0.74853
After:
- `zulip`: 0.99705
- `django`: 0.99795
- `warehouse`: 0.99600
- `build`: 0.75623
- `transformers`: 0.99471
- `cpython`: 0.75989
- `typeshed`: 0.74853
**Summary** Some files seems notoriously slow in the formatter (secons in debug mode). This time was however almost exclusively spent in the diff algorithm to collect the similarity index, so i replaced that. I kept `similar` for printing actual diff to avoid rewriting that too, with the disadvantage that we now have to diff libraries in format_dev.
I used this PR to remove the spinner from tracing-indicatif and changed `flamegraph --perfdata perf.data` to `flamegraph --perfdata perf.data --no-inline` as the former wouldn't finish for me on release builds with debug info.
## Summary
This PR adds formatting support for `MatchCase` node with subs for the
`Pattern`
nodes.
## Test Plan
Added test cases for case node handling with comments, newlines.
resolves: #6299
## Summary
The bug was happening in this
[loop](75f402eb82/crates/ruff_python_formatter/src/comments/placement.rs (L545)).
Basically, In the first iteration of the loop, the `comment_indentation`
is bigger than `child_indentation` (`comment_indentation` is 7 and
`child_indentation` is 4) making the `Ordering::Greater` branch execute.
Inside the `Ordering::Greater` branch, the `if` block gets executed,
resulting in the update of these variables.
```rust
parent_body = current_body;
current_body = Some(last_child_in_current_body);
last_child_in_current_body = nested_child;
```
In the second iteration of the loop, `comment_indentation` is smaller
than `child_indentation` (`comment_indentation` is 7 and
`child_indentation` is 8) making the `Ordering::Less` branch execute.
Inside the `Ordering::Less` branch, the `if` block gets executed, this
is where the bug was happening. At this point `parent_body` should be a
`StmtFunctionDef` but it was a `StmtClassDef`. Causing the comment to be
incorrectly formatted.
That happened for the following code:
```python
class A:
def f():
pass
# strangely indented comment
print()
```
There is only one problem that I couldn't figure it out a solution, the
variable `current_body` in this
[line](75f402eb82/crates/ruff_python_formatter/src/comments/placement.rs (L542C5-L542C49))
now gives this warning _"value assigned to `current_body` is never read
maybe it is overwritten before being read?"_
Any tips on how to solve that?
Closes#5337
## Test Plan
Add new test case.
---------
Co-authored-by: konstin <konstin@mailbox.org>
**Summary** Implement `DerefMut` for `WithNodeLevel` so it can be used
in the same way as `PyFormatter`. I want this for my WIP upstack branch
to enable `.fmt(f)` on `WithNodeLevel` context. We could extend this to
remove the other two method from `WithNodeLevel`.
## Summary
Some follow-ups to https://github.com/astral-sh/ruff/pull/6131 to ensure
that fixes are inserted _after_ function docstrings, and that fixes are
robust to a bunch of edge cases.
## Test Plan
`cargo test`
## Summary
This PR respects our unused variable regex when flagging bound
exceptions, so that you no longer get a violation for, e.g.:
```python
def f():
try:
pass
except Exception as _:
pass
```
This is an odd pattern, but I think it's surprising that the regex
_isn't_ respected here.
Closes https://github.com/astral-sh/ruff/issues/6391
## Test Plan
`cargo test`
## Summary
In https://github.com/astral-sh/ruff/pull/5811, I suggested that we add
a heuristic to the overlong-lines check such that if the line had fewer
bytes than the character limit, we return early -- the idea being that a
single byte per character was the "worst case". I overlooked that this
isn't true for tabs -- with tabs, the "worst case" scenario is that
every byte is a tab, which can have a width greater than 1.
Closes https://github.com/astral-sh/ruff/issues/6425.
## Test Plan
`cargo test` with a new fixture borrowed from the issue, plus manual
testing.
## Summary
Checks for any misspelled dunder name method and for any method defined
with `__...__` that's not one of the pre-defined methods.
The pre-defined methods encompass all of Python's standard dunder
methods.
ref: #970
## Test Plan
Snapshots and manual runs of pylint.
## Summary
Our `is_builtin` check did a naive walk over the parent scopes; instead,
it needs to (e.g.) skip symbols in a class scope if being called outside
of the class scope itself.
Closes https://github.com/astral-sh/ruff/issues/6466.
## Test Plan
`cargo test`
## Summary
Reopening of https://github.com/astral-sh/ruff/pull/4880
One open TODO as described in:
https://github.com/astral-sh/ruff/pull/4880#discussion_r1265110215
FYI @charliermarsh seeing as you commented you wanted to do final review
and merge. @konstin @dhruvmanila @MichaReiser as previous reviewers.
# Old Description
## Summary
Adds an autofix for B006 turning mutable argument defaults into None and
setting their original value back in the function body if still `None`
at runtime like so:
```python
def before(x=[]):
pass
def after(x=None):
if x is None:
x = []
pass
```
## Test Plan
Added an extra test case to existing fixture with more indentation.
Checked results for all old examples.
NOTE: Also adapted the jupyter notebook test as this checked for B006 as
well.
## Issue link
Closes: https://github.com/charliermarsh/ruff/issues/4693
---------
Co-authored-by: konstin <konstin@mailbox.org>
**Summary** I collected all examples of end-of-line comments after
opening parentheses that i could think of so we get a comprehensive view
at the state of their formatting (#6390).
This PR intentionally only adds tests cases without any changes in
formatting. We need to decide which exact formatting we want, ideally in
terms of these test files, and implement this in follow-up PRs.
~~One stability check is still deactivated pending
https://github.com/astral-sh/ruff/pull/6386.~~
We currently don't format all comments as match statements are not yet implemented. We can work around this for the top level match statement by setting them manually formatted but the mocked-out top level match doesn't call into its children so they would still have unformatted comments
<!--
Thank you for contributing to Ruff! To help us out with reviewing, please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR fixes the issue where the FString formatting dropped dangling comments between the string parts.
```python
result_f = (
f' File "{__file__}", line {lineno_f+1}, in f\n'
' f()\n'
# XXX: The following line changes depending on whether the tests
# are run through the interactive interpreter or with -m
# It also varies depending on the platform (stack size)
# Fortunately, we don't care about exactness here, so we use regex
r' \[Previous line repeated (\d+) more times\]' '\n'
'RecursionError: maximum recursion depth exceeded\n'
)
```
The solution here isn't ideal because it re-introduces the `enclosing_parent` on `DecoratedComment` but it is the easiest fix that I could come up.
I didn't spend more time finding another solution becaues I think we have to re-write most of the fstring formatting with the upcoming Python 3.12 support (because lexing the individual parts as we do now will no longer work).
closes#6440
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
`cargo test`
The child PR testing that all comments are formatted should now pass
<!--
Thank you for contributing to Ruff! To help us out with reviewing, please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR adds the `AnyNodeRef.visit_preorder` method. I'll need this method to mark all comments of a suppressed node's children as formatted (in debug builds).
I'm not super happy with this because it now requires a double-dispatch where the `walk_*` methods call into `node.visit_preorder` and the `visit_preorder` then calls back into the visitor. Meaning,
the new implementation now probably results in way more function calls. The other downside is that `AnyNodeRef` now contains code that is difficult to auto-generate. This could be mitigated by extracting the `visit_preorder` method into its own `VisitPreorder` trait.
Anyway, this approach solves the need and avoids duplicating the visiting code once more.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
`cargo test`
<!-- How was it tested? -->
## Summary
The use of `|` as a union operator is not always safe, if a type
annotation is evaluated in a runtime context. For example, this code
errors at runtime:
```python
import httpretty
import requests_mock
item: type[requests_mock.Mocker | httpretty] = requests_mock.Mocker
```
However, it's fine in a `.pyi` file, with `__future__` annotations`, or
if the annotation is in a non-evaluated context, like:
```python
def func():
item: type[requests_mock.Mocker | httpretty] = requests_mock.Mocker
```
This PR modifies the rule to avoid enforcing in those invalid,
runtime-evaluated contexts.
Closes https://github.com/astral-sh/ruff/issues/6455.
## Summary
Use the same Python version by default for all tests (our
latest-supported version).
## Test Plan
`cargo test`
---------
Co-authored-by: Zanie <contact@zanie.dev>
## Summary
I think it makes sense for `PythonVersion::default()` to return our
minimum-supported non-EOL version.
## Test Plan
`cargo test`
---------
Co-authored-by: Zanie <contact@zanie.dev>
## Summary
This PR renames the `MagicCommand` token to `IpyEscapeCommand` token and
`MagicKind` to `IpyEscapeKind` type to better reflect the purpose of the
token and type. Similarly, it renames the AST nodes from `LineMagic` to
`IpyEscapeCommand` prefixed with `Stmt`/`Expr` wherever necessary.
It also makes renames from using `jupyter_magic` to
`ipython_escape_commands` in various function names.
The mode value is still `Mode::Jupyter` because the escape commands are
part of the IPython syntax but the lexing/parsing is done for a Jupyter
notebook.
### Motivation behind the rename:
* IPython codebase defines it as "EscapeCommand" / "Escape Sequences":
* Escape Sequences:
292e3a2345/IPython/core/inputtransformer2.py (L329-L333)
* Escape command:
292e3a2345/IPython/core/inputtransformer2.py (L410-L411)
* The word "magic" is used mainly for the actual magic commands i.e.,
the ones starting with `%`/`%%`
(https://ipython.readthedocs.io/en/stable/interactive/reference.html#magic-command-system).
So, this avoids any confusion between the Magic token (`%`, `%%`) and
the escape command itself.
## Test Plan
* `cargo test` to make sure all renames are done correctly.
* `grep` for `jupyter_escape`/`magic` to make sure all renames are done
correctly.
## Summary
This PR removes the group around function definition parameters, instead
grouping the parameters with the type parameters and return type
annotation.
This increases Zulip's similarity score from 0.99385 to 0.99699, so it's
a meaningful improvement. However, there's at least one stability error
that I'm working on, and I'm really just looking for high-level feedback
at this point, because I'm not happy with the solution.
Closes https://github.com/astral-sh/ruff/issues/6352.
## Test Plan
Before:
- `zulip`: 0.99396
- `django`: 0.99784
- `warehouse`: 0.99578
- `build`: 0.75436
- `transformers`: 0.99407
- `cpython`: 0.75987
- `typeshed`: 0.74432
After:
- `zulip`: 0.99702
- `django`: 0.99784
- `warehouse`: 0.99585
- `build`: 0.75623
- `transformers`: 0.99470
- `cpython`: 0.75988
- `typeshed`: 0.74853
## Summary
In https://github.com/astral-sh/ruff/pull/6397, the documentation was
updated stating that the default target-version is now "py38", but the
actual default value wasn't updated and remained py310. This commit
updates the default value to match what the documentation says.
## Summary
This PR adds support for a stricter version of help end escape
commands[^1] in the parser. By stricter, I mean that the escape tokens
are only at the end of the command and there are no tokens at the start.
This makes it difficult to implement it in the lexer without having to
do a lot of look aheads or keeping track of previous tokens.
Now, as we're adding this in the parser, the lexer needs to recognize
and emit a new token for `?`. So, `Question` token is added which will
be recognized only in `Jupyter` mode.
The conditions applied are the same as the ones in the original
implementation in IPython codebase (which is a regex):
* There can only be either 1 or 2 question mark(s) at the end
* The node before the question mark can be a `Name`, `Attribute`,
`Subscript` (only with integer constants in slice position), or any
combination of the 3 nodes.
## Test Plan
Added test cases for various combination of the possible nodes in the
command value position and update the snapshots.
fixes: #6359fixes: #5030 (This is the final piece)
[^1]: https://github.com/astral-sh/ruff/pull/6272#issue-1833094281
## Summary
Error if `tab-size` is set to zero (it is used as a divisor). Closes
#6423.
Also fixes a typo.
## Test Plan
Running ruff with a config
```toml
[tool.ruff]
tab-size = 0
```
returns an error message to the user saying that `tab-size` must be
greater than zero.
## Summary
Given:
```python
def double(a: int) -> ( # Hello
int
):
return 2*a
```
We currently treat `# Hello` as a trailing comment on the parameters
(`(a: int)`). This PR adds a placement method to instead treat it as a
dangling comment on the function definition itself, so that it gets
formatted at the end of the definition, like:
```python
def double(a: int) -> int: # Hello
return 2*a
```
The formatting in this case is unchanged, but it's incorrect IMO for
that to be a trailing comment on the parameters, and that placement
leads to an instability after changing the grouping in #6410.
Fixing this led to a _different_ instability related to tuple return
type annotations, like:
```python
def zrevrangebylex(self, name: _Key, max: _Value, min: _Value, start: int | None = None, num: int | None = None) -> ( # type: ignore[override]
):
...
```
(This is a real example.)
To fix, I had to special-case tuples in that spot, though I'm not
certain that's correct.
## Summary
This PR moves `empty_parenthesized` such that it's peer to
`parenthesized`, and changes the API to better match that of
`parenthesized` (takes `&str` rather than `StaticText`, has a
`with_dangling_comments` method, etc.).
It may be intentionally _not_ part of `parentheses.rs`, but to me
they're so similar that it makes more sense for them to be in the same
module, with the same API, etc.
## Summary
This PR adds support for `StmtMatch` with subs for `MatchCase`.
## Test Plan
Add a few additional test cases around `match` statement, comments, line
breaks.
resolves: #6298
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fix name of rule in example of `extend-per-file-ignores` in `options.rs`
file.
It was `E401` but in configuration example `E402` was listed. Just a
tiny mismatch.
## Test Plan
<!-- How was it tested? -->
Just by my eyes :).
## Bug
Given
```python
x = () - (#
)
```
the comment is a dangling comment of the empty tuple. This is an
end-of-line comment so it may move after the expression. It still
expands the parent, so the operator breaks:
```python
x = (
()
- () #
)
```
In the next formatting pass, the comment is not a trailing tuple but a
trailing bin op comment, so the bin op doesn't break anymore. The
comment again expands the parent, so we still add the superfluous
parentheses
```python
x = (
() - () #
)
```
## Fix
The new formatting is to keep the comment on the empty tuple. This is a
log uglier and again has additional outer parentheses, but it's stable:
```python
x = (
()
- ( #
)
)
```
## Alternatives
Black formats all the examples above as
```python
x = () - () #
```
which i find better.
I would be happy about any suggestions for better solutions than the
current one. I'd mainly need a workaround for expand parent having an
effect on the bin op instead of first moving the comment to the end and
then applying expand parent to the assign statement.
## Summary
Manually add the parentheses around tuple expressions for the autofix in
`B014`.
This is also done in various other autofixes as well such as for
[`RUF005`](6df5ab4098/crates/ruff/src/rules/ruff/rules/collection_literal_concatenation.rs (L183-L184)),
[`UP024`](6df5ab4098/crates/ruff/src/rules/pyupgrade/rules/os_error_alias.rs (L137-L137)).
### Alternate Solution
An alternate solution would be to fix this in the `Generator` itself by
checking
if the tuple expression needs to be generated at the top-level or not.
If so,
then always add the parentheses.
```rust
} else if level == 0 {
// Top-level tuples are always parenthesized.
self.p("(");
let mut first = true;
for elt in elts {
self.p_delim(&mut first, ", ");
self.unparse_expr(elt, precedence::COMMA);
}
self.p_if(elts.len() == 1, ",");
self.p(")");
```
## Test Plan
Add a regression test for this case in `B014`.
fixes: #6412
Extends #6289 to support moving type variable usage in type aliases to
use PEP-695.
Does not remove the possibly unused type variable declaration.
Presumably this is handled by other rules, but is not working for me.
Does not handle type variables with bounds or variance declarations yet.
Part of #4617
## Summary
We have some logic in the expression analyzer method to avoid
re-checking the inner `Union` in `Union[Union[...]]`, since the methods
that analyze `Union` expressions already recurse. Elsewhere, we have
logic to avoid re-checking the inner `|` in `int | (int | str)`, for the
same reason.
This PR unifies that logic into a single method _and_ ensures that, just
as we recurse over both `Union` and `|`, we also detect that we're in
_either_ kind of nested union.
Closes https://github.com/astral-sh/ruff/issues/6285.
## Test Plan
Added some new snapshots.
## Summary
We can anticipate earlier that this will error, so we should avoid
flagging the error at all. Specifically, we're talking about cases like
`"{1} {0}".format(*args)"`, in which we'd need to reorder the arguments
in order to remove the `1` and `0`, but we _can't_ reorder the arguments
since they're not statically analyzable.
Closes https://github.com/astral-sh/ruff/issues/6388.
## Summary
I noticed some deviations in how we treat dangling comments that hug the
opening parenthesis for function definitions.
For example, given:
```python
def f( # first
# second
): # third
...
```
We currently format as:
```python
def f(
# first
# second
): # third
...
```
This PR adds the proper opening-parenthesis dangling comment handling
for function parameters. Specifically, as with all other parenthesized
nodes, we now detect that dangling comment in `placement.rs` and handle
it in `parameters.rs`. We have to take some care in that file, since we
have multiple "kinds" of dangling comments, but I added a bunch of test
cases that we now format identically to Black.
## Test Plan
`cargo test`
Before:
- `zulip`: 0.99388
- `django`: 0.99784
- `warehouse`: 0.99504
- `transformers`: 0.99404
- `cpython`: 0.75913
- `typeshed`: 0.74364
After:
- `zulip`: 0.99386
- `django`: 0.99784
- `warehouse`: 0.99504
- `transformers`: 0.99404
- `cpython`: 0.75913
- `typeshed`: 0.74409
Meaningful improvement on `typeshed`, minor decrease on `zulip`.
Closes https://github.com/astral-sh/ruff/issues/6068
These commits are kind of a mess as I did some stumbling around here.
Unrolls formatting of chained boolean operations to prevent nested
grouping which gives us Black-compatible formatting where each boolean
operation is on a new line.
## Summary
This PR modifies our `can_omit_optional_parentheses` rules to ensure
that if we see a call followed by an attribute, we treat that as an
attribute access rather than a splittable call expression.
This in turn ensures that we wrap like:
```python
ct_match = aaaaaaaaaaact_id == self.get_content_type(
obj=rel_obj, using=instance._state.db
)
```
For calls, but:
```python
ct_match = (
aaaaaaaaaaact_id == self.get_content_type(obj=rel_obj, using=instance._state.db).id
)
```
For calls with trailing attribute accesses.
Closes https://github.com/astral-sh/ruff/issues/6065.
## Test Plan
Similarity index before:
- `zulip`: 0.99436
- `django`: 0.99779
- `warehouse`: 0.99504
- `transformers`: 0.99403
- `cpython`: 0.75912
- `typeshed`: 0.72293
And after:
- `zulip`: 0.99436
- `django`: 0.99780
- `warehouse`: 0.99504
- `transformers`: 0.99404
- `cpython`: 0.75913
- `typeshed`: 0.72293
## Summary
This PR leverages the unified function definition node to add precise
AST node types to `MemberKind`, which is used to power our docstring
definition tracking (e.g., classes and functions, whether they're
methods or functions or nested functions and so on, whether they have a
docstring, etc.). It was painful to do this in the past because the
function variants needed to support a union anyway, but storing precise
nodes removes like a dozen panics.
No behavior changes -- purely a refactor.
## Test Plan
`cargo test`
## Summary
Per the suggestion in
https://github.com/astral-sh/ruff/discussions/6183, this PR removes
`AsyncWith`, `AsyncFor`, and `AsyncFunctionDef`, replacing them with an
`is_async` field on the non-async variants of those structs. Unlike an
interpreter, we _generally_ have identical handling for these nodes, so
separating them into distinct variants adds complexity from which we
don't really benefit. This can be seen below, where we get to remove a
_ton_ of code related to adding generic `Any*` wrappers, and a ton of
duplicate branches for these cases.
## Test Plan
`cargo test` is unchanged, apart from parser snapshots.
## Summary
See discussion in
https://github.com/astral-sh/ruff/pull/6351#discussion_r1284996979. We
can remove `RefEquality` entirely and instead use a text offset for
statement keys, since no two statements can start at the same text
offset.
## Test Plan
`cargo test`
## Summary
This PR adds support for help end escape command in the lexer.
### What are "help end escape commands"?
First, the escape commands are special IPython syntax which enhances the
functionality for the IPython REPL. There are 9 types of escape kinds
which are recognized by the tokens which are present at the start of the
command (`?`, `??`, `!`, `!!`, etc.).
Here, the help command is using either the `?` or `??` token at the
start (`?str.replace` for example). Those 2 tokens are also supported
when they're at the end of the command (`str.replace?`), but the other
tokens aren't supported in that position.
There are mainly two types of help end escape commands:
1. Ending with either `?` or `??`, but it also starts with one of the
escape tokens (`%matplotlib?`)
2. On the other hand, there's a stricter version for (1) which doesn't
start with any escape tokens (`str.replace?`)
This PR adds support for (1) while (2) will be supported in the parser.
### Priority
Now, if the command starts and ends with an escape token, how do we
decide the kind of this command? This is where priority comes into
picture. This is simple as there's only one priority where `?`/`??` at
the end takes priority over any other escape token and all of the other
tokens are at the same priority. Remember that only `?`/`??` at the end
is considered valid.
This is mainly useful in the case where someone would want to invoke the
help command on the magic command itself. For example, in `%matplotlib?`
the help command takes priority which means that we want help for the
`matplotlib` magic function instead of calling the magic function
itself.
### Specification
Here's where things get a bit tricky. What if there are question mark
tokens at both ends. How do we decide if it's `Help` (`?`) kind or
`Help2` (`??`) kind?
| | Magic | Value | Kind |
| --- | --- | --- | --- |
| 1 | `?foo?` | `foo` | `Help` |
| 2 | `??foo?` | `foo` | `Help` |
| 3 | `?foo??` | `foo` | `Help2` |
| 4 | `??foo??` | `foo` | `Help2` |
| 5 | `???foo??` | `foo` | `Help2` |
| 6 | `??foo???` | `foo???` | `Help2` |
| 7 | `???foo???` | `?foo???` | `Help2` |
Looking at the above table:
- The question mark tokens on the right takes priority over the ones on
the left but only if the number of question mark on the right is 1 or 2.
- If there are more than 2 question mark tokens on the right side, then
the left side is used to determine the same.
- If the right side is used to determine the kind, then all of the
question marks and whitespaces on the left side are ignored in the
`value`, but if it’s the other way around, then all of the extra
question marks are part of the `value`.
### References
- IPython implementation using the regex:
292e3a2345/IPython/core/inputtransformer2.py (L454-L462)
- Priorities:
292e3a2345/IPython/core/inputtransformer2.py (L466-L469)
## Test Plan
Add a bunch of test cases for the lexer and verify that it matches the
behavior of
IPython transformer.
resolves: #6357
## Summary
This PR fixes the performance degradation introduced in
https://github.com/astral-sh/ruff/pull/6345. Instead of using the
generic `Nodes` structs, we now use separate `Statement` and
`Expression` structs. Importantly, we can avoid tracking a bunch of
state for expressions that we need for parents: we don't need to track
reference-to-ID pointers (we just have no use-case for this -- I'd
actually like to remove this from statements too, but we need it for
branch detection right now), we don't need to track depth, etc.
In my testing, this entirely removes the regression on all-rules, and
gets us down to 2ms slower on the default rules (as a crude hyperfine
benchmark, so this is within margin of error IMO).
No behavioral changes.
## Summary
This PR attempts to draw a clearer divide between "methods that take
(e.g.) an expression or statement as input" and "methods that rely on
the _current_ expression or statement" in the semantic model, by
renaming methods like `stmt()` to `current_statement()`.
This had led to confusion in the past. For example, prior to this PR, we
had `scope()` (which returns the current scope), and `parent_scope`,
which returns the parent _of a scope that's passed in_. Now, the API is
clearer: `current_scope` returns the current scope, and `parent_scope`
takes a scope as argument and returns its parent.
Per above, I also changed `stmt` to `statement` and `expr` to
`expression`.
## Summary
Given:
```python
[ # comment
first,
second,
third
] # another comment
```
We were adding a hard line break as part of the formatting of `#
comment`, which led to the following formatting:
```python
[first, second, third] # comment
# another comment
```
Closes https://github.com/astral-sh/ruff/issues/6367.
## Summary
Fixes an instability whereby this:
```python
def get_recent_deployments(threshold_days: int) -> Set[str]:
# Returns a list of deployments not older than threshold days
# including `/root/zulip` directory if it exists.
recent = set()
threshold_date = datetime.datetime.now() - datetime.timedelta( # noqa: DTZ005
days=threshold_days
)
```
Was being formatted as:
```python
def get_recent_deployments(threshold_days: int) -> Set[str]:
# Returns a list of deployments not older than threshold days
# including `/root/zulip` directory if it exists.
recent = set()
threshold_date = (
datetime.datetime.now()
- datetime.timedelta(days=threshold_days) # noqa: DTZ005
)
```
Which was in turn being formatted as:
```python
def get_recent_deployments(threshold_days: int) -> Set[str]:
# Returns a list of deployments not older than threshold days
# including `/root/zulip` directory if it exists.
recent = set()
threshold_date = (
datetime.datetime.now() - datetime.timedelta(days=threshold_days) # noqa: DTZ005
)
```
The second-to-third formattings still differs from Black because we
aren't taking the line suffix into account when splitting
(https://github.com/astral-sh/ruff/issues/6377), but the first
formatting is correct and should be unchanged (i.e., the first-to-second
formattings is incorrect, and fixed here).
## Test Plan
`cargo run --bin ruff_dev -- format-dev --stability-check ../zulip`
## Summary
When we iterate over the AST for analysis, we often process nodes in a
"deferred" manner. For example, if we're analyzing a function, we push
the function body onto a deferred stack, along with a snapshot of the
current semantic model state. Later, when we analyze the body, we
restore the semantic model state from the snapshot. This ensures that we
know the correct scope, hierarchy of statement parents, etc., when we go
to analyze the function body.
Historically, we _haven't_ included the _expression_ hierarchy in the
model snapshot -- so we track the current expression parents in the
visitor, but we never save and restore them when processing deferred
nodes. This can lead to subtle bugs, in that methods like
`expr_parent()` aren't guaranteed to be correct, if you're in a deferred
visitor.
This PR migrates expression tracking to mirror statement tracking
exactly. So we push all expressions onto an `IndexVec`, and include the
current expression on the snapshot. This ensures that `expr_parent()`
and related methods are "always correct" rather than "sometimes
correct".
There's a performance cost here, both at runtime and in terms of memory
consumption (we now store an additional pointer for every expression).
In my hyperfine testing, it's about a 1% performance decrease for
all-rules on CPython (up to 533.8ms, from 528.3ms) and a 4% performance
decrease for default-rules on CPython (up to 212ms, from 204ms).
However... I think this is worth it given the incorrectness of our
current approach. In the future, we may want to reconsider how we do
these upward traversals (e.g., with something like a red-green tree).
(**Note**: in https://github.com/astral-sh/ruff/pull/6351, the slowdown
seems to be entirely removed.)